Introduction
Hey folks, a quick introduction about the content that I'll be sharing here today. This publication will help you deeply understand the application of Agentic AI programmatically. I will be covering a few popular frameworks which will help you get started with Agentic AI Frameworks.
Abstract
This paper looks at agentic artificial intelligence (AI) frameworks, which allow AI systems to make decisions, pursue goals, and learn on their own. Agentic AI is a big step forward in how intelligent systems work, enabling them to handle complex tasks with little human input. In this paper, we explore the basics of agentic AI and how it can be used in areas like robotics, virtual assistants, and decision-making tools. We also dive into how developers can code these frameworks, offering practical examples and code snippets to help bring agentic AI to life. By exploring various case studies and providing practical coding examples, this research aims to bridge the gap between conceptual understanding and practical implementation, equipping developers and researchers with the tools needed to harness the power of agentic AI. Even simple applications of agentic AI can add significant value by automating everyday tasks and improving efficiency. Application of these frameworks will show how automation can be achieved for small intermediate steps in business.
Methodology
As all industries are moving towards AI-powered solutions, it is important for developers to approach the integration of agentic AI with responsibility and foresight. As creators of these systems, developers must ensure that the AI's autonomy is balanced with ethical considerations, safety protocols, and transparency. By doing so, we can create AI that not only enhances productivity but also aligns with societal values and benefits. The few frameworks that this paper would be covering is Autogen, LangGraph, Crewai, SmolAgents and LlamaIndex . By first understanding these key terms, we lay the groundwork for better understanding how agentic AI frameworks function in practice;
[Ref - Prepare for agentic AI]
To keep the content concise, references are included throughout the paper. Please feel free to navigate to them for a deeper understanding of each concept.
-
Agentic AI - Agentic AI uses sophisticated reasoning and iterative planning to solve complex, multi-step problems.
[Ref - What is Agentic AI?] -
Agentic AI frameworks - Agentic frameworks are the building blocks for developing, deploying and managing AI agents.
[Ref - What is Agentic AI?] -
Agent - An artificial intelligence (AI) agent is a software program that can interact with its environment, collect data, and use the data to perform self-determined tasks to meet predetermined goals. Humans set goals, but an AI agent independently chooses the best actions it needs to perform to achieve those goals.
[Ref - What are AI agents?] -
Tool Use - Interaction with external systems like APIs, databases, calculators, and even web searches.
[Ref - Tool calling Agents] -
Knowledge Graph - A collection of Entities, Entity Types, and Entity Relationship Types that enable reasoning and inference.
[Ref - Tool calling Agents] -
Multi-Agent systems - A multi-agent system (MAS) is composed of multiple interacting intelligent agents - autonomous entities that can sense, learn models of their environment, make decisions and act upon them.
[Ref - Concept of Multi-agentic system.] -
Orchestration - Artificial intelligence (AI) agent orchestration is the process of coordinating multiple specialized AI agents within a unified system to efficiently achieve shared objectives.
[Ref - AI agent Orchestration] -
Human-in-loop - A human acting as a mediator/orchestrator helps agent gather feedback. This integration allows human to provide guidance and oversight before tasks are executed, ensuring that the agent stays on the right track and aligns with the intended goals.
[Ref - Human-in-loop] -
Prompt - In the context of AI, a prompt is the input you provide to the model to elicit a specific response. This can take various forms, ranging from simple questions or keywords to complex instructions, code snippets, or even creative writing samples. The effectiveness of your prompt directly influences the quality and relevance of the AI's output.
[Ref - AI agent Orchestration] -
Tokens - Tokens can be thought of as pieces of words. Before the API processes the request, the input is broken down into tokens. These tokens are not cut up exactly where the words start or end - tokens can include trailing spaces and even sub-words.
[Ref - What are tokens?]
Now that we have a solid understanding of the key concepts in agentic AI, let's dive into the frameworks that enable the development and deployment of such systems. These frameworks provide the structure and tools necessary for building autonomous AI systems that can make decisions, learn from experience, and interact with their environments effectively.
There are some Access and Availability Status that should be considered before using any frameworks or tools -
License Agreements: Some frameworks or tools (like Azure OpenAI, or certain paid APIs) may require users to accept specific license agreements before use.
API Keys & Authentication: Many tools, especially cloud-based ones like Azure OpenAI, will require users to create accounts and obtain API keys. Make sure to follow the authentication steps outlined in their respective documentation.
Beta Versions: Be aware that some frameworks may be in beta or experimental stages. These might offer advanced features but could come with stability issues.
Before we jump into the use cases and how these frameworks work in practice, let’s quickly go over what you’ll need to get started. Here's a list of the essentials to set everything up and make the most of these tools:
- Any local IDE - VS code, Pycharm, etc
- Python (Version 3.10 or higher)
- Virtual Environment Setup (Optional but Recommended) -
python -m venv myenv source myenv/bin/activate
- Environment Configuration and Setup(using .env)
Here is the summary of access and availability status for each framework:
-
AutoGen
Access: AutoGen is available through the official GitHub repository. It is an open-source framework and can be freely accessed and integrated into your projects.
Availability: As of now, AutoGen is actively maintained and frequently updated. Make sure to check the repository for the latest release.
Limitations: Users need an Azure account to use certain services within AutoGen (e.g., language models). Some features may require specific Azure permissions. -
LangChain
Access: LangChain is also open-source and can be accessed via the LangChain GitHub repository. It's widely used for chaining together different components, such as LLMs and other tools.
Availability: LangChain is actively maintained, with regular updates and a large community of contributors. The framework is publicly available and free to use.
Limitations: While LangChain itself is free to use, certain tools and services (such as APIs or cloud-based integrations) may require separate licensing or API keys. -
Crewai
Access: Crewai is available as part of the CrewAI package. The library is open-source and free to use.
Availability: Crewai is currently stable but has periodic updates. It's available for integration into custom workflows and projects.
Limitations: Crewai’s functionality can be limited by the complexity of the tasks it is set to perform. Users need to ensure they are using compatible tools and agents for optimal performance. -
SmolAgents
Access: SmolAgents is available via GitHub. It’s an experimental framework with some parts still under active development.
Availability: SmolAgents is publicly available, though some features may be subject to changes as it evolves. Be sure to check the repository for any breaking changes or updates.
Limitations: SmolAgents is not fully stable in every scenario, especially for larger projects. Users may experience issues related to scalability and integration with certain APIs. -
LlamaIndex
Access: LlamaIndex is an open-source project and can be found on GitHub. It is widely used in LLM-powered applications.
Availability: The framework is stable and maintained, and it is supported by a large user community.
Limitations: While LlamaIndex is freely available, users may face limitations in terms of scalability when handling large data sets. Performance might be affected based on the deployment scale.
In this section, we’ll explore several widely-used agentic AI frameworks, examining their core features, practical applications, and how developers can implement them to create intelligent, goal-directed systems. Each framework has its unique strengths and use cases, and we’ll discuss how they can be leveraged across various industries, from robotics and virtual assistants to complex decision-making systems.
Smart Orchestration for Local Code Generation and Execution using AutoGen -

Version Used - 0.047
Framework description -
AutoGen is an open-source programming framework for building AI agents and facilitating cooperation among multiple agents to solve tasks. AutoGen aims to provide an easy-to-use and flexible framework for accelerating development and research on agentic AI.

