American Sign Language Recognition to Speech System for Medical Communication
Objective
This project aims to develop a system that recognizes the American Sign Language (ASL) alphabet. The system can translate identified signs into words relevant to the medical field and vocalize selected phrases associated with those words. Its primary goal is to make communication easier for auditorily challenged people, especially in medical situations. The project seeks to bridge a communication gap between people with auditory impairment and medical staff by concentrating on medical terminology and phrases. This helps to provide better and faster medical care.
Code: https://github.com/haziqa5122/ASL-Recognition-to-Speech-System
Introduction
Communication is a basic human need for social interaction, education, and healthcare access. However, for the auditory-impaired community, communication barriers can cause social isolation, limited educational opportunities, and inaccessibility to healthcare services. In medical settings, these challenges are particularly acute. Miscommunication can lead to misdiagnosis, incorrect treatment, and serious health issues.
Sign language interpreters are important in helping solve these communication problems. However, they are not always available, especially in emergencies or places with limited resources.
This project addresses the challenge of facilitating real-time communication between ASL users and medical staff. We are developing a system to recognize ASL alphabet signs, identify potential medical words, and convert selected phrases into spoken language. The system uses computer vision, deep learning, and text-to-speech technologies to create a user-friendly interface. This will help improve the quality of care and enhance the overall healthcare experience for the auditory-impaired individuals. By enabling immediate communication, this system helps ASL users share their medical needs clearly and promotes a more inclusive and accessible healthcare environment.
Methodology
We employed advanced technologies and a methodical approach to model development, data processing, and interface design to achieve the project objectives. This section details the key steps in building the Real-Time ASL Recognition to Speech System.
Technology Stack
The system is built using a combination of cutting-edge technologies:
-
Ultralytics (YOLOv8): A state-of-the-art (SOTA) object detection framework used to train a model capable of recognizing ASL alphabet signs in real-time. YOLOv8's speed and accuracy make it ideal for this application.
-
Bark TTS: A transformer-based text-to-audio model used to convert recognized text (medical phrases) into natural-sounding speech. Bark's ability to generate realistic and expressive audio improves the system's usability and user experience (UX).
-
Gradio: A Python library for creating interactive user interfaces (UI) used to build the front-end application that allows users to interact with the system. Gradio simplifies the process of deploying models and creating an intuitive UX.
-
OpenCV: A comprehensive library for image processing and computer vision, OpenCV captures and preprocessing video frames from the webcam.
Dataset
The project relies on two key datasets.
- ASL Alphabet Dataset for Model Training
- Contextualizing Communication: A Curated Medical Phrases Dataset
ASL Alphabet Dataset for Model Training
The American Sign Language Letters Dataset from Roboflow was used to train the YOLOv8 model. This dataset contains a large collection of images depicting various ASL alphabet signs, providing a robust foundation for training and accurate recognition. The dataset contains numerous images per letter representing different hand shapes, orientations, and backgrounds. Before training, the dataset was analyzed to determine the number of images, image size distribution, and overall data quality.
Contextualizing Communication: A Curated Medical Phrases Dataset
A custom dataset of medical phrases was created using a combination of ChatGPT and GitHub Copilot. This dataset was designed to provide contextual relevance to the recognized ASL signs. It is stored in JSON format, with each entry consisting of a medical keyword (e.g., "ambulance," "appointment," "allergy") and a list of corresponding phrases.
