Artistic Algorithms with Neural-Style Transfer
Introduction
Neural-style transfer is a unique application of generative AI that mimics the human visual cortex to interpret and create art (Gatys et al., 2016). This algorithm separates an image into two key components:
- Content: The structure and identifiable elements in the image, like objects and their arrangements.
- Style: The artistic texture, colors, and patterns of an image.
By blending a content image and a style image, the algorithm generates novel artwork combining the structure of the content image with the artistic style. See results of the my implementation of the algorithm here. This generative AI approach not only can produce artistic creations, but provides insights into the human biological systems responsible for recognizing and re-creating art.
Background
Neural-style transfer leverages deep convolutional neural networks (CNNs):
- Convolutional Layers: Extract features by applying kernels to image matrices. Kernels are matrix-multiplied by the image as the kernel moves across in "strides".
- Activation Functions: Introduce non-linearity to capture complex relationships.
- Pooling Layers: Down-sample feature maps to reduce overfitting and computational cost. Common approaches are max-pooling (take the maximum pixel value in a small matrix) or average-pooling (take the average pixel value in a small matrix).
For a comprehensive explanation of CNNs, refer to Milosevic's guide.
Higher convolutional layers capture abstract, complex features like objects. Lower convolutional layers capture simpler features of an image like its colors, textures, and various patterns. Neural style transfer takes advantage of these properties by extracting losses for the "style" of an image from the lower layers and the "content" of an image from the higher layers. By creating a combined-weighted loss to minimize, the algorithm adjusts the pixel values of a blank image to re-create the content of one image in the style of another.
Key Operations
- Feature Extraction: Kernels detect edges, contours, and patterns. Kernel values extracted from a pre-trained VGG_19 network, which is trained for a variety of object recognition tasks.
- Hierarchical Abstraction: Lower layers capture style (colors, patterns), and higher layers identify content (object arrangements). Pull losses at specific layers in network.
Neural-Style Transfer Algorithm
The algorithm uses the pre-trained VGG-19 network to extract and blend features from input images:
- Content Loss: Measures differences in high-level feature maps (the outputs of the convolutional and activation layers higher in the network).
- Style Loss: Uses a Gram matrix to evaluate correlations between feature maps across all layers (capturing the textures and colors of an image).
Optimization
The algorithm minimizes the total loss using the LBFGS optimizer, known for its efficiency in handling complex loss functions. It estimates the inverse hessian matrix to dynamically adjust the step size, according to the curvature, in gradient descent. Instead of optimizing network parameters, as is often done in classical machine learning tasks, we optimize the pixel values of a blank image. Thus, in practice, the optimizer is "fit" to the blank image pixel matrix.
Implementation
The project was implemented using the automatic differentiation library PyTorch:
- Images were normalized based on VGG-19's training parameters.
- Custom classes were created for content and style losses and inserted into the network to extract content and style losses at various layers.
- The input image was optimized over multiple epochs, starting with a white noise image.
Experiments
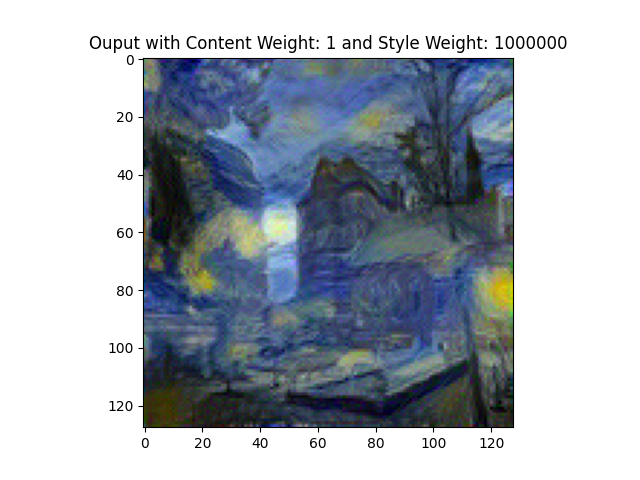
1. Duquesne University in Starry Night Style. Content image is Duquesne, style image is Starry Night.
- Parameters: Content weight = 1, Style weight = 1,000,000, Epochs = 1,000
- Result: Captured the swirling patterns of Starry Night.