Key Features :
- Asynchronous messaging
- Modular and extensible
- Observability and debugging
- Scalable and distributed
- Built-in and community extensions
- Cross-language support
- Full type support
Architecture of class demonstrated(MagenticOneGroupChat)
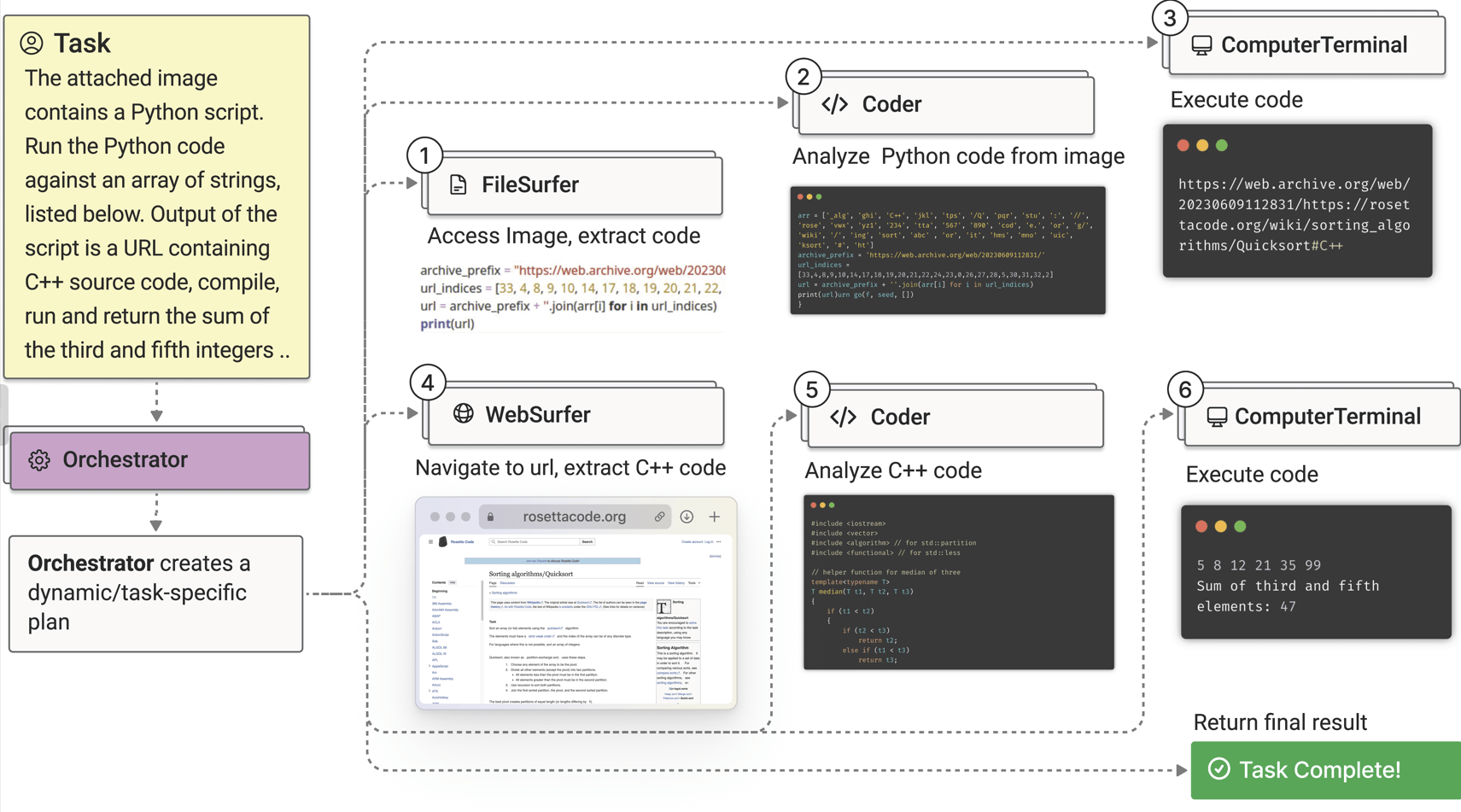
Magentic-One is a versatile and generalist multi-agent system designed to solve open-ended tasks, both web-based and file-based, across a variety of domains. It was built using the autogen-core library but has since been upgraded to work with autogen-agentchat, offering a more modular and user-friendly interface. The system is powered by an orchestrator called MagenticOneGroupChat, which now functions as an AgentChat team, supporting various agents.
- Installation and Usage Instructions :
It is recommended to create a virtual environment on your local machine before installing any packages.
Please refer to installation guide for getting started.
LocalCommandLineCodeExecutor functionality is not recommended by Autogen. Due to resource limitation I have used local executor. Consider using docker!
Problem Statement Addressed - The need for a self-healing, autonomous orchestration system for local code generation and execution, capable of operating without human intervention.
## Note - AutoGen internally uses a lot of packages which might need to download externally # importing required libraries import asyncio from autogen_ext.models.openai import AzureOpenAIChatCompletionClient from autogen_ext.agents.web_surfer import MultimodalWebSurfer from autogen_ext.agents.magentic_one import MagenticOneCoderAgent from autogen_ext.code_executors.local import LocalCommandLineCodeExecutor from autogen_ext.agents.file_surfer import FileSurfer from autogen_ext.tools.code_execution import PythonCodeExecutionTool from autogen_agentchat.teams import MagenticOneGroupChat from autogen_agentchat.ui import Console from autogen_agentchat.agents import AssistantAgent, CodeExecutorAgent from autogen_core import SingleThreadedAgentRuntime # Using AutoGen with Async as it is supported in >=v0.4 async def main() -> None: # Setting runtime for the team which we are using - MagenticOneGroupChat runtime = SingleThreadedAgentRuntime() runtime.start() # Enabling Local code Execution supported in AutoGen ## WARNING - Functionality is not recommended by Autogen. Due to resource limitation I have used local executor. Consider using docker! executor = LocalCommandLineCodeExecutor(work_dir="output") python_tool = PythonCodeExecutionTool(executor=executor) # Start off by setting up model client which is essential for defining an agent model_client = AzureOpenAIChatCompletionClient( model='gpt-4o', azure_endpoint='https://example.deployment.azure.com/', azure_deployment='deployment_name', api_version='2024-08-01-preview', api_key='API_key', ) # Define agents web_surfer = MultimodalWebSurfer( "webSurfer", model_client=model_client, headless=True, to_save_screenshots=True, use_ocr=True, debug_dir="./output" ) coder = MagenticOneCoderAgent( "coder", model_client=model_client, ) unit_tester = AssistantAgent( "tester", model_client=model_client, description="An AI assistant that helps in creating unit test cases and conduct a security scan for the code.", system_message="""create and execute 3 unit test cases using the following format: Unit test case - 1: Test case description Input: Input values Expected Output: Expected output. Code: Unit test code Repeat the same for all test cases. """, tools=[python_tool], ) local_file_surfer = FileSurfer( "fileSurfer", model_client=model_client, description="A local file surfer that can access files on the local system.", ) code_executor = CodeExecutorAgent( "CoderExecutor", code_executor=executor, ) critic_agent = AssistantAgent( "critic", model_client=model_client, description="An AI assistant that helps in reviewing the code and ensure it is executing properly.", ) # Use agents as participants in group chats participants = [unit_tester, local_file_surfer, code_executor, web_surfer, coder, critic_agent] # Use agents as participants in group chats team = MagenticOneGroupChat( participants=participants, model_client=model_client, max_turns=50, runtime=runtime, ) # try running user query await Console(team.run_stream(task="write a code to scrape web pages using python"), output_stats=True) await runtime.stop() asyncio.run(main())
Code Explanation -
The provided code sets up an asynchronous environment to manage a team of AI agents, each with a specific role, using the SingleThreadedAgentRuntime. This setup allows each agent to perform distinct tasks, such as web surfing, code execution, file browsing, and unit testing, working together to complete a larger goal. The main function initializes these agents, starts the runtime, and triggers a task using the console interface.
Imports:
The code begins by importing various necessary modules and classes that help set up the agents and their functionalities. These imports include tools for code execution, interacting with models, and managing agent behaviors.
Main Function:
An asynchronous main function is defined to initialize and execute the agents. It sets up the overall workflow of the agents in the environment, ensuring that tasks are carried out as expected.
Runtime Initialization:
The SingleThreadedAgentRuntime is initialized and started within the main function. This runtime serves as the backbone for managing agent operations, ensuring that each task is processed sequentially and efficiently in a single-threaded environment.
Code Executor:
The LocalCommandLineCodeExecutor is set up to execute code locally, specifically within the "output" directory. This executor facilitates running code on the local machine rather than relying on remote servers. It ensures that any code generated by the agents is executed in a controlled, local environment. The PythonCodeExecutionTool is created using this executor, enabling the execution of Python code tasks.
Model Client:
The AzureOpenAIChatCompletionClient is initialized with necessary parameters to interact with the Azure OpenAI service. This client allows the agents to communicate with a language model (such as GPT) to generate code, solve problems, or perform various tasks that require natural language processing.
Agents Initialization:
Several agents are initialized, each serving a unique role;
Web Surfer(The MultimodalWebSurfer is configured to carry out web surfing tasks, allowing it to browse the web and gather information.)
Coder(The MagenticOneCoderAgent is initialized to handle coding tasks, such as writing scripts or solving coding challenges.)
Unit Tester(The AssistantAgent is configured to create and run unit tests, ensuring that the code functions correctly.)
File Surfer(The FileSurfer agent is set up to navigate local files, accessing documents, configurations, or code that may be needed.)
Code Executor(The CodeExecutorAgent is set up to handle the execution of the code generated by the other agents.)
Critic Agent(Another AssistantAgent is used as a critic to review and verify the correctness of the code execution.)
Team Setup:
A list of agents (referred to as participants) is created to collaborate on the task. The MagenticOneGroupChat orchestrates the interactions between these agents, enabling them to work together seamlessly. It is initialized with the participants, model client, and the runtime environment, ensuring that all agents are ready to cooperate.
Task Execution:
Using the console interface, a task is run where the agents work together to write Python code for scraping web pages. The task involves multiple agents interacting with each other—web surfing agents collect information, coding agents write the code, and unit testing agents ensure the code works as intended. Once the task is completed, the runtime is stopped.
Run Main Function:
Finally, the asyncio.run(main()) method is used to run the main function asynchronously, initiating the entire process and allowing the agents to execute their respective roles in the workflow.
