In recent years, artificial intelligence (AI) has made significant breakthroughs in various areas of modern life. Presently, AI is revolutionizing the workforce by increasing efficiency, reducing costs, and solving complex problems across industries like healthcare, finance, education, e-commerce, and business. This breakthrough in AI, particularly through large language models (LLMs), will drive the Fourth Industrial Revolution (4IR). These large language models trained on vast amounts of data are essential in building intelligent agentic systems. Despite the strong capabilities of these models, however, LLMs often struggle to provide accurate, up-to-date information and can generate hallucinated or incorrect responses.
To remedy this deficiency in LLMs, we will build a multi-modal agent system with an enhanced Retrieval Augmented Generation (RAG) with diverse data sources such as URLs PDF, local PDF and URLs. Multi-modal agent system is a coordinated system of agents capable of handling tasks both independently and collaboratively to produce accurate results. This article explores how to build a multi-modal AI agent system for web search, stock analysis and cryptocurrency analysis using URLs PDF, URLs and PDF Retrieval Augmented Generation (RAG) system to improve the knowledge base and generate more accurate responses.
 AI generated image: Multi-modal agent (web search agent, stock agent and cryptocurrency agent)
AI generated image: Multi-modal agent (web search agent, stock agent and cryptocurrency agent)
A Retrieval Augmented Generation (RAG) system utilizes external data sources combined with LLMs to generate accurate, relevant responses. The RAG system uses retrieval techniques to generate updated information responses and reduce errors and hallucinations instead of relying on data training techniques, unlike traditional LLMs that rely solely on trained data. Some benefits of RAG systems include enhanced privacy, especially for sensitive and proprietary information, improved knowledge base, and increased trustworthiness by avoiding outdated responses. A well-designed RAG system with quality embeddings is crucial for providing accurate, and reliable responses. The RAG system must ensure that the chunk size is well optimized to avoid irrelevant or incomplete information.
To build a reliable AI agent for specialized tasks, it is crucial for us to select the appropriate AI models and tools that can handle the task efficiently and effectively. For this system, we will utilize and integrate the following tools for building multi-modal AI agents:
Phidata — Phidata is a powerful and versatile open-source framework for building and monitoring agentic systems. It is useful for multi-agent orchestration or building multi-modal agents.
Yahoo Finance Tool — for stock analysis and cryptocurrency analysis. YFinanceTool enables an Agent to access stock data and cryptocurrency data from Yahoo Finance.
Tavily and DuckDuckGo — both are for web search detailed information. TavilyTool enables an AI Agent to search the web using the Tavily API while DuckDuckGo enables an AI Agent to search the web with the command below.
pip install -U duckduckgo-search
PGVector— PGVector extension of Postgres SQL creates a vector database for vector embeddings and retrieval for RAG system. Other examples of vector databases include Pinecone DB, Chroma DB etc.
These tools are integrated for the complete set-up of the following agents:
These agents are powered by large language model “gpt-4o”. The model requires an API key for sufficient access and authentication. The “gpt-4o” (omni) model is advanced AI model with multimodal capabilities, strong memory, enhanced reasoning and fast in handling and processing texts, images and audio/video input tasks for a lower cost.
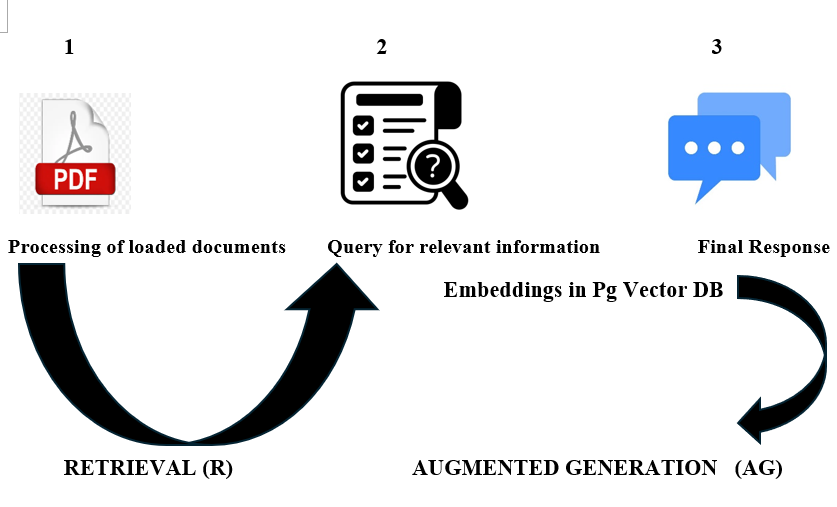
Figure 1: The Retrieval Augmented Generation System (RAG)
Document Loading and Embedding: The RAG system processes loaded documents from external sources such as PDFs or URLs etc. The system converts text into embeddings — numerical vectors that represent text in a way that allows for fast similarity searches and retrieval.
Similarity Search: The RAG system uses techniques such as Cosine Similarity to search for the relevant portions of text (embeddings) stored in the vector database based on a user’s query. Embedding involves the conversion of texts to numerical vectors for similarity, clustering and classification tasks. Example PGVector DB, other vector databases such as Pinecone DB, Astra DB, Chroma DB etc., are used to store and search for vectors using Cosine Similarity. Cosine Similarity and text embeddings are explained in detail (see fig.2)
Response Generation: Finally, the RAG system will craft the specific response based on the prompt. Augmented generation utilizes the capabilities of LLMs reasoning to generate highly accurate and relevant responses based on the retrieved data. If the query is outside the system’s knowledge base, the RAG system will refuse to answer rather than hallucinating it, thereby improving its trustworthiness.
Due to the token size limits for the LLMs, and to optimize efficiency, the large documents and other knowledge base are processed as smaller chunks to ensure faster, more relevant retrieval of information. The size of these chunks is crucial because if a chunk is too large it may include irrelevant information, while too small chunks may result in incomplete data for the LLM to generate a meaningful response.
Text embeddings are representation of documents texts and words as numerical vectors. The texts are converted to numerical format as text embeddings in a way that the AI system can quickly process. These embeddings allow for similarity searches, where similar texts of documents are grouped together with assigned values. The embeddings vectors represent huge lists of numbers in a multi-dimensional space and the Cosine Similarity measures the closeness of vectors in multi-dimensional space.
