https://github.com/zoezhousy/Canteen_Queue_Monitoring
COMP4423 Computer Vision
Canteen Queue Monitoring System Project Report
1 Introduction
In campus canteens, managing queues and ensuring efficient service delivery is crucial for providing a positive dining experience to students. Long queues and waiting times can lead to frustration and dissatisfaction among students, impacting their overall experience. Queue monitoring systems in campus canteens are important for efficient crowd control and ensuring a smooth flow of students for this situation. To achieve this, the queue monitoring backend system with different computer vision tasks I will develop contains following 2 aspects:
• Monitoring the number of students waiting in line in front of any service window
• Calculation of estimated average waiting time in a queue.
This report will introduce general method selected to train and test, what and how model is used to trained, validated, and tested, how it performs in object detection and segmentation in the real campus scenario, what problem I have encountered and how I solved them.
During system development, several factors must be considered, such as data collection, object detection using the Histogram of Oriented Gradient (HOG) Descriptor algorithm, YOLO v5 pretrained model, faster R-CNN model algorithm, predict time mainly use the MLP Regressor with fully connected neural network – a supervised learning algorithm used for predicting time.
The primary goal of a queue monitoring system is to enhance the overall customer experience by reducing waiting times and improving the efficiency of the queue management process. By analyzing the queue data, the system can help canteen managers allocate resources more effectively, such as adjusting staff schedules or optimizing food preparation processes. The system aims to streamline the queue management process, leading to increased operational efficiency and productivity in the canteen.
2 Method
Step 1: Data collection
Videos from canteen were collected from canteen manually. The aim was to gather a divers set of canteens queuing information that covers different service window of canteen that covers different time.
Step 2: Data Labeling
Once data were collected, labeled Json line files were created for each video file in the folder “label” in dataset directory, and it contains frame numbers and customer numbers which will be used in the accuracy checking part. Number examples are as shown in Figure 1 below.
 Figure 1 customer number and frame ID in dataset JSON lines files
Figure 1 customer number and frame ID in dataset JSON lines files
Also, a CSV file(servingTime.csv) was created, recording the waiting time, service time, waiting people, window name. Data are created manually by labeling with the video. The data will be processed in for predicting waiting times in a queue. The form of the csv is shown as Figure 2 below. The first is the wait time after entering the queue. The second is service time. The third was waiting for a couple of people before service. The last column means the window name.
 Figure 2 Serving time duration data in CSV file
Figure 2 Serving time duration data in CSV file
Step 3: Data Preprocessing
For the Json line files, the label in this file is processed in the cell “Preprocessing label with image-frames”, process data and labels in every frame of a video dataset, it preprocessed the label file, and get the customer number from in the line of ‘customernum’
For the video collected, the video path is also processed, and save as a path_list, for better iteration in later algorithms to processing videos in a batch. In the cell “Extract Frame” was used to convert video into frames pictures with an interval of one second. For each video in video_path, it opens the video file using cv2.VideoCapture(video_name). It sets time_skips to 1 second. This is the interval at which frames will be extracted from the video. It skips ahead in the video by time_skips milliseconds with cap.set(cv2.CAP_PROP_POS_MSEC, (count*time_skips)). In the first cell of “YOLOv5 Algorithm”, the frame images’ paths are also saved in a list of img_path_list with different list of frame_path for each video. And then the model YOLO v5 can process the images with the path easily after convert to frame.
For the CSV file, for the data in CSV file, the file can be converted into a data frame, which is better for column operation. The data frame form enables efficient column operation, such as filtering, aggregation, sorting, and transformation. In our project, for predicting waiting time in a queue, we
will use filtering more. It would be easier to manipulate and analyze data. Conversion from CSV to Dataframe is implemented by the read_csv() function from pandas library.
Step 4: Pretrained model for People Detection
In this section, we describe the algorithms used for object detection in the queue monitoring system. We explore three popular object detection algorithms: HOG descriptor, Improved HOG descriptor, YOLOv5, and Faster R-CNN.
1. HOG people detector
As people have horizontal edges in the shoulders and vertical edges in both arms. Whereas the edge of non-people samples are cluttered, so the shape can be detected by constructing a HOG. Since the histogram loses spatial information, HOG segments the image into small regions one by one (linking to the chunking method in thresholding), constructs histograms for the small regions separately, and then stitches them together to get a large histogram.
The Histogram of Oriented Gradients (HOG) descriptor is a classic feature-based object detection algorithm. It works by calculating the gradient orientation in local image patches and representing them as histograms. HOG is known for its simplicity and efficiency, making it suitable for real-time applications.
- Initialization HOG & SVM detector: The code initializes an HOG person detector, sets SVM detector, and open the video using OpenCV's VideoCapture class. We trained a linear support vector machine (SVM) classifier using the extracted HOG features. The SVM was trained on our annotated dataset, where positive samples contained images with customers in the queue area, and negative samples contained images without customers.