Sample Output -
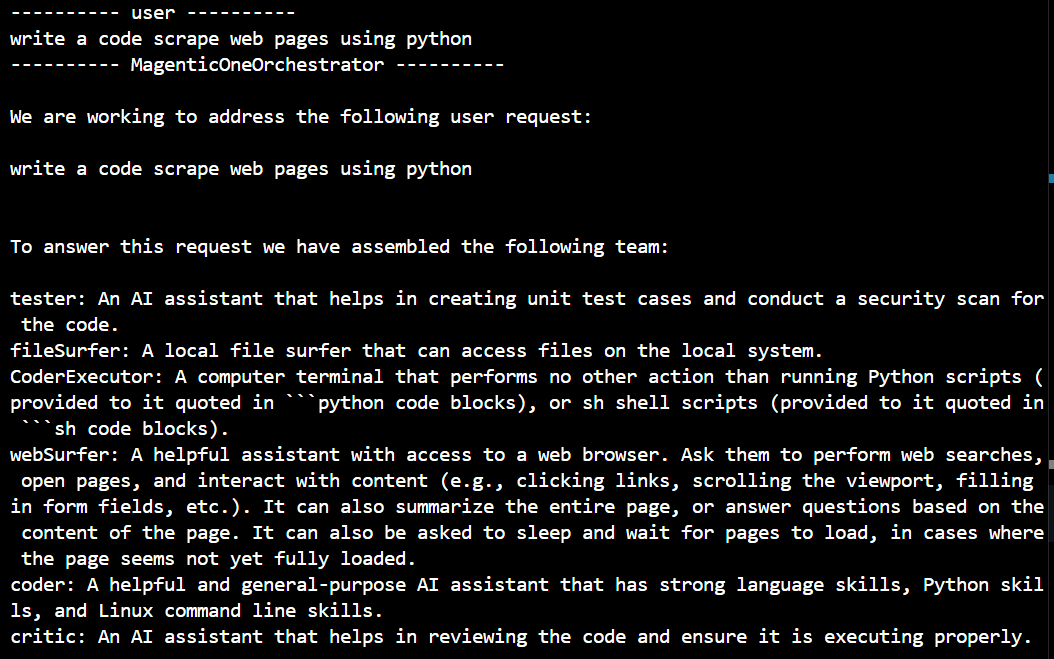
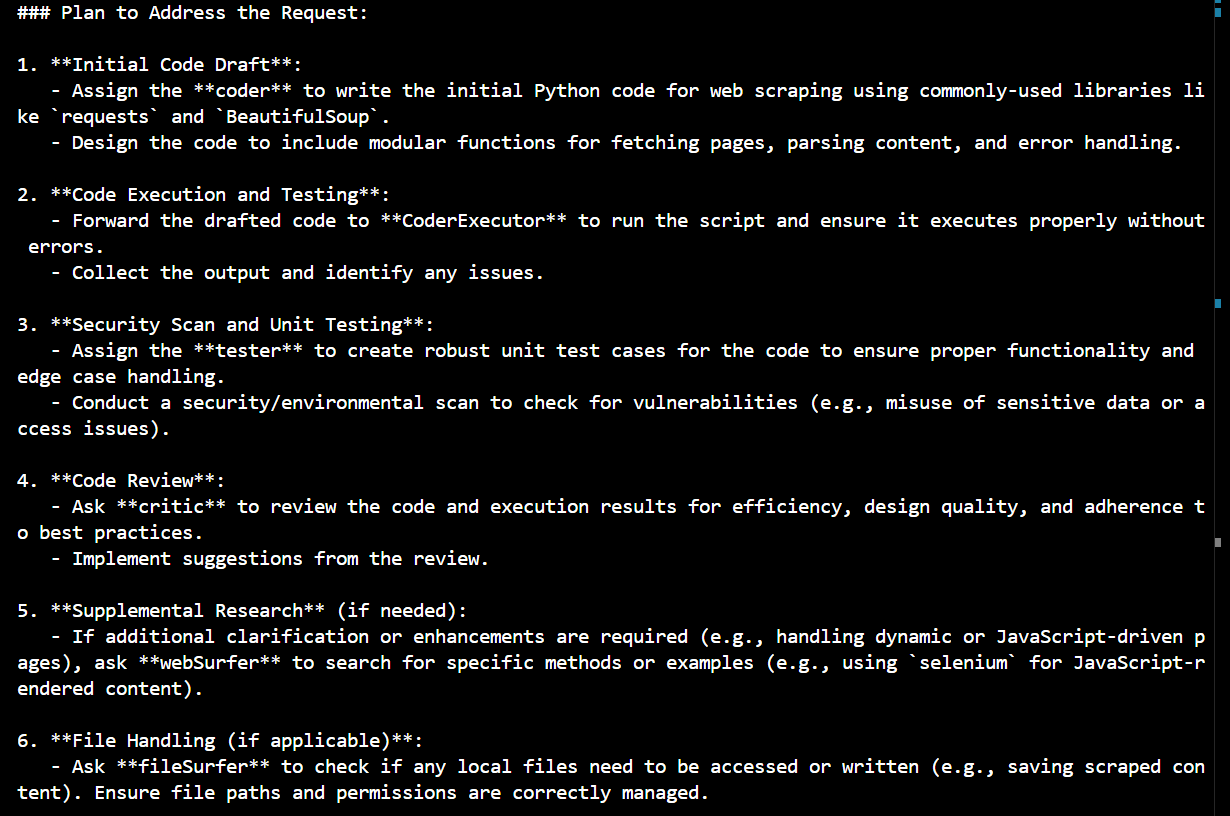
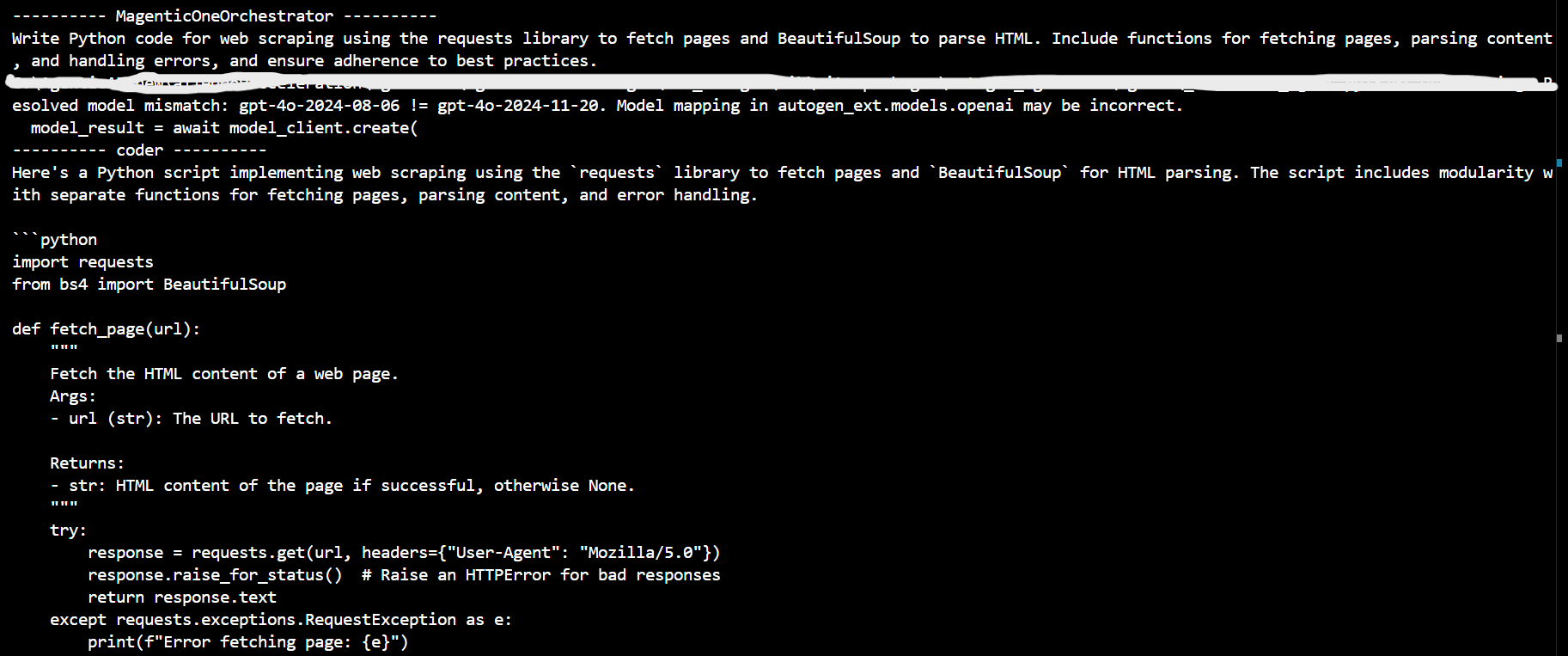

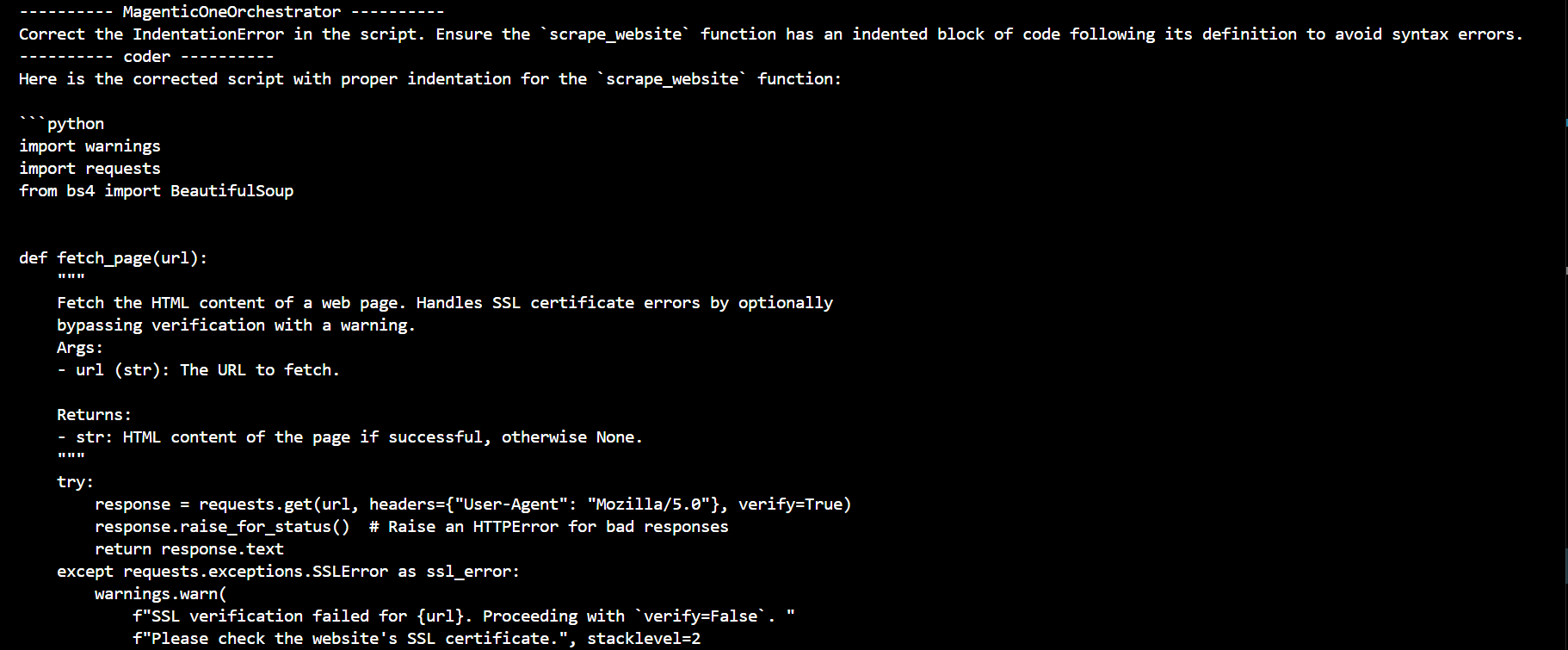
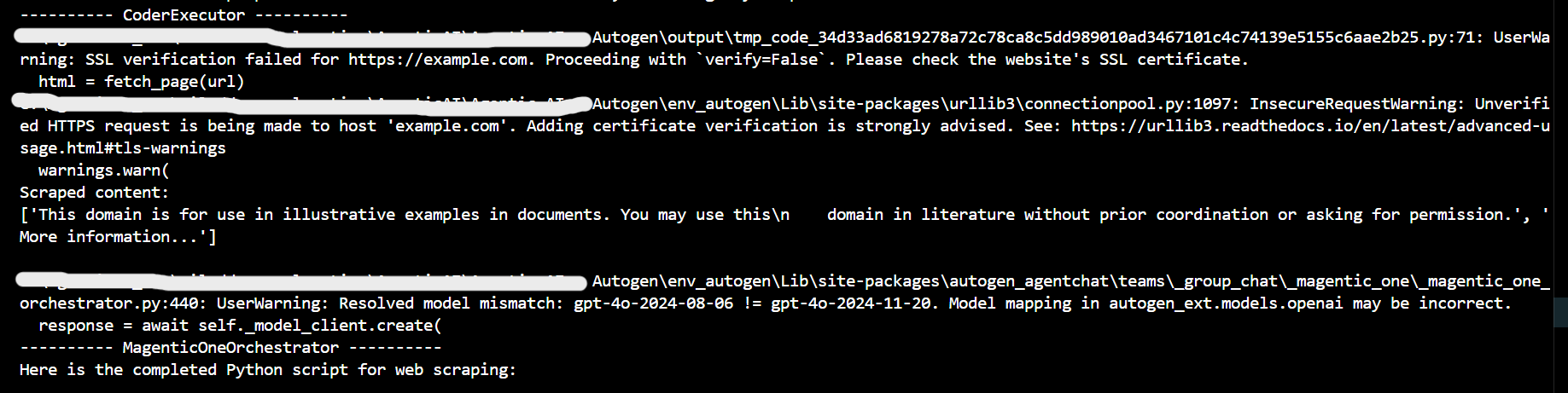

This is an example of an implementation where the system can autonomously generate and execute code, create and run test cases, and even heal itself when issues arise. You can add or remove agents as per your requirements. This system can implement any library/framework as it has access to web it can gather relevant information and try out a sample implementation.
Limitations/Drawbacks : The orchestration class can be token-hungry, especially when the Group Chat exceeds 8-10 messages, often leading to token shortages. This becomes a significant challenge as the system scales with more complex interactions.
Gaps in existing research : While the central orchestrator approach works well, it may not suit all use cases. For more process-oriented approaches, you might want to explore other orchestration models, such as Swarm (for structured hand-offs), SelectorGroupChat (for LLM-based speaker selection), SocietyOfMind (where agents collaborate to produce a single output), and RoundRobinGroupChat (based on a Round Robin approach for task allocation). These alternatives offer unique strengths depending on your project's needs. Human-in-loop approches are also supported in AutoGen which can be helpful if human intervention is needed at intermediate steps.
Automating Data Visualization using LangGraph -

Version Used - 0.3.16
Framework description -
