This publication presents the development and evaluation of an AI-powered chatbot designed to enhance user interaction with the Geoportale Nazionale dell'Archeologia (GNA) user manual.
The system leverages Retrieval-Augmented Generation (RAG) and Natural Language Processing (NLP) techniques to provide precise and context-aware responses to user queries. Built using the LangChain framework and Mistral AI, the chatbot integrates a vector database for efficient query retrieval and employs Mistral's generative language model for response generation. The prototype, developed iteratively, demonstrates core functionalities and validates the proof of concept, aiming to improve accessibility and engagement with the GNA platform. Evaluation through human assessment and LLM-based methods highlights the system's strengths in consistency and relevance, while identifying areas for improvement in fluency and completeness. Future work will focus on incorporating real-world user feedback and automated metrics to further refine the chatbot's performance.
This report presents a Question-Answering (QnA) application that integrates Retrieval-Augmented Generation (RAG) and Natural Language Processing (NLP) techniques . Built using LangChain framework and Mistral AI, the system assists users in navigating the user manual of the Geoportale Nazionale dell'Archeologia (GNA) project. The GNA chatbot application is thus designed to streamline user operations, ensuring relevant and accurate responses based on the Geoportale's documentation.
The code and deployment guidelines for the system are publicly available on GitHub.
The project’s primary objective is to build an AI-powered chatbot that enhances access to the structured knowledge contained in the GNA user manual. The system combines text-retrieval techniques with generative AI to deliver precise, context-aware responses in Italian.
The development process follows an iterative and modular approach, starting with a demo version (Minimum Viable Product) to gather feedback and refine functionalities, presented in this report. The prototype employs a vector database for efficient query retrieval and leverages Mistral LLM for intelligent response generation. Expected outcomes include demonstrating core functionalities, validating the proof of concept, and identifying areas for improvement, ultimately leading to a fully deployed solution within the GNA web platform (Fig. 1).
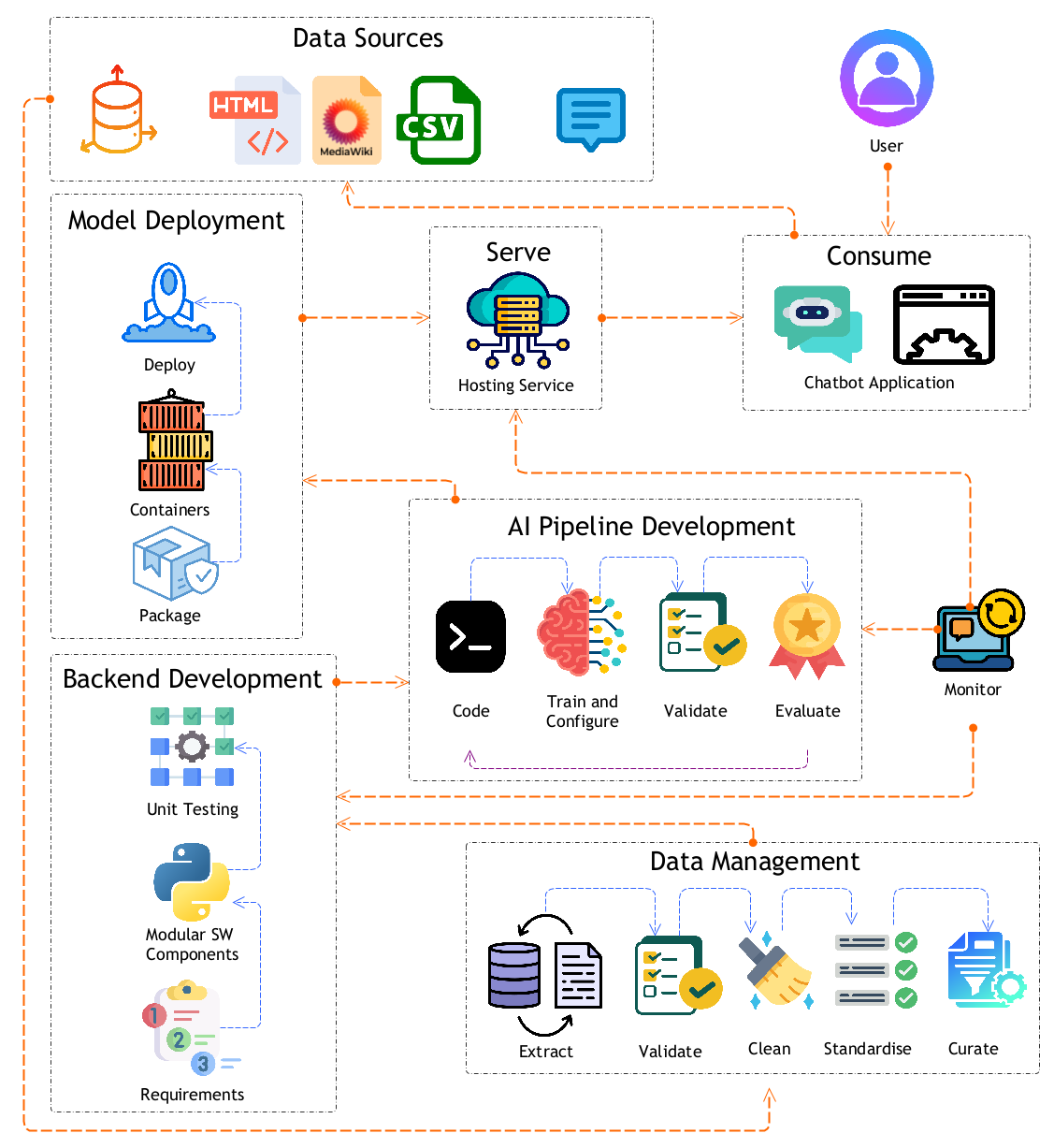 Figure 1: General application diagram of the integrated chatbot system.
