Abstract
Based on what I've found in my industry, there is a lack of datasets in the engineering field to train big models for my own industry. This is because the knowledge in the engineering domain is in the form of reports, standard specifications, technical guidelines or more complex engineering diagrams, not in the form of datasets QA that can be used for training, in contrast to the medical and legal domains, where a large number of consultation records and legal counseling datasets, where Q&A pairs can be used to fine-tune the training of large models.
View more in my github:
AutogenQA
Introduction
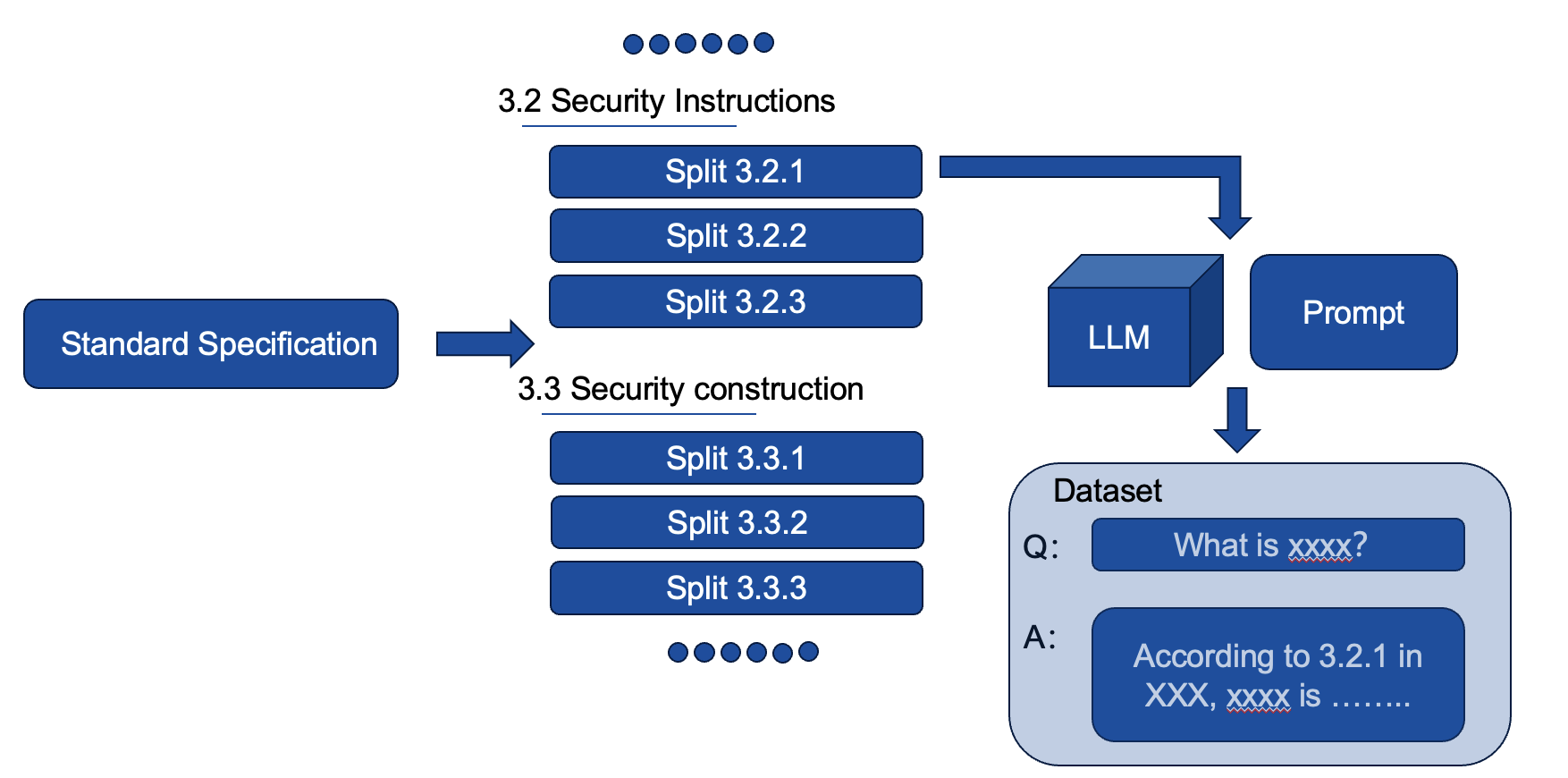
When I want to train LLMs in the engineering domain, I have to start with a Standard Specification
, so that the LLM models can think like engineers and have the relevant knowledge. But the standard specifications are all presented in the form of a line by line, and there are no Q&A pairs, so we need to organize all of these standards into a Q&A format, but this will consume a lot of human and material resources. So I developed a platform that can generate Q&A pairs by using big models, and provide evaluation and annotation functions to ensure that the quality of Q&A pairs can meet the requirements.
Practice
Using the open source python visualization tool Taipy, I made a visualization platform for production QA.
##Page 1
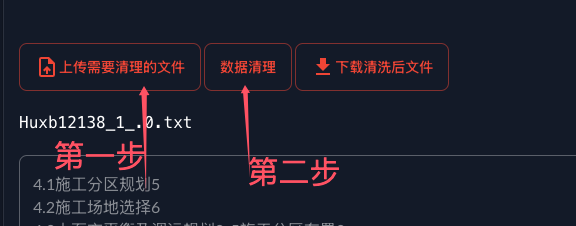
- First of all, the user needs to import TXT files, meaning that the user needs to speak in advance of the standard specification pre-processing perfect, because in my industry there are most of the standard specification is PDF format, so you need to use the OCR tool or can be read into a string file.