2. College Hall (An Academic Building at Duquesne) in Surrealist Style.
- Parameters: Larger image size (512x512).
- Outcome: Highlighted challenges with complex style images, as brush strokes of surrealist style intermediately interfere with various aspects of the content.

3. Acrisure Stadium in Mona Lisa Style
- Parameters: Content weight = 1, Style weight = 1,000,000, Epochs = 340
- Observation: Achieved minimal style loss with a simpler style image (Mona Lisa highly resembles a regular photograph compared to more abstract art like surrealism)

Conclusions
Neural-style transfer demonstrates the versatility of CNNs beyond classic classification tasks, using layers' hierarchical structure to blend artistic and structural features. Future research could address:
- Spatial Constraints: Improving performance on portrait images, where tight spatial constraints must be maintained in the content image.
- Artistic Insight: Exploring parallels between human and machine creativity. Does biology mimic the processes found in Neural Style Transfer?
References
- Gatys, L. et al. (2016). A Neural Algorithm of Artistic Style. Journal of Vision.
- Milosevic, N. (2020). Introduction to Convolutional Neural Networks.
- PyTorch Documentation: Neural Style Transfer.
- Liu, D.C. & Nocedal, J. (1989). LBFGS Optimization.
##Code Examples
###The three code snippets are style_content_loss_layers() which computes the content and style losses after a pass through the network, neural_style_transfer_algorithm() which is the main runner that optimizes the input image over a set range of epochs, and ManualLBFGS which is a manual implementation of the LBFGS optimization algorithm that can be used in place of vanilla gradient descent.
def style_content_loss_layers(convolutional_network, network_mean, network_std, image_one, image_two): """Creates the model layers for computing the style and content losses. Args: convolutional_network (PyTorch network): Pre-trained convolutional network (e.g., VGG-19). network_mean (tensor): Normalization mean for the images. network_std (tensor): Normalization standard deviation for the images. image_one (tensor): The content image. image_two (tensor): The style image. Returns: nn.Sequential: A modified network model with content and style loss layers added. list: List of content losses. list: List of style losses. """ #The content layers are higher level, abstract features, so we take the 4th convolutional layer of the VGG-19 network content_layers_default = set(["('7', Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))"]) #The style layers are given in multiple layers, as style features can be high or low level style_layers_default = set(["('0', Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))", "('2', Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))", "('5', Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))", "('7', Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))", "('10', Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))", "('12', Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))"]) #Creating normalization module and initializing the model with a normalization layer normalization = normalize_images(network_mean, network_std) model = nn.Sequential(normalization) content_loss_list = [] style_loss_list = [] #Iterate through each layer of the convolutional network for layer in convolutional_network.named_children(): layer_type = type(layer[-1]) if layer_type in (nn.Conv2d, nn.ReLU, nn.MaxPool2d, nn.BatchNorm2d): name = str(layer) #inplace ReLU recommended for neural style transfer if layer_type == nn.ReLU: layer = nn.ReLU(inplace=False) #Adding the current layer to the model with the appropriate name if type(layer) == tuple: if isinstance(layer[-1], nn.Conv2d): layer_add = layer[-1] else: layer_add = layer #Adding the layer to the model with appropriate name model.add_module(name, layer_add) #Add content loss after the specified content layers if name in content_layers_default: #The feature maps of the content image we want to match content_target_filters = model(image_one).detach() #Create the content loss layer content_loss = content_image_loss(content_target_filters) #Adding content loss layer to the model model.add_module(f'content_loss_{layer[0]}', content_loss) #Append the content loss to the list content_loss_list.append(content_loss) #Add style loss after the specified style layers if name in style_layers_default: #The feature maps of the style image, using the Gram matrix style_target_filters = model(image_two).detach() #Create the style loss layer style_loss = style_image_loss(style_target_filters) #Adding style loss layer to the model model.add_module(f'style_loss_{layer[0]}', style_loss) #Append the style loss to the list style_loss_list.append(style_loss) index = trim_layers(model) #Trim layers that come after the last loss layer through indexing model = model[:index + 1] return model, content_loss_list, style_loss_list def neural_style_transfer_algorithm(cnn, normalization_mean, normalization_std, content_image, style_image, input_image, num_steps=300, style_weight=1000000, content_weight=1): """Runs the neural style transfer algorithm Args: cnn (PyTorch network): A convolutional neural network. We use the pre-trained vgg-19. normalizpation_mean (tensor): A tensor of values to normalize the image's channels normalization_std (tensor): A tensor of values to normalize the image's channels content_img (tensor): The content image (converted to a tensor) style_img (tensor): The style image (converted to a tensor) input_img (tensor): The input image (white noise which will get altered through gradient-descent losses) num_steps (int, optional): The number of steps to compute the losses. Defaults to 300. style_weight (int, optional): The weighting parameter to give to the style image. Defaults to 1000000. content_weight (int, optional): The weighting parameter to give to the content image. Defaults to 1. Returns: tensor: An ouput image that is a blend of the style and content images """ #Retrieving the baseline losses model, content_losses, style_losses = style_content_loss_layers(cnn, normalization_mean, normalization_std, content_image, style_image ) #Input image needs grad to compute loss and adjust pixel values input_image.requires_grad_(True) #We are not updating model weights so we set to eval() model.eval() model.requires_grad_(False) #Getting the optimizer to adjust pixel values for the input image optimizer = get_manual_input_image_optimizer(input_image, learning_rate=0.0001) #Define run as an array due to Python scope. Arrays are mutable, whereas integers are not, within the #inner function 'optimize' num_steps_array = [0] while num_steps_array[0] <= num_steps: def optimize(): """The function that returns the loss for the optimizer. It computes the weighted loss of both and calls backward() on this loss. This computes the gradients needed by the optimizer to change the input image. Returns: float: The loss """ #Ensure pixel values are between 0 and 1 input_image.data.clamp_(0, 1) #Zero the gradients at each step optimizer.zero_grad() model(input_image) style, content = 0, 0 for sl in style_losses: style += sl.loss style = style * style_weight #Only one layer used in content loss content = content_weight * content_losses[0].loss #total loss is the weighted sum of the two separate losses total_loss = style + content #Computing all the gradients with backward() total_loss.backward() #Increment the step num_steps_array[0] += 1 if num_steps_array[0] % 20 == 0: print(f"Step {num_steps_array[0]}: Style Loss: \ {style.item():.4f}, Content Loss: {content.item():.4f}") return total_loss optimizer.step(optimize) #Ensuring final image has valid pixel values between 0 and 1 (sanity check) with torch.no_grad(): input_image.clamp_(0, 1) return input_image class ManualLBFGS: """A Manual implementation of the LBFGS Algorithm. LBFGS approximates the second-derivative matrix for better convergence compared to vanilla gradient descent optimization. The 'curvature' information gained allows the algorithm to take larger optimization steps in flatter regions and smaller steps in steep regions. L stands for limited memory, as the algorithm approximates the derivates using the past n updates. """ def __init__(self, params, learning_rate=0.0001, history_size=20): """Initializing optimizer class Args: params (vary): The thing to be optimized (input image) learning_rate (int, optional): The step size in gradient descent. Defaults to 0.0001. history_size (int, optional): The number of steps to go back in time. Defaults to 20. """ #Storing the parameters self.params = params #How long to loop back through previous iterations self.history_size = history_size #The differences in parameters, gradients, and scaling weights self.parameter_differences = [] self.gradient_differences = [] self.scaling = [] #The step size in adjusting the parameters (pixel values) self.learning_rate= learning_rate #For first step, we do not have amy parameters or gradients