Examples from the Medical Phrases Dataset:
{ "ambulance 🚑": [ "Please call an ambulance immediately, it's an emergency situation.", "Is the ambulance on its way? We need urgent medical assistance.", "How long will the ambulance take to arrive? The patient is in critical condition.", "We need an ambulance for the emergency, please hurry." ], "appointment 📅": [ "I need to schedule an appointment with the doctor as soon as possible.", "Can you check if there are any available slots for today? It's urgent.", "When is my next appointment? I need to plan my day accordingly.", "I want to reschedule my appointment to a later date. Can you help?" ], "bed 🛏️": [ "Can you help me adjust my bed? I need to be more comfortable.", "I need to elevate my headrest to help with my breathing.", "The bed feels uncomfortable, can it be fixed or adjusted?", "I need to change the bed position to relieve my back pain." ], "bathroom 🚻": [ "I need assistance to use the bathroom, can someone help me?", "Could you bring me a bedpan? I can't get up right now.", "Where is the nearest restroom? I need to go urgently.", "I feel weak; can you help me get to the bathroom safely?" ], "blood 🩸": [ "I need a blood test to check my hemoglobin levels.", "Can you check my blood sugar levels? I feel dizzy.", "When will the blood test results be ready? I need to know soon.", "Is this my blood pressure reading? It seems higher than usual." ], "cancer 🎗️": [ "I need to discuss my cancer treatment options with the doctor.", "Can you provide more information about my cancer diagnosis?", "I'm worried about my cancer prognosis, can you help me understand?", "When is my next chemotherapy session scheduled?" ], "dizziness 😵": [ "I'm feeling dizzy, can you check my blood pressure?", "The room is spinning, I need help.", "I feel lightheaded and dizzy, what should I do?", "Can you help me sit down? I'm feeling dizzy." ], "dose 💊": [ "What's the dose for this medication?", "I think I missed a dose, what should I do?", "Can I take a double dose to catch up?", "When should I take the next dose?" ], "emergency 🚨": [ "Please take me to the emergency room immediately, I can't wait.", "This is a critical emergency, we need help right now.", "I need immediate medical attention, please hurry.", "Call the emergency team quickly, the situation is getting worse." ], // ... more entries }
This dataset enables the system to go beyond simple letter recognition and provide contextually relevant phrases that are more useful in real-world medical communication.
Model Development: Training a Robust ASL Sign Recognizer
YOLOv8 was selected as the object detection model for this project because of its numerous advantages, including speed and accuracy, real-time performance, and ease of use.
YOLOv8 Architecture Overview
YOLOv8 follows a single-stage detection approach, dividing the input image into a grid. Each grid cell is responsible for predicting bounding boxes and class probabilities for potential objects. The architecture consists of:
-
Backbone: A convolutional neural network (CNN) that extracts features from the input image.
-
Neck: A series of layers that connect the backbone to the head, used for feature aggregation and refinement.
-
Head: The final layers predict bounding boxes, class probabilities, and objectness scores.

Figure 1. YOLOv8 Network Architecture Diagram | Source
Data Preparation
Load the dataset configuration file (data.yaml) using the load\_yaml function. This file specifies the paths to the training and validation sets, the number of classes (26 for A-Z), and the class names.
def load_yaml(dataset_path: str, yaml_filename: str) -> dict: """Loads data from a YAML file. Args: dataset_path: The path to the dataset directory. yaml_filename: The name of the YAML file. Returns: A dictionary containing the loaded YAML data. """ yaml_file_path = os.path.join(dataset_path, yaml_filename) try: with open(yaml_file_path, 'r') as file: yaml_content = yaml.safe_load(file) except FileNotFoundError: raise FileNotFoundError(f"YAML file not found: {yaml_file_path}") except yaml.YAMLError as e: raise ValueError(f"Error parsing YAML file: {e}") return yaml_content # Define the dataset path and YAML filename dataset_path = '/aug-asl-dataset' yaml_filename = 'data.yaml' # Load the YAML file yaml_content = load_yaml(dataset_path, yaml_filename) print(yaml.dump(yaml_content, default_flow_style=False))
Analyze the dataset using the analyze_images function to get information about the number of images and image sizes.
def analyze_images(dataset_path: str, data_type: str) -> tuple: """Analyzes image sizes and counts in a given dataset directory. Args: dataset_path: The path to the dataset directory. data_type: The type of data ('train' or 'valid'). Returns: A tuple containing the number of images and a set of unique image sizes. """ images_path = os.path.join(dataset_path, data_type, 'images') num_images = 0 image_sizes = set() try: for filename in os.listdir(images_path): if filename.endswith('.jpg'): num_images += 1 image_path = os.path.join(images_path, filename) with Image.open(image_path) as img: image_sizes.add(img.size) except FileNotFoundError: raise FileNotFoundError(f"Image directory not found: {images_path}") return num_images, image_sizes # Analyze the training images num_train_images, train_image_sizes = analyze_images(dataset_path, 'train') print(f"Number of training images: {num_train_images}") if len(train_image_sizes) == 1: print(f"All training images have the same size: {train_image_sizes.pop()}") else: print("Training images have varying sizes.") # Analyze the validation images num_valid_images, valid_image_sizes = analyze_images(dataset_path, 'valid') print(f"Number of validation images: {num_valid_images}") if len(valid_image_sizes) == 1: print(f"All validation images have the same size: {valid_image_sizes.pop()}") else: print("Validation images have varying sizes.")
