It is getting increasingly complicated and expensive to train models that detect images generated by AI. To tackle this issue, we work on utilising the discriminative model present in the generative models called Generative Adversarial Networks to work as efficient detectors of AI generated images. We separate out the discriminator, modify and retrain it to fit the classification task. In comparison to other more complex detection models, our model obtains an accuracy close to these models while still being computationally less expensive to train. Code is available at https://github.com/sanyamjain0315/generated-image-detection.
The pace at which newer image generative models are being released is beyond the pace of creating systems and models that detect their work. These models can pose a threat if in the hands of bad actors. They could be used to create profile pictures of fake accounts, ones that seem real enough to gullible people and scam them. They can also be used to perpetuate fake art, where one person could wrongfully sell AI generated art under the guise of real art and reap the benefits.
There has been success with utilising pre-trained models such as the Resnet architecture [4, 8, 9, 10], the VGG net architecture, and other such models, with the addition of data enriching and augmentation techniques to improve the performance [3, 10]. However, with newer generative models being released every week, these detection models need to be re-trained more times, increasing the net computation cost to keep these detection models up to date.
To eliminate the need of retraining complex and excessively large detection models, we decided to explore the feasibility of obtaining a discriminative model right alongside the generative model to detect it. Generative Adversarial Networks are a marvel of generative networks, some of the very first image generation models that actually produced good results. Over the years there have been many refinements to these models, that is, the development of Wasserstien GANs, Conditional GANs, ProGANs, StyleGANs, etc, each model better than the last. What has stayed the same is the basic methodology of using two networks [11]. They consist of the generator, the main model to be used for downstream generation tasks, and the discriminator or critic model, that is locked in a game-playing manner with the generator to improve its performance. In our paper, we specifically look at the discriminator that is left after the GAN training and modify it to perform as an independent detection model, one that does not require as many parameters as other pre-trained architectures.
The reason we chose this method is that since the discriminator network is accustomed to not just the final generated images of the generator, but also the type of images generated throughout, the model could in theory perform better than a model that has just seen the generator’s end result. We test it against models of similar size as well as larger discriminative models.
In summary our contributions are the retraining and repurposing of the discriminator network of a GAN, particularly Wasserstein GAN, to work as an actual detector of AI generated images, saving the need for creating a detection network from scratch.
##Utilisation of GAN directly for classification.
As far as we know, there have been two papers that have explored the possibility of using a GAN as a classifier, Meng et al. [2] and Zhu et al. [3]. Both works trained a GAN model and later utilised it for both, in the case of Zhu et al., binary as well as multi-class classification.
Meng et al. trained a convolutional GAN on the MNIST dataset. Since MNIST data has 10 classes for each numeric digit, while the discriminator in the GAN was only trained for binary classification, the discriminator was modified and trained for a few further epochs to enable multi-class classification. Zhu et al. did something similar, creating two classification frameworks called 1D-GAN(for spectral classification) and 3D-GAN (for spectral-spatial classification). Due to the unique dataset of Hyper Spectral Images (HSI), these frameworks performed Principal Component Analysis (PCA) of the dataset to make GAN training easier. They trained these GAN models on a vast HSI dataset and utilised the discriminators from these models for classification, not just as real or fake but also for identifying the spectral class. They fine-tuned the frameworks with generated images as a new class (N+1) in the dataset. Finally, they also applied the GAN as a regularization technique to CNN classifiers [3], expanding the training data for other classification models, yielding better results.
However, both papers had limitations of their own. Meng et al. did test the classification capabilities of GAN, but the task of classifying MNIST data was not complex enough to determine the viability of the methodology for real world use cases. It is possible that the discriminator may have overfit to the dataset as well as the generator, with there being no validation losses provided. Furthermore, all layers except the last layer were frozen during the discriminator retraining [2]. We believe this would not allow the model to fit to the multi-class classification task without also overfitting. Zhu et al. did an excellent job of applying the GAN frameworks to more complex tasks. However, they applied the fine-tuning process to the entire GAN framework, instead of just the discriminator [3], which could lead to the generator learning from itself and throwing off the discriminator in theory, since the distribution of real images was modified.