self.prev_params = None self.prev_grad = None def step(self, optimize): """This is the "step" in minimizing the loss, adjusting the pixel values of the input image. We adjust in the opposite direction of gradient of loss. Args: optimize (function): A function that returns the loss Returns: float: The loss """ #Get the loss (which also calculates gradients because optimize() calls loss.backward()) loss_at_step = optimize() #Retrieve the current gradients and parameters gradients = self._get_flat_grad() parameters = self._get_flat_params() #If we aren't the first step if self.prev_grad is not None: #Find the difference in the previous params and gradients. When differences are larger then the #slope of loss function is also greater diff_param = parameters - self.prev_params diff_grad = gradients - self.prev_grad #Scaling (add small number to prevent divide by 0) scaling_step = 1.0 / (diff_grad.dot(diff_param) + 0.00000001) #If we reached the max history size, pop an element to make room for previous iteration if len(self.parameter_differences) >= self.history_size: self.parameter_differences.pop(0) self.gradient_differences.pop(0) self.scaling.pop(0) #Otherwise add the current differences self.parameter_differences.append(diff_param) self.gradient_differences.append(diff_grad) self.scaling.append(scaling_step) #Retrieve the direction to adjust pixel values in based on LBFGS Algorithm direction = self.lbfgs(gradients) else: #Normal gradient descent is used when we have no previous parameters (the first step) direction = -gradients #Updating pixel values of input image (the parameters) in the direction that minimizes loss with torch.no_grad(): for parameter in self.params: #Updating each parameter in-place using PyTorch add_ in the direction of direction scaled by the learning rate parameter.add_(direction.view(parameter.size()), alpha=self.learning_rate) #Store current params and grads in prev variables for next step self.prev_params = parameters.clone() self.prev_grad = gradients.clone() return loss_at_step def zero_grad(self): """Zeroes the gradients at each optimization step. This is necessary to recompute distances accurately """ for parameter in self.params: if parameter.grad is not None: #For each parameter, detach from computational graph and set gradient to zero parameter.grad.detach_() parameter.grad.zero_() def _get_flat_params(self): """Flattens parameters into a 1-D Vector Returns: pyTorch: Tensor """ listed = [] for parameter in self.params: listed.append(parameter.view(-1)) concat = torch.cat(listed) return concat def _get_flat_grad(self): """Flattens gradients into a 1-D Vector Returns: pyTorch: Tensor """ listed = [] for parameter in self.params: listed.append(parameter.grad.view(-1)) concat = torch.cat(listed) return concat def lbfgs(self, gradients): """The two-loop recursion implementation of LBFGS. When the paramter differences are large (the slope of loss function is steep), we have bigger scaling factors. We then subtract these factors from the gradients. Therefore, if we have a steep slope, we take smaller steps. If we have a flatter slope, we take larger steps. Args: gradients (Tensor): The current gradients at step n Returns: Tensor: The updated direction """ #Clone so we do not alter in intermediate steps final_grads = gradients.clone() scaling_factors = [] #Going backwards through the history of updates for i in range(len(self.parameter_differences) - 1, -1, -1): #Get current differences param_diff = self.parameter_differences[i] grad_diff = self.gradient_differences[i] scaling = self.scaling[i] #Get scaling factor scaling_factor_backward = (scaling * param_diff.dot(final_grads)) scaling_factors.append(scaling_factor_backward) #Adjusting the final grads by subtracting scaling factors final_grads -= (scaling_factor_backward * grad_diff) #The intermediate grads after backward history pass intermediate = final_grads #Forward pass through the history of our parameter differences for i in range(len(self.parameter_differences)): #Get differences param_diff = self.parameter_differences[i] grad_diff = self.gradient_differences[i] scaling = self.scaling[i] scaling_factor_forward = (scaling * grad_diff.dot(intermediate)) #Adding differences between parameter differences and difference of scaling factors intermediate += param_diff * (scaling_factors[i] - scaling_factor_forward) #Return the negative direction for minimization (we are trying to go in opposite direction of gradients) updated_gradient = -intermediate return updated_gradient