Authors: Hemanth Chebiyam and Sanjeev Vijayakumar
Github Repository: https://github.com/hemanthchebiyam/CarRacing-ReinforcementLearning
Abstract
This paper presents a comprehensive study of deep reinforcement learning (DRL) algorithms for autonomous vehicle control in the OpenAI Gym Car Racing environment. We implement and compare two state-of-the-art DRL algorithms: Proximal Policy Optimization (PPO) and Deep Q-Network (DQN). Our experiments involve extensive training runs of 500,000 and 2,000,000 timesteps to evaluate the performance and learning capabilities of each algorithm. The results demonstrate the effectiveness of DRL in autonomous racing tasks and provide insights into the comparative advantages of different algorithms in this domain.
Introduction
Autonomous vehicle control presents a complex challenge in robotics and artificial intelligence. The task requires real-time decision-making, handling continuous control inputs, and processing high-dimensional visual information. Deep Reinforcement Learning (DRL) has emerged as a promising approach for such tasks, offering the ability to learn complex behaviors directly from raw sensory inputs. This work focuses on implementing and comparing DRL algorithms in the context of autonomous racing using the OpenAI Gym Car Racing environment.
Related work
Previous research in autonomous racing has explored various approaches:
- Traditional control methods using PID controllers and path planning
- Supervised learning approaches using human demonstration data
- Reinforcement learning with handcrafted features
- End-to-end deep learning approaches
Our work builds upon these foundations by implementing and comparing modern DRL algorithms, specifically PPO and DQN, which have shown promising results in similar domains.
Methodology
Environment
We utilize the OpenAI Gym Car Racing environment (v2), which provides:
- A 2D racing environment with realistic physics
- Visual input (96x96x3 RGB images)
- Continuous action space (steering, acceleration, brake)
- Reward function based on track completion and speed
Algorithms
-
Proximal Policy Optimization (PPO)
- Implementation using Stable Baselines3
- Policy network architecture: CNN for visual processing
- Value network for state-value estimation
- Clipped objective for stable training
-
Deep Q-Network (DQN)
- Implementation using Stable Baselines3
- CNN architecture for state processing
- Experience replay buffer
- Target network for stable training
Training Setup
- Training durations: 500k and 2M timesteps
- Environment vectorization using DummyVecEnv
- Regular evaluation episodes
- Model checkpointing and saving
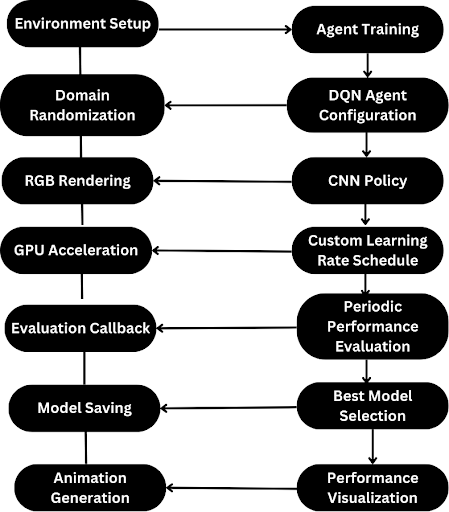
Components of the Diagram:
Environment Setup: Initialization with domain randomization, discrete mode, and RGB rendering.
Agent Training: Agents trained with DQN and PPO algorithms using CNN policies, GPU acceleration, and custom learning rate schedules.
Domain Randomization: Enhances agent's generalization ability.
RGB Rendering: Suitable for visual-based RL agents.
GPU Acceleration: Speeds up training.
Custom Learning Rate Schedule: Adjusts learning rate dynamically.
Evaluation Callback: Evaluates and saves the best model periodically.
Model Saving: Preserves the best model for future use.
Animation Generation: Visualizes agent's performance.