LangGraph simplifies the creation of stateful, multi-actor applications using LLMs. Building on LangChain, it adds the ability to create and manage cyclical graphs, which are crucial for developing advanced agent runtimes. The core features of LangGraph include its graph structure, state management, and coordination capabilities.
Key Features :
- Modular Architecture
- Framework customizability
- Unified Interface
- Extensive Documentation and Examples
Description of class implementated(create_pandas_dataframe_agent)
LangChain's Pandas DataFrame Agent allows language models (LLMs) to interact with and analyze data in Pandas DataFrames using natural language queries, making complex data tasks like filtering, aggregation, and visualization more accessible for data scientists and analysts. It streamlines workflows by combining the power of LLMs with the flexibility of Pandas. However, since the agent uses a Python REPL to execute code, it introduces potential security risks, such as executing malicious code, if not carefully managed. To mitigate these risks, users must opt-in to this feature by setting a specific parameter to True, ensuring they understand the security implications and have safeguards in place.
- Installation and Usage Instructions :
It is recommended to create a virtual environment on your local machine before installing any packages.
Please refer to installation guide for getting started.
create_pandas_dataframe_agent is an experimental function. Use it at your own risk. Enabling parameters like allow_dangerous_code can pose security risks, so proceed with caution and use them at your discretion.
Problem Statement Addressed - The need for automating data visualization processes, enabling efficient and dynamic creation of visual representations from data.