Figure 1: General application diagram of the integrated chatbot system.
Operating within the Cultural Heritage sector under Ministero della Cultura (MiC), the GNA project is dedicated to preserving and disseminating Italy’s archaeological heritage. The platform functions as a central digital mapping hub, offering public access to cataloging procedures, historical data, excavation and archaeological sites data in accordance with national documentation standards set by the Istituto Centrale per il Catalogo e la Documentazione (ICCD). Designed to serve a diverse range of stakeholders – including ministry officials, technical teams, researchers, archaeologists, and scholars – the chatbot software solution aims to improve accessibility, efficiency, and engagement
in managing cultural assets.
The system (Fig. 2) integrates as main components Mistral NeMo LLM, a vector store Facebook AI Similarity search (FAISS), and a Streamlit user interface to create an interactive conversational agent. Its primary function is to retrieve and present relevant information from a CSV dataset based on user queries.
LangChain was chosen for its user-friendly platform that integrates both NLP and AI capabilities, facilitating smooth dataset uploads and enabling a user-friendly chat interface through natural language queries (Das, 2024). The main components were utilized from the library, in particular Prompts, Memory, and Chains (see more in Topsakal et al., 2023).
 Figure 2: System architecture diagram of the chatbot prototype
Figure 2: System architecture diagram of the chatbot prototype
1. Getting the Dataset
Data is extracted from an XML sitemap file to create a structured dataset. The process involves parsing the sitemap to retrieve URLs, fetching the corresponding web pages and extracting content. Metadata such as titles, descriptions, and subtitles are extracted using BeautifulSoup, while additional textual information is retrieved using the Trafilatura library. If the content follows the MediaWiki format, mwparserfromhell library is used to extract sections and plain text. The collected data is compiled into a Pandas dataframe, ensuring uniqueness and completeness, before being saved as a CSV file.
2. Environment Setup & Dataset Preparation
The system loads environment variables (e.g., Mistral API key) to ensure secure configuration. The CSV dataset is processed by splitting large texts into manageable chunks using RecursiveCharacterTextSplitter. This approach ensures the text fits within the Mistral model’s context window while maintaining coherence. Each chunk is enriched with metadata (title, description, URL) to provide contextual understanding.
3. Embedding and Vector Storage
To enable efficient retrieval, text chunks are converted into high-dimensional vectors using Mistral AI embeddings, which employ sub-word tokenization (Transformer-based model). These embeddings capture semantic meaning and are stored in a FAISS vector database.
4. Retrieval Mechanism
User queries are transformed into embeddings and compared against stored vectors in FAISS to identify the most semantically similar text chunks. The system uses the stuff method (Topsakal and Akinci, 2023), where all retrieved chunks are included in a single prompt for response generation. Ensuring adherence to Mistral’s token limit is critical to prevent truncation.
NeMo model constraint: 200k tokens per minute and 1k API requests per minute.
5. Generative Language Model & Conversational Memory
The retrieved information is passed to Mistral NeMo LLM, to generate context-aware responses. To maintain conversational context, buffer memory is implemented, limiting context retention to a fixed number of turns for efficient memory management. LangChain's ConversationBufferMemory was selected for this purpose.
6. User Interaction & Response Handling
The chatbot operates through a customized Streamlit interface (Fig. 3), processing user input and displaying responses in a structured format. A rate-limiting mechanism ensures compliance with MistralAI’s one-request-per-second limit. The system also manages API failures, such as handling missing environment variables and empty embeddings, and response formatting, ensuring clarity and readability.
 Figure 3: Chatbot user interface. System deployed in local host
Figure 3: Chatbot user interface. System deployed in local host
7. Debugging & Optimization
During development, some issues in LangChain’s source code were identified and addressed, including:
MistralAIEmbeddings retry function was triggered only on single-request HTTP timeouts, not on HTTP 429 errors, making the wait_time parameter ineffective.Issue fixed in LangChain PR #28242, though the patches in the latest release of langchain-mistralai package (v2.7) still does not fully resolve the 429 error for requests.