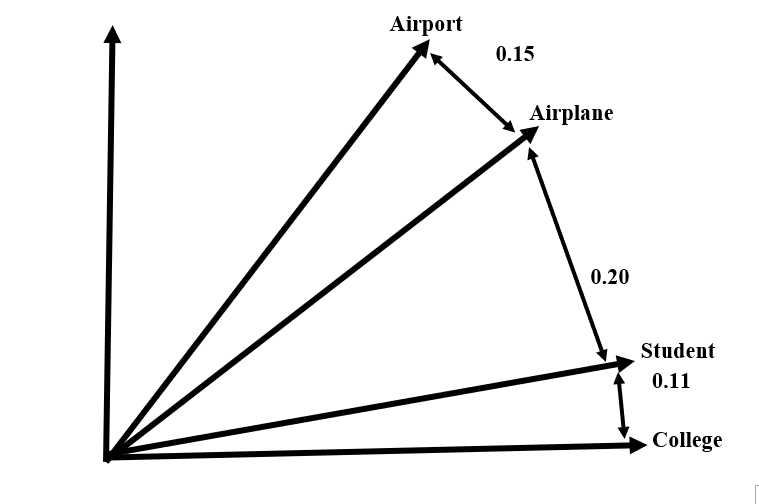
Figure 2: Illustration of the Cosine Similarity
For example, consider the Cosine Similarity between the terms “airport” and “airplane” with similarity score of 0.15. It shows that they are closer compared to the Cosine Similarity value between “airplane” and “student” which is 0.20. The vectors of similar terms (like “student” and “college”) are the closest with similarity score of 0.11, making it easier for the RAG system to retrieve and group relevant information together. The similarity score of 0.11 between “student” and “college” shows that they are highly relevant in academic context, followed by “airplane” and “airport "which indicates that they are highly relevant in aviation context.
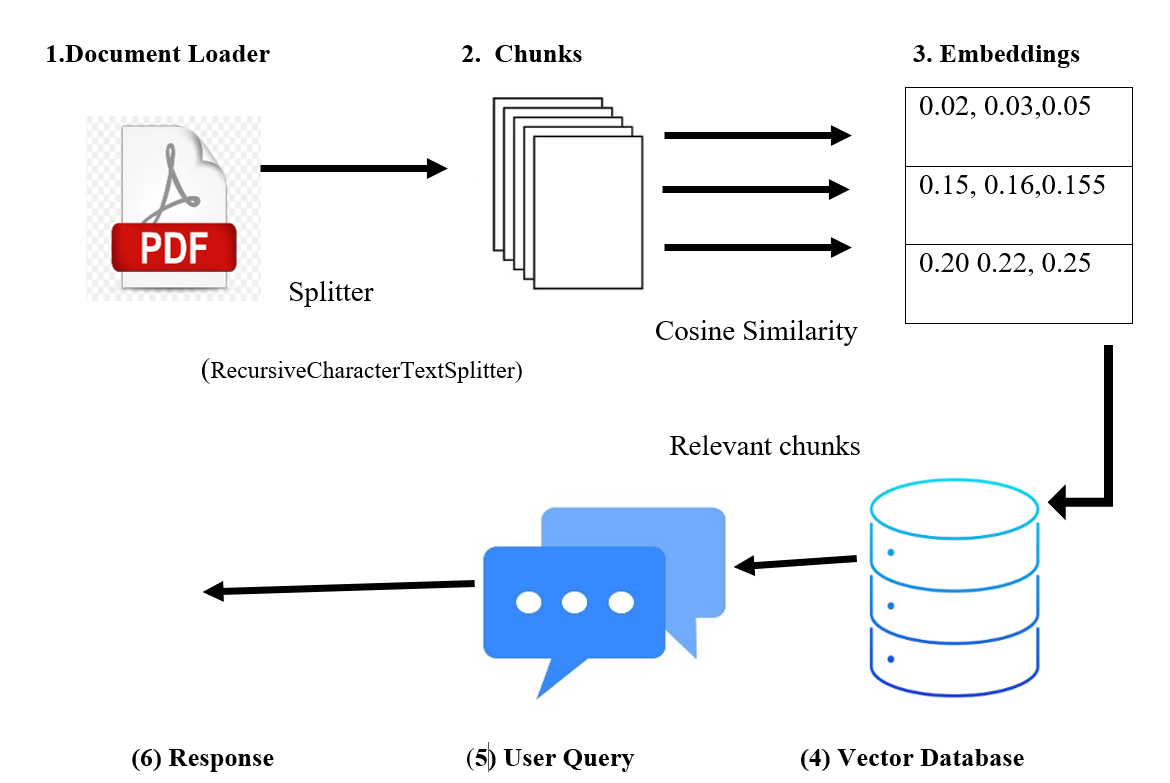
Figure 3 : The schematic illustration of step-by-step process of RAG from data source loading such as PDF document loading, text splitting, chunking, embedding, vector database storage, processing of queries and response generation
When a user submits a query, the query is converted vector embedding, the vector database then scans through similar embedding vectors stored in the vector database based on the Cosine Similarity and the most relevant or corresponding information is retrieved as the output of the user query or response. The relevant chunks are fed into LLMs such as ChatGPT to generate relevant response.
Getting Started and Configure Your Environment in Visual Studio Code (VS code)
# Create a new virtual environment for the project in Python3 python -m venv myenv # Activate the virtual environment in Windows with the command below myenv\Scripts\activate # Install all the dependencies required for the project inside the activated # virtual environment with the command below: pip install -r requirements.txt # The dependencies below are saved as "requirements.txt" in the project folder # Dependencies: duckduckgo-search fastapi openai packaging phidata python-dotenv pgvector psycopg[binary] python-multipart pypdf bs4 sqlalchemy tavily-python uvicorn yfinance
4.Get the API keys from providers to access an LLM. To get the API keys from providers such as OpenAI, Phidata and Tavily.