Moreover, both papers utilised convolutional GANs such as the DCGAN, whose training process is unstable [8], leading to longer and more expensive training times.
Zhu et al. also tested the capabilities of using GANs as a data augmentation tool to further improve the accuracy of their proposed models. They found the accuracy after data augmentation to be better than without, stating that additional fake samples can improve classification performance [3]. Ma et al. studied this individually and in the context of blood cell image classification. They use the DC-GAN to solve the problems of insufficient data samples, unbalanced data, and missing data labels and reduce the influence from out-of-distribution inputs [9]. In many of the different types of cells they achieved a better classification accuracy for their discriminative Resnet model that was trained with GAN augmented images, while the ones without augmentation performed worse. This gives strength to the point that generative models can improve the accuracy of discriminative models in one form or another.
Papers such as Epstien et al. and Wang et al. test CNN based classifiers to detect images from generative models such as GANs, Diffusers, and other CNN-generation models. Epstein et al, utilised the Resnet50 architecture as a classifier. They trained this model progressively to simulate an online environment, where new models for generation are released periodically. They train it across 14 generative models which achieve the ability of generalizing to other models [4]. Wang et al. specifically tests the generalizing capability of models trained on a specific set of images from a particular generative model. They too utilise the Resnet50 architecture and train it on just the ProGAN images and test it on images of other models. They also study the effect of data augmentation on generalization and robustness. They found positive results too with the CNN based classifier, achieving good generalization across all generative models [10].
The proposed system can be classified into two main parts; training of the Wasserstein Generative Adversarial Network, and modification of the critic into a discriminator and fine tuning. We first train the WGAN on the real images from our dataset, with the aim of creating a generator as well as the critic. The goal of the critic is to learn the features of a real image indirectly from a generator as well as model the learning process of the generator up to the point where it can generate realistic looking images. We then modify the critic into a discriminator that can perform binary classification of images, and fine tune it on real and generated images to determine the optimal weights for the modified layers.
We utilised the real images of the dataset from [1], which had 70000 real faces in total. For the purposes of training and fine tuning of the models outlined in our research. We sampled 25000 real images for training specifically, which for validation and testing we sampled 5000 each. The fake images for the fine tuning of our discriminator will be obtained from the generator model itself.
WGAN Training Process
We chose the Wasserstein GAN over the Deep Convolutional GAN due to the proven stability of WGAN. We utilised the architecture and training parameters outlined in Gulrajani et al. [7] to create the generative network. The WGAN involves two networks; the generator which generates new images depending on the input vector, and the critic which scores the input images as real or fake. The WGAN employs the Wasserstein loss, constructed using the Kantorovich-Rubinstein duality [7] to obtain
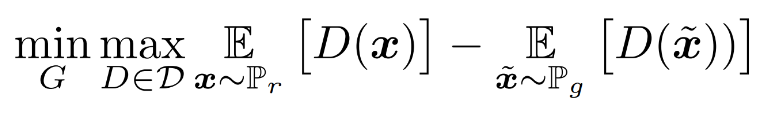
where D is the set of 1-Lipschitz functions and Pg is the model distribution implicitly defined by x˜ = G(z), z ∼ p(z). In that case, under an optimal discriminator (called a critic in the paper, since it’s not trained to classify), minimizing the value function with respect to the generator parameters minimizes W(Pr, Pg). [7]
They also propose an alternative way to enforce the Lipschitz constraint. A differentiable function is 1-Lipschtiz if and only if it has gradients with norm at most 1 everywhere, so they consider directly constraining the gradient norm of the critic’s output with respect to its input. To circumvent tractability issues, they enforce a soft version of the constraint with a penalty on the gradient norm for random samples xˆ ∼ Pxˆ. The new objective is
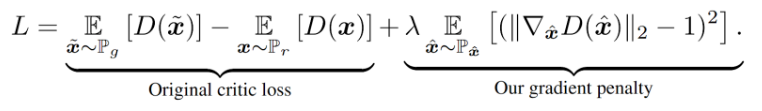
We also followed their practice of using λ = 10 and also did not implement batch normalisation in the critic, since in our findings it led to worse results, in line with the paper.