import httpx import pandas as pd from typing import List from typing_extensions import TypedDict from langchain_openai import AzureChatOpenAI from langchain.agents import StructuredChatAgent, AgentExecutor, Tool from langchain_community.tools import DuckDuckGoSearchRun from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent from langgraph.graph import StateGraph # Create an HTTP client with SSL verification disabled client = httpx.Client(verify=False) # Initialize the AzureChatOpenAI language model llm = AzureChatOpenAI( model='gpt-4o', azure_endpoint='https://your.endpoint.azure.com/', azure_deployment='your_deployment', api_version='2024-08-01-preview', api_key='YOUR_API_KEY' ) # Function to create an agent with specified tools def create_agent(csv_path, llm): # Initialize the DuckDuckGo search tool search = DuckDuckGoSearchRun(max_results=3, verify=False) # Create a pandas dataframe agent pd_agent = create_pandas_dataframe_agent( llm, pd.read_csv(csv_path), verbose=True, allow_dangerous_code=True, agent_executor_kwargs={"handle_parsing_errors": True}, ) # Define the tools available to the agent tools = [ Tool( name="Search", func=search.run, description=""" Useful for when you need to find information related to Exploratory Data Analysis(EDA) on web. Input should be a search query. """ ), Tool( name="CSV_Agent", func=pd_agent.run, description=""" Useful when you need to carry out EDA with insights from the dataset provided from. Input should be a search query. """ ), ] # Define the prefix, format instructions, and suffix for the agent's responses PREFIX = """[INST]Respond to the human as helpfully and accurately as possible. You have access to the following tools:""" FORMAT_INSTRUCTIONS = """Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input). Valid "action" values: "Final Answer" or {tool_names} while passing query to the tool make sure not to pass multiple queries. Provide only ONE action per $JSON_BLOB, as shown: ``` {{{{ "action": $TOOL_NAME, "action_input": $INPUT }}}} ``` Follow this format: Question: input question to answer Thought: consider previous and subsequent steps Action: ``` $JSON_BLOB ``` Observation: action result ... (repeat Thought/Action/Observation N times) Thought: I know what to respond Action: ``` {{{{ "action": "Final Answer", "action_input": "Final response to human" }}}} ```[/INST]""" SUFFIX = """Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:. Thought:[INST]""" HUMAN_MESSAGE_TEMPLATE = "{input}\n\n{agent_scratchpad}" # Create the structured chat agent agent = StructuredChatAgent.from_llm_and_tools( llm, tools, prefix=PREFIX, suffix=SUFFIX, human_message_template=HUMAN_MESSAGE_TEMPLATE, format_instructions=FORMAT_INSTRUCTIONS, ) # Create the agent executor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True) return agent_executor # Path to the CSV file csv_path = 'path_to_your_CSV_dataset' # Define the state structure class State(TypedDict): messages: List # Initialize the state graph graph_builder = StateGraph(State) # Define the chatbot function def chatbot(state: State): chatbot = create_agent(csv_path, llm) return {"messages": [chatbot.invoke(state["messages"])]} # Add the chatbot node to the graph graph_builder.add_node("chatbot", chatbot) # Set the entry and finish points for the graph graph_builder.set_entry_point("chatbot") graph_builder.set_finish_point("chatbot") # Compile the graph graph = graph_builder.compile() # Main loop to interact with the user while True: user_input = input("User: ") if user_input.lower() in ["quit", "exit", "q"]: print("Goodbye!") break for event in graph.stream({"messages": [("user", user_input)]}): for value in event.values(): print("Message structure:", value["messages"][-1]) print("Assistant:", value["messages"][-1]) print('-' * 50)
Code Explanation -
The provided code sets up a chatbot system that utilizes the langchain library to interact with users in an intelligent, dynamic way. The chatbot uses multiple tools, such as a web search tool (DuckDuckGo) and a pandas dataframe agent, to respond accurately to user queries. The system operates based on a state graph that manages the flow of conversation, helping to keep track of interactions and guide the user through a series of actions.
Language Model Initialization:
The AzureChatOpenAI language model is initialized with specific parameters. This model is responsible for processing the natural language inputs from the user and generating appropriate responses. By using this model, the chatbot can handle complex language tasks and provide insightful answers.
Agent Creation Function:
The code defines a function to create a chatbot agent that is equipped with various tools for enhanced functionality;
DuckDuckGoSearchRun(This tool allows the agent to perform web searches using DuckDuckGo, which is useful for retrieving up-to-date information or answering questions that require browsing the web.)
create_pandas_dataframe_agent(This tool enables the agent to interact with data stored in pandas dataframes, making it capable of analyzing and manipulating structured data.)
Tool(This is a general definition for the tools that are available to the agent, providing flexibility in adding different types of functionalities.)
StructuredChatAgent(This creates an agent with the specified tools and sets response format instructions, ensuring that the agent responds in a structured and predictable manner.)
AgentExecutor(This is responsible for executing the agent's tasks using the defined tools and ensuring the proper sequence of operations.)
CSV Path:
The path to the CSV file used by the pandas dataframe agent is specified. This file provides structured data that the agent can reference, making it capable of performing tasks like data analysis or answering questions based on the data.
State Definition:
The state structure is defined, outlining the different states or stages in the conversation. This structure helps track where the conversation is and guides the flow of interaction based on user input.
State Graph Initialization:
The state graph is initialized with the defined state structure. The state graph is crucial because it manages the transitions between different states, ensuring that the chatbot can handle multi-turn conversations effectively by keeping track of the context.
Chatbot Function:
A function is defined to create and invoke the chatbot with the current state. This function integrates all the components—language model, tools, and state graph—into a cohesive system that can respond to user inputs.
Graph Configuration:
The state graph is further configured by adding a chatbot node, setting the entry point (where the conversation starts), and specifying the finish point (where the conversation ends). This configuration ensures that the chatbot knows how to begin and end interactions with the user.
Main Loop:
The main loop continuously interacts with the user. It accepts user input, processes it through the state graph to determine the appropriate response, and then outputs the assistant’s reply. The loop keeps running until the user types a command like "quit", "exit", or "q", at which point the chatbot ends the session.
Sample Output -
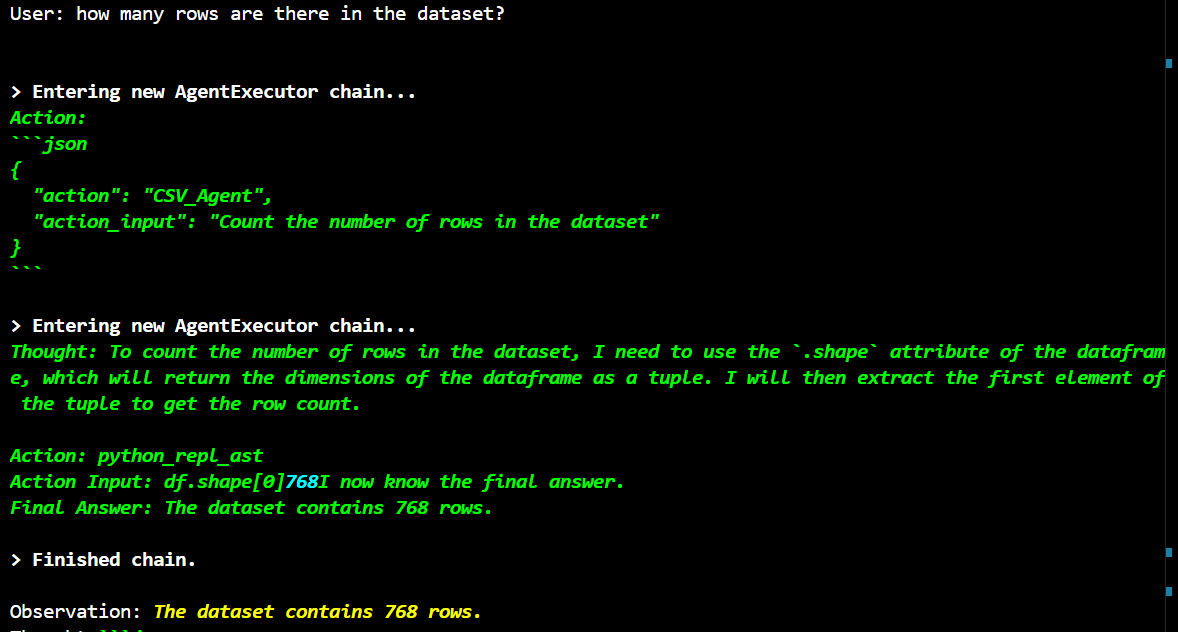
This simple agentic implementation helps visualizing any dataset you have. It also helps find outliers and assists in selecting the most relevant features for your machine learning model. Alternatively, you can create a graph for tools and enable the agent to interact with the tools as needed based on the specific requirements of the task.
Limitations/Drawbacks: Managing the state of the graph is challenging, especially since the state function changes based on the use case. If proper state management is not implemented, errors may arise later in the process, leading to instability.
Gaps in Existing Research: This approach is highly use case-specific, which limits its broader applicability. To improve flexibility, some approaches incorporate a tool node, allowing the agent to select tools based on specific requirements. Additionally, adding graphs under nodes for a more use case-centric design could provide greater adaptability and scalability.
Code Review and Technology stack analysis using CrewAI -
Version Used - 0.102.0
Framework description -
CrewAI is a fast, lightweight Python framework built from the ground up, independent of LangChain or other agent frameworks, offering developers both simplicity and fine-grained control. It is designed for creating autonomous AI agents that can be customized for any use case. CrewAI provides two key features: Crews, which allow developers to create AI teams where each agent has specific roles, tools, and goals to collaborate effectively, and Flows, which offer event-driven control, enabling precise task orchestration with single LLM calls, while also supporting Crews natively. This combination makes CrewAI a flexible solution for building complex, collaborative AI systems.

Key Features :
- Workflow management
- Flexible tools
- Task Management
- Intelligent collaboration
Description of class implemented(sequential process)
The sequential process ensures tasks are completed in a specific, linear order, making it ideal for projects that require clear, step-by-step execution. Key features include a linear task flow that ensures tasks follow a predetermined sequence, simplicity for projects with straightforward tasks, and easy monitoring for tracking task completion. To implement the sequential process, users can assemble their AI crew and define the tasks in the order they need to be executed, ensuring an efficient and organized approach to project completion.
- Installation and Usage Instructions :
It is recommended to create a virtual environment on your local machine before installing any packages.