# Visit the following websites below, login and subscribe to generate API keys: # https://platform.openai.com/settings/organization/api-keys # https://www.phidata.app/playground/chat # https://app.tavily.com/home #The API keys are saved as .env in the same location inside the project folder # For security reasons, the keys are shown as "xxxxxxxxxxxxxxxxx" here OPENAI_API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" PHI_API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" TAVILY_API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
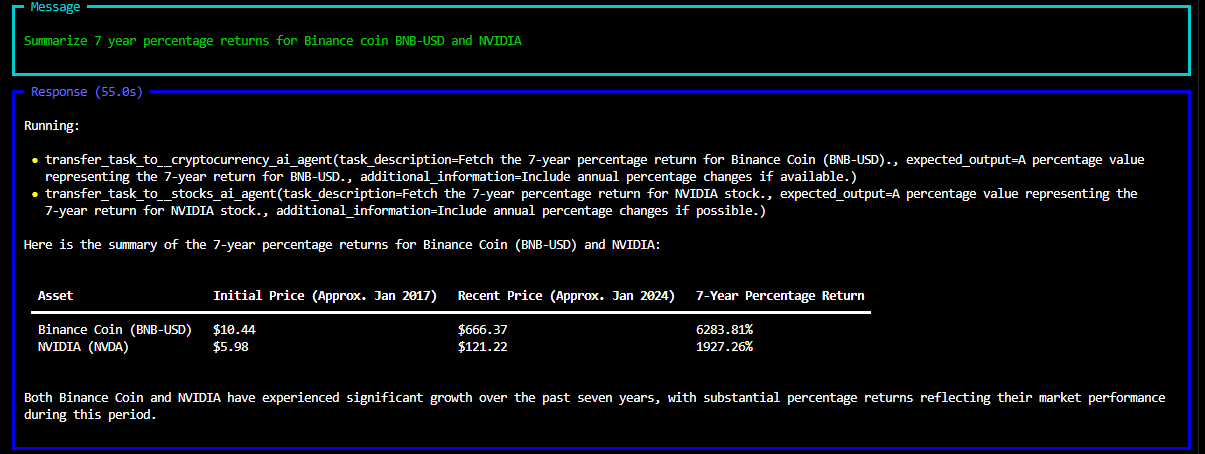
# Install all the necessary libraries and tools and save the file as stock_crypto_agent.py from phi.agent import Agent from phi.model.openai import OpenAIChat from phi.tools.tavily import TavilyTools from phi.tools.duckduckgo import DuckDuckGo from phi.tools.yfinance import YFinanceTools from tavily import TavilyClient # Step 1. Instantiating your TavilyClient tavily_client = TavilyClient(api_key="TAVILY_API_KEY") from dotenv import load_dotenv import os # Loading a virtual environment with all the dependencies load_dotenv() os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY") #Create all the agents for the project ## Search Web Agent search_web_agent = Agent( name= 'Search Web Agent', role= 'Search the web for detailed information', model=OpenAIChat(id="gpt-4o"), tools=[DuckDuckGo(),TavilyTools()], instructions=['Always include sources'], show_tool_calls=True, markdown=True, ) ## Conventional/ Traditional Stocks Agent stock_agent = Agent( name= " Stocks AI Agent", model=OpenAIChat(id="gpt-4o"), tools=[YFinanceTools(stock_price=True, analyst_recommendations=True,company_news=True,historical_prices=True,technical_indicators=True)], show_tool_calls=True, description="You are an investment stock analyst that researches stock prices, analyst recommendations, and stock fundamentals.", instructions=["Use tables to display the data"], markdown=True, ) ## Cryptocurrency AI Agent crypto_agent = Agent( name= " Cryptocurrency AI Agent", model=OpenAIChat(id="gpt-4o"), tools=[YFinanceTools(stock_price=True, analyst_recommendations=True,company_news=True,historical_prices=True,technical_indicators=True)], show_tool_calls=True, description="You are an investment cryptocurrency analyst that researches cryptocurrency prices, analyst recommendations,historical_prices and cryptocurrency fundamentals.", instructions=["Use tables to display the data","Use reliable cryptocurrency website to get the latest data"], markdown=True, ) ## Multi AI Agent that coordinates and integrates the functionalities of the three agents (web search agent, stock and cryptocurrency agent. multi_ai_agent = Agent( team=[search_web_agent,stock_agent,crypto_agent], model=OpenAIChat(id="gpt-4o"), instructions=['Always include sources','Use table to display data'], show_tool_calls=True, markdown=True, ) multi_ai_agent.print_response("Summarize 7 year percentage returns for Binance coin BNB-USD and NVIDIA",stream=True)
python stock_crypto_agent.py
