Abstract
This report presents a real-time gesture recognition system for AUSLAN (Australian Sign Language) fingerspelling using Long Short-Term Memory (LSTM) neural networks. The system utilizes left and right hand landmarks extracted from video frames using MediaPipe's holistic model. Key challenges addressed include interclass similarity, background illumination, varying distance from the camera, and varying hand sizes. Through data normalization, augmentation, and a carefully designed LSTM model, the system achieves 99% accuracy in recognizing hand gestures and providing robust performance in real-time applications.
Source Code
Demo
Introduction
Gesture recognition has advanced with various methods addressing sign language interpretation. Early Hidden Markov
Models (HMMs) modeled temporal sequences but lacked spatial accuracy, while Recurrent Neural Networks (RNNs), especially Long Short-Term Memory (LSTM) networks, im proved temporal dependencies. For example, Koller et al. utilized RNNs for continuous sign recognition, address ing temporal challenges but facing vanishing gradient issues. Convolutional Neural Networks (CNNs) capture spatial features but require high computational power and struggle with lighting sensitivity. Our approach counters these limitations by using hand landmark data extracted via MediaPipe, reducing input size and focusing on essential gesture features. By employing LSTM networks, we model temporal dynamics while handling long-term dependencies without the vanishing gradient issues associated with standard RNNs. This results in a more com putationally efficient model that converges faster and requires less data compared to CNN-based methods. Additionally, normalization and data augmentation make our model robust to variations in hand size and camera distance, addressing challenges that previous methods struggled with.
Methodology
Data collection is a critical step in building a robust gesture recognition system. We used the MediaPipe holistic model to extract left and right hand landmarks from video frames. The landmarks provide 3D coordinates (x, y, z) for 21 key points on each hand. For the process, we capture 50 video sequences one instance of a gesture (e.g., the letter "A") and each sequence consists of 30 frames to ensure uniformity. We saved the extracted keypoints as .npy files for each frame is more efficient in terms of storage space and computational resources compared to storing full images.
.png?Expires=1782213623&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=e337hMMhx8BYwF20~XIrxKURG6owPgNWbs6hD6KactZHSMYZVZBVDkSdoiCmYbO-NTHg60031HKezFCoYv~y0VA4aCoKUoCzvWZFqvkiQAwlbu8USanjaK~8QwwoPauV1996wwKv3hKIKlcuVLt4MnzS2Dblu-T3vuqBov1AMuNgtg~zfjXOt3vj14RfKWQgk1PWxKfFJI6yDC7e32R1Cf9P5lme3VpjSiZGXxO9rslb3bbOFgyAC0GGkABxvDPD0TnVTPrUsd71foRRjh-vdHJBVlFUgxJqhIrSzeU5LiwW03ifRNOdVX2XdEvltUQKPGIJjSoZ3VDRe7AgW8ZU2w__)
We designed LSTM-based neural network captures temporal dependencies in gesture sequences with a multi-layer architecture. It begins with an input layer that accepts sequences shaped (30, 126), representing 30 frames and 126 flattened keypoints from two hands. The first LSTM layer, with 64 neurons, processes the sequences to identify temporal patterns, followed by a batch normalization layer to stabilize training and a dropout layer (rate: 0.5) to prevent overfitting. The second LSTM layer expands the model's capacity to capture complex patterns with 128 neurons, again followed by normalization and dropout. A third LSTM layer with 64 neurons summarizes the learned features, preparing them for the dense layer with 64 neurons that combines these features. The output layer generates class probabilities for 26 classes (letters A-Z) using the softmax activation function. The model is optimized with the Adam optimizer (learning rate: 1e-4) and employs categorical cross-entropy loss, monitoring performance with categorical accuracy metrics.
Challenges and Solutions
To address the identified challenges, we implemented specific strategies tailored to each problem.
Interclass Similarity
The issue of interclass similarity arises when certain AUSLAN letters have very similar hand shapes, making it difficult for the model to distinguish between them. For example, letters like 'M', 'N', ‘I’, ‘O’, and ‘U’ involve subtle differences in finger positioning. To overcome this, we employed data augmentation techniques to increase the diversity and variability of the training data. By augmenting the data with noise injection, scaling, and time warping, we effectively provided the model with a broader range of examples, helping it learn the subtle differences between similar gestures. Additionally, we fine-tuned the model architecture by adjusting the number of LSTM units and layers to better capture intricate temporal patterns inherent in the gestures.
Background Illumination
Variations in lighting conditions can affect the accuracy of landmark detection, as bright sunlight or dim indoor lighting can cause inconsistent landmark extraction. To mitigate this issue, we adopted a landmark-based approach that uses only the 3D hand landmarks rather than raw images. This approach reduces sensitivity to lighting conditions because the landmark detection algorithm is robust to illumination changes. Furthermore, we applied data normalization to the keypoints, which minimizes the impact of any residual inconsistencies caused by varying illumination, ensuring that the model receives consistent input data.
