BucaraSet: Object detection and depth estimation for urban environments in Colombia.
Table of contents
Overview
Object detection and depth estimation in urban environments present unique challenges due to changing lighting conditions, occlusions and object variability. This work addresses these challenges through the implementation of foundational models leveraging computer vision and artificial intelligence, in addition to the use of an RGB dataset of images and videos created in different scenarios in the city of Bucaramanga.

Creation of the dataset (Bucaraset)
The input data are images and videos of scenarios where Bucaramanga traffic circulates, which are El Mesón De Los Búcaros Park, Floridablanca Highway and parking lots of the Universidad Industrial de Santander and Barrio La Universidad.
BucaraSet was created in 4 urban environments of Bucaramanga, it contains 403 scenes and 14 videos.
Training of models
Object Detection
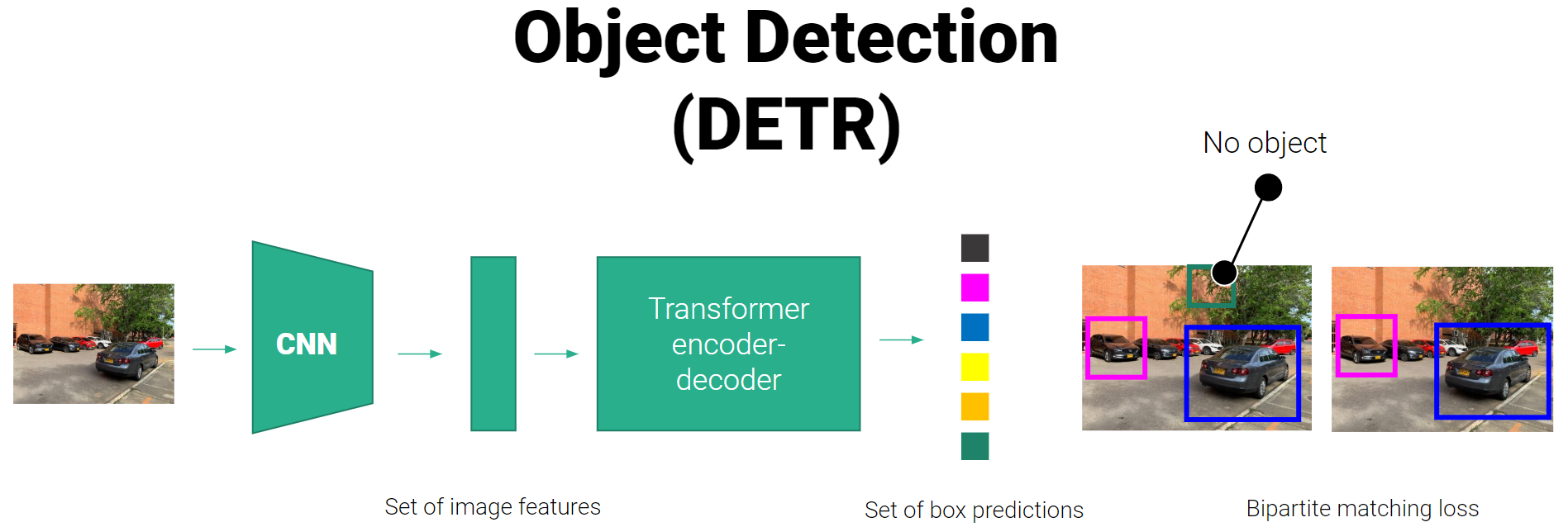
The DETR model was proposed in End-to-End Object Detection with Transformers by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. DETR consists of a convolutional backbone followed by an encoder-decoder Transformer which can be trained end-to-end for object detection. It greatly simplifies a lot of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use things like region proposals, non-maximum suppression procedure and anchor generation. Moreover, DETR can also be naturally extended to perform panoptic segmentation, by simply adding a mask head on top of the decoder outputs.
The pre-trained model was used to generate inference from the data, with the previously assigned labels and an adjustment of the configuration parameters by filtering the confidence threshold, effectively obtaining object detection.
Depth Estimation
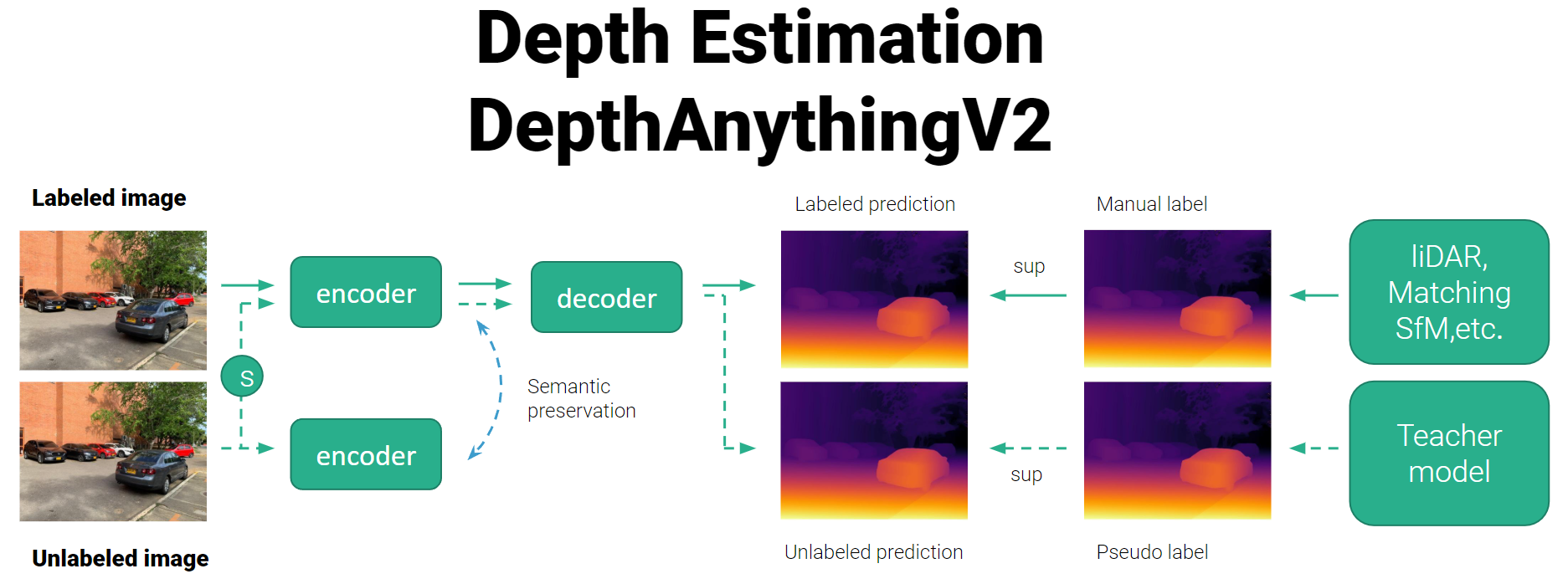
Depth Anything V2 is trained from 595K synthetic labeled images and 62M+ real unlabeled images, providing the most capable monocular depth estimation (MDE) model.
The pre-trained model was used to generate inference from the data, with an adjustment of the configuration parameters where the generated depth maps were interpolated to match the original dimensions of the images and also avoided the calculation of gradients thus optimizing memory usage and speed.
Results

Estimation of the distance of detected objects
To calculate the actual distances in meters, the camera parameters, including focal length and sensor size, were used, along with a specific formula that converts the depth values obtained by the model into physical distances.
