Abstract
"Generative Adversarial Networks (GANs) are widely used for image synthesis due to their ability to generate high-quality images. This study analyzes the architecture and working of GANs and their popular variants, summarizing their differences in terms of architecture, training methods, learning types, benefits, and performance metrics. Using the MNIST dataset of handwritten digits, we compare these models based on image quality, classification accuracy, losses, and computational efficiency. The findings provide insights into GANs' strengths, limitations, and potential future research directions in synthetic handwritten digit generation."
Introduction
Generative Adversarial Networks (GANs), introduced by Goodfellow in 2014, have become a cornerstone of generative modeling due to their ability to synthesize realistic data. Their adversarial framework, comprising a generator and a discriminator in a minimax competition, enables the generation of high-quality outputs that closely resemble real data. GANs have been extensively applied to tasks such as image synthesis, object detection, text modeling, and image inpainting. Notable variants, including Convolutional GANs (e.g., DCGAN) and Inference GANs (e.g., BiGAN), employ different network architectures, leveraging fully connected layers or convolutional networks to address diverse application needs. Despite their success, GANs face challenges such as training instability and mode collapse, spurring ongoing research to enhance their robustness and effectiveness.
This paper investigates the application of GANs for synthetic handwritten digit generation, focusing on the MNIST dataset as a benchmark. It critically evaluates popular GAN variants, analyzing their architectures, training methods, and performance metrics such as image quality, classification accuracy, and training efficiency. Furthermore, the study highlights the strengths, limitations, and challenges associated with GANs, offering insights into potential future advancements. By providing a comprehensive analysis, this work aims to contribute to the understanding and development of GANs in the field of generative modeling
Methodology
Dataset Preparation:
The MNIST dataset of handwritten digits is loaded using TensorFlow.
Images are reshaped to Images are reshaped to 28281 and normalized to range [-1,1] for better GAN training performance.
Model Architecture:
Generator:
A neural network that takes random noise as input and generates synthetic images resembling the MNIST dataset.
It consists of fully connected layers, reshaping, and transposed convolution layers with batch normalization and activation functions (LeakyReLU and tanh).
Discriminator:
A neural network that classifies whether an input image is real or generated (fake).
It uses convolutional layers with LeakyReLU activation, dropout layers for regularization, and a dense output layer for classification.
Training Setup:
The generator and discriminator are trained simultaneously in an adversarial setup:
Generator Loss: Encourages the generator to produce images that the discriminator classifies as real.
Discriminator Loss: Combines losses from correctly classifying real images and rejecting fake ones.
The Adam optimizer is used for both networks with a learning rate of 0.0001
Training Process:
A training loop iterates over a specified number of epochs.
For each batch of real images:
Random noise is used to generate fake images using the generator.
Real images and fake images are passed through the discriminator.
Losses for both networks are computed and gradients are backpropagated.
Gradients are applied to update the generator and discriminator using their respective optimizers.
Image Generation and Saving:
During training, the generator produces synthetic images at each epoch using random noise.
These images are saved and displayed for qualitative assessment of the generator's performance.
Model Saving:
After training, the generator model is saved as gan_generator.h5 for later use in generating synthetic handwritten digits.
Hyperparameters:
Batch size: 128
Noise dimension: 100
Number of epochs: 1000
Buffer size for dataset shuffling: 60,000
This methodology trains a GAN to generate realistic handwritten digits by leveraging the adversarial training process between the generator and discriminator networks.
 using TensorFlow and Keras. Specifically:
Key Details:
Framework:
TensorFlow with Keras APIs is used to define, train, and save the models.
Model Type:
Generator: A neural network that learns to generate synthetic data (e.g., images) from random noise. It consists of dense layers followed by convolutional layers with transposed convolutions for upscaling.
Discriminator: A neural network that learns to distinguish real data from synthetic data generated by the Generator.
Dataset:
The MNIST dataset is used, which consists of grayscale images of handwritten digits.
Architecture:
The Generator uses dense and transposed convolutional layers, Batch Normalization, and LeakyReLU activations.
