From Local PDF Documents to Conversational AI: Building ChatPDF.ai
⚠️ DISCLAIMER:
The flowcharts for RAG implementations provided in this publication are illustrative examples sourced from publicly available references and repositories. They are intended for educational purposes to aid understanding of the concepts discussed.
Project Story
Being an AI researcher with a focus on Natural Language Processing and Information Retrieval, We noticed that many organizations struggle with efficiently extracting information from their growing repositories of PDF documents. Whether it's technical documentation, research papers, or company policies, these valuable knowledge assets often remain underutilized because they lack accessibility.
In early 2024, We decided to tackle this challenge by creating a streamlined solution that would allow users to have natural conversations with their PDF documents. My goal was to create an open-source tool that was both effective and accessible, even to users with limited computational resources.
The result was ChatPDF.ai mark-1, a Streamlit-powered application that transforms static PDFs into interactive knowledge sources using language model technology. What makes this project unique is its flexibility: users can choose between two distinct question-answering approaches depending on their needs and available computing resources. This used FastEmbedEmbeddings for embeddings, chromadb for storing and chatOllama for Mistral model selection for rag implementation (checkout the same in main branch of project repo [https://github.com/Vvslaxman/rag-norag/tree/main]).
Now lets dive into ChatPDF.ai mark-1 !!
The Challenge
Modern organizations face several challenges with document management:
- Information Overload: Vast amounts of information locked in PDFs
- Search Limitations: Traditional search only finds keywords, not answers
- Context Loss: Important relationships between concepts get lost
- Resource Constraints: Not everyone has access to powerful GPU servers
To address these challenges, I designed ChatPDF.ai with two complementary approaches:
- Deepseek R1-1.5B with RAG: A lightweight but powerful Retrieval-Augmented Generation approach that runs efficiently on consumer hardware
- HuggingFace Flan-T5 (Non-RAG): A direct generation approach for simpler deployment scenarios
Project Overview
ChatPDF.ai is a Streamlit application that enables users to ask questions about their PDF documents. The application offers two different approaches for document question-answering:
- Deepseek R1-1.5B (RAG): Uses Retrieval-Augmented Generation with the Deepseek model