Please refer to installation guide for getting started. Things get a bit complicated when it comes to CrewAI. This is due to the folder structure that the library follows. Strictly refer to the installation guide provided above. Before making any further changes try executing sample code and make sure the flow works end-too-end. In case you get any errors while running the crew please refer to the discussions. Make sure you have the following directory structure :
Problem Statement Addressed - The need for automating code review and technology stack analysis, enabling efficient evaluation and assessment of code quality and technology choices.
CodeReviewCrew/
├── .env
├── .gitignore
├── pyproject.toml
├── README.md
├── uv.lock
├── knowledge/
│ └── user_preference.txt
├── output/
├── src/
│ └── CodeReviewCrew/
│ ├── pycache/
│ ├── config/
│ │ ├── agents.yaml
│ │ └── agents.yaml
│ ├── tools/
│ │ ├── init.py
│ │ └── custom_tool.py
│ ├── main.py
│ ├── init.py
│ ├── crew.py
├── tests/
└── ...
Once you are have the crew running and directory in place make following changes:
- Change your .env file to -
MODEL=gpt-4o
AZURE_API_KEY=your_api_key
AZURE_API_BASE=https://example.baseURL.azure.com/
AZURE_API_VERSION=2024-05-01-preview
AZURE_SDK_TRACING_IMPLEMENTATION=opentelemetry
Ensure that you include the exact same parameters in your environment file (do not modify the names or remove the uppercase letters). For tracing, in some versions, if "opentelemetry" doesn't work, try replacing it with "opentelemetry".
- Add some context to the user preference file -
User name is XXXX. User is an AI Engineer. User is interested in AI Agents. User creates documents based on the code provided for more code readability.
- Setting up the agent configs -
Add this to agents.yaml
code_interpretor: role: > {topic} Senior Python coder goal: > Create high level description of code based on {topic} provided. backstory: > You are an experienced code reviewer with strong code readability and analyzing skills. llm: azure/gpt-4o documentation_expert: role: > {topic} Documentation Expert goal: > Create document based on information provided on {topic} to create a detailed report. backstory: > You are an experienced documentation expert with strong writing and analytical skills. You are capable of creating detailed reports based on the information provided. llm: azure/gpt-4o technology_expert: role: > {topic} Technology Expert goal: > Understand the technology stack used in {topic}. Gather information from web and provide detailed report on the technology stack. backstory: > You are an experienced technology expert with strong knowledge of the technology stack used in {topic}. You are capable of providing detailed reports on the technology stack. llm: azure/gpt-4o
Add this to tasks.yaml
code_interpretor_task: description: > Review the code you got and create a high-level description of the code, integrating it into a full section for a report. Ensure the report is detailed, includes all relevant code snippets, and provides insights into the code structure and functionality. expected_output: > A fully fledged report on explainability of the code, including code snippets, code structure, and functionality. agent: code_interpretor documentation_expert_task: description: > Review the context you got and document the information provided to create a detailed report. Ensure the report is detailed, includes all relevant information, and provides insights into the {topic}. expected_output: > A fully fledged report with detailed information, analysis, and insights into the {topic}. agent: documentation_expert technology_expert_task: description: > Review the context you got and provide a detailed report on the technology stack used in {topic}. Do thorough research on the web to gather information on the technology stack. Ensure the report is detailed, includes all relevant information, and provides insights into the technology stack. expected_output: > A fully fledged report with detailed information, analysis, and insights into the technology stack used in {topic}. agent: technology_expert
- Adding a custom tool -
from langchain_community.tools import DuckDuckGoSearchRun from crewai.tools import BaseTool class MyCustomDuckDuckGoTool(BaseTool): name: str = "DuckDuckGo Search Tool" description: str = "Search the web for a given query." def _run(self, query: str) -> str: # Ensure the DuckDuckGoSearchRun is invoked properly. duckduckgo_tool = DuckDuckGoSearchRun() response = duckduckgo_tool.invoke(query) return response def _get_tool(): # Create an instance of the tool when needed return MyCustomDuckDuckGoTool()
- Change the main.py and crew.py
# Replace main.py with the following code import sys import warnings from datetime import datetime from CodeReviewCrew.crew import CodeReviewCrew warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd") # This main file is intended to be a way for you to run your # crew locally, so refrain from adding unnecessary logic into this file. # Replace with inputs you want to test with, it will automatically # interpolate any tasks and agents information def run(): """ Run the crew. """ inputs = { 'topic': ''' #python code from swarm import Agent def process_refund(item_id, reason="NOT SPECIFIED"): """Refund an item. Refund an item. Make sure you have the item_id of the form item_... Ask for user confirmation before processing the refund.""" print(f"[mock] Refunding item {item_id} because {reason}...") return "Success!" def apply_discount(): """Apply a discount to the user's cart.""" print("[mock] Applying discount...") return "Applied discount of 11%" triage_agent = Agent( name="Triage Agent", instructions="Determine which agent is best suited to handle the user's request, and transfer the conversation to that agent.", ) sales_agent = Agent( name="Sales Agent", instructions="Be super enthusiastic about selling bees.", ) refunds_agent = Agent( name="Refunds Agent", instructions="Help the user with a refund. If the reason is that it was too expensive, offer the user a refund code. If they insist, then process the refund.", functions=[process_refund, apply_discount], ) def transfer_back_to_triage(): """Call this function if a user is asking about a topic that is not handled by the current agent.""" return triage_agent def transfer_to_sales(): return sales_agent def transfer_to_refunds(): return refunds_agent triage_agent.functions = [transfer_to_sales, transfer_to_refunds] sales_agent.functions.append(transfer_back_to_triage) refunds_agent.functions.append(transfer_back_to_triage) ''', 'current_year': str(datetime.now().year) } try: CodeReviewCrew().crew().kickoff(inputs=inputs) except Exception as e: raise Exception(f"An error occurred while running the crew: {e}") def train(): """ Train the crew for a given number of iterations. """ inputs = { "topic": "AI LLMs" } try: CodeReviewCrew().crew().train(n_iterations=int(sys.argv[1]), filename=sys.argv[2], inputs=inputs) except Exception as e: raise Exception(f"An error occurred while training the crew: {e}") def replay(): """ Replay the crew execution from a specific task. """ try: CodeReviewCrew().crew().replay(task_id=sys.argv[1]) except Exception as e: raise Exception(f"An error occurred while replaying the crew: {e}") def test(): """ Test the crew execution and returns the results. """ inputs = { "topic": "AI LLMs" } try: CodeReviewCrew().crew().test(n_iterations=int(sys.argv[1]), openai_model_name=sys.argv[2], inputs=inputs) except Exception as e: raise Exception(f"An error occurred while testing the crew: {e}")
# Replace crew.py with the following code from crewai import Agent, Crew, Process, Task from crewai.project import CrewBase, agent, crew, task # from crewai_tools import ( # DirectoryReadTool, # FileReadTool, # SerperDevTool, # WebsiteSearchTool # ) from CodeReviewCrew.tools.custom_tool import MyCustomDuckDuckGoTool Duck_search = MyCustomDuckDuckGoTool() # If you want to run a snippet of code before or after the crew starts, # you can use the @before_kickoff and @after_kickoff decorators # https://docs.crewai.com/concepts/crews#example-crew-class-with-decorators @CrewBase class CodeReviewCrew(): """CodeReviewCrew crew""" # Learn more about YAML configuration files here: # Agents: https://docs.crewai.com/concepts/agents#yaml-configuration-recommended # Tasks: https://docs.crewai.com/concepts/tasks#yaml-configuration-recommended agents_config = 'config/agents.yaml' tasks_config = 'config/tasks.yaml' # If you would like to add tools to your agents, you can learn more about it here: # https://docs.crewai.com/concepts/agents#agent-tools @agent def code_interpretor(self) -> Agent: return Agent( config=self.agents_config['code_interpretor'], verbose=True ) @agent def documentation_expert(self) -> Agent: return Agent( config=self.agents_config['documentation_expert'], verbose=True ) @agent def technology_expert(self) -> Agent: return Agent( config=self.agents_config['technology_expert'], verbose=True, tools=[Duck_search] ) # To learn more about structured task outputs, # task dependencies, and task callbacks, check out the documentation: # https://docs.crewai.com/concepts/tasks#overview-of-a-task @task def code_interpretor_task(self) -> Task: return Task( config=self.tasks_config['code_interpretor_task'], output_file='output/Code_report.md' ) @task def documentation_expert_task(self) -> Task: return Task( config=self.tasks_config['documentation_expert_task'], output_file='output/code_document_report.md' ) @task def technology_expert_task(self) -> Task: return Task( config=self.tasks_config['technology_expert_task'], output_file='output/technology_stack_report.md' ) @crew def crew(self) -> Crew: """Creates the CodeReviewCrew crew""" # To learn how to add knowledge sources to your crew, check out the documentation: # https://docs.crewai.com/concepts/knowledge#what-is-knowledge return Crew( agents=self.agents, # Automatically created by the @agent decorator tasks=self.tasks, # Automatically created by the @task decorator process=Process.sequential, verbose=True, # process=Process.hierarchical, # In case you wanna use that instead https://docs.crewai.com/how-to/Hierarchical/ )
- Running the crew -
To run the completed crew navigate to the root of your project
cd .\CodeReviewCrew\
Once you navigate to the root of your project run the crew
crewai run
- Results -
Check the output folder for results. LLM powered reports will be generated by each agent in .md format.