The terminal output:
import openai import phi.api from phi.agent import Agent from phi.model.openai import OpenAIChat from phi.tools.tavily import TavilyTools from phi.tools.duckduckgo import DuckDuckGo from phi.tools.yfinance import YFinanceTools from tavily import TavilyClient from dotenv import load_dotenv # Set the Phidata Playground for interaction of the agents import phi import os from phi.playground import Playground,serve_playground_app # Load the environment variables load_dotenv() # Playground authentication key to connect to the endpoint in localhost phi.api = os.getenv("PHI_API_KEY") ## Search Web Agent for searching the internet for information ## Search Web Agent search_web_agent = Agent( name= 'Search Web Agent', role= 'Search the web for detailed information', model=OpenAIChat(id="gpt-4o"), tools=[DuckDuckGo(),TavilyTools()], instructions=['Always include sources'], show_tool_calls=True, markdown=True, ) ## Conventional/ Traditional Stocks Agent stock_agent = Agent( name= " Stocks AI Agent", model=OpenAIChat(id="gpt-4o"), tools=[YFinanceTools(stock_price=True, analyst_recommendations=True,company_news=True,historical_prices=True,technical_indicators=True)], show_tool_calls=True, description="You are an investment stock analyst that researches stock prices, analyst recommendations, and stock fundamentals.", instructions=["Use tables to display the data"], markdown=True, ) ## Cryptocurrency AI Agent crypto_agent = Agent( name= " Cryptocurrency AI Agent", model=OpenAIChat(id="gpt-4o"), tools=[YFinanceTools(stock_price=True, analyst_recommendations=True,company_news=True,historical_prices=True,technical_indicators=True)], show_tool_calls=True, description="You are an investment cryptocurrency analyst that researches cryptocurrency prices, analyst recommendations,historical_prices and cryptocurrency fundamentals.", instructions=["Use tables to display the data","Use reliable cryptocurrency website to get the latest data"], markdown=True, ) my_app=Playground(agents=[search_web_agent,stock_agent,crypto_agent]).get_app() if __name__=="__main__": serve_playground_app("playground:my_app",reload=True)
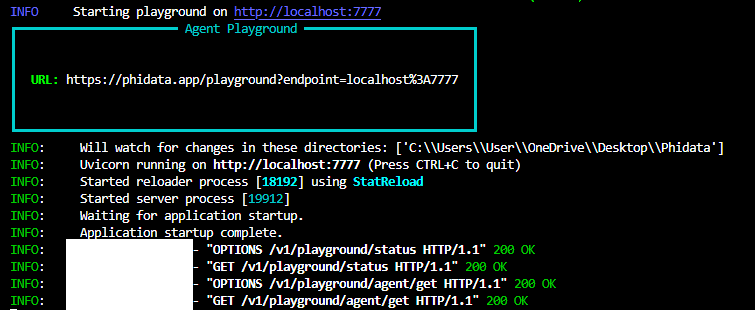
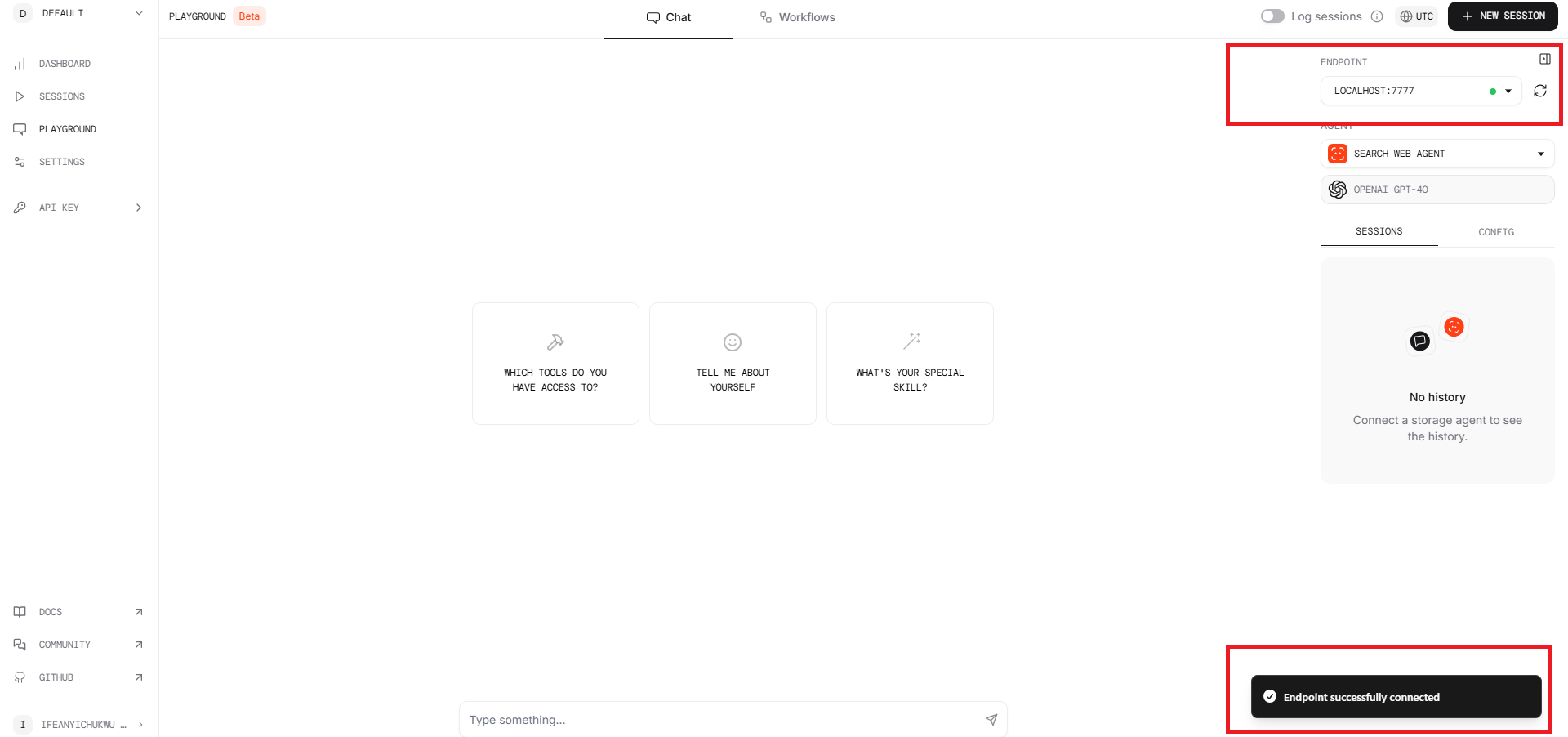
8.Run the code below to execute the playground.py file above and connect to Phidata dashboard.