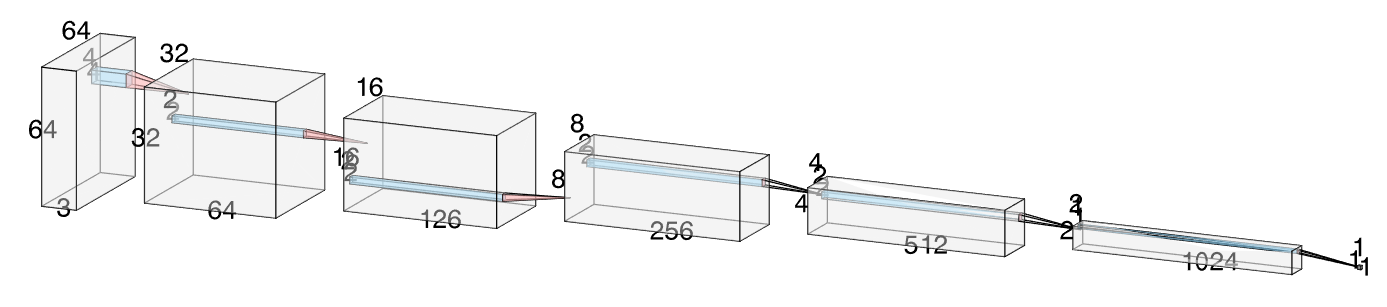
Figure 1: Discriminator architecture in WGAN
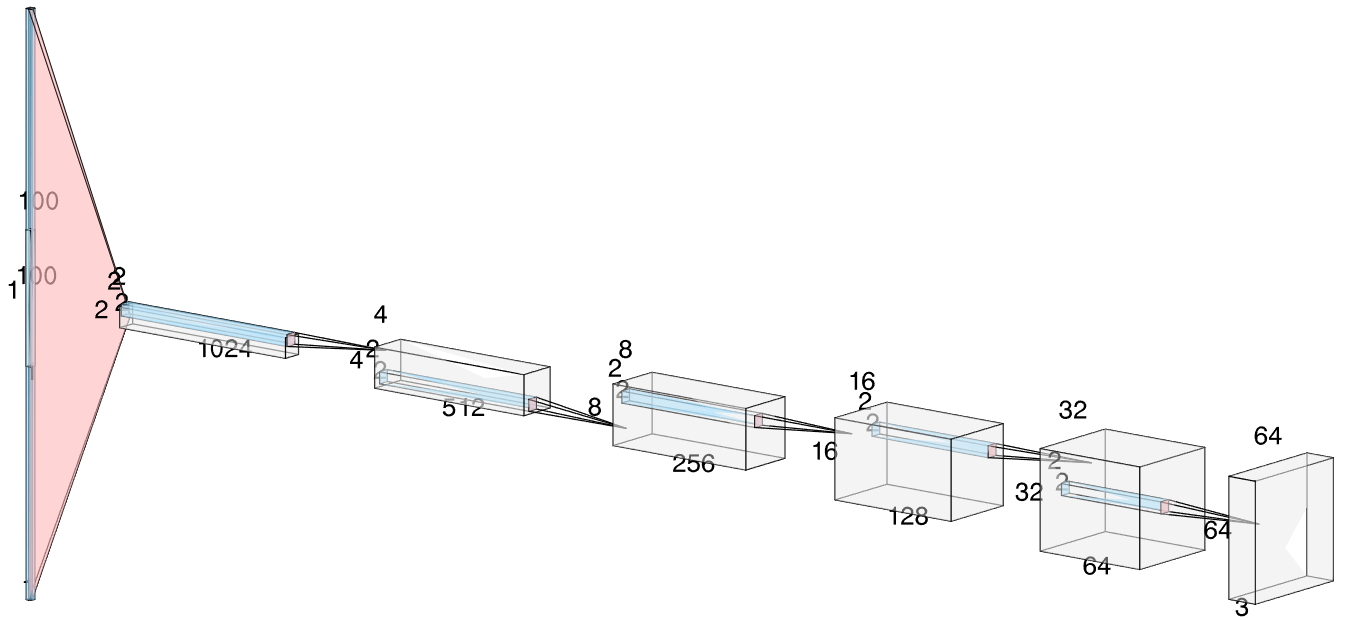
Figure 2: Generator architecture used in WGAN
We trained the WGAN on 25000 randomly sampled real images from [1], keeping the batch size of 256. We trained the WGAN for 30 epochs with the Adam optimizer at a learning rate of 0.0001 and betas 1 and 2 being 0 and 0.9 respectively, with the critic iteration of 5, meaning for every generator epoch the critic was trained 5 times. The input random noise to the generator had 100 values sampled from a normal distribution with mean 0 and variance 1.
