Automated Resume Classification Using NLP
Table of contents
Resume Classification Project
1. Introduction
In today’s fast-paced hiring landscape, HR teams face the challenge of sorting through thousands of resumes, which can be time-consuming and inefficient. This project aims to automate the resume classification process by categorizing resumes into four distinct categories, thereby reducing manual effort and enhancing accuracy.
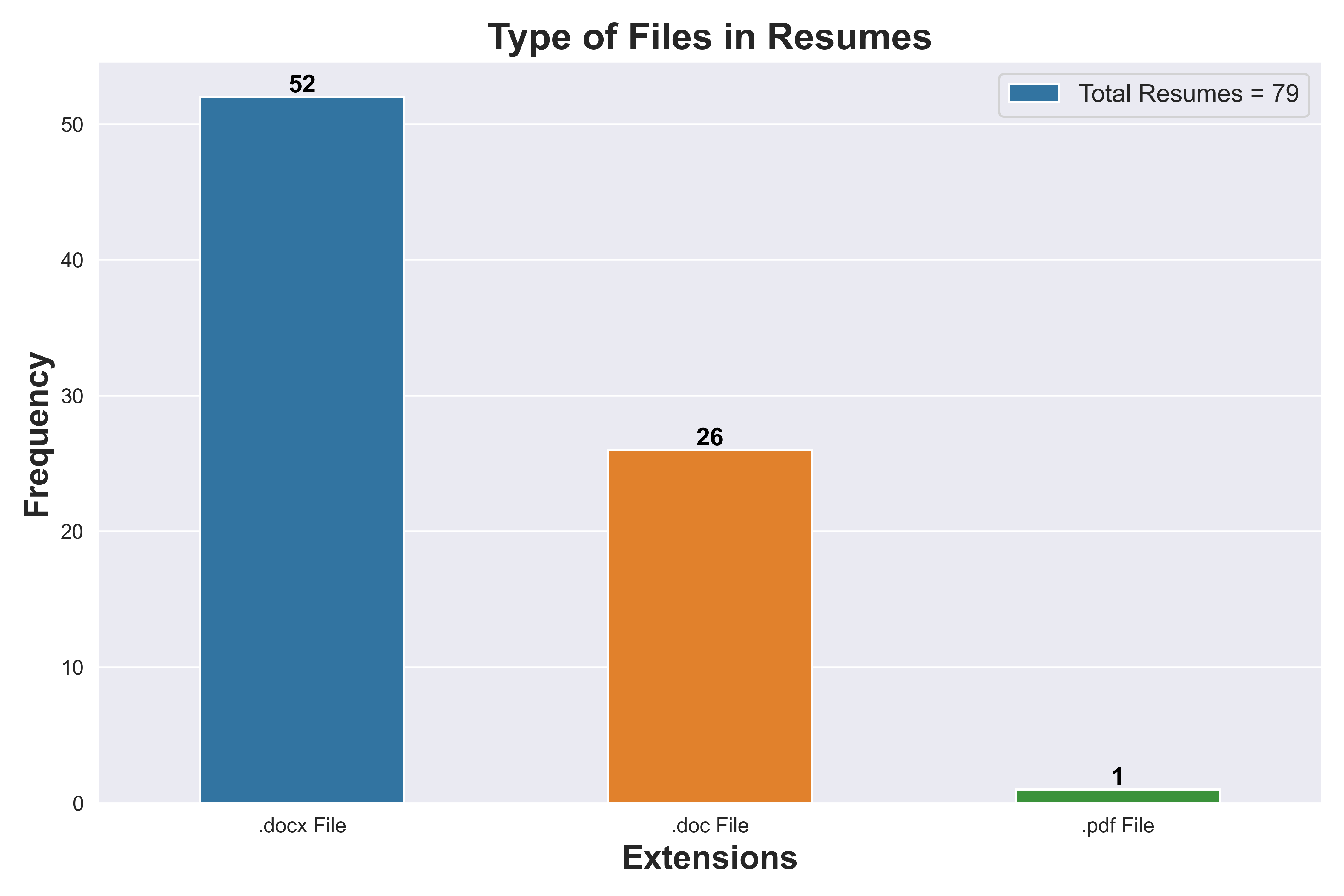
2. Data Visualization
Below is the count of different resume types in the dataset.
3. Methodology
The classification model employs the TF-IDF (Term Frequency-Inverse Document Frequency) technique to transform the text data into a numerical format that can be used by machine learning algorithms.
What is TF-TDF
TF-IDF is a statistical measure used to evaluate how important a word is to a document in a collection of documents. It comprises two components:-
Term Frequency (TF) measures how frequently a term appears in a document, normalized by the total number of terms to avoid bias toward longer documents.