Display sample images using the display_sample_images function to visually inspect the data.
def display_sample_images(images_path: str, num_samples: int = 8, grid_shape: tuple = (2, 4)) -> None: """Displays a grid of sample images from a directory. Args: images_path: The path to the directory containing images. num_samples: The number of sample images to display. grid_shape: The shape of the grid to display the images in (rows, columns). """ try: image_files = [file for file in os.listdir(images_path) if file.endswith('.jpg')] if len(image_files) < num_samples: raise ValueError(f"Not enough images in the directory to display {num_samples} samples.") # Select images at equal intervals num_images = len(image_files) selected_images = [image_files[i] for i in range(0, num_images, num_images // num_samples)] # Create a subplot fig, axes = plt.subplots(*grid_shape, figsize=(20, 11)) # Display each of the selected images for ax, img_file in zip(axes.ravel(), selected_images): img_path = os.path.join(images_path, img_file) image = Image.open(img_path) ax.imshow(image) ax.axis('off') plt.suptitle('Sample Images from Training Dataset', fontsize=20) plt.tight_layout() plt.show() except FileNotFoundError: raise FileNotFoundError(f"Image directory not found: {images_path}") # Display sample images from the training set train_images_path = os.path.join(dataset_path, 'train', 'images') display_sample_images(train_images_path)
Model Training
Load a pre-trained YOLOv8m model using model = YOLO('yolov8m.pt'). This provides a good starting point and speeds up training. Train the model using the train_yolo_model function. The YOLOv8 model was trained for 20 epochs, and the initial learning rate was set to 0.0001, with a final learning rate factor of 0.1. The optimizer is set to auto; Ultralytics automatically selects the best optimizer.
def train_yolo_model( yaml_file_path: str, epochs: int = 20, imgsz: int = 640, device: int = 0, patience: int = 50, batch: int = 32, optimizer: str = 'auto', lr0: float = 0.0001, lrf: float = 0.1, dropout: float = 0.1, seed: int = 0 ) -> YOLO: """Trains a YOLO model on a custom dataset. Args: yaml_file_path: Path to the dataset configuration file (data.yaml). epochs: Number of epochs to train for. imgsz: Size of input images as integer. device: Device to run on (i.e., cuda device=0). patience: Epochs to wait for no observable improvement for early stopping. batch: Number of images per batch. optimizer: Optimizer to use (choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]). lr0: Initial learning rate. lrf: Final learning rate (lr0 * lrf). dropout: Use dropout regularization. seed: Random seed for reproducibility. Returns: The trained YOLO model. """ try: model = YOLO('yolov8m.pt') # Load a pretrained YOLO model results = model.train( data=yaml_file_path, epochs=epochs, imgsz=imgsz, device=device, patience=patience, batch=batch, optimizer=optimizer, lr0=lr0, lrf=lrf, dropout=dropout, seed=seed ) return model except Exception as e: print(f"An error occurred during training: {e}") return None # Train the model yaml_file_path = os.path.join(dataset_path, 'data.yaml') trained_model = train_yolo_model(yaml_file_path)
We monitored the model's performance throughout the training process and assessed it using metrics like precision, recall, and mean Average Precision (mAP) Precision).