Fine-tuning of discriminator
After WGAN training, we separate the critic out from it. The critic in its current state only has a linear output, meaning it cannot work as a classifier yet. We modify the critic into a discriminator by adding a flatten as well as a sigmoid layer to enable binary classification. We used weights from the pre-trained critic model to be further tuned according to the newly added layer. The notion behind this was to preserve the knowledge of the training process of a generator in the model and fine tune it for the classification task.
The discriminator model was trained for 10 epochs with the same learning rate parameters as in the WGAN. It also similarly made use of the Adam optimizer and BCE loss. We also utilised the same training so as to not give the discriminator out of domain knowledge and utilised a validation set during training.
After around 30 epochs, the WGAN achieved Nash equilibrium where the loss of neither the generator nor the critic was improving significantly, and the images being produced by the generator could be considered real.
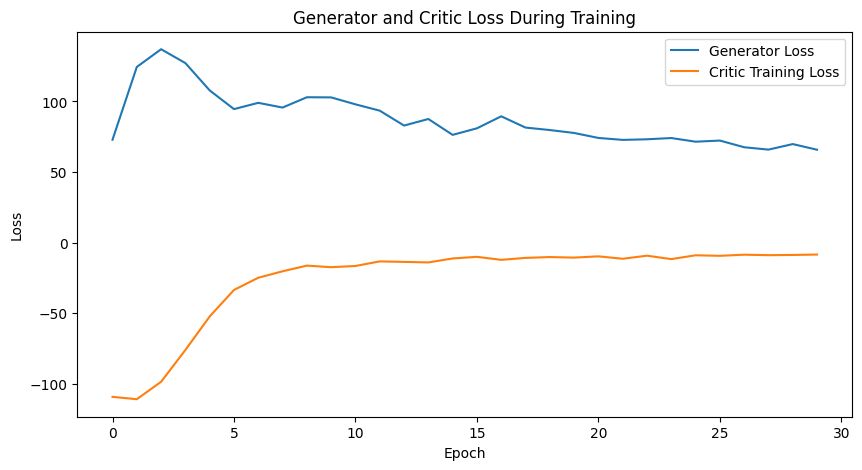
Figure 3: Wasserstein GAN training losses
The discriminator, the modified version of the critic, reached an optimal solution after just 10 epochs with its validation loss being lower than the training loss. Further a testing accuracy of 99.86% was obtained on the training set of real and generated images with the testing loss being 0.831.
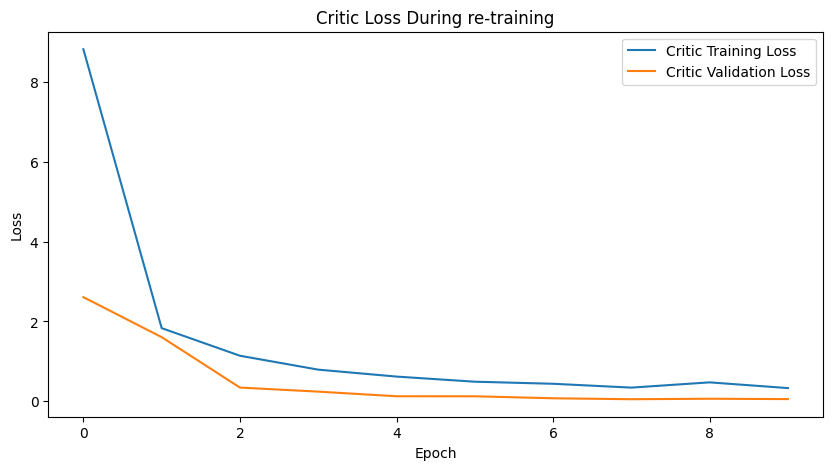
Figure 4: Loss of discriminator (modified critic model) during its retraining.