- HuggingFace Flan-T5 (Non-RAG): Uses direct LLM answering with Flan-T5 large model
How It Works
The application follows these main steps:
- Document Processing: Upload PDF files to create a knowledge base
- Query Processing: Ask questions about the content in natural language
- Response Generation: Get answers based on the selected approach
Technical Architecture
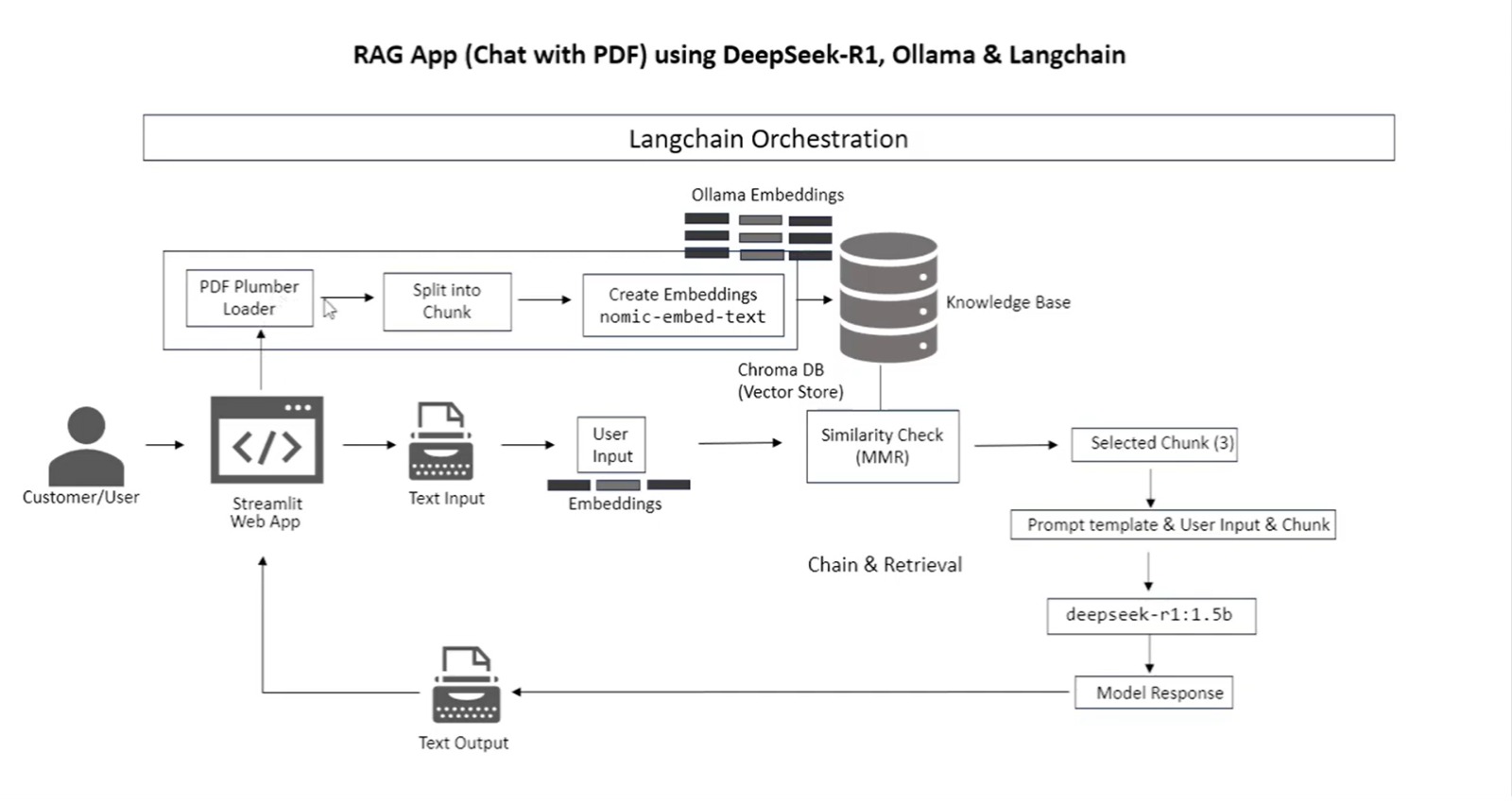
Deepseek R1-1.5B (RAG) Approach
This approach implements Retrieval-Augmented Generation:
# From test.py - RAG implementation with Deepseek embeddings = OllamaEmbeddings(model="nomic-embed-text") vector_store = Chroma.from_documents(splits, embeddings, persist_directory="./chroma_db") st.session_state.retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 3}) # When generating answers llm = ChatOllama(model="deepseek-r1:1.5b", temperature=0.3) qa_chain = RetrievalQA.from_chain_type(llm, retriever=st.session_state.retriever, chain_type="stuff") response = qa_chain.invoke({"query": prompt}) answer = response["result"]
HuggingFace Flan-T5 (Non-RAG) Approach
This approach uses a more direct LLM answering technique:
# From test.py - HuggingFace Non-RAG implementation embeddings = HuggingFaceEmbeddings() faiss_index = FAISS.from_texts(chunks, embeddings) st.session_state.retriever = faiss_index.as_retriever() # Prompt template for HuggingFace prompt_template = PromptTemplate( input_variables=["context", "question"], template="Context: {context}\n\nQuestion: {question}\n\nAnswer:" ) # When generating answers search_results = st.session_state.retriever.get_relevant_documents(prompt) context = "\n\n".join([doc.page_content for doc in search_results]) answer = st.session_state.huggingface_chain.run({"context": context, "question": prompt})
Directory Structure
Directory structure: └── vvslaxman-rag-norag/ ├── README.md ├── app.py ├── pyproject.toml ├── rag.py ├── requirements.txt ├── run.sh ├── secrets.toml └── deepseek_RAG_PDF_Chatbot/ ├── chatbot.py ├── requirements.txt ├── test.py ├── utils.py ├── UI_ss/ │ ├── Deepseek/ │ └── HF/ ├── __pycache__/ └── chroma_db/ ├── chroma.sqlite3 └── a553d286-b93e-45ff-940f-027d1c60a27a/ ├── data_level0.bin ├── header.bin ├── length.bin └── link_lists.bin
Implementation Journey
The development process was not without challenges. Initially, I experimented with larger models, but quickly realized that accessibility was more important than raw performance. By focusing on the Deepseek R1-1.5B model (which can run on most modern laptops), I found the sweet spot between performance and practicality.