python playground.py
The terminal output:
.png?Expires=1780103604&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=vp2XdCCD~iCAGZGfFOH6Xe4ec0eVudo8lNJqNENxwW6ZAQmV4Ja9QlnKl-PEupZoOqU~hiATnc7TsOXXREaRl2eOTODOC6697DTBSxLJemi9XDnYQvxH8xVfms9nZSp4jB54O7hBFXlNchY5PHgyMXPZ8PayATDrmei45viL~bP~jLMbKFTLLCLu6k31p5uWD3jHuOtpjGdiMxG37ukp~61gz6l9jOKhNGekhwagJRxf~R7N0YMMjh7YfztmzIykOIZKB6xaxytqEawED1BmCdIKIrOT7eSFmJBG0nqmCHQEm9KooVrOaj93Smzi3PZ~mkqspOCoTgJiwUnAmgg-KA__)
.png?Expires=1780103604&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=LWoe6DlbvXs9EjDKtNdiRNMKXm5U8unA9oheBOLsoYxxcAd0hNd-namw7ltBbNNdYC8-2jVmAgTOdzxg1F~hXVRsmsO~Gq3agUHLAFZODdDz9ZqsG-3CfPl2E-ytSfO7rRL2Qq3MuBtzjjhCqHweUHZZ4L~iPbwfrUTxAzpWtBHVqlQ2mx72Us6A2wpsQaw4qwFWrfCG3VzsQ~Y2Fppq3N4OUOww1gDjqfh3CJPXenUEY9HBePfqaYizFiLEwJYuy6ndplX~0EWCjTPiTc6I3MtCKsggGMCTgvFMm9A9E~PsJSkQv6lsXRwKOV7JG7IBr1bxKp1fAFySAknV5l1VRg__)
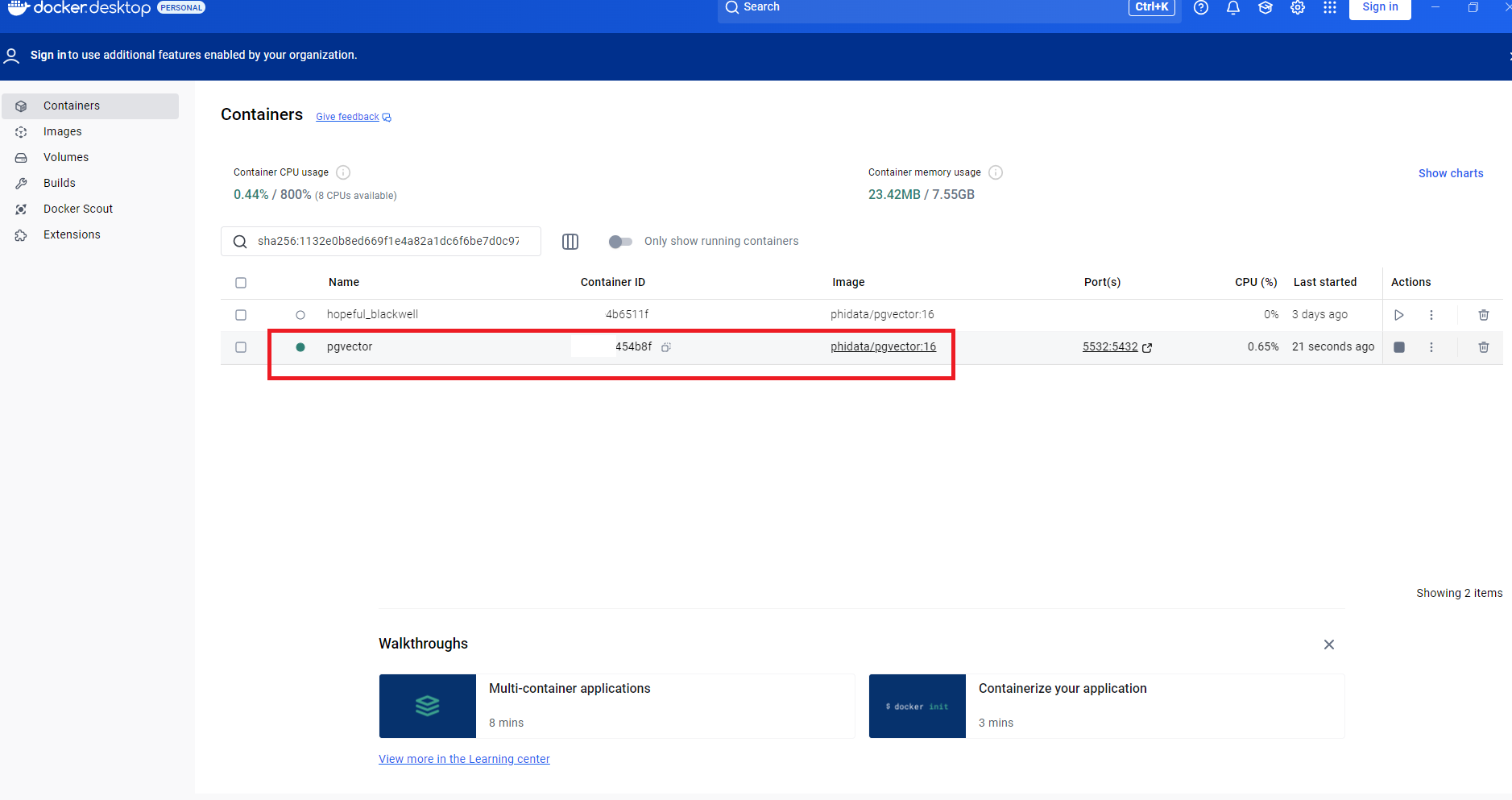
docker run -d \ -e POSTGRES_DB=ai \ -e POSTGRES_USER=ai \ -e POSTGRES_PASSWORD=ai \ -e PGDATA=/var/lib/postgresql/data/pgdata \ -v pgvolume:/var/lib/postgresql/data \ -p 5532:5432 \ --name pgvector \ phidata/pgvector:16
The Docker Container output:
import typer from typing import List,Optional from phi.assistant import Assistant from phi.storage.assistant.postgres import PgAssistantStorage from phi.knowledge.pdf import PDFUrlKnowledgeBase from phi.knowledge.combined import CombinedKnowledgeBase from phi.knowledge.website import WebsiteKnowledgeBase from phi.vectordb.pgvector import PgVector from phi.knowledge.pdf import PDFKnowledgeBase, PDFReader import os from dotenv import load_dotenv load_dotenv() os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY") db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai" # Create a Combined Knowledge Base from PDF urls , website urls and local drive PDF # PDF url links below are for demonstration and teaching purposes only # Create first knowledge base for PDF urls with PG vector database for embeddings and retrieval url_pdf_knowledge_base = PDFUrlKnowledgeBase( urls=["https://s3.amazonaws.com/static.bitwiseinvestments.com/Research/Bitwise-The-Year-Ahead-10-Crypto-Predictions-for-2024.pdf", "https://www.flowtraders.com/media/i33f1ipp/crypto-etp-report.pdf", "https://25733253.fs1.hubspotusercontent-eu1.net/hubfs/25733253/Focus-Crypto%20Outlook%202024-09.01.24.pdf", ], vector_db=PgVector(table_name ="urlpdf_crypto_stock",db_url=db_url,), ) # Create another knowledge base for website urls with PG vector database for embeddings and retrieval website_knowledge_base = WebsiteKnowledgeBase( urls=["https://coinmarketcap.com/", "https://finance.yahoo.com/"], # Table name: ai.website_documents vector_db=PgVector( table_name="website_documents", db_url=db_url), ) # Create another knowledge base for PDF in local drive with PG vector database for embeddings