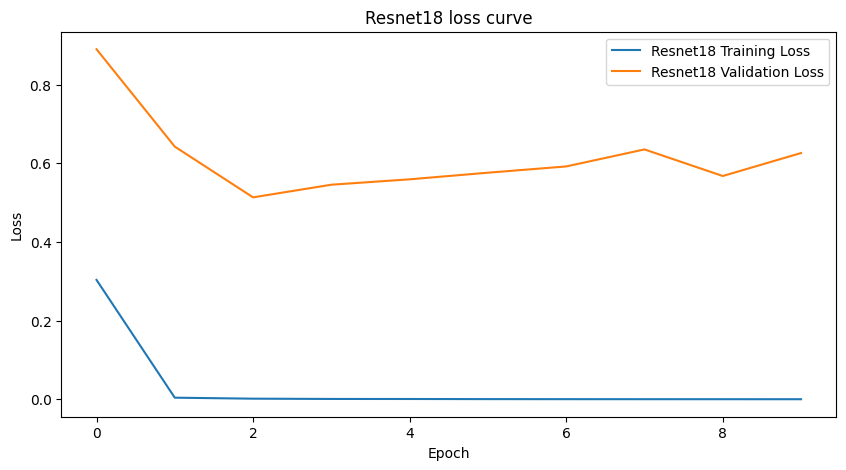
Figure 5: Loss curves of Resnet18 model
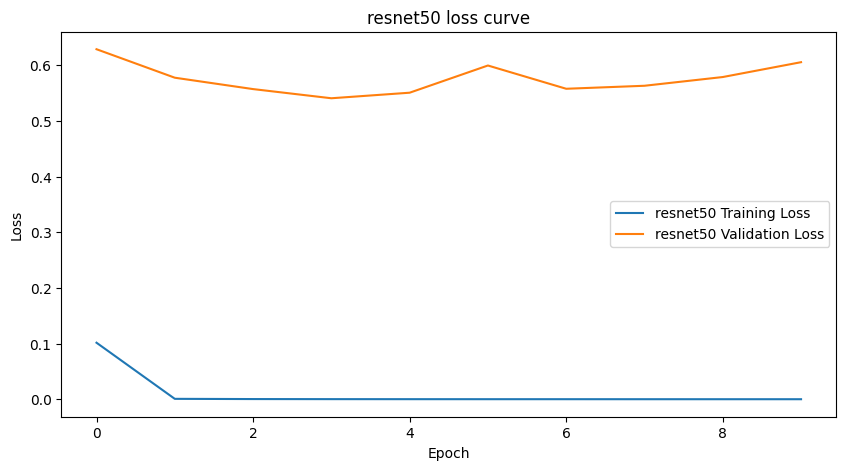
Figure 6: Loss curves of Resnet 50 model
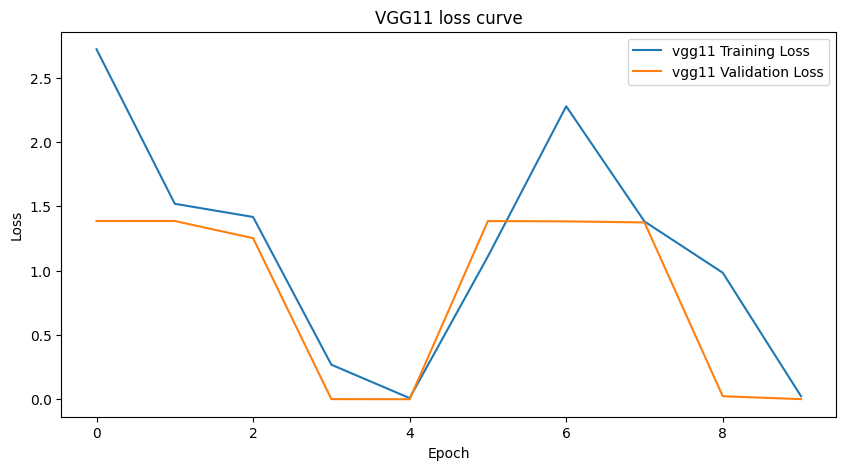
Figure 7: Loss curves of the VGG11 model
The other benchmarks obtained a higher testing accuracy, with ResNet50 even achieving 100% accuracy. However, both the Resnet models had their validation loss being higher than the training loss since the very first epoch. VGG11 was an exception, achieving 99.94% testing accuracy with test loss of 0.006, and the validation loss being lower than the training loss. It is important to note, however, that the number of trainable parameters in VGG11 far exceed the WGAN Discriminator, making it computationally expensive to train.