- the document for chunking, the platform uses the method is, a specification as a one-time content input to the model as material to produce Q&A pairs. So my algorithm here is to use each line as one time material to produce QA, so I will make sure that each specification is done in the same line.
##Page 2
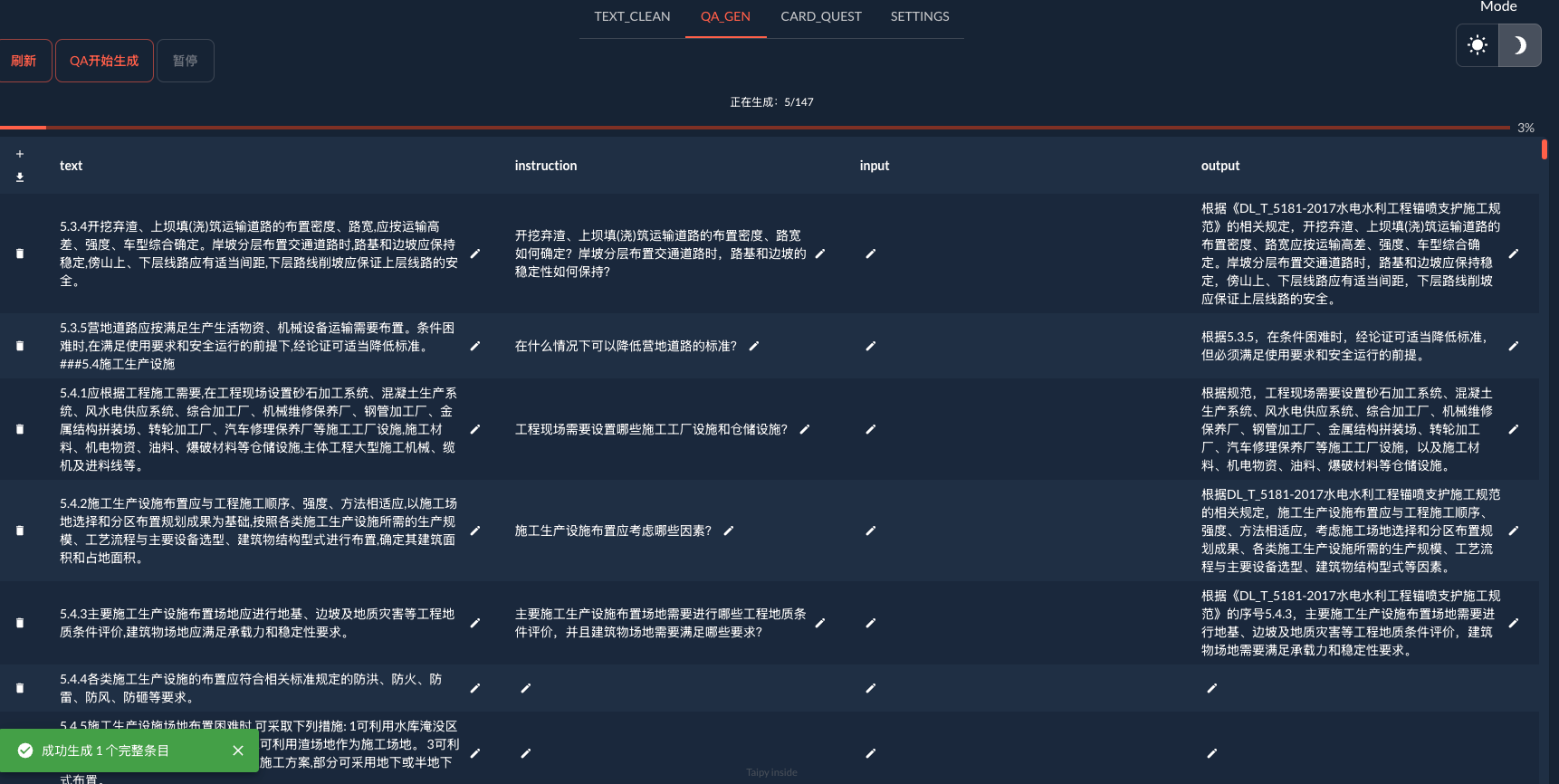
- On the second page, you can visualize the progress of the Q&A pair production and control the progress by clicking Continue and Pause. While paused, you can make changes to the currently produced QA.
- Click Download csv file, you can talk about the current QA has been generated in the form of csv to save, the file reference dataset show the effect.
##Page3
- The project provides an interface to change the prompt word and apikey, and please modify it according to the instructions in the github.https://github.com/Huxb12138/AutogenQA
Conclusion
Produces Q&A pairs that have multiple uses in my industry:
- they can be used in RAG applications to enrich the database by vectorization.
- can be used as datasets in fine-tuning to fine-tune the parameters of the model, by modifying the cue words to produce datasets of instructions with clearer goals and more practiced business.
- etc. of
Future Work
-
the current use is still in the form of cue words to give the model instructions to complete the task, if you can collect the dataset in the process, that is:
Q: Material content
A: QA of the material content
Such QA would be collected and utilized to train and fine-tune a model dedicated to producing QA. This saves a lot of arithmetic and token consumption. -
I've also thought about the issue of deciding what to give to the big model as material content as a single input: if you directly give each paragraph of the standard specification to the big model, you'll lose the contextual relationships in the specification and lose the logic of the whole chapter. For example, 3.2.1 and 3.2.2 are complementary to each other, and the meaning of the text can only be perfectly expressed when the two norms are used as material at the same time. Violent cuts alone will lose the textual information. So introducing a big model for semantic understanding is also a solution, and it also allows users to perform manual labeling to determine which ones to use as material for one input.