and retrieval local_pdf_knowledge_base = PDFKnowledgeBase( path= r"C:\Users\User\OneDrive\Desktop\Phidata\ADTA5230.pdf", # The exact local path in your system # Table name: ai.local_pdf_documents vector_db=PgVector( table_name="local_pdf_documents", db_url=db_url, ), reader=PDFReader(chunk=True), ) # Combine the 3 different knowledge base for enhanced RAG System knowledge_base = CombinedKnowledgeBase( sources=[ url_pdf_knowledge_base, website_knowledge_base, local_pdf_knowledge_base, ], vector_db=PgVector( table_name="combined_documents", db_url=db_url, ), ) # Create a storage for the vectors storage = PgAssistantStorage(table_name="combined_assistant",db_url=db_url) # Create a combined assistant function to handle the vector embeddings from combined knowledge base and method of storage def combined_assistant(new : bool = False,user : str = "user"): run_id: Optional[str] = None if not new: existing_run_ids : List[str] = storage.get_all_run_ids(user) if len(existing_run_ids) > 0: run_id = existing_run_ids[0] assistant = Assistant( run_id=run_id, user_id=user, knowledge_base=knowledge_base, storage=storage, show_tool_calls=True, search_knowledge=True, read_chat_history=True, ) if run_id is None: run_id = assistant.run_id print(f"Started Run : {run_id}\n") else: print(f"Continue Running : {run_id}\n") assistant.cli_app(markdown=True) if __name__== "__main__": typer.run(combined_assistant)
from phi.agent import Agent from combined_knowledge import knowledge_base # Import combined_knowledge import typer from typing import List,Optional from phi.assistant import Assistant from phi.storage.assistant.postgres import PgAssistantStorage import os from dotenv import load_dotenv load_dotenv() os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY") db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai" storage = PgAssistantStorage(table_name="combined_assistant",db_url=db_url) agent = Agent( knowledge=knowledge_base, search_knowledge=True, ) agent.knowledge.load(recreate=False) def combined_assistant(new : bool = False,user : str = "user"): run_id: Optional[str] = None if not new: existing_run_ids : List[str] = storage.get_all_run_ids(user) if len(existing_run_ids) > 0: run_id = existing_run_ids[0] assistant = Assistant( run_id=run_id, user_id=user, knowledge_base=knowledge_base, storage=storage, show_tool_calls=True, search_knowledge=True, read_chat_history=True, ) if run_id is None: run_id = assistant.run_id print(f"Started Run : {run_id}\n") else: print(f"Continue Running : {run_id}\n") assistant.cli_app(markdown=True) if __name__== "__main__": typer.run(combined_assistant) # Typer to execute queries
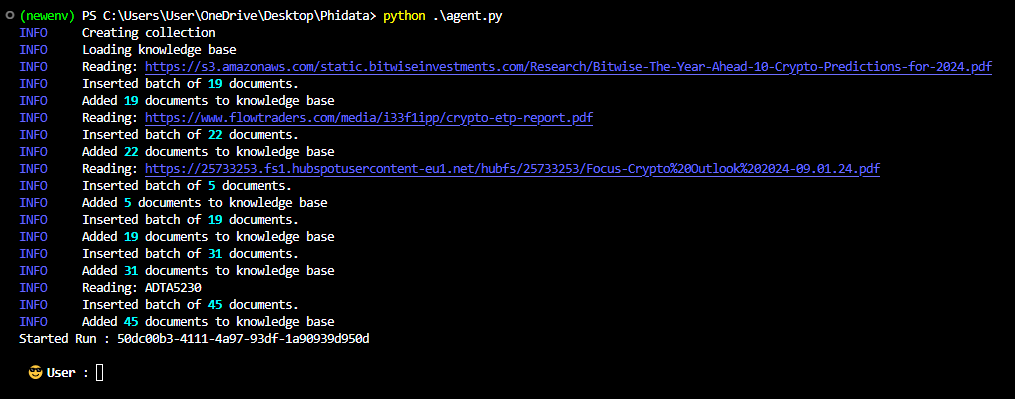
13.Run the code below to execute the agent.py file above to load the knowledge bases with our PDFs, URLs PDFs and website URLs and then interact with the knowledge bases.
