
RAG stands for Retrieval-Augmented Generation. It's a framework for Generative AI to provide informed responses.
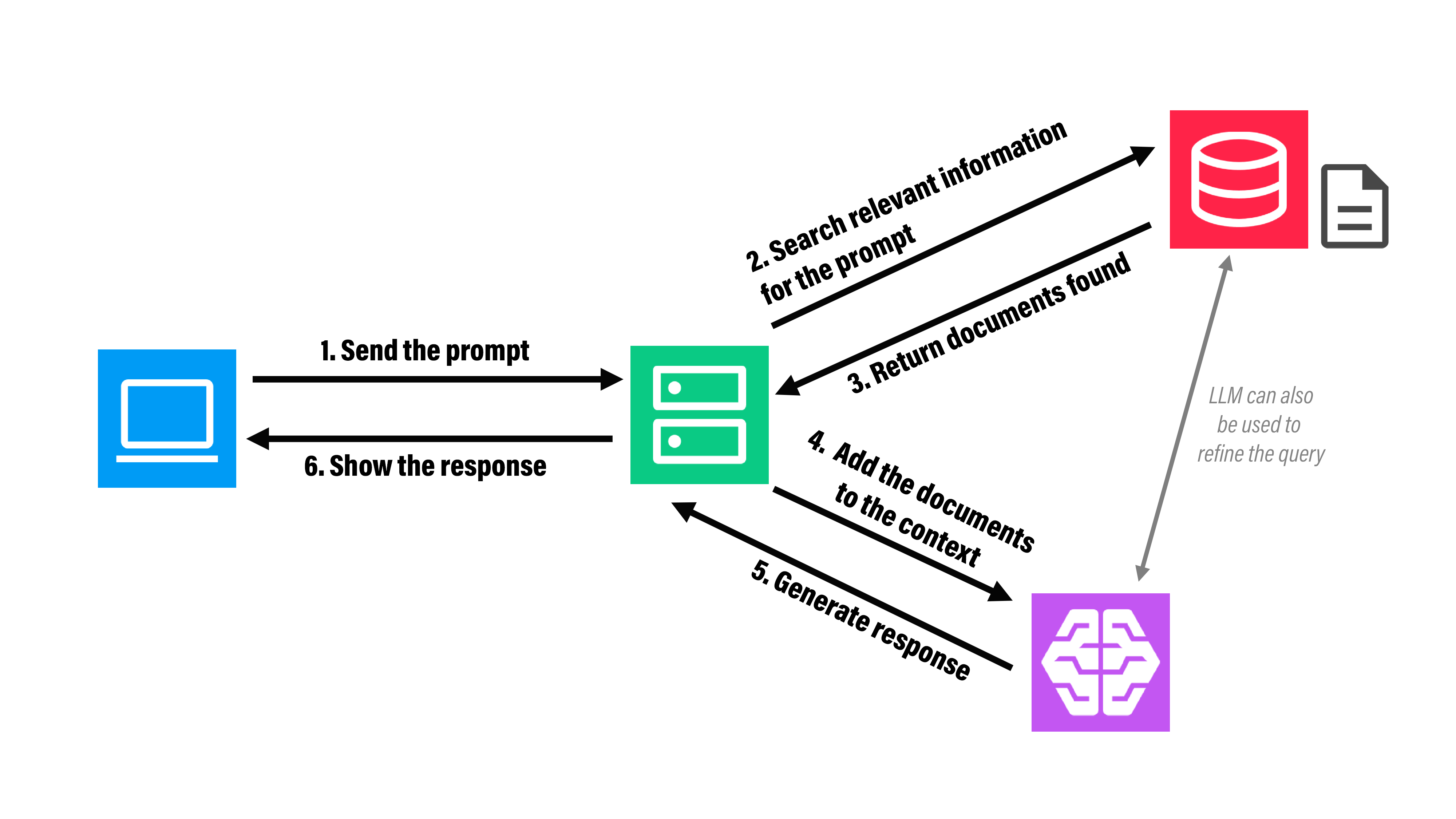
For LLMs, this is done with the following steps:
1. AI hallucinations: this method reduces the chance of getting made-up answers.
2. The limits of the training data: we can add up-to-date answers which could not yet be elements of the training dataset.
3. Context-aware answers: instead of getting generic answers, the RAG retrieves domain-specific documents (so words are less likely to be overshadowed).
4. Reliability: the model will know about the documents returned, so it can cite sources where we can check the correctness of the answer.
In this article I'll show you how I built my own RAG.
The goal of this article is to teach any reader about Retrieval-Augmented Generation (RAG) systems through code.
This learning experience is also cost efficient and secure as it runs locally, so the data isn't shared and there are no cloud fees.
Requirements: To complete this project, Python 3.11 and Docker (or Docker Desktop) should be installed. Python is needed for scripting, while Docker will run containers with Apache Solr and Ollama.
Basically any database can be used for this purpose. I used Apache Solr 9.8.1 (documentation) as it's a scalable solution with great search capabilities.
First of all you have to collect documents which can be uploaded to your database. (These can range from Wikipedia articles to your own company documents.)
When you have collected all the data you should preprocess them to make it easier for an LLM to understand.
Cleaning data: let's say you have .html files which contain unnecessary html tags. With BeautifulSoup you can make the content more readable which increases the performance of your system.
from bs4 import BeautifulSoup def get_content(path_to_file : str) -> str: with open(path_to_file, encoding='utf-8') as file: soup = BeautifulSoup(file, 'html.parser', from_encoding="utf-8") return soup.get_text()
(This is just a simple function, it won't remove page specific data like headers and footers. But BeautifulSoup is more than capable of doing that if you know the structure of the data)
I would recommend using wikitextparser for wiki articles and pypdf for pdfs.