Sample Output -



This implementation automates code reviews and technology stack analysis by taking advantage of CrewAI’s advanced features, including built-in document-saving capabilities. This implementation helps in the process of identifying code quality issues, optimizing performance, and assessing compatibility across various technologies within a project.
Limitations/Drawbacks: There are recurring telemetry issues, despite attempts to resolve them using OpenTelemetry or other fixes. While these issues don’t impact the output of the crew, they negatively affect the clarity of the terminal output, which can be problematic for troubleshooting and monitoring.
Gaps in Existing Research: This implementation includes the sequential process approach to address the problem statement; however, a hierarchical process could also be a valuable alternative, depending on the complexity of the tasks. Additionally, there is potential to configure custom flows tailored to specific use cases, and agents could be trained over time to improve their performance and adaptability.
Agentic RAG using HuggingFace SmolAgents -

Version Used - 1.11.0
Framework description -
For certain low-level agentic tasks, such as chains or routers, writing all the code yourself can give you full control and a better understanding of your system. However, as the complexity increases—like when you want an LLM to call a function (tool calling) or run a while loop (multi-step agent)—you’ll need some abstractions. SmolAgents is a lightweight library developed by Hugging Face that makes it easier to create and run powerful agents. Its minimalist design sets it apart, with the entire agent logic contained in just about 1,000 lines of code. This simple yet efficient approach ensures that users can quickly get started while still benefiting from the full functionality needed for building robust agents.

Key Features :
- Simplicity
- Hub Integrations
- Code Agent Support
- Multi LLM support
Description of class implemented(ToolCallingAgent)
The ToolCallingAgent is a special agent in the smolagents library that helps solve tasks by using predefined tools or managed agents. It works by creating and using structured JSON-like tool calls, which help it communicate clearly with external systems like APIs or databases. Key features of the ToolCallingAgent include dynamically executing tools, managing intermediate results, keeping track of its actions through logging, and offering transparency in decision-making. It also uses a fallback mechanism to provide a final answer if it can't solve the task within a certain number of steps. Essentially, it makes interacting with tools more organized and efficient.
- Installation and Usage Instructions :
It is recommended to create a virtual environment on your local machine before installing any packages.
Please refer to installation guide for getting started.
Problem Statement Addressed - The need for automating Retrieval-Augmented Generation (RAG) processes, enabling intelligent and context-aware generation of responses.
from smolagents import AzureOpenAIServerModel from smolagents import ToolCallingAgent from smolagents import Tool from langchain_core.vectorstores import VectorStore from langchain.docstore.document import Document from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores import FAISS from langchain_huggingface import HuggingFaceEmbeddings from langchain_community.vectorstores.utils import DistanceStrategy from transformers import AutoTokenizer from dotenv import load_dotenv import fitz from tqdm import tqdm # Load environment variables load_dotenv() # Initialize the Azure OpenAI model model = AzureOpenAIServerModel( model_id="gpt-4o", azure_endpoint="https://example.endpoint.azure.com/", api_key="your_api_key", api_version="2024-08-01" ) # Function to extract text from a PDF file def extract_text_from_pdf(pdf_path): doc = fitz.open(pdf_path) text = "" for page in doc: text += page.get_text() return text # Path to your PDF file pdf_path = "path_to_your_pdf" # Extract text from the PDF pdf_text = extract_text_from_pdf(pdf_path) # Create a Document object from the extracted text pdf_document = Document(page_content=pdf_text, metadata={"source": "pdf_file"}) # Use the extracted PDF document as the source document source_docs = [pdf_document] # Initialize the text splitter text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer( AutoTokenizer.from_pretrained("thenlper/gte-small"), chunk_size=200, chunk_overlap=20, add_start_index=True, strip_whitespace=True, separators=["\n\n", "\n", ".", " ", ""], ) # Split documents and keep only unique ones print("Splitting documents...") docs_processed = [] unique_texts = {} for doc in tqdm(source_docs): new_docs = text_splitter.split_documents([doc]) for new_doc in new_docs: if new_doc.page_content not in unique_texts: unique_texts[new_doc.page_content] = True docs_processed.append(new_doc) # Embed the processed documents print("Embedding documents...") embedding_model = HuggingFaceEmbeddings(model_name="thenlper/gte-small") huggingface_doc_vector_db = FAISS.from_documents( documents=docs_processed, embedding=embedding_model, distance_strategy=DistanceStrategy.COSINE, ) # Define the RetrieverTool class class RetrieverTool(Tool): name = "retriever" description = "Using semantic similarity, retrieves some documents from the knowledge base that have the closest embeddings to the input query." inputs = { "query": { "type": "string", "description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.", } } output_type = "string" def __init__(self, vectordb: VectorStore, **kwargs): super().__init__(**kwargs) self.vectordb = vectordb def forward(self, query: str) -> str: assert isinstance(query, str), "Your search query must be a string" docs = self.vectordb.similarity_search( query, k=7, ) return "\nRetrieved documents:\n" + "".join( [f"===== Document {str(i)} =====\n" + doc.page_content for i, doc in enumerate(docs)] ) # Initialize the retriever tool and agent huggingface_doc_retriever_tool = RetrieverTool(huggingface_doc_vector_db) retriever_agent = ToolCallingAgent( tools=[huggingface_doc_retriever_tool], model=model, ) # Function to run the agentic RAG process def run_agentic_rag(question: str) -> str: question_prompt = f"""Using the information contained in your knowledge base, which you can access with the 'retriever' tool, give a comprehensive answer to the question below. Respond only to the question asked, response should be concise and relevant to the question. If you cannot find information, do not give up and try calling your retriever again with different arguments! Make sure to have covered the question completely by calling the retriever tool several times with semantically different queries. Question: {question}""" return retriever_agent.run(question_prompt) question = "Explain core capabilities of autogen" answer = run_agentic_rag(question) print(f"Question: {question}") print(f"Answer: {answer}")
Code Explanation -
This script is designed to extract text from a PDF, break it down into smaller pieces, embed these pieces into a vector database, and then use a retriever tool to find the most relevant documents based on a query. The code relies on several libraries and tools such as smolagents, langchain, transformers, and fitz to process the PDF and perform the retrieval tasks.
Imports and Environment Setup:
The script begins by importing the necessary libraries and modules required for the entire process. It also loads environment variables using the dotenv library, ensuring that any sensitive data, like API keys or configuration details, are securely managed and accessed.
Model Initialization:
The script initializes the Azure OpenAI model with specific parameters. This model will be responsible for processing the query and interacting with the data, allowing the agent to generate answers based on the retrieved documents.
PDF Text Extraction:
A function is defined to extract text from a given PDF file using the fitz library, which is a part of the PyMuPDF package. The function takes in a PDF file, processes it, and converts the extracted text into a Document object, making it easier to handle and manipulate.
Text Splitting:
Once the text is extracted, a text splitter is initialized using a tokenizer from HuggingFace. This step breaks the long text into smaller, manageable chunks, ensuring that each chunk is unique. This is crucial because smaller chunks make it easier to work with the data and improve the quality of retrieval results.
Document Embedding:
The text chunks are then embedded into a vector database using the FAISS library, which is used for efficient similarity search. A HuggingFace embedding model is applied to transform the text chunks into vector representations. These embeddings allow the system to understand the semantic meaning of the text and perform more accurate retrieval when a query is made.
Retriever Tool Definition:
The code defines a RetrieverTool class that is responsible for retrieving documents from the vector database. It does this by comparing the semantic similarity between the query and the embedded text chunks. This ensures that the documents retrieved are the most relevant to the given query.
Agent Initialization:
A ToolCallingAgent is initialized with the retriever tool and the Azure OpenAI model. This agent will manage the interaction between the user’s query and the retrieval system, ensuring that the query is processed and the correct documents are fetched from the database.
Question Answering Function:
The function run_agentic_rag is defined to handle the process of enhancing the query and using the retriever agent to find the most relevant documents. The function takes the question, processes it, and retrieves the documents that are most related to it, ultimately returning the best possible answer based on the information stored in the vector database.
Execution:
Finally, a sample question is defined and passed into the run_agentic_rag function to retrieve an answer. The script prints out the question along with the answer retrieved from the vector database, providing an example of how the system works in practice.