Varying Distance from the Camera
The scale of the hand in the image changes with the subject's distance from the camera, affecting the coordinates of landmarks. Gestures performed closer to the camera appear larger, leading to different keypoint values compared to those performed farther away. To address this, we implemented keypoint normalization to make the model invariant to scale. By centering and scaling the hand landmarks based on individual hand size, we ensured that the model focuses on the relative positions of the landmarks rather than their absolute positions. We also incorporated scaling augmentation into our data augmentation process to simulate varying distances, further improving the model's robustness to this variation.
Varying Hand Sizes
Different individuals have varying hand sizes, which impacts the absolute values of keypoints and can affect model performance. Children's hands, for example, are smaller than adults', leading to variations in the keypoint data. To make the model invariant to hand size, we normalized each hand independently. By centering the keypoints around the wrist and scaling them based on individual hand size (e.g., the distance from the wrist to the middle finger MCP joint), the model learns to focus on the relative positions of landmarks within a hand. This approach allows the model to generalize across different hand sizes and perform accurately regardless of the user.
Tranning and Evaluation
We trained the model using the prepared dataset, combining both the original and augmented data to enhance the model's ability to generalize. The training process involved shuffling the data to ensure randomness and prevent any ordering biases. We set up the training parameters to train the model for 50 epochs with a batch size of 32. We used 80% of the data for training and 20% for validation to monitor the model's performance on unseen data.
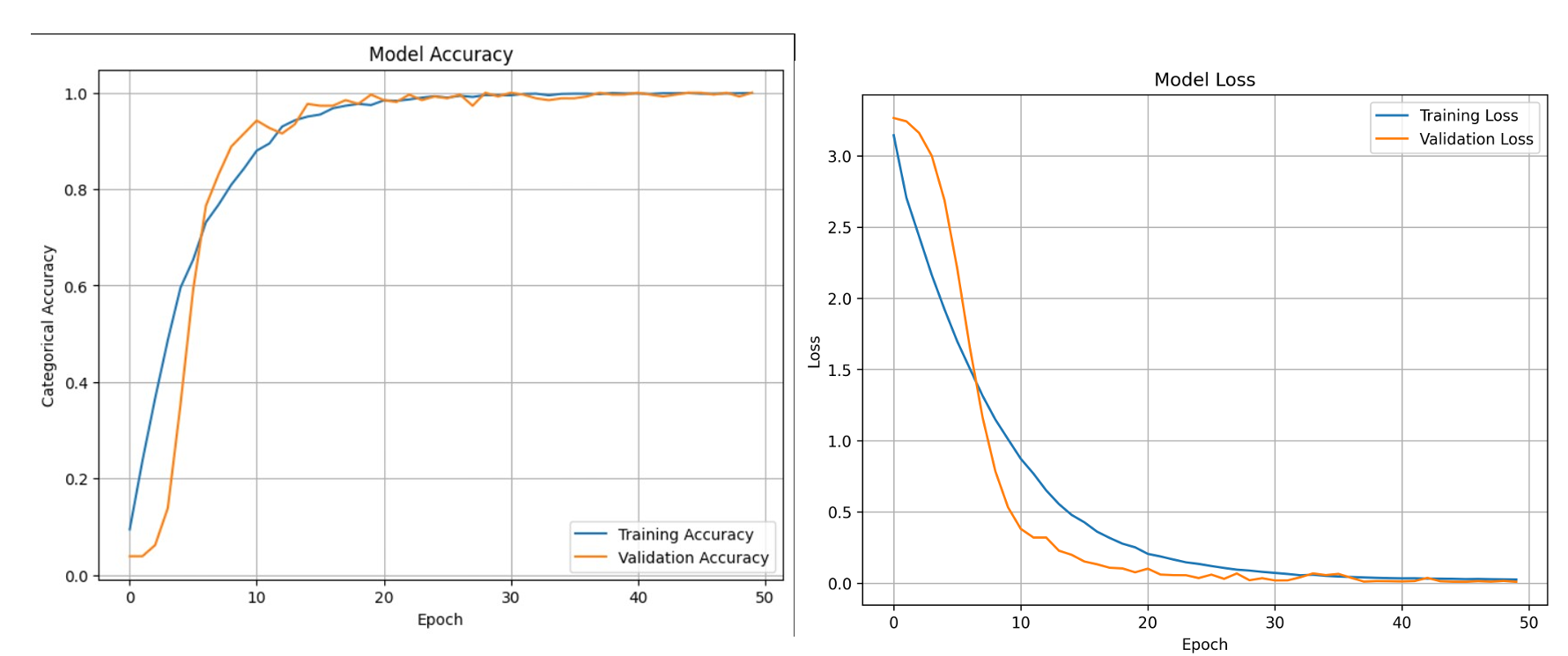
To optimize the training process and prevent overfitting, we employed several callbacks. The ModelCheckpoint callback saved the best model based on validation loss, ensuring that we retained the most effective version of the model. The ReduceLROnPlateau callback monitored the validation loss and reduced the learning rate when it plateaued, allowing the model to fine-tune its weights with smaller adjustments. The EarlyStopping callback stopped training when no improvement was observed in the validation loss for a specified number of epochs, preventing unnecessary training and potential overfitting.
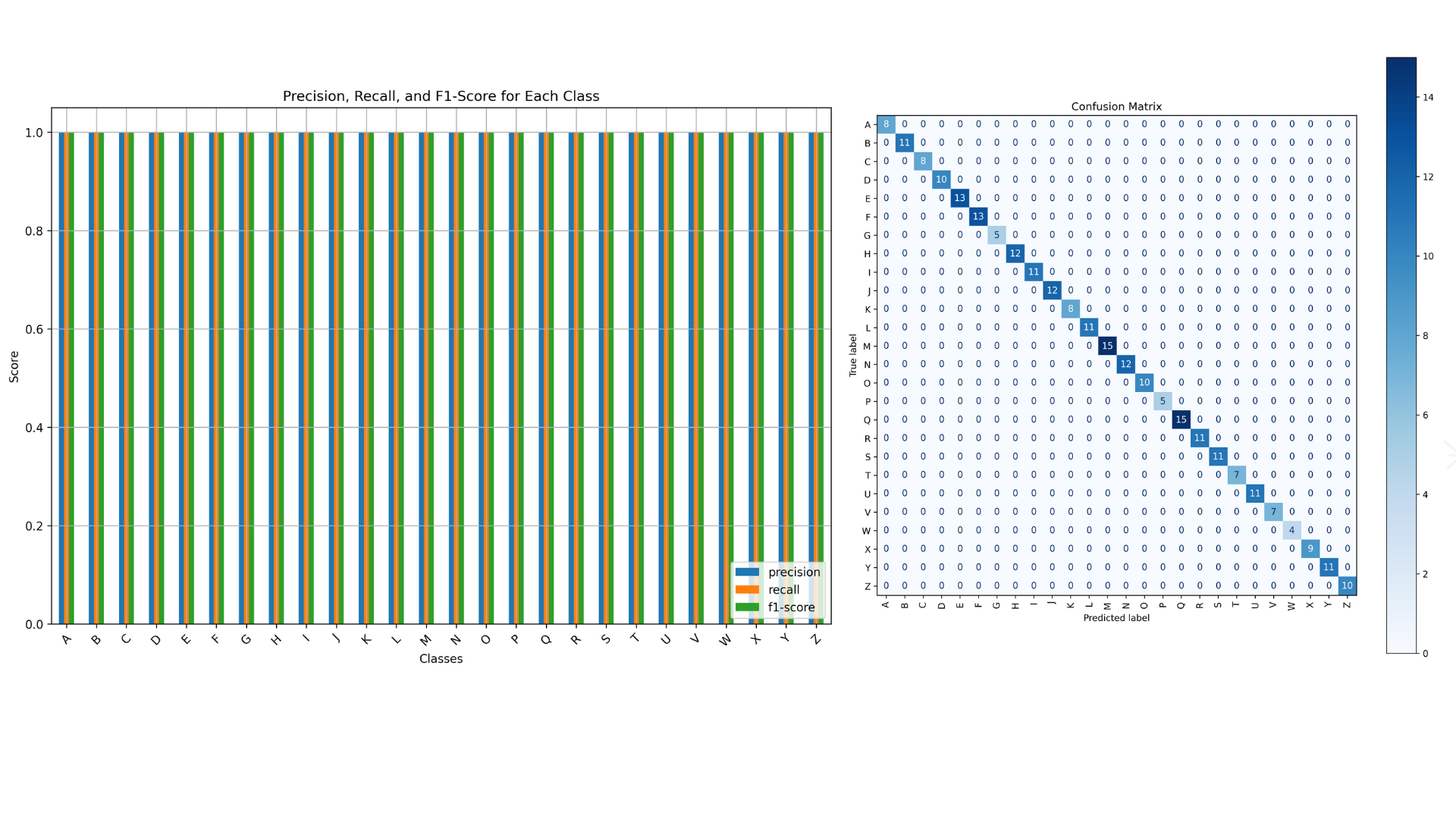
We evaluated the model's performance using various metrics to ensure its effectiveness. The accuracy and loss curves demonstrated that the model achieved an impressive 99% accuracy on both the training and validation datasets, indicating strong generalization without signs of overfitting. The classification report provided detailed insights into the model's performance across all gesture classes (A-Z), with precision, recall, and F1-scores consistently at 1.0 (100%) for each class. This highlights the model's ability to correctly classify gestures without significant false positives or false negatives. The confusion matrix further validated these results by showing that all true positive values lie on the diagonal, with no off-diagonal values, confirming zero misclassifications across the dataset. For instance, the model correctly classified 8 instances of 'A,' 11 instances of 'B,' and so on, up to 'Z.' This perfect alignment across metrics and visualization demonstrates that the model is highly accurate and reliable in recognizing gestures.
We tested on Real Time Recognization:
Conclusion
The project successfully developed a real-time AUSLAN fingerspelling recognition system using LSTM neural networks, achieving reliable and robust performance under various real-world conditions. By focusing on hand landmarks, the system is invariant to scale and hand size differences, reducing sensitivity to lighting and background. This innovation not only bridges communication gaps, but also fosters inclusion within the deaf community, creating a foundation for future advancements in dynamic sign language recognition and charmingly enhancing accessibility for its audience.