ConversationalRetrievalChain rephrased questions even when unnecessary, leading to two consecutive LLM calls, risking rate-limit violations. A 1-second delay was introduced between these calls when rephrase_question is enabled.This file contains the set of testing queries examples, illustrating how the chatbot system manages different questions and delivers relevant responses. The queries are in Italian, as the chatbot is primarily designed for this language usage, though it can also operate in English and other languages, as shown in the mock attempt of the first test. Queries range from simple to multi-part (e.g., Come compilare il layer MOSI? Spiegami la procedura nel dettaglio).
All the tests are executed within a controlled, artificial environment on a local host.
The system evaluation relied on two primary methodologies: human assessment and LLM-based evaluation. The human evaluation involved manually labeling responses based on key quality criteria – consistency, relevance, fluency, and completeness – using a 5-point Likert scale (Abeysinghe, 2024; van der Lee, 2020; Liu, 2016). The second approach, defined in the literature as LLM-as-a-Judge, employed an external LLM using a few-shot learning strategy to assess pre-collected chatbot responses, generating aggregated scores (Svikhnushina and Pu, 2023).
However, in this phase several challenges arose due to the absence of standardized evaluation methods and benchmarks. The lack of a golden standard – a verified set of chatbot responses representing objective truth – made it difficult to comprehensively assess accuracy. Additionally, there were no predefined benchmarks for internal institutional tasks, nor a baseline system for comparison, as real users or domain experts were unavailable for testing at this stage. While taxonomies for LLM evaluation exist (Guo et al., 2023), they are not universally applicable to chatbot assessment. Moreover, commonly used algorithmic metrics such as BLEU, ROUGE, and METEOR are considered ineffective for dialogue systems (Deriu et al., 2019; Liu et al., 2016), reinforcing the need for human evaluation as the most reliable approach (Mehri and Eskenazi, 2020; Abeysinghe, 2024).
The evaluation was thus primarily intrinsic, assessing chatbot responses in isolation rather than in real-world contexts. While human annotation provided direct insights, an external LLM – OpenAI’s GPT-3.5 – was also used to evaluate responses based on predefined criteria, adding another layer to the intrinsic evaluation. Despite these efforts, the exclusion of automated frameworks such as INSPECTORRAGET (Fadnis et al., 2024), which require a baseline system, limited the scope of analysis. Future evaluations should incorporate extrinsic assessments involving real users or domain experts, alongside automated metrics such as precision, recall, F1-score. Additionally, user satisfaction surveys and qualitative feedback (Maier et al., 1996) would enhance the evaluation process. A combined approach integrating intrinsic, extrinsic, and automated methods would provide a more comprehensive understanding of the chatbot’s performance and guide further improvements.
| Prompt | Consistency | Relevance | Fluency | Completeness |
|---|---|---|---|---|
| 1 | 5 | 5 | 5 | 5 |
| 2 | 5 | 5 | 5 | 5 |
| 3 | 5 | 5 | 5 | 5 |
| 4 | 5 | 5 | 5 | 5 |
| 5 | 5 | 5 | 4 | 3 |
| 6 | 5 | 0 | 5 | 2 |
The response to 6th question is incomplete (fig. below), as it does not offer any meaningful information about the user’s query, but it accurately reflects the system's instruction not to answer irrelevant questions (see script below).

system_message_prompt = SystemMessagePromptTemplate.from_template( """ You are a helpful chatbot assistant tasked with responding to questions about the WikiMedia user manual of the [Geoportale Nazionale dell’Archeologia (GNA)](https://gna.cultura.gov.it/wiki/index.php/Pagina_principale), managed by Istituto centrale per il catalogo e la documentazione (ICCD). You should never answer a question with a question, and you should always respond with the most relevant GNA user manual content. Do not answer questions that are not about the project. Given a question, you should respond with the most relevant user manual content by following the relevant context below:\n {context} """ )
Efficiency and response time are crucial for real-time applications. Efficiency reflects resource use, while response time measures processing speed. Lower response times improve user experience, whereas inefficiencies cause delays. The system recorded 31.19s for embedding generation and 1.26s for query response. However, to fully assess the significance of these values, they should be compared against the average response time of baseline systems.
The GNA Chatbot system effectively provides precise and context-aware responses to user queries related to the Geoportale Nazionale dell'Archeologia (GNA). The evaluation, as illustrated in the diagram (Fig. 4), underscores the chatbot's strengths in consistency and relevance, ensuring reliable and pertinent responses. However, areas for improvement were identified in fluency and completeness, indicating that while the responses are accurate, they may lack smoothness and depth.
 Figure 4: Radar diagram of the final system’s evaluation scores.
Figure 4: Radar diagram of the final system’s evaluation scores.
Despite challenges in evaluation due to the absence of standardized benchmarks and real-world user testing, the system demonstrates a robust proof of concept. Future work should focus on incorporating real-world user feedback and automated metrics to refine the chatbot's performance further.