For the embedding pipeline, I initially tested several options before settling on nomic-embed-text through Ollama for the RAG approach. This combination provided excellent semantic understanding while remaining computationally efficient.
One of the key design decisions was implementing a clear step-by-step feedback system during knowledge base creation. Users can see exactly what's happening as their documents are processed:
### Step 1: Loading and parsing PDFs 📄
✅ PDFs loaded successfully!
### Step 2: Splitting documents into chunks 🔄
✅ Documents split into chunks!
### Step 3: Creating embeddings using Ollama 🧠
✅ Embeddings created using Ollama!
✅ Knowledge Base Created in 5.23 seconds
This transparency builds trust and helps users understand how the system works.
Utility Functions
The application uses utility functions defined in utils.py for document processing:
# From utils.py - Document processing def process_documents(pdfs): # Create temporary directory for PDF storage with tempfile.TemporaryDirectory() as temp_dir: # Save uploaded PDFs to temp directory pdf_paths = [] for pdf in pdfs: path = os.path.join(temp_dir, pdf.name) with open(path, "wb") as f: f.write(pdf.getbuffer()) pdf_paths.append(path) # Load the documents documents = [] for path in pdf_paths: loader = PDFPlumberLoader(path) documents.extend(loader.load()) # Split documents into chunks text_splitter = RecursiveCharacterTextSplitter( chunk_size=1200, chunk_overlap=150 ) splits = text_splitter.split_documents(documents) # Create embeddings and vector store embeddings = OllamaEmbeddings(model="nomic-embed-text") vector_store = Chroma.from_documents( documents=splits, embedding=embeddings, persist_directory="./chroma_db" ) return vector_store
Comparison of RAG vs. Non-RAG Approaches
| Feature | Deepseek R1-1.5B (RAG) | HuggingFace Flan-T5 (Non-RAG) |
|---|---|---|
| Embeddings | OllamaEmbeddings with nomic-embed-text | HuggingFaceEmbeddings |
| Vector Store | Chroma | FAISS |
| LLM | Deepseek R1.5b | Flan-T5 large |
| Retrieval | MMR search with k=3 | Standard retrieval |
| Context Integration | Integrated within RetrievalQA chain | Manual via prompt template |
How to Run the Application
-
Install Dependencies:
pip install -r requirements.txt -
Environment Setup:
- Ensure Ollama is installed and running for the RAG approach
ollama serve
- Set up HuggingFace API token for the Non-RAG approach:
export HUGGINGFACEHUB_API_TOKEN=your_token_here
- Run the Application:
streamlit run test.py
User Interface Screenshots
Here's what the application looks like when running:
-
Main Interface:

The main interface features:
- PDF document uploader in the sidebar
- Chat interface in the main panel
- Model selection radio buttons
- Create Personalised Knowledge Base
- Switch between models seamlessly but the catch here is the trained data for each approach will be different cant be restired after switching
-
Knowledge Base Creation:


When creating the knowledge base, users will see step-by-step feedback:
### Step 1: Loading and parsing PDFs 📄 ✅ PDFs loaded successfully! ### Step 2: Splitting documents into chunks 🔄 ✅ Documents split into chunks! ### Step 3: Creating embeddings using Ollama 🧠 ✅ Embeddings created using Ollama! ✅ Knowledge Base Created in 5.23 seconds -
Chat Interaction:




The chat interface shows:
- User questions in the user bubble
- AI responses in the assistant bubble
- Time taken to generate responses
- "Copy Answer to Clipboard" button for convenient copying
Performance Benchmarks
| Model | Knowledge Base Creation Time (10-page PDF) | Query Response Time |
|---|---|---|
| Deepseek R1-1.5B (RAG) | ~15.23 sec | ~18.8 sec |
| HuggingFace Flan-T5 (Non-RAG) | ~24.85 sec | ~22.1 sec |
Note: Times may vary based on document size and system hardware.