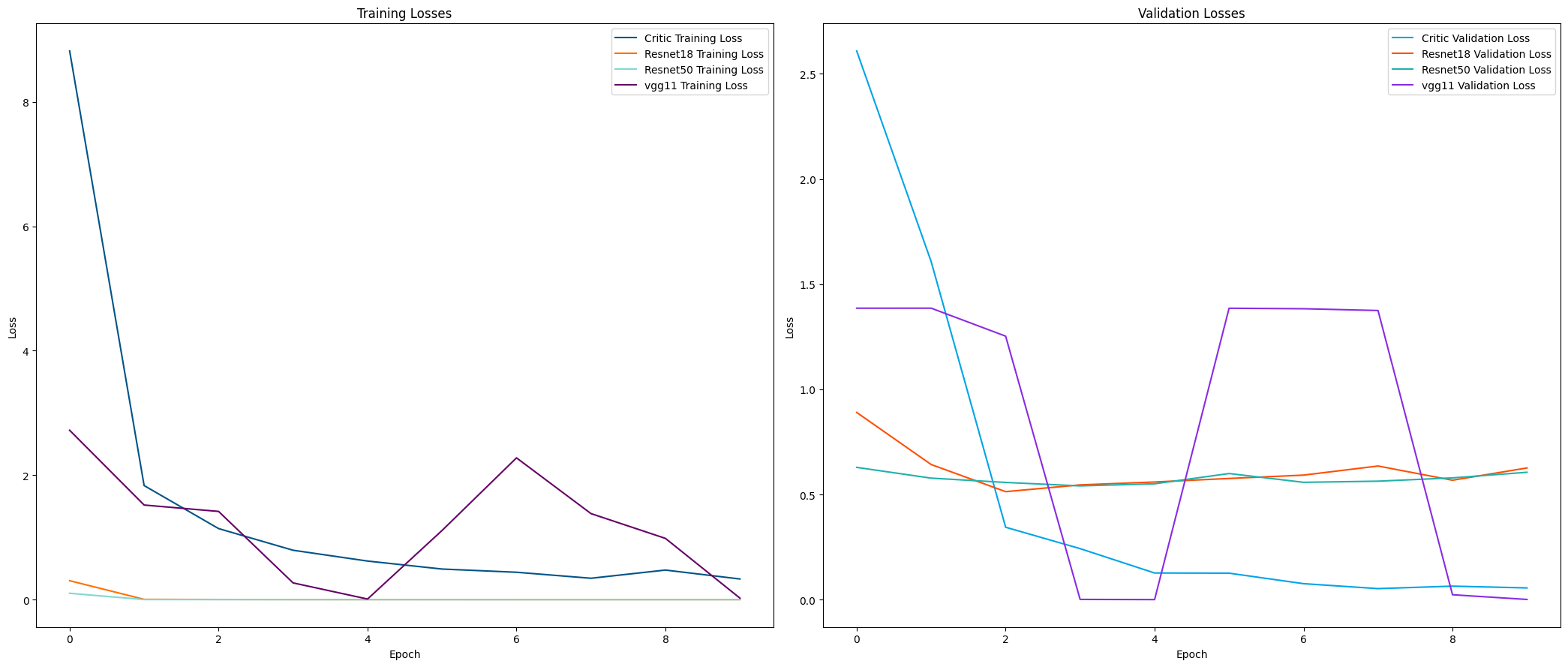
Figure 8: Training and validation losses of all the models compared
| Model | Testing Accuracy | Training loss | Validation loss |
|---|---|---|---|
| Discriminator | 99.86% | 0.3311891858946033 | 0.05573347210884094 |
| Resnet 18 | 99.98% | 0.0001981194045865121 | 0.626217782497406 |
| Resnet 50 | 100% | 3.820521988487111e-05 | 0.6056482195854187 |
| VGG 11 | 99.94% | 0.023528755146007673 | 0.0009363375138491392 |
Table 1: Results of training and validation of our modified discriminator, Resnet 18, Resnet 50, and VGG 11 models
In our research the GAN trained discriminator does outperform many of the other more comparable and complex models such as Resnet 18 and Resnet 50, particularly when you compare their validation losses.
