Agentic Search
This work proposes the agentic search which enable the LLMs as search agents, which can actively seek information, select key knowledge and record useful evidence iteratively and summarize the final answer. Compared with previous RAG methods, the key of our agentic search is the reasoning technique. Here is a concrete example of our agentic search.
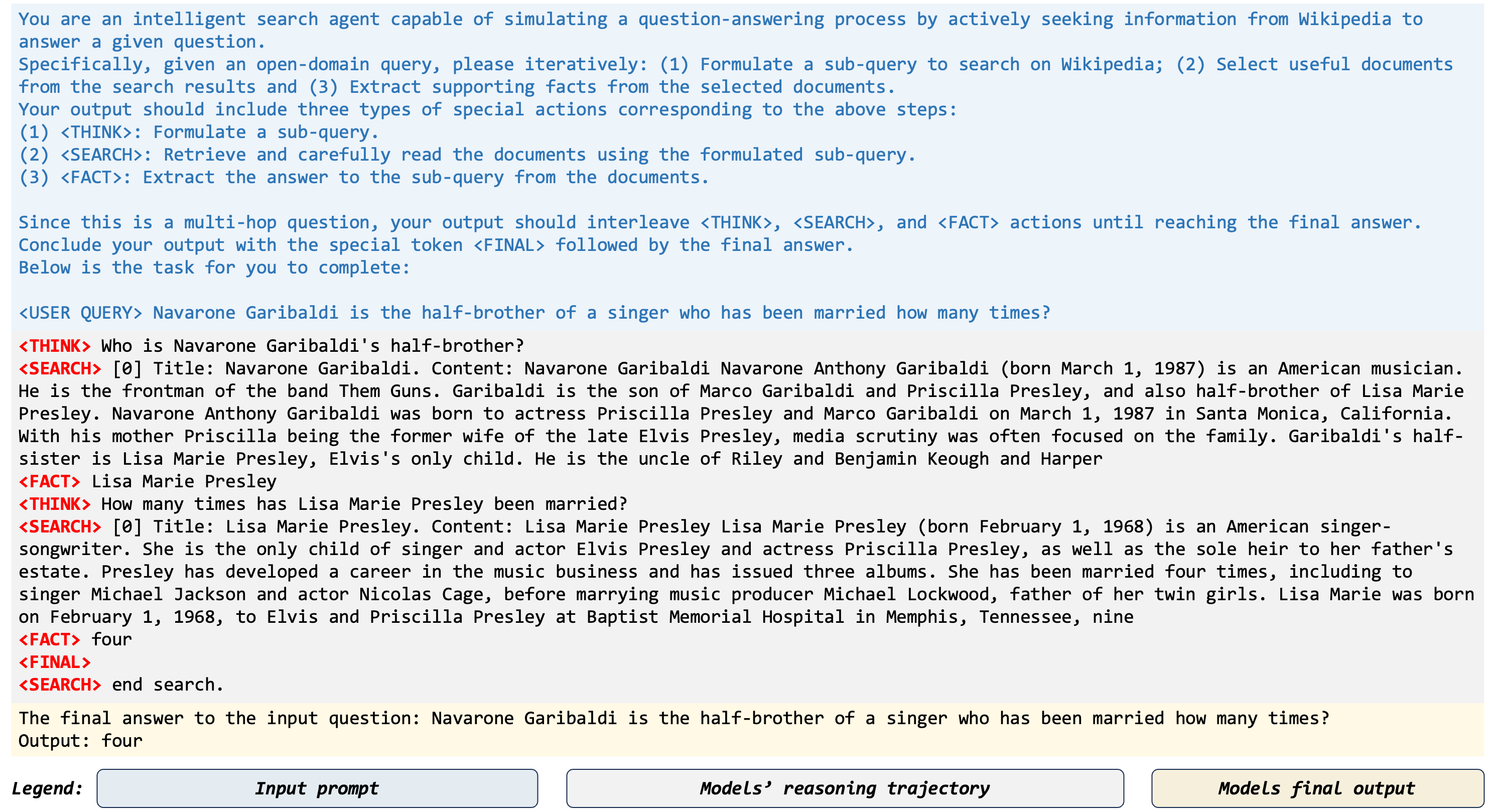
Environment
- create the
pythonenv withconda
conda create -n rag python=3.10 conda activate rag pip install -r requirements.txt pip install pytrec_eval -i https://pypi.tuna.tsinghua.edu.cn/simple
- [Optional] set the
vllmenvironment variable when using it.
VLLM_WORKER_MULTIPROC_METHOD=spawn
- [Optional] Please login the
wandbif use it to record the loss.
wandb login
(wandb login --relogin to force relogin)
Dataset
Download raw dataset
Retrieval Corpus
We follow previous work and use the Wikipedia 2018 as our document corpus, which can be found in DPR repo.
In our official experiment, we use the ColBERT as the retrieval model to pair each query with top-20 documents. The pre-trained ColBERT checkpoint can be downloaded in either its official repo or its link.
You can deploy the ColBERT retrieval or other customized retrieval in your experimental environment to implement this document retrieval process.
If you use the ColBERT, please set the request url in os.environment. For example,
import os os.environ['API_SEARCH'] = "http://10.96.202.234:8893"
If you use your customized retrieval such as Bge retriever, Bing search or Google search, please replace the following retrieval function in src/utilize/apis.py with your own retrieval function. In more details, please re-implement the following code snippet in our src/utilize/apis.py file:
import requests api_search = "http://10.96.202.234:8893" def document_retrieval(query, k=20): url = f'{api_search}/api/search?query={query}&k={k}' response = requests.get(url) res = response.json() knowledge = [] for doc in res['topk']: text = doc['text'][doc['text'].index('|') + 1:].replace('"','').strip() title = doc['text'][:doc['text'].index('|')].replace('"','').strip() knowledge.append(f"Title: {title}. Content: {text}") return knowledge
We provide more detailed guidance in src/retrieval/README.md. Please see it for a more clear illustration.