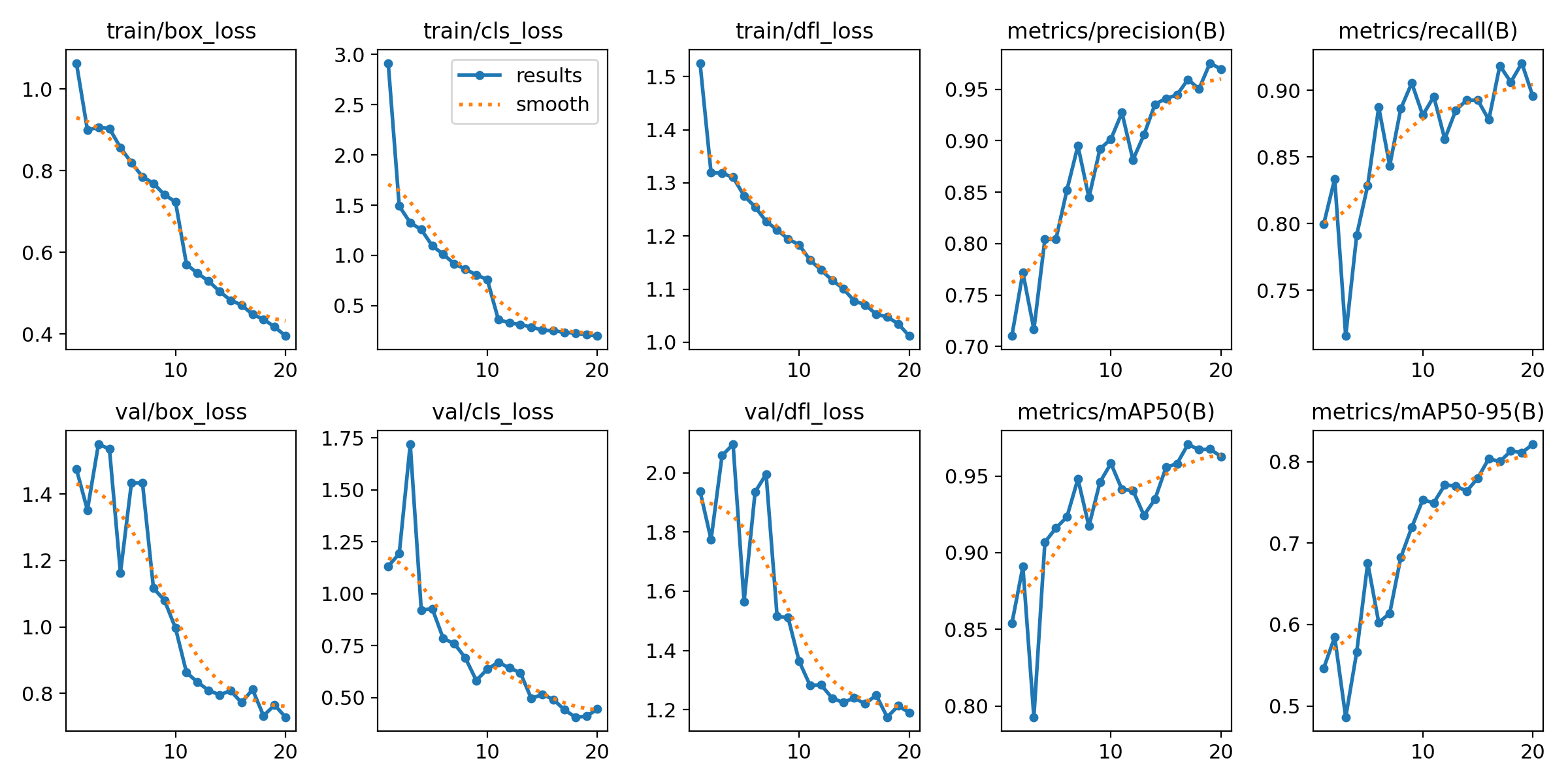
Figure 2. Results from YOLOv8 Model
Training Loss
train/box_loss: This graph shows the model's ability to localize the bounding boxes around the hand signs accurately. The decreasing trend shows that the model is learning to locate the hands more precisely over time.train/cls_loss: This represents the model's ability to classify the hand signs correctly into 26 different classes (A-Z). The consistent decrease in classification loss suggests that the model is more proficient at identifying the correct letters.train/dfl_loss: This indicates how well the model handles the uncertainty in bounding box predictions. A lower DFL loss suggests more confident and accurate predictions.