The Discriminator uses convolutional layers, LeakyReLU activations, and Dropout for regularization.
Loss Functions:
Binary Cross-Entropy Loss is used for both the Generator and Discriminator, with logits.
Optimizers:
Adam Optimizer with a learning rate 0.0001
Output:
The Generator produces 28x28 grayscale images (to match the MNIST dataset).
Results
after 1 EPOC :

after 10 EPOC:

after 100 EPOC :

after 1000 EPOC:

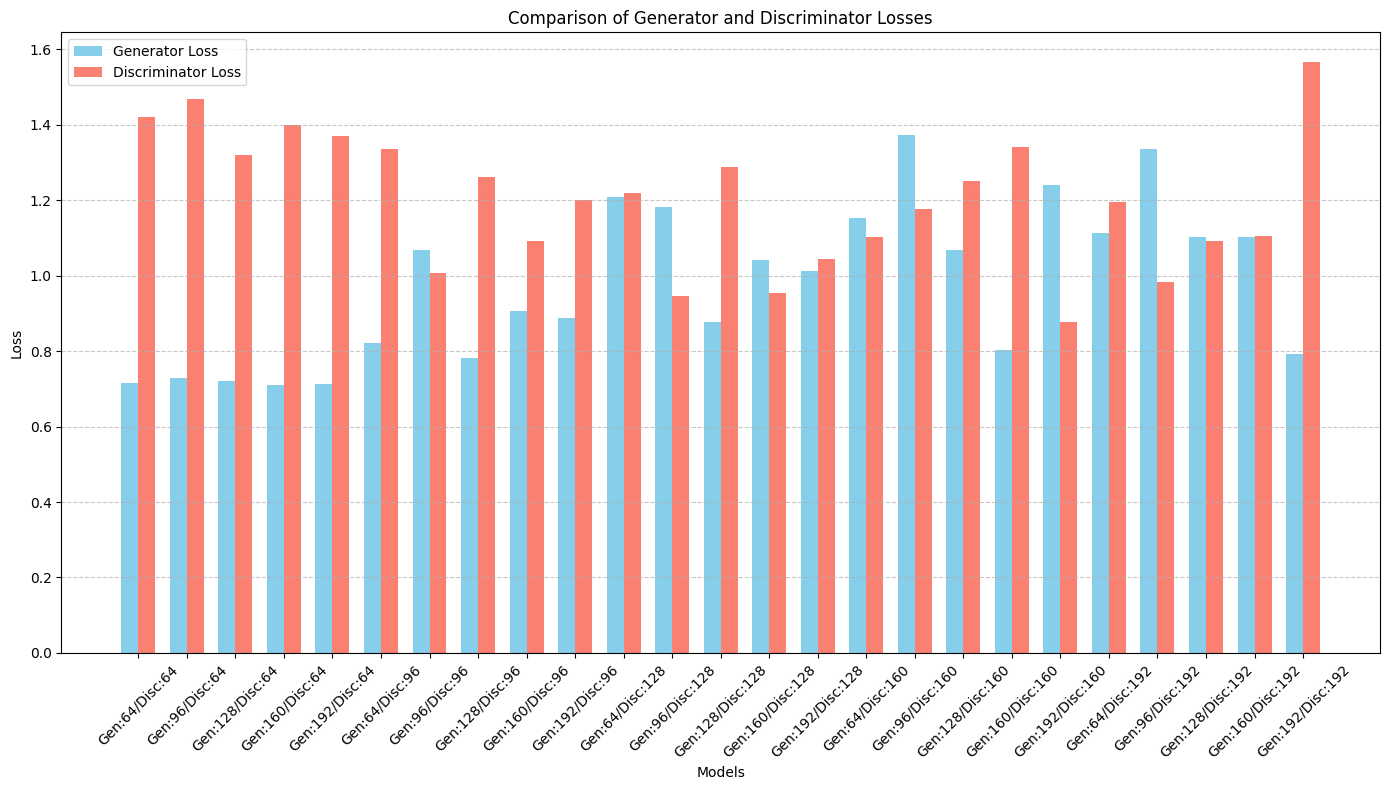
Graph of Generator and Discriminator loss over epochs :
.png?Expires=1782196598&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=TUkA3wGQCweKYw15JNxAzhsQZ7zhlTmbNm3LJnrul6kwSs8ykIVlXBBRsZu7D~Tsdo~Z8aXDfHmLOs7OWK1bQWKhVZ4G4ur9CMDqYjwnvM4-EE5rPiw~5nop~1VcX4X3oO5Zb-8-Hdwg22Phm9P-en62w6RFtn6ob5NVxERrm0O88lZNYWXjJ2499iYgVGqRciWyBNXs5at3w0H5LszP1o~NNLTUEQmvzT2Y~-lCDd~4EUknXf332R4zfEg~ze66s6pRY-GuCu52trReo8OqFMyhWyoib8TbMehdBX~uE0gchGPiNZsVM3nPabKFEhXjkN5P4irGw2u8f1f4FpA-xA__)
Discussion
Switching to a Different GAN Architecture:
we can replace the Generator and Discriminator architectures with those of a more advanced GAN variant (e.g., DCGAN, WGAN, StyleGAN).
Adjust loss functions and optimizers accordingly.
Switching to a Different Generative Model:
Replace the GAN with a Variational Autoencoder (VAE) or a Diffusion Model for generative tasks.
This involves changing the Generator's architecture and possibly eliminating the Discriminator.
Replace the loss function with one suitable for the new model (e.g., reconstruction loss for VAEs).
Switching to a Pre-Trained Model:
Use a pre-trained model from a library like Hugging Face Transformers for text or image generation (e.g., GPT for text, Stable Diffusion for images).
Install the appropriate libraries and adapt the data preprocessing pipeline.
Switching Frameworks:
Move from TensorFlow to PyTorch or another framework. This requires rewriting the architecture, training loop, and other components to match the new framework.
Example: Switching to a DCGAN
To switch from the current GAN to a Deep Convolutional GAN (DCGAN):
Modify the Generator:
Add more convolutional layers.
Use a fixed set of hyperparameters for kernel size, stride, etc.