Sample Output -
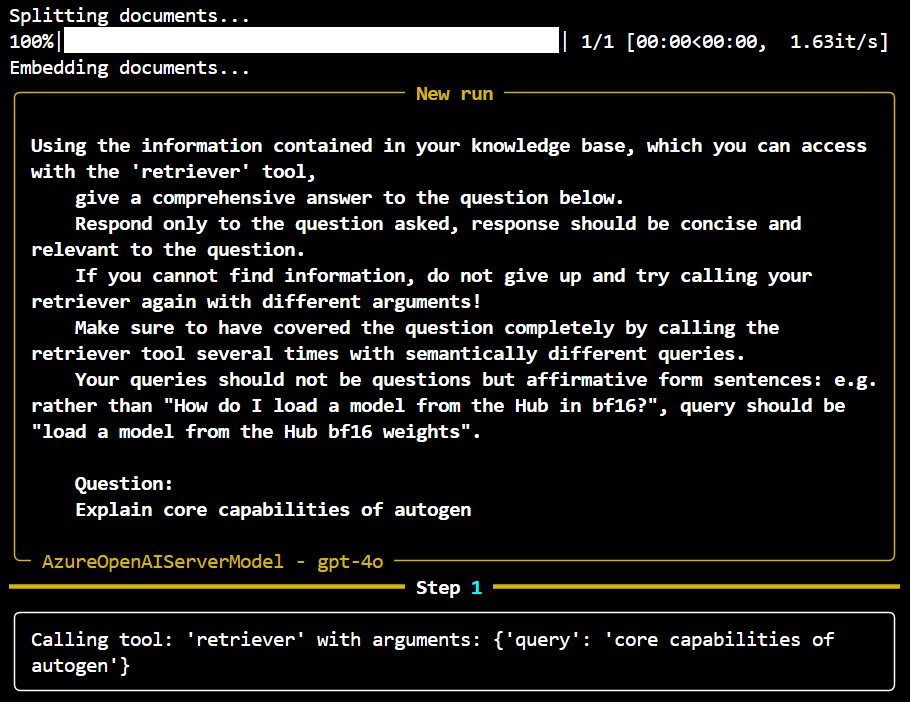
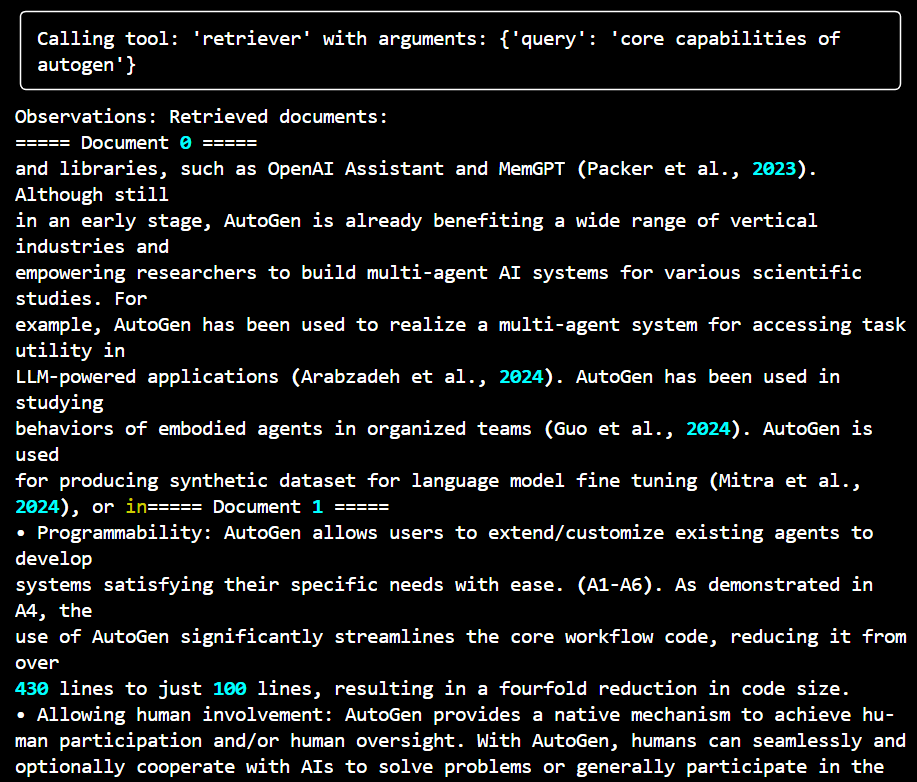
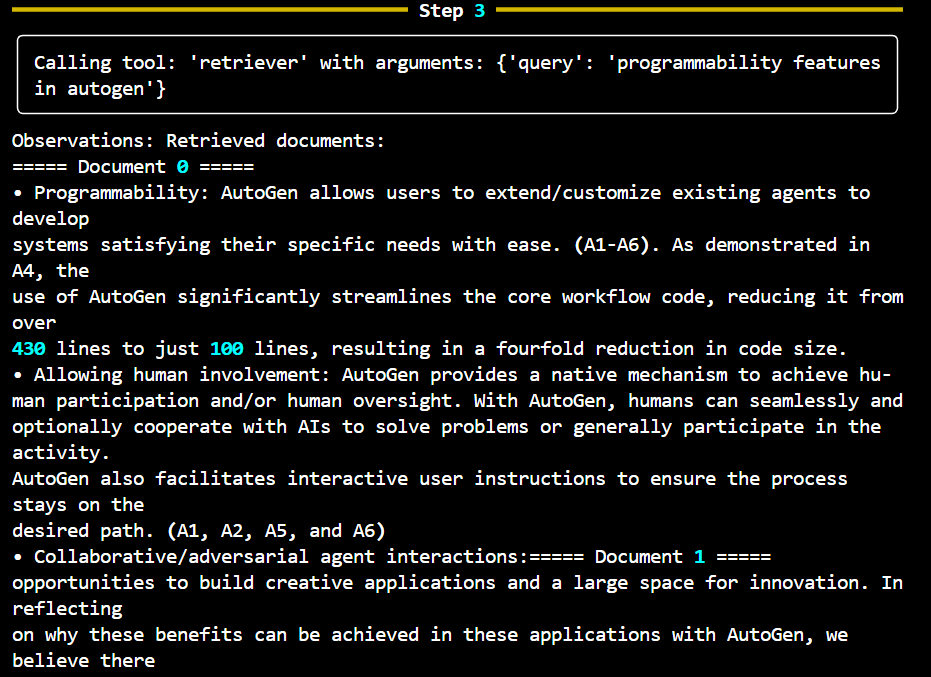
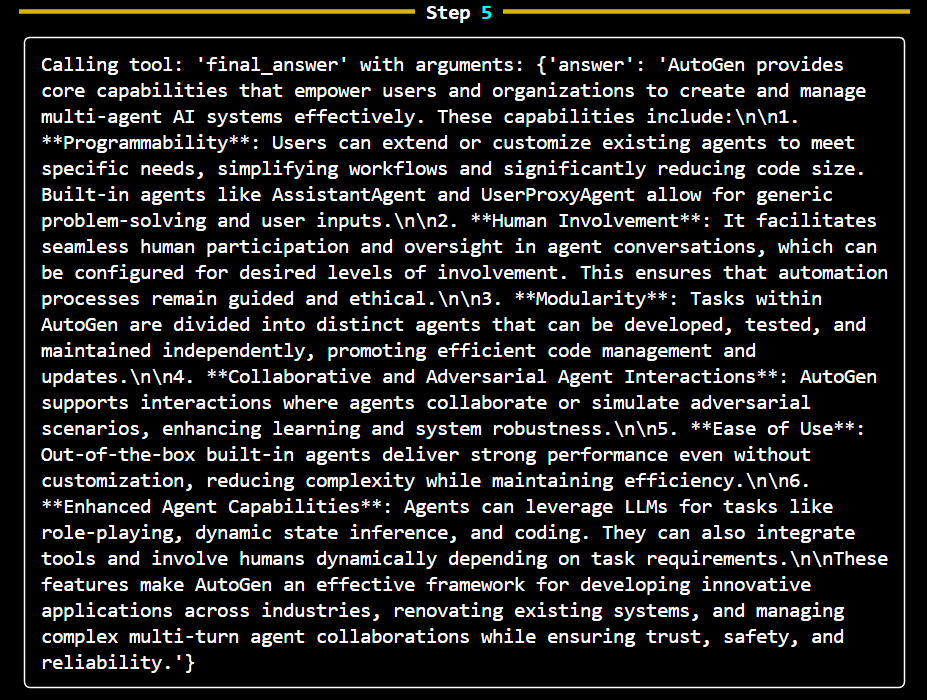

The script automates the process of querying a PDF document for information using AI. It extracts text, processes it into manageable chunks, converts the text into vector embeddings, and then uses a semantic search mechanism to find relevant answers to user queries. Agentic approach helps gather information multiple times for different relevant input prompt allowing more accurate answer.
Limitations/Drawbacks: The MultiStepAgent class encounters frequent issues related to Git, as the framework is still experimental and subject to frequent changes in functions, methods, and classes. This instability can create challenges when trying to maintain consistency.
Gaps in Existing Research: This approach lacks central orchestration or process integrations, primarily due to limited community support and insufficient examples in the documentation. While there are some multi-agent handling capabilities, they remain underexplored and are still in development. The CodeAgent class, however, is the most stable and reliable agent for code-related use cases.
AI powered Research and report generation using LlamaIndex -

Version Used - 0.12.22
Framework description