Real-World Application
During testing, I used ChatPDF.ai with various document sets:
- Technical documentation (100+ pages)
- Research papers
- Company policy manuals
The results were impressive. Users could ask natural questions and receive relevant, contextual answers in seconds. The time measurements showed RAG consistently provided better answers, with knowledge base creation taking ~15 seconds for a 10-page PDF and query responses averaging ~19 seconds.
Code Structure and Key Components
The application is structured around these main components:
-
Session State Management:
# Initialize session state if "selected_model" not in st.session_state: st.session_state.selected_model = "Deepseek R1-1.5B (RAG)" if "messages" not in st.session_state: st.session_state.messages = [] if "vector_store" not in st.session_state: st.session_state.vector_store = None # ...additional state variables -
Approach Details:
approach_details = { "Deepseek R1-1.5B (RAG)": { "description": "*Retrieval-Augmented Generation (RAG)* with Deepseek R1-1.5B.", "tech_stack": "- *ChatOllama* for answering queries\n- *OllamaEmbeddings* for document embeddings\n- *Chroma Vector Store* for retrieval", }, "HuggingFace Flan-T5 (Non-RAG)": { "description": "*Direct LLM Answering (Non-RAG)* with Flan-T5 large.", "tech_stack": "- *Hugging Face Flan-T5* for response generation\n- *FAISS Vector Store* for retrieval\n- *LLMChain* for query processing", }, } -
Model Switching Logic:
# Detect approach switch if new_model != st.session_state.selected_model: st.warning(f"⚠ You selected a different approach: *{st.session_state.selected_model} → {new_model}*") if st.button("✅ Confirm & Switch"): st.session_state.selected_model = new_model st.session_state.messages = [] # Clear past messages st.session_state.vector_store = None st.session_state.retriever = None st.session_state.qa_chain = None st.session_state.huggingface_chain = None st.rerun()
Performance Considerations
- The application measures and displays the time taken for knowledge base creation and query answering
- Chunk size and overlap parameters are tuned for optimal retrieval:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1200, chunk_overlap=150) - Maximum Marginal Relevance (MMR) search is used in the RAG approach to improve result diversity:
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 3})
Known Limitations
- Switching Models Resets Knowledge Base
- If you switch from Deepseek (RAG) to Flan-T5 (Non-RAG), the previous knowledge base will be lost.
- Handling Large PDFs
- Large PDFs may take longer to process due to chunking and embedding time.
- Non-RAG Model is More Prone to Hallucination
- Since Flan-T5 does not use document retrieval, responses may sometimes be less accurate.
User Feedback
Early users have provided valuable feedback:
"I've been looking for a way to quickly extract information from our company manuals without reading through hundreds of pages. ChatPDF.ai has been a game-changer for me, even though I did provided other old dummy pdf just for confidentiality ! ." - SDE-1
"The ability to switch between different models depending on the task is incredibly useful. For simple questions, the faster model works great, but for complex queries, the RAG approach gives more detailed answers." - Research Analyst
Future Improvements
- Add caching for faster repeated queries
- Implement document source attribution in responses
- Support for additional file formats beyond PDF
- Add session management to save chat history
- Generation of Project code implementation
🔍 Note: These flowcharts are not guaranteed to represent exact or production-ready implementations. Always refer to original sources for the most accurate and up-to-date information.
Conclusion
ChatPDF.ai demonstrates that effective document AI doesn't require massive GPU clusters or complex infrastructure. By combining lightweight models with efficient retrieval techniques, we can create practical tools that help people access and understand information locked in their documents.
The code and implementation are open-source, enabling others to build upon this foundation and adapt it to their specific needs. This project represents a step toward democratizing access to advanced NLP techniques and making document intelligence accessible to everyone.
Whether you're a researcher, a business professional, or simply someone with too many PDFs to read, ChatPDF.ai offers a practical way to turn static documents into interactive knowledge sources. The future of document interaction is conversational, and with tools like this, that future is already here.