Validation Loss
val/box_loss: This metric measures the bounding box loss on the validation set, indicating how well the model generalizes to unseen data. While there are some fluctuations, the overall trend decreases, suggesting good generalization.val/cls_loss: Similar to the training classification loss, this shows the model's ability to classify ASL letters on the validation set. The decreasing trend indicates that the model is not overfitting to the training data and is learning to generalize well.val/dfl_loss: This reflects the model's confidence in bounding box predictions on unseen data.
Validation Inference
Evaluate the trained model on the validation set using the display_validation_inferences function. This provides a visual assessment of the model's performance on unseen data.
def display_validation_inferences(model: YOLO, dataset_path: str, num_samples: int = 9) -> None: """Displays inferences on sample images from the validation set. Args: model: The trained YOLO model. dataset_path: The path to the dataset directory. num_samples: The number of sample images to display. """ if model is None: print("Model not trained. Skipping validation inference.") return valid_images_path = os.path.join(dataset_path, 'valid', 'images') try: # List all jpg images in the directory image_files = [file for file in os.listdir(valid_images_path) if file.endswith('.jpg')] if len(image_files) < num_samples: raise ValueError(f"Not enough images in the directory to display {num_samples} samples.") # Select images at equal intervals num_images = len(image_files) selected_images = [image_files[i] for i in range(0, num_images, num_images // num_samples)] # Initialize the subplot fig, axes = plt.subplots(3, 3, figsize=(20, 21)) fig.suptitle('Validation Set Inferences', fontsize=24) # Perform inference on each selected image and display it for i, ax in enumerate(axes.flatten()): image_path = os.path.join(valid_images_path, selected_images[i]) results = model.predict(source=image_path, imgsz=640, conf=0.5) annotated_image = results[0].plot(line_width=1) annotated_image_rgb = cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB) ax.imshow(annotated_image_rgb) ax.axis('off') plt.tight_layout() plt.show() except FileNotFoundError: raise FileNotFoundError(f"Image directory not found: {valid_images_path}") # Display inferences on validation set display_validation_inferences(trained_model, dataset_path)

Figure 3. Validation Results
After validation, the trained model is saved to a .pt file for later use without retraining.
Gradio Interface
The Gradio interface provides a user-friendly way to interact with the trained ASL recognition model and the text-to-speech functionality. The interface includes the following components:
-
Live Webcam Input: Captures video from the user's webcam using
gr.Image(sources=["webcam"]). -
Capture Sign Button: Triggers the
webcam_predictfunction to process the current frame from the webcam. -
Detection Results Textbox: Displays the detected ASL letters using
gr.Textbox(label="Detection Results"). -
Word Dropdown: Presents a list of potential medical words based on the detected letters, allowing the user to select the intended word. This is implemented using
gr.Dropdownand dynamically updated based on predictions. -
Phrase Dropdown: Displays a list of contextual phrases associated with the selected word, allowing the user to choose the phrase they want to communicate. This is also implemented using
gr.Dropdownand is dynamically updated. -
Audio Output: Plays the generated speech for the selected phrase using
gr.Audio(label="Speech Output"). -
Speak Selected Phrase Button: Triggers the
speak_selected_phrasefunction to generate and play the audio for the selected phrase. -
Reset Button: Clears the detection buffers and resets the interface to its initial state using the
reset_recognitionfunction. -
Final Phrase Textbox: Displays the selected phrase before sending it to the TTS engine.