The re-trained discriminator’s accuracy is within 1 percent of every other model tested. When comparing the validation losses, it is clear that the discriminator has understood the problem of fake image detection more thoroughly. Its validation loss is significantly lower than both the Resnet architectures by a large margin, despite them having a marginally higher accuracy, note that Resnet 50 achieves full accuracy. However, both of these models have their validation loss higher than their respective training losses, indicating an overfit. These models are overfit from the very first epoch, while the discriminator has a validation loss lower than the training loss throughout, signifying a better understanding of the task.
The only other model that outperforms re-trained discriminator in every aspect is the VGG net. It boasts higher test accuracy, as well as lower training and validation accuracy of every other model. However, one flaw of it is that the model itself has close to 129 million parameters, many folds higher than the discriminator. The discriminator can achieve comparable accuracy without the computational complexity and resources required to train the VGG net.
It is also important to note that the loss curves during WGAN training are also much more stable when compared to training with a conventional DCGAN. This aligns with the findings of both [6] and [7], where WGAN achieves a much stable training process.
[3] employed a similar approach to this paper where they actually tuned the entire GAN with the fake images while re-training the discriminator. This step may be unnecessary since we achieved similar results with separately training the discriminator. At the end of the GAN training, both the generator and the discriminator have a similar latent distribution, the generator has learnt the distribution of real images. If we then introduce the fake images again into the training process, the distribution of the real image changes, which is not ideal for the discriminator. Separately tuning the discriminator is hence better since it ensures the real and fake distributions stay separate.
Fine-tuning was also imperative in our case considering the critic only has a linear layer, incapable of classification tasks. The critic hence needs to be transformed into a discriminator with the modification and needs to be tuned to make the new output layer useful.
[1] xhlulu. (2020). 140k-real-and-fake-faces, Version 1. Retrieved December 14, 2023 from https://www.kaggle.com/datasets/xhlulu/140k-real-and-fake-faces.
[2] Meng, Han, and Fangru Guo. "Image classification and generation based on GAN model." In 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), pp. 180-183. IEEE, 2021.
[3] Zhu, Lin, Yushi Chen, Pedram Ghamisi, and Jón Atli Benediktsson. "Generative adversarial networks for hyperspectral image classification." IEEE Transactions on Geoscience and Remote Sensing 56, no. 9 (2018): 5046-5063.
[4] Epstein, David C., Ishan Jain, Oliver Wang, and Richard Zhang. "Online detection of ai-generated images." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 382-392. 2023.
[5] “How to Train a GAN, NIPS 2016 | Soumith Chintala, Facebook AI Research.” n.d. Www.youtube.com. Accessed April 13, 2024. https://www.youtube.com/watch?v=myGAju4L7O8.
[6] Arjovsky, Martin, Soumith Chintala, and Léon Bottou. "Wasserstein generative adversarial networks." In International conference on machine learning, pp. 214-223. PMLR, 2017.
[7] Gulrajani, Ishaan, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C. Courville. "Improved training of wasserstein gans." Advances in neural information processing systems 30 (2017).
[8] Martin Arjovsky and L´eon Bottou. Towards principled methods for training generative adversarial networks. In International Conference on Learning Representations, 2017. Under review.
[9] Ma, L., Shuai, R., Ran, X. et al. Combining DC-GAN with ResNet for blood cell image classification. Med Biol Eng Comput 58, 1251–1264 (2020). https://doi.org/10.1007/s11517-020-02163-3
[10] Wang, Sheng-Yu, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. "CNN-generated images are surprisingly easy to spot... for now." In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8695-8704. 2020.
[11] Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. "Generative adversarial networks." Communications of the ACM 63, no. 11 (2020): 139-144.