Chunking: If your cleaned texts are really long I'd recommend creating smaller chunks because the LLMs have limited context windows and giving an entire book instead of the relevant chapters could be a disadvantage.
After preparing your data you can upload it to the database of your choice (in this case Apache Solr).
The easiest way to setup Solr is with docker:
docker pull solr docker create --name solr_server -v /path/to/your/volume:/var/solr -p 8983:8983 solr docker start solr_server
Then open the terminal inside the container and run the following command:
bin/solr create -c <core_name> -s 2 -rf 2
This creates a core (with the provided core name) where you can upload your documents.
The warning for the previous command mentions: Data driven schema functionality is enabled by default
This means that the data structure will fit your data dynamically.
For the best performance you should create your scheme with Solr Cloud Schema Designer or create your own solrconfig.xml based on the documentation.
(To download Solar Cloud visit their deployment guides)
For this we'll use pysolr: pip install pysolr
Step 0: Check the connection
import pysolr core_name = 'my_core' solr_port = 8983 solr_url = f'http://localhost:{solr_port}/solr/{core_name}' solr = pysolr.Solr(solr_url, timeout=10) response = solr.ping() print(response) # If the response status is 'OK' you can move to the next steps
Step 1: Uploading the data
import os def upload_folder(folder_path, core_name): data = [] for filename in os.listdir(folder_path): # we will use the name of the file as an id name = filename.split('.')[0] file_path = os.path.join(folder_path, filename) with open(file_path, 'r', encoding='utf-8') as f: # reading the content of the file content = f.read() # saving the content to our data list data.append({ 'id': name, 'title': content.split('\n')[0], 'text': content }) # uploading all the data at once (from the data list) solr.add(data)) upload_folder('path/to/your/data', core_name)
Feel free to change the data structure to better fit your dataset.
Step 3: check your upload
Visit the web interface http://localhost
/solr/#/my_core/core-overview and check the number of documents you have.Or use python to validate:
results = solr.search('apple') for result in results: print(result['title'])
The next thing we have to implement is the communication with our LLM.
I chose a free software Ollama 0.6.2 (documentation) as a provider in which you can select popular open source models (e.g. Llama 3.3, DeepSeek-R1, Mistral, Gemma 3) and run them locally. The interface is similar to OpenAI's API so if you don't want to run the LLM locally I'd recommend using their services.
Step 1: Setting up Ollama with docker
docker pull ollama/ollama docker create --name ollama_docker --restart unless-stopped -v ./path/to/voolume:/root/.ollama -p 11434:11434 -e OLLAMA_KEEP_ALIVE=24h -e OLLAMA_HOST=0.0.0.0 ollama/ollama docker start ollama_docker # select a model here: https://ollama.com/library docker exec -it ollama_docker ollama run <model_name>
(For NVIDIA support check out the docker docs for Ollama)
Step 2: Install the ollama client
pip install ollama
Step 3: Create a wrapper for Solr for easier search
from pysolr import Solr class SolrHandler: def __init__(self, connection_str, top_n = 1): self.solr = Solr(connection_str, timeout=10) # search params self.params = { # fields returned 'fl': 'score, title, text', 'sort': 'score desc', # number of docs returned 'rows': str(top_n), 'tie': '0.1', 'defType': 'edismax', 'qf': 'title^2 text', 'pf': 'text^2', 'stopwords': 'true', } def search(self, query): query = query.strip() results = self.solr.search(query, **self.params) if len(results) == 0: return [] else: return results.docs
Step 4: Create a simple class for handling the LLM
import os from ollama import Client, Options class OllamaClient: def __init__(self, solr_handler, insertion_format = None, role = None): self.solr_handler = solr_handler default_insertion = "Answer the question based only on the context below: \nContext: {data} \nQuestion: {query}" self.insertion_format = insertion_format if insertion_format else default_insertion default_role = "You are an upbeat, encouraging tutor who helps students understand concepts by explaining ideas and asking students questions." self.role_prompt = role if role else default_role self.messages = [] # setting up Ollama self.client = Client('localhost:11434') # check if the model is running running = self.client.ps()['models'] self.model = '<your_model:version>' if sum(self.model in r['name'] for r in running) == 0: print(f"This model isn't running! Try `docker exec -it ollama_docker ollama run {self.model}`") def new_chat(self): self.messages = [ # setting the role for the LLM as a system message { 'role': 'system', 'content': self.role_prompt } ] def new_message(self, message): message = message.strip() results = self.solr_handler.search(message) if len(results) == 0: message_added = message else: # if we have any documents # we'll place the first one in the prompt as a data source # and ask the question message_added = self.insertion_format.format( data=results[0]['text'], query=message ) self.messages.append({ 'role': 'user', 'content': message_added }) # generating answer result = self.client.chat( model=self.model, messages=self.messages, ) self.messages.append({ 'role': 'assistant', 'content': result.message.content })
The source of the default insertion format is the IBM SuperKnowa repository.
To find more role prompts checkout Microsoft's prompts-for-edu repo
And you're done. Basically you can build any UI around this system and call it a RAG.
Based on the instructions above you can build your own system around this skeleton. The result shows that you've learned how the system works.
The system’s performance depends on the hardware, as larger language models require more powerful CPUs, GPUs, or RAM.
Additionally, this example didn't showcase the capabilities of Apache Solr, which could massively improve retrieval efficiency.
As you can see, this is just a start. There are many ways to go from here, so I wanted to list out some of the things I did with my project:
Based on another research I worked on, using LLMs to improve querying multilingual documents might improve search performance (so there is still room for further development).
If you feel stuck or just want reproduce my system checkout the GitHub repository
Happy Coding ❤!