Our method
We first automatically annotate an agentic search dataset to train the base LLM, enabling its initial expertise in RAG tasks. This is similar to the warmup learning of Deepseek-R1, which train a model with supervised fine-tuning dataset before using reinforcement learning method for training.
Below, we show the command for launching the training experiment.
Warmup training
MODEL_PATH="<YOUR_MODEL_PATH>" $WARMUP_DATA_PATH="<YOUR_WARMUP_DATA_PATH>" $OUTPUT_DIR="<YOUR_OUTPUT_DIR>" PROCEDURE=sft CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 nohup torchrun --nproc_per_node=8 --master_port=11021 ./src/run.py \ --model_name_or_path $MODEL_PATH \ --dataset_name_or_path $WARMUP_DATA_PATH \ --deepspeed ./src/script/ds_z3_config.json \ --output_dir $$OUTPUT_DIR \ --overwrite_cache True \ --warmup_ratio 0.1 \ --report_to wandb \ --run_name test_run \ --logging_steps 1 \ --cutoff_len 8192 \ --max_samples 200000 \ --save_steps 110 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 16 \ --learning_rate 2.0e-6 \ --num_train_epochs 2 \ --lr_scheduler_type cosine \ --bf16 True &
Alignment
After the warmup learning, the LLM is initialized the basic expertise in agentic search. Thus, we alternate the following steps to achieve the self-training of agentic search.
Inference
We first simulate the task-solving trajectories, e,g., inference, to create the training dataset.
MODEL_PATH="<YOUR_MODEL_PATH>" INPUT_FILE="<YOUR_INFERENCE_FILE>" OUTPUT_DIR="<YOUR_OUTPUT_DIR>" PROCEDURE=inference CUDA_VISIBLE_DEVICES=1,2,3,4,5,6,7 python ./src/run.py \ --model_name_or_path $MODEL_PATH \ --input_file $$INPUT_FILE \ --output_dir $OUTPUT_DIR \ --left 0 \ --right 100000 \ --shuffle True
Entropy
Then, we compute the entropy to compute the log-probability in generating the final answer. This log-probability takes the roles as a weight on the final learning loss function.
MODEL_PATH="<YOUR_MODEL_PATH>" INFERENCE_FILE="<YOUR_INFERENCE_FILE>" OUTPUT_DIR="<YOUR_OUTPUT_DIR>" PROCEDURE=entropy CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python ./src/run.py \ --model_name_or_path $MODEL_PATH \ --inference_file $INFERENCE_FILE\ --output_dir $OUTPUT_DIR \ --left 0 \ --right 1000000 \ --epo 2
Format
Using the task-solving trajectories and the corresponding entropy, we then synthesize the training dataset for the next step.
INFERENCE_FILE="<YOUR_INFERENCE_FILE>" ENTROPY_FILE="<YOUR_ENTROPY_FILE>" OUTPUT_DIR="<YOUR_OUTPUT_DIR>" PROCEDURE=formate CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python ./src/run.py \ --output_dir $OUTPUT_DIR \ --inference_file $INFERENCE_FILE \ --entropy_file $ENTROPY_FILE \ --size 200000 \ --epo 2
Learning
MODEL_PATH="<YOUR_MODEL_PATH>" WARMUP_DATA_PATH="<YOUR_WARMUP_DATA_PATH>" OUTPUT_DIR="<YOUR_OUTPUT_DIR>" PROCEDURE=sft CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 nohup torchrun --nproc_per_node=8 --master_port=11021 ./src/run.py \ --model_name_or_path $MODEL_PATH \ --dataset_name_or_path $WARMUP_DATA_PATH \ --deepspeed ./src/script/ds_z3_config.json \ --output_dir $$OUTPUT_DIR \ --overwrite_cache True \ --warmup_ratio 0.1 \ --report_to wandb \ --run_name test_run \ --logging_steps 1 \ --cutoff_len 8192 \ --max_samples 200000 \ --save_steps 110 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 16 \ --learning_rate 2.0e-6 \ --num_train_epochs 2 \ --lr_scheduler_type cosine \ --bf16 True &
Evaluation on Benchmarks
We evaluate our method using the F1, EM and Accuracy metrics. We use the evaluation scripts from official KILT.
Pre-processed Data
Download pre-processed evaluation data
You can directly download our pre-processed datasets, which will be provided after the anonymous period.
| File | Note | Link |
|---|---|---|
| nq_dev.json | Pre-processed data of the NQ dataset | Google drive |
| hotpotqa_dev.json | Pre-processed data of the HotpotQA dataset | Google drive |
| musiqueqa_dev.json | Pre-processed data of the MuSiQue dataset | Google drive |
| wikimultihop_dev.json | Pre-processed data of the 2WikimultihopQA dataset | Google drive |
| wow_dev.json | Pre-processed data of the Wizard-of-Wikipedia dataset | Google drive |
Download the warmup learning dataset
The warmup learning dataset is released in Huggingface dataset.
Download the model checkpoint
We first release two trained search agents with different parameter size, including Search-agent-Mistral-24B andd Search-agent-Llama-3.1-8B. Please see our Huggingface Collection for more details. You can download their weight and conduct inference using our inference code.
Todo
- We will release the warmup learning datasets and our data synthetic code.
- Checkpoints will be released.
- Our paper will be released as soon as possible
- We will release the inference trajectories for each trained checkpoint.
Acknowledgement
We sincerely thank prior work, including RankGPT and Llama-Factory.
We also thank the Baidu Inc., Shandong University, and Leiden University for this project.