Modify the Discriminator:
Use deeper convolutional layers with more filters.
Update Loss Function:
DCGAN can use the same Binary Cross-Entropy Loss.
Update the Training Loop:
Follow the same training logic but adjust for the deeper architecture.
Conclusion
The above paper demonstrates the implementation of a Generative Adversarial Network (GAN) using TensorFlow and Keras to generate synthetic images based on the MNIST dataset. The architecture consists of two neural networks: a Generator that creates synthetic images and a Discriminator that classifies images as real or fake. Both networks are trained in an adversarial manner, with the Generator striving to produce realistic images to fool the Discriminator, while the Discriminator learns to distinguish between real and generated images.
Key features include:
Generator and Discriminator Architectures:
The Generator uses a combination of dense layers, transposed convolutions, and Batch Normalization to generate realistic 28x28 grayscale images.
The Discriminator employs convolutional layers and Dropout to effectively classify images.
Training Procedure:
Binary Cross-Entropy Loss is used for both the Generator and Discriminator.
The training process tracks the loss values for each network across multiple epochs to monitor performance.
Visualization:
Synthetic images are generated and saved periodically to evaluate the quality of the Generator's output.
A graph of Generator and Discriminator loss over epochs provides insights into the model's learning dynamics.
This implementation provides a foundational GAN framework that can be extended for more complex datasets or adapted to advanced GAN variants, such as Wasserstein GANs (WGANs) or StyleGANs. The generated images and loss trends serve as benchmarks for assessing model convergence and improving hyperparameters.
References
https://rdcu.be/d5bov An analysis of generative adversarial networks and variants for image synthesis on MNIST dataset
https://arxiv.org/abs/1701.07875v3 Wasserstein GAN
https://rdcu.be/d5bpK Exploring deep convolutional generative adversarial networks (DCGAN) in biometric systems: a survey study