python agent.py
The terminal output:
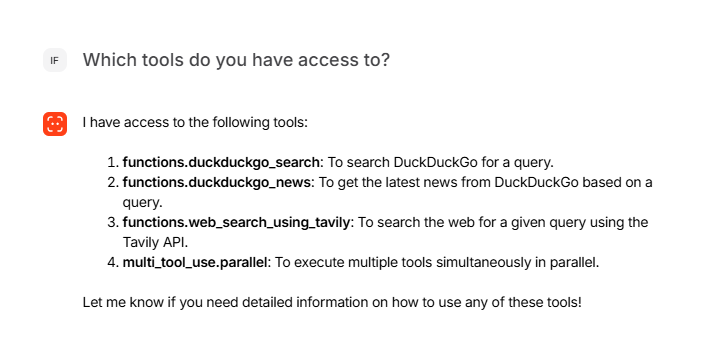
The multi-agent queries and responses from the knowledge base stored in vector database of RAG system are shown below:
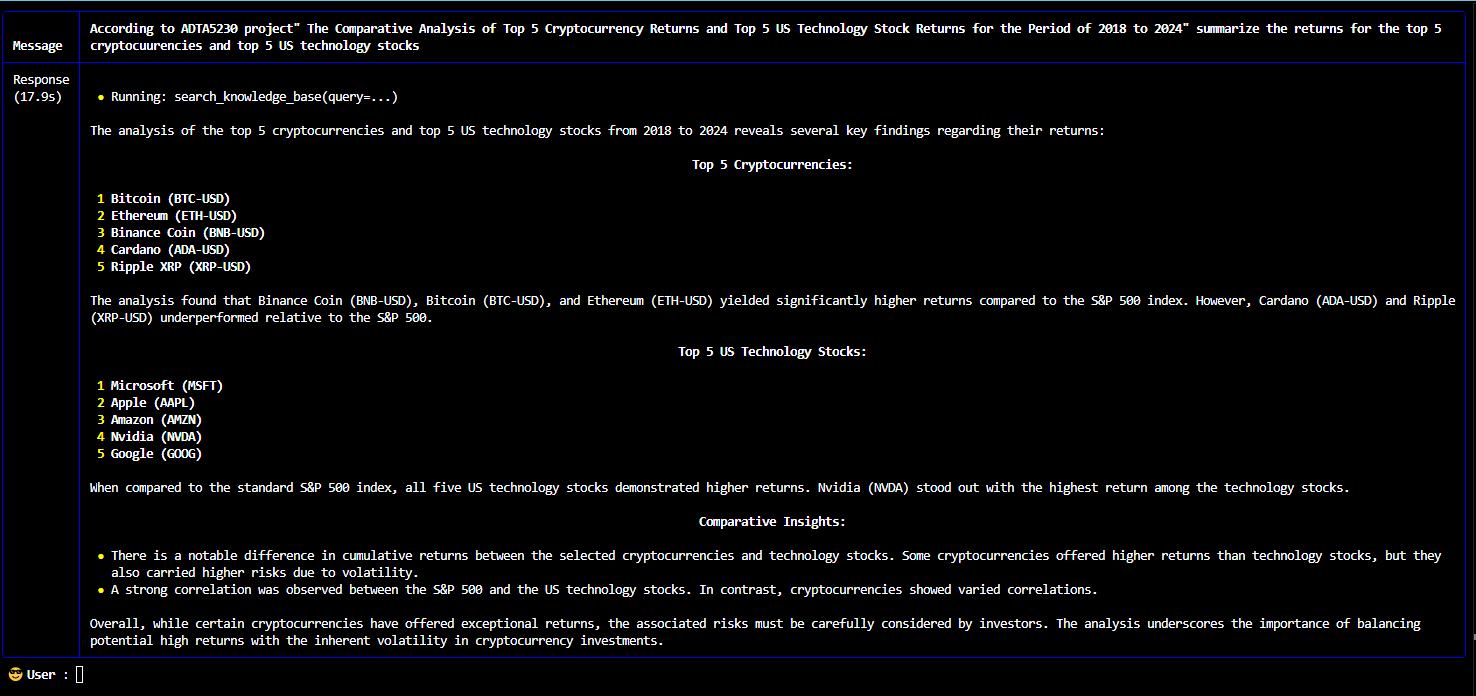
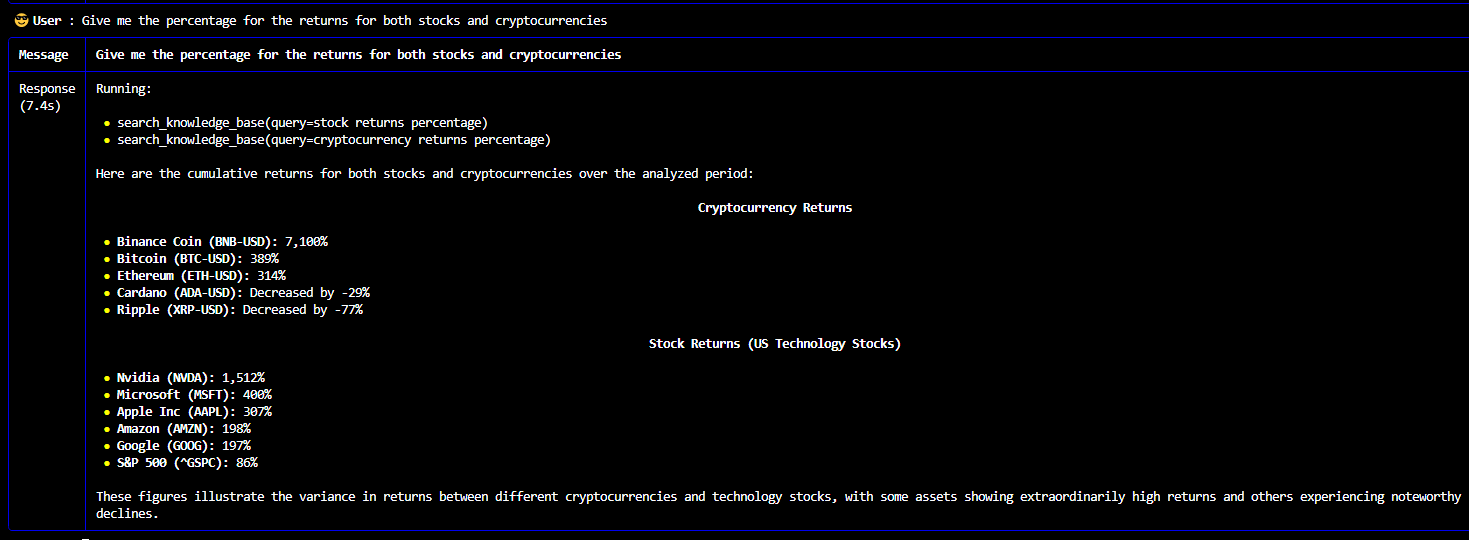

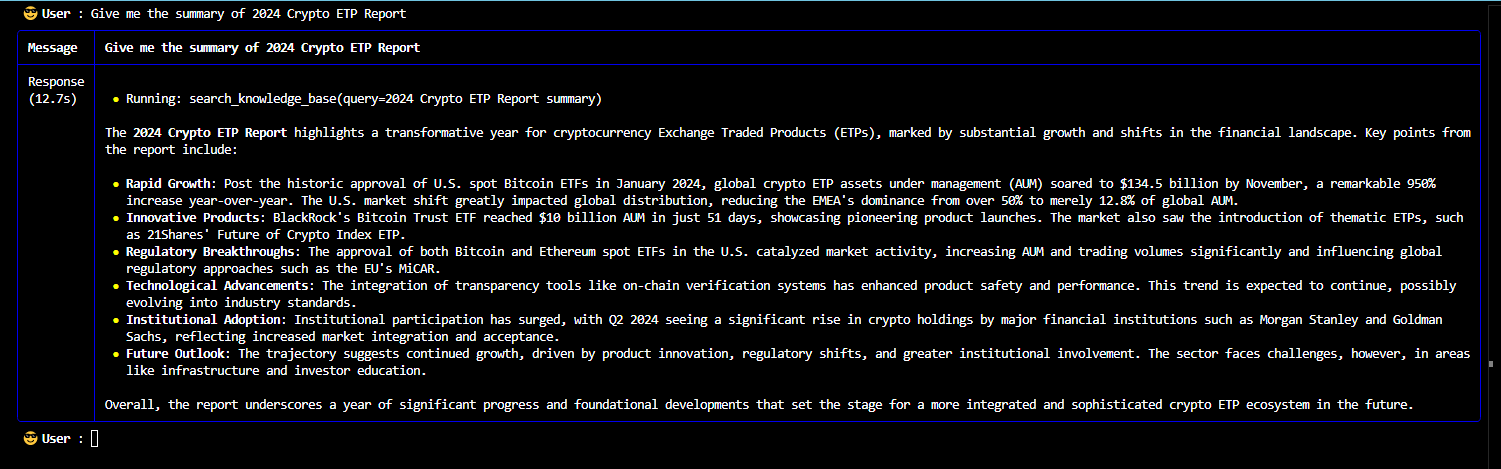
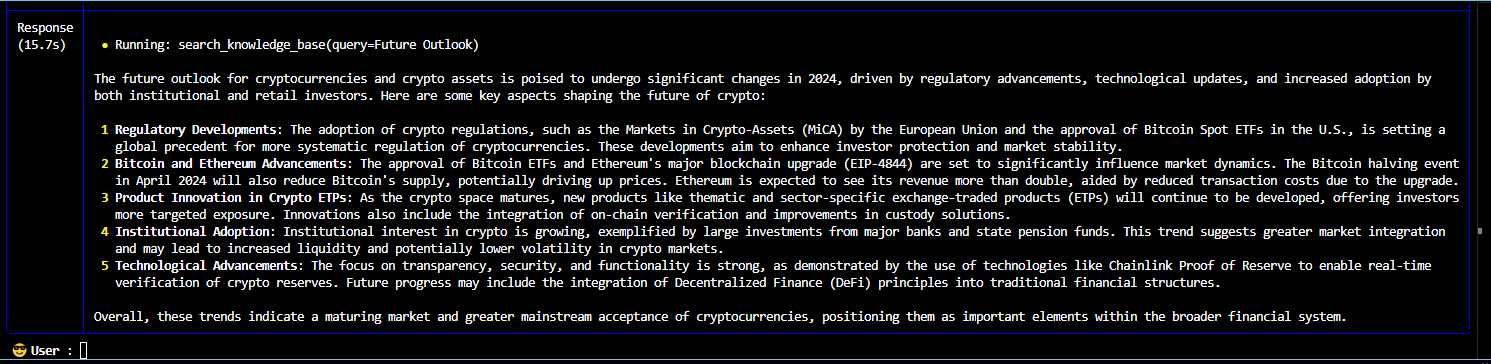
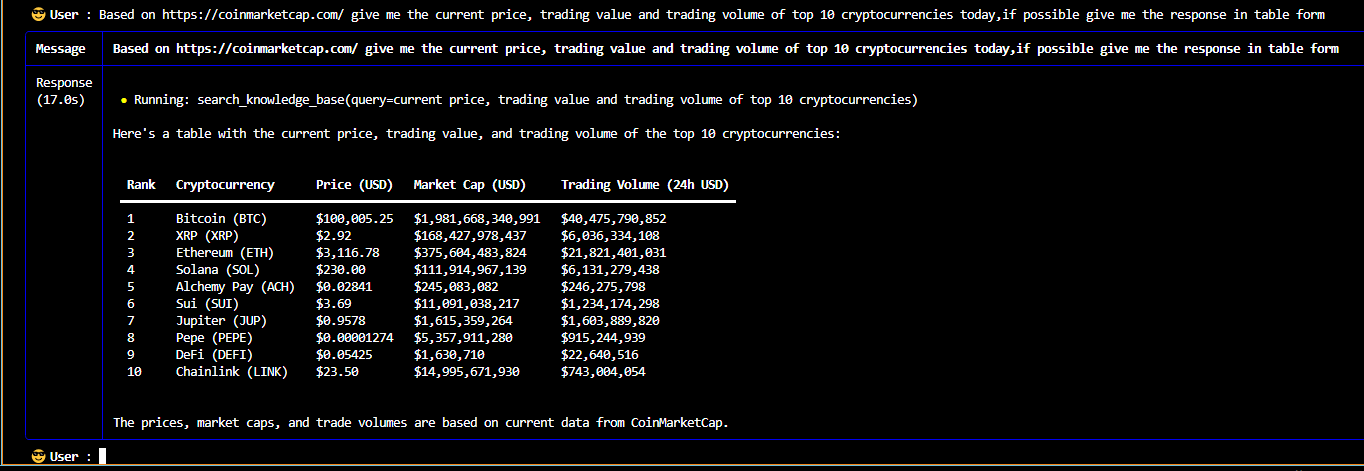
A multi-modal AI agent system for web search, stock analysis and cryptocurrency analysis powered by an enhanced Retrieval Augmented Generation (RAG) system with an integration of large language models offers more accurate, reliable, up-to-date and relevant responses while minimizing the risk of hallucinations.
GitHub Repository for source code.
Documentation for Phidata