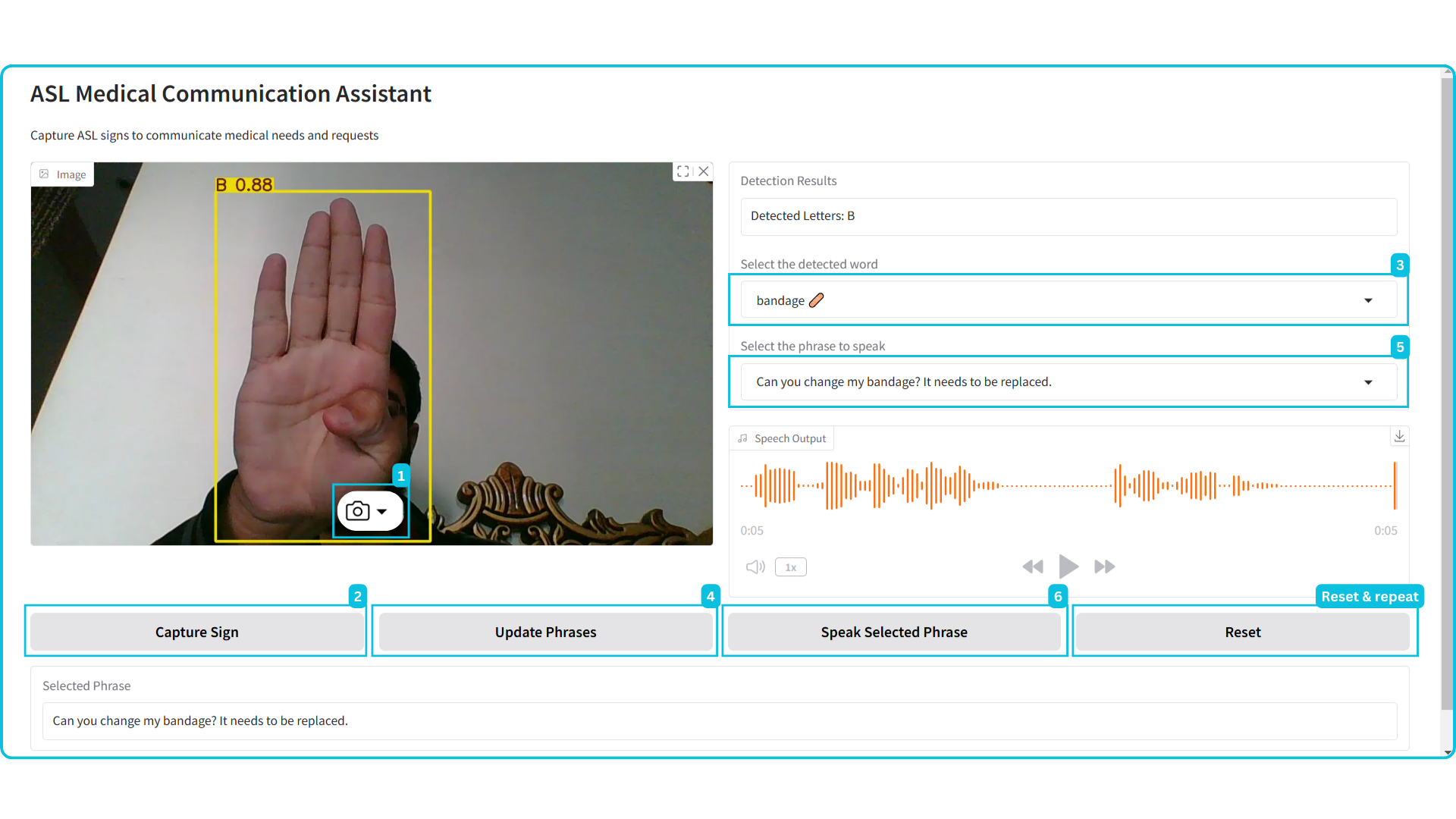
Figure 4. Gradio Interface
ASL TTS Integration
The Bark text-to-speech model powers the ASL TTS functionality, and we can install the Bark TTS library directly from its GitHub repository.
!pip install gradio ultralytics git+https://github.com/suno-ai/bark.git
Loading Medical Phrases
We use a JSON file to store medical phrases. The load_medical_phrases function loads these phrases into a Python dictionary.
def load_medical_phrases(file_path): """ Load medical phrases from a JSON file """ try: with open(file_path, 'r') as file: return json.load(file) except Exception as e: print(f"Error loading medical phrases: {e}") return {}
Generating Speech
def generate_speech(text, audio_dir="generated_audio"): """ Generate speech from text using Bark """ if not text: return None audio_array = generate_audio( text, history_prompt="v2/en_speaker_6", text_temp=0.5, waveform_temp=0.6 ) timestamp = int(time.time()) os.makedirs(audio_dir, exist_ok=True) audio_path = os.path.join(audio_dir, f"speech_{timestamp}.wav") write_wav(audio_path, SAMPLE_RATE, audio_array) return audio_path
This function takes text as input and uses the generate_audio function from Bark to synthesize speech.
text: The text to be converted to speech.history_prompt: Specifies the speaker or voice style. Here, "v2/en_speaker_6" is used, an English speaker model in Bark's v2 version. You can experiment with different prompts to change the voice.text_temp: Controls the creativity or randomness of the text generation (higher values lead to more variation).waveform_temp: Controls the variability of the generated audio waveform.