-
Inverse Document Frequency (IDF) measures the importance of a term across the corpus. It is low for common terms and high for rare ones.
-
TF-IDF Score combines these measures to reflect the importance of a term in a document relative to the corpus.
Models Trained
- K-Nearest Neighbors
- Decision Tree
- Random Forest
- Support Vector Machine
- Logistic Regression
- Bagging Classifier
- Ada Boost Classifier
- Gradient Boosting
- Naive Bayes
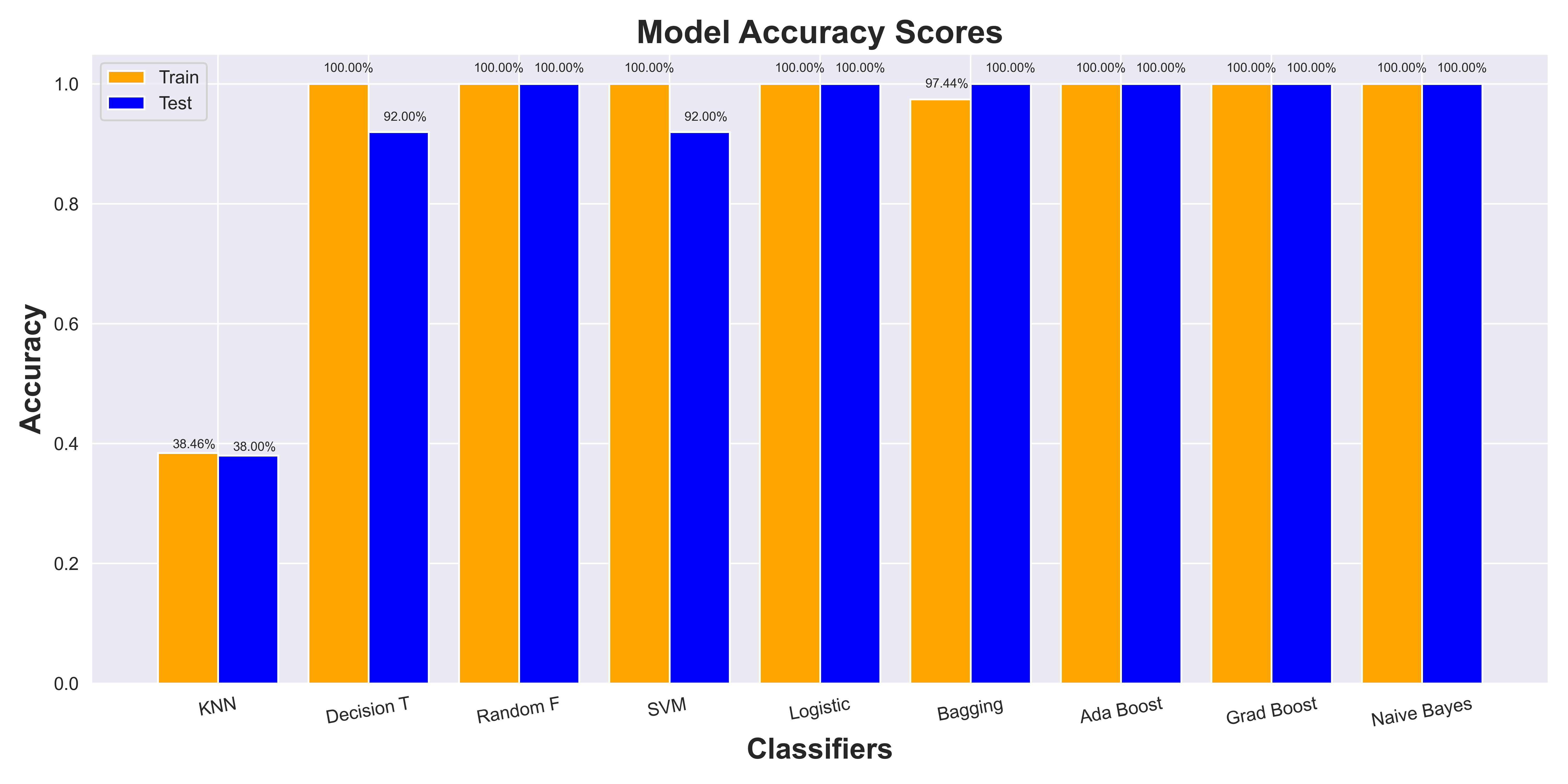
4. Results
The results section provides a comprehensive overview of the model performance, including train and test accuracy metrics.
5. Conclusion
This project demonstrates the effectiveness of using machine learning for automating resume classification, significantly reducing manual efforts while maintaining high accuracy.