- Read through each frame: For each video, the program read each frame using cap.read().
- Apply the HOG descriptor-based object detection: using hog.detectMultiScale(), the code returns bounding boxes and weights for each detected person. Then counts the number of people detected in each frame and appends the pred_num_people list. It also sets the video’s position to the next frames according to the specified time_skips
 Figure 3 Bounding box from HOG People detector
Figure 3 Bounding box from HOG People detector
2. Improved HOG people detector
However, the performance of HOG descriptors is not desirable as Figure 3 shows, it will not box the correct people, such as some sundries. Therefore, we choose to apply a non-maxima suppression
technique for improvement. Non-Maxima Suppression is an improvement technique used in detecting people with the Histogram of Oriented Gradients (HOG) descriptor, using non_max_suppression function from imutils.object_detection library.
boxes = np.array([[x, y, x + w, y + h] for (x, y, w, h) in boxes])
pick = non_max_suppression(boxes, probs=None, overlapThresh=0.65)
The goal is to select the detection box with the highest confidence score among the candidate human detection boxes and suppress other overlapping detection boxes with a high overlap with the selected box, thus eliminating redundant detection results.
3. YOLOv5
YOLO (You Only Look Once) is a popular real-time object detection algorithm known for its speed and accuracy. We utilized the YOLOv5 variant, which offers improved performance over its predecessors. The steps are as follows:
- Import YOLOv5 model: import from PyTorch library to perform object detection on the frames produced.
- Load YOLOv5 model if CUDA-enabled GPU is available. This step speed up the computing speed.
- Iterate all frames generated by all videos, and result are obtained as a pandas Data Frame using results.pandas().xyxy[0].
- Filter the DataFrame to include only rows where the ‘name’ column is ‘person’
- Calculate the number of people, then save into the people_list , representing the number of people detected in each image.
 Figure 4 The detection result for YOLO v5 Algorithm
Figure 4 The detection result for YOLO v5 Algorithm
The result of YOLOv5 is much more accurate than HOG descriptor we implemented before. But from camera’s view-point, the staff in the window was also detected as the algorithm does not label the difference between staff and region of the window.
4. Faster RCNN
Faster R-CNN is a state-of-the-art object detection algorithm that combines region proposal networks (RPN) and region-based convolutional neural networks (R-CNN). It achieves high accuracy by generating region proposals and classifying objects within those proposals. The steps we implemented are as follows:
- Process the captured frame with 1 second’s interval: The code iterates over each frame of the video using a while loop.
- Normalizing pixel values: The frame is preprocessed by converting the color space to RGB.
- Load YOLOv5model if CUDA-enabled GPU is available. This step speed up the computing speed.
- The frame tensor is passed through the Faster R-CNN model for inference using model([frame_model]).
- Apply non-maximun suppression: The output is post-processed to apply non-maximum suppression applied in the Improved HOG descriptorand filter out detections below a confidence threshold.
- Calculate the number of people, then save into the people_list_RCNN, representing the number of people detected in each image.
Step 5: Result Validation for People Detection
The validation process for People Detection part is mainly done by one function match_rate(original, pred), This function calculates the match rate between the original and predicted values. The function takes original (The original values list), pred (The predicted value list), and then returns the match rate for each set of values.
Step 6: Pretrained model and for Time Prediction
We assume that the time values follow a normal distribution. We calculate the mean and standard deviation of the time data. Using these parameters, we can generate predictions by sampling from the normal distribution.
For VA canteen, the mean of distribution is 31.88888888888889, and the standard deviation is 17.489118932803667, and the distribution and predicted distribution is like follows.
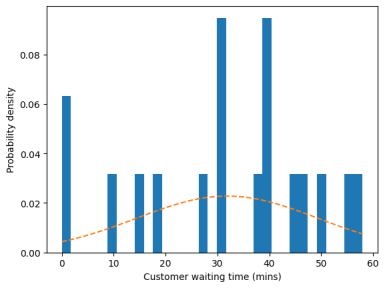
Figure 5 Customer Waiting Time for VA and Communal Canteen
Then apply information fitted in the MLPRegressor from library sklearn.neural_network and after fits into the Neural Network. Then do the prediction for the value data, the result is shown as follows. It is not predicted right for a small scale.
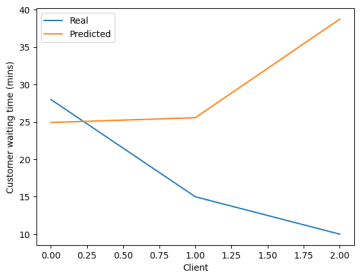
Figure 6 Prediction of VA group data and Communal group data
And the Mean absolute error for VA group data before Neural network is 13.995331312107668, after applying, the mean absolute error for VA group data with the neural network is 14.122988555126183 seconds. And the Mean absolute error for Communal group data before Neural network is 16.785586225631405, after applying, the mean absolute error for Communal group datawith the neural network is 16.281377988082898 seconds.