The function saves the generated audio as a WAV file with a timestamp in the specified audio_dir and returns the file path.
ASL Medical Recognizer Class: Orchestrating System Functionality
This class now initializes the Bark TTS models by calling them preload_models(). It loads the necessary models into memory for faster audio generation.
class ASLMedicalRecognizer: def __init__(self, model_path, confidence_threshold=0.5, buffer_size=5): """ Initialize the ASL Medical Word Recognizer with contextual TTS """ self.model = YOLO(model_path) self.confidence_threshold = confidence_threshold self.labels = [ 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z' ] self.medical_phrases = load_medical_phrases("/phrases.json") self.medical_words = set(self.medical_phrases.keys()) self.prediction_buffer = [] self.buffer_size = buffer_size # Initialize Bark TTS print("Loading Bark TTS models...") preload_models() print("Bark TTS models loaded successfully!") def detect(self, frame): """ Perform detection on a single frame """ results = self.model.predict( source=frame, conf=self.confidence_threshold, device=0 #if GPU available ) detected_letters = [] for result in results: boxes = result.boxes if len(boxes) > 0: for box in boxes: cls = int(box.cls[0]) conf = float(box.conf[0]) if conf > self.confidence_threshold: detected_letter = self.labels[cls] detected_letters.append(detected_letter) annotated_frame = results[0].plot() if results else frame return annotated_frame, detected_letters def find_potential_medical_words(self, letters): """ Find potential medical words from a sequence of letters """ prefix = ''.join(letters).lower() if not prefix: return [] potential_matches = [ word for word in self.medical_words if word.startswith(prefix) and len(word) >= len(prefix) ] return potential_matches[:5] def get_contextual_phrase(self, word): """ Get a contextual phrase for the selected medical word """ if word in self.medical_phrases: return random.choice(self.medical_phrases[word]) return word def process_captured_image(self, image): """ Process a captured image and return results """ annotated_frame, detected_letters = self.detect(image) if detected_letters: self.prediction_buffer.extend(detected_letters) if len(self.prediction_buffer) > self.buffer_size * 3: self.prediction_buffer = self.prediction_buffer[-self.buffer_size * 3:] potential_words = self.find_potential_medical_words(self.prediction_buffer) # Get phrases for all potential words word_phrases = {word: self.get_contextual_phrase(word) for word in potential_words} return annotated_frame, detected_letters, potential_words, word_phrases return annotated_frame, [], [], {} def reset_buffers(self): """ Reset prediction buffer """ self.prediction_buffer.clear()
- The
detectmethod to process video frames and identify ASL signs. - The
Find_potential_medical_wordsfunction filters themedical_wordsto find words that start with the sequence of detected letters (theprefix). It returns up to 5 potential matches. - The
get_contextual_phrasefunction retrieves a phrase associated with the selectedwordfrom themedical_phrasesdictionary. If no phrase is found for the word, it simply returns the word itself. - The
process_captured_imagemethod combines the detection and phrase retrieval logic. - The
reset_buffers methodis used to clear the prediction buffer.
Gradio Interface: Facilitating User Interaction and Real-Time Feedback
Gradio interface provides a user-friendly way to interact with the ASL recognition and TTS system. This helps users to capture signs, select predicted words and phrases, and generate speech output.