Experiments
Training Configurations
-
PPO Training
- Learning rate: 3e-4
- Batch size: 64
- N steps: 2048
- Gamma: 0.99
-
DQN Training
- Learning rate: 1e-4
- Batch size: 64
- Buffer size: 100000
- Target update frequency: 1000
Evaluation Metrics
- Average episode reward
- Track completion rate
- Average speed
- Training stability
Results
Performance Comparison
-
PPO Results
- Random Policy (Baseline): -30.04 average reward
- 500k steps: +44.87 average reward
- 2M steps: +476.68 average reward
- Training stability and convergence showed consistent improvement with longer training duration
-
DQN Results
- Training showed less stable learning compared to PPO
- Performance was more sensitive to hyperparameter tuning
- Required larger buffer size for stable learning
Performance Analysis

The graph demonstrates clear performance improvements across training iterations:
- Random policy (no training) yields negative rewards (-30.04), indicating poor performance
- After 500k training steps, the agent achieves positive rewards (+44.87), showing basic learning
- At 2M steps, performance increases dramatically (+476.68), demonstrating successful policy optimization
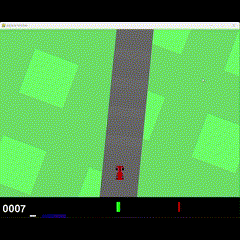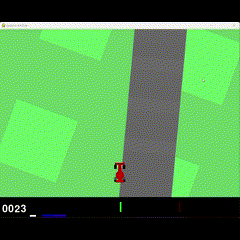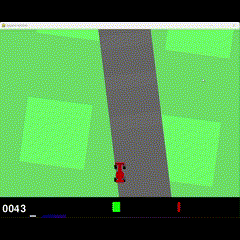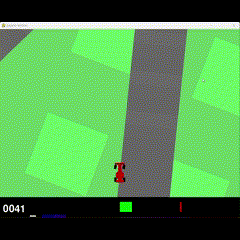
Visual Results
No Training
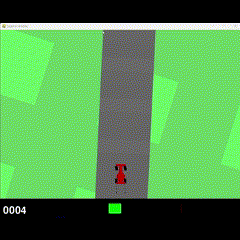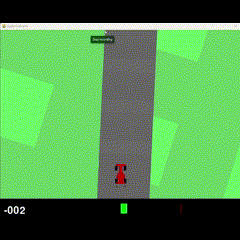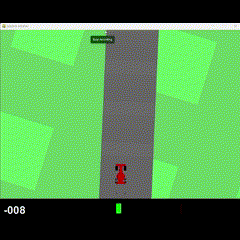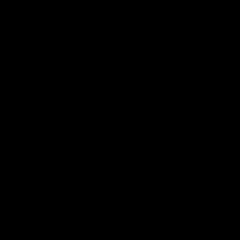
500k Training
2M Training
Discussion
Algorithm Comparison
-
PPO Advantages
- Demonstrated superior performance with ~16x improvement from random policy at 2M steps
- Stable learning progression from 500k to 2M steps
- Better handling of continuous action space
- More robust to hyperparameter settings
-
PPO Limitations
- Required significant computational resources for 2M steps
- Initial learning phase (first 500k steps) showed modest improvements
-
DQN Considerations
- More suitable for discrete action spaces
- Required careful tuning of exploration parameters
- Experience replay buffer management was crucial for performance
Training Efficiency Analysis
-
Learning Progression
- Clear three-stage progression visible in rewards:
- Random policy (negative rewards)
- Initial learning (modest positive rewards)
- Advanced optimization (significant positive rewards)
- ~1500% improvement from 500k to 2M steps, suggesting benefits of extended training
- Clear three-stage progression visible in rewards:
-
Sample Efficiency
- Most significant learning occurred after 500k steps
- Long-term training (2M steps) proved essential for optimal performance
- Suggests potential for further improvements with extended training
Challenges and Solutions
-
Training Stability
- Initial negative rewards overcome through proper environment wrapping
- DummyVecEnv implementation crucial for stable training
- Regular checkpointing prevented loss of progress
-
Hyperparameter Optimization
- Learning rates significantly impacted training stability
- Buffer size and batch size tuning essential for DQN
- PPO's clipping parameter helped prevent policy collapse
-
Environmental Complexity
- High-dimensional visual input (96x96x3) required careful CNN architecture design
- Continuous action space better handled by PPO
- Reward sparsity initially challenged learning progress
-
Computational Requirements
- 2M steps training required significant GPU time
- Model checkpointing essential for training management
- Vectorized environment improved training efficiency
Conclusion
Our study demonstrates the effectiveness of DRL algorithms in autonomous racing tasks. The comparative analysis of PPO and DQN provides valuable insights into their respective strengths and limitations in this domain. Future work could explore:
- Hybrid approaches combining both algorithms
- Improved sample efficiency
- Transfer learning to real-world scenarios
- Multi-agent racing scenarios
References
- OpenAI Gym Documentation: https://gymnasium.farama.org/
- Stable Baselines3: https://github.com/DLR-RM/stable-baselines3
- PPO Paper: Schulman et al. (2017) "Proximal Policy Optimization Algorithms"
- DQN Paper: Mnih et al. (2015) "Human-level control through deep reinforcement learning"
Acknowledgements
- OpenAI for providing the Gym environment
- The Stable Baselines3 team for their excellent implementation
- Our academic institution for computational resources
Appendix
Implementation Details
# PPO Training Configuration model = PPO( "CnnPolicy", env, learning_rate=3e-4, n_steps=2048, batch_size=64, gamma=0.99 ) # DQN Training Configuration model = DQN( "CnnPolicy", env, learning_rate=1e-4, batch_size=64, buffer_size=100000, target_update_interval=1000 )
Environment Specifications
- Observation Space: Box(0, 255, (96, 96, 3), uint8)
- Action Space: Box([-1. 0. 0.], 1.0, (3,), float32)
- Reward Range: [-inf, inf]