After neural network, the MAE goes higher for VA canteen, and goes slightly lower for Communal canteen. So MAE
The trained model was evaluated on the testing data using the Mean Absolute Error (MAE) metric, which measures the average prediction error.
3 Discussion
3.1 Result Analysis
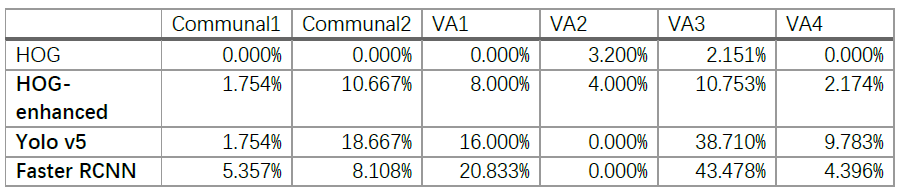
Table 1 Comparison between different videos and different algorithms
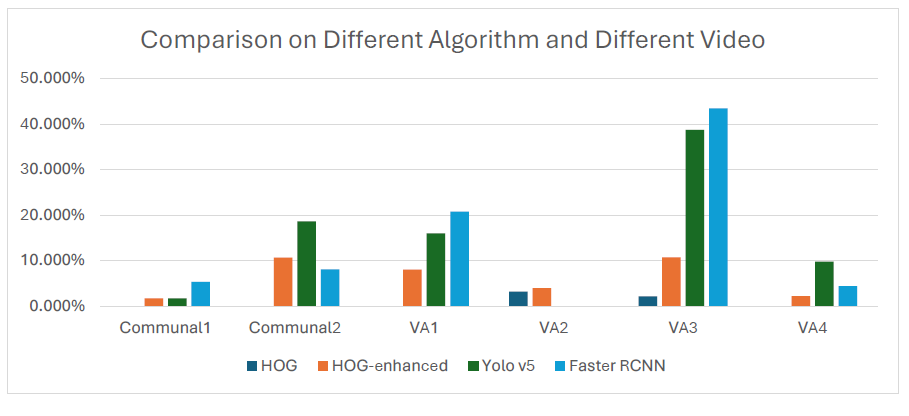
Based on the provided data, which appears to represent the performance of different object detection models on various tasks (Communal1, Communal2, VA1, VA2, VA3, VA4), we can make the following observations:
HOG (Histogram of Oriented Gradients): It has a low detection rate across all tasks, with 0% detection for Communal1 and Communal2, and a slightly higher but still low detection rate for VA2 and VA3.
HOG-enhanced: This variant of HOG performs better than the basic HOG method, with improved detection rates for all tasks compared to HOG. However, the detection rates are still relatively low, ranging from 1.754% to 10.667%.
Yolo v5: This model shows better performance compared to HOG and HOG-enhanced. It achieves higher detection rates across most tasks, with the highest detection rates for VA3 and VA4 (38.710% and 9.783% respectively). However, it performs poorly on Communal1 and Communal2.
Faster RCNN: Among the models listed, Faster RCNN exhibits the highest detection rates for most tasks. It performs particularly well on VA3 and VA4, with detection rates of 43.478% and 4.396% respectively. However, it shows lower performance on Communal1 and Communal2 compared to Yolo v5.
Overall, Yolo v5 and Faster RCNN appear to outperform HOG and HOG-enhanced in terms of detection rates. However, the specific choice of the best model depends on the task and requirements of the application.
3.2 Limitations
3.3.1 Limited Diversity in Training Data
The training dataset may not fully capture the wide range of different windows, and the time duration for the video is not long. This limitation can affect the model's ability to generalize to the time prediction part. Collecting a more diverse and representative training dataset could help address this limitation.
3.3.2 Sensitivity to Image Quality and Resolution
The performance of the model may be sensitive to the quality and resolution of the input images. Variations in image quality, such as low-resolution or noisy images, might impact the accuracy of feature extraction and subsequently affect the model's predictions. Preprocessing techniques, such as image enhancement or denoising, could be explored to mitigate this limitation.
4 Conclusion
In conclusion, the Canteen Queue Monitoring System project provides a promising approach to managing queues efficiently in campus canteens. By utilizing advanced computer vision techniques, including HOG descriptor, YOLO v5, and Faster R-CNN, the system can effectively monitor the number of students in line and estimate the waiting time. Despite certain limitations, such as the diversity of training data and sensitivity to image quality, the system demonstrates potential in
enhancing the dining experience for students and improving operational efficiency for canteen managers. Future work will focus on overcoming these challenges and refining the system to ensure more accurate and reliable results. This project underscores the importance of leveraging technology to address real-world challenges and improve the quality of everyday life.