Interface Components: Webcam Input, Text Displays, and Interactive Controls
def create_asl_interface(model_path): """ Create Gradio interface for ASL medical communication """ recognizer = ASLMedicalRecognizer(model_path) def webcam_predict(image): """ Process webcam input and update interface components """ if image is None: return None, "No image captured", [], gr.Dropdown(choices=[]), gr.Dropdown(choices=[]) annotated_frame, detected_letters, potential_words, word_phrases = recognizer.process_captured_image(image) detection_text = f"Detected Letters: {', '.join(detected_letters)}" word_choices = potential_words if potential_words else [] word_dropdown = gr.Dropdown( choices=word_choices, value=word_choices[0] if word_choices else None, interactive=True, label="Select the detected word" ) phrase_dropdown = gr.Dropdown( choices=[], value=None, interactive=True, label="Select the phrase to speak" ) return annotated_frame, detection_text, word_dropdown, phrase_dropdown def update_phrases(selected_word): """ Update phrase dropdown based on the selected word """ if selected_word: phrases = recognizer.medical_phrases.get(selected_word, []) return gr.Dropdown( choices=phrases, value=phrases[0] if phrases else None, interactive=True, label="Select the phrase to speak" ) return gr.Dropdown(choices=[], interactive=True, label="Select the phrase to speak") def speak_selected_phrase(selected_phrase): """ Generate speech for the selected phrase """ if selected_phrase: audio_path = generate_speech(selected_phrase) return selected_phrase, audio_path return "", None def reset_recognition(): """ Reset all components """ recognizer.reset_buffers() empty_word_dropdown = gr.Dropdown(choices=[], interactive=True, label="Select the detected word") empty_phrase_dropdown = gr.Dropdown(choices=[], interactive=True, label="Select the phrase to speak") return "Buffers reset. Ready for new recognition.", None, empty_word_dropdown, empty_phrase_dropdown with gr.Blocks() as demo: gr.Markdown("# ASL Medical Communication Assistant") gr.Markdown("Capture ASL signs to communicate medical needs and requests") with gr.Row(): webcam = gr.Image(sources=["webcam"]) with gr.Column(): detection_output = gr.Textbox(label="Detection Results") word_dropdown = gr.Dropdown(choices=[], label="Select the detected word", interactive=True) phrase_dropdown = gr.Dropdown(choices=[], label="Select the phrase to speak", interactive=True) audio_output = gr.Audio(label="Speech Output") with gr.Row(): capture_btn = gr.Button("Capture Sign") update_btn = gr.Button("Update Phrases") speak_btn = gr.Button("Speak Selected Phrase", interactive=True) reset_btn = gr.Button("Reset") final_phrase = gr.Textbox(label="Selected Phrase") capture_btn.click( webcam_predict, inputs=webcam, outputs=[webcam, detection_output, word_dropdown, phrase_dropdown] ) update_btn.click( update_phrases, inputs=word_dropdown, outputs=phrase_dropdown ) speak_btn.click( speak_selected_phrase, inputs=phrase_dropdown, outputs=[final_phrase, audio_output] ) reset_btn.click( reset_recognition, outputs=[detection_output, audio_output, word_dropdown, phrase_dropdown] ) return demo
Update_phrases function updates the phrase_dropdown based on the selected_word from the word_dropdown. It retrieves the list of phrases associated with the selected word and updates the dropdown choices accordingly.
Launch Gradio Interface
The main function sets the path to the trained YOLOv8 model, creates the Gradio interface using create_asl_interface, and launches the application.
def main(): model_path = '/model_path.pt' demo = create_asl_interface(model_path) demo.launch(debug=True) if __name__ == '__main__': main()
Conclusion and Future Directions
We have successfully developed an ASL alphabet recognition system that translates signs into medical words and speaks associated phrases. It uses the YOLOv8 object detection model for accurate sign recognition, a custom medical phrases dataset for contextual relevance, and the Bark text-to-speech model for natural-sounding audio output. The Gradio interface provides a user-friendly way to interact with the system, making it accessible to both ASL users and medical professionals.
Future Research Direction
Future development of the system will focus on:
- Expanded Vocabulary: The current system focuses on the ASL alphabet and a limited set of medical phrases. Expanding the vocabulary to include full ASL signs and a broader range of medical terms would greatly enhance its utility.
- Multi-lingual Support: Adding support for other sign and spoken languages would broaden the system's applicability and impact.
- Real-time Sentence Construction: Implementing natural language processing (NLP) techniques to construct grammatically correct sentences from the recognized signs would make communication more fluid and natural.
- Integration with Electronic Health Records (EHRs): Integrating the system with EHRs could streamline documentation and improve information sharing among medical professionals.