Data Collection (10 Persons)
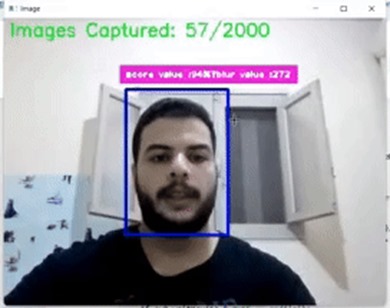
The Face Detection and Image Capture uses a custom FaceDetector model and a webcam to detect faces in video frames. analyzes each frame, adjusts bounding boxes for accuracy, and extracts face regions. The sharpness of detected faces is verified using the Laplacian variance method, and normalized face details are recorded. High-quality face images are saved with unique timestamps, stopping either after capturing a set number of images or upon user command. The system provides real-time visualization and was used to collect data for 10 persons, with each person having 2,000 images with confidence score 0.8.
Data Splitting
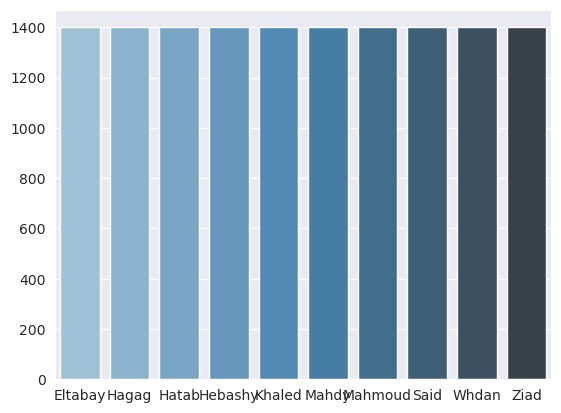
The Dataset Splitting process images collected for 10 persons into train, test, and val for machine learning. randomizes the image order to ensure unbiased splits based on defined ratios (70% training, 15% testing, 15% validation). Images are then moved to their respective folders, and the counts for each split are printed for verification.
Data Augmentation
Visualization for 10 Classes Train data
Applied Techniques
o I have used various data augmentation techniques in my face recognition projects, including rotation, flipping, zooming, shearing, color jittering, and cropping. These augmentations help improve the model's robustness by simulating real-world variations like different angles, lighting conditions, and distances, ensuring that the model generalizes well and can recognize faces in diverse situations.
o For validation and test data generators, I apply only the rescale=1./255. transformation, which scales the pixel values from the original range of 0-255 to a normalized range of 0 to 1. Unlike the training data, these generators do not perform any augmentation (such as rotation, shearing, or flipping), as the goal is to evaluate the model on real-world, unmodified data that it has not seen before, ensuring a consistent and accurate performance assessment.
Choosing Model (Vision Transformer)

VIT-T2T model (83% Accuracy)
Model Walk-Through
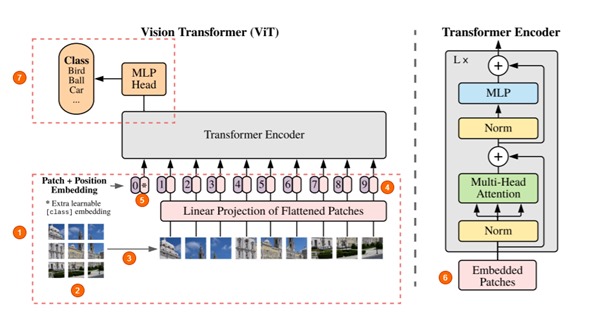
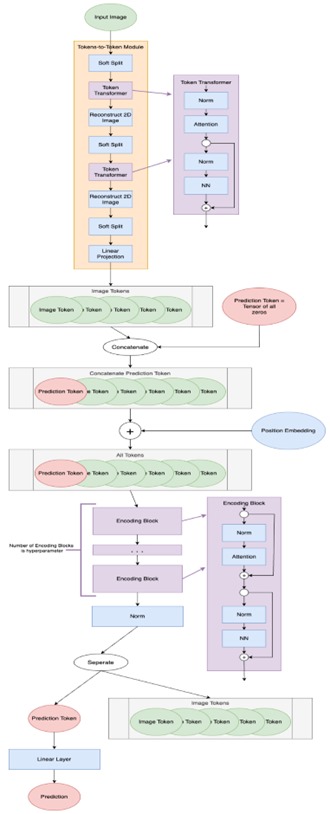
The model structure outlined in An Image is Worth 16x16 Words². However, code from this paper is not publicly available. Code from the more recent Tokens-to-Token ViT³ is available on GitHub. The Tokens-to-Token ViT (T2T-ViT) model prepends a Tokens-to-Token (T2T) module to a vanilla ViT backbone. The code in this article is based on the ViT components in the Tokens-to-Token ViT³ GitHub code. Modifications made for this article include, but are not limited to, modifying to allow for non-square input images and removing dropout layers.
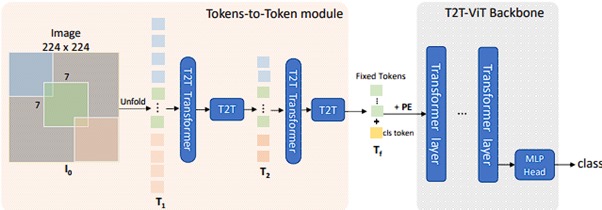
After training the ViT model alone, we achieved an 83% accuracy over 50 epochs. Encouraged by these results, we decided to further experiment with the ViT model.
fe_L2 = hub.KerasLayer("https://tfhub.dev/sayakpaul/vit_r50_l32_fe/1", input_shape = (224,224,3), trainable = False, name = "Pre_Trained_") model_2 = tf.keras.Sequential([ fe_L2, layers.Dense(128,activation = "relu"), layers.Dropout(0.5), layers.Dense(10, activation = "softmax", name = "output_layer") ]) model_2.compile(loss = "categorical_crossentropy", optimizer = tf.keras.optimizers.Adam(learning_rate = 0.0001), metrics = ["accuracy"])
VIT model (88% Accuracy)
• ViT-r50-l32-Fe Vision Transformer:
-
A member of the ViT model family that combines ResNet-50 and ViT architectures.
-
Utilizes a ResNet-50 backbone followed by a ViT for image processing.
-
Embeds spatial output from ResNet into ViT's initial patch embeddings.
After performing data augmentation to enhance the diversity of our training dataset, we proceeded with training the Vision Transformer (ViT) model. The data augmentation techniques included transformations like rotation, flipping, scaling, and color jittering, which helped improve the model's generalization ability. Using the ViT model alone, without any additional complex architectures, we trained the model for 50 epochs. The model showed promising performance, achieving an accuracy of 88%. This result indicates that the ViT model, even with standard augmentation techniques, is effective at capturing important features in the images and generalizing well to unseen data. However, further tuning of hyperparameters or integrating additional techniques could potentially boost the accuracy even further.
VIT model with Token-to-Token Technique (100% Accuracy)
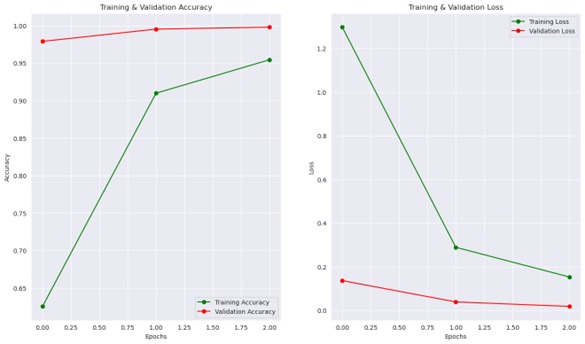
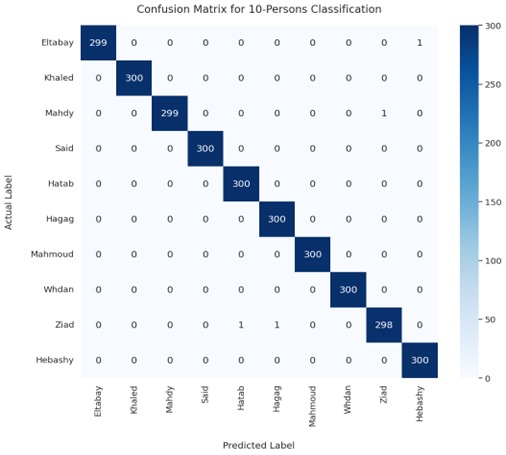
After performing data augmentation, we started working with the Vision Transformer (ViT) model and applied the Token-to-Token (T2T) method ourselves. We customized the tokenization process to enhance the model's ability to capture intricate details from the input images. After applying the T2T method, the augmented data was fed into the ViT model for training. Remarkably, we achieved 100% accuracy across 10 classes after just 8 epochs of training. This impressive result highlights the effectiveness of the T2T method and the ViT model in handling image classification tasks with augmented data, achieving flawless performance in a relatively short training period.
Image tokenization


Model Accuracy and Loss
Confusion Matrix
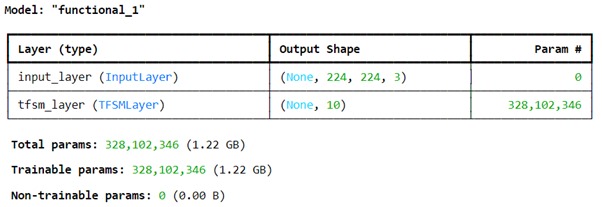
Model Sequence
Final Output for model
Loading mode ant test (Real World)
After loading the model weights, it's time to test it in real-time
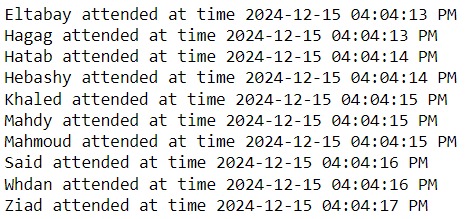
The Final script starting with captures video frames in a loop, detecting faces in each frame using a face detector. If a face is detected and it hasn't been captured already, it saves the face image (with some extra space above the face) to a specified folder. The face is saved as a new image file with a unique name for each detected face.
Final Output
iterates through images in a specified folder, processes each image by resizing it to 224x224 pixels, normalizing the pixel values, and then passing it through a pre-loaded model to make predictions. The model output is accessed, and the class with the highest predicted probability is determined. It then prints the image's name along with the current time in a 12-hour format, indicating when the face was attended to. The model used here for face prediction is a Vision Transformer (ViT) model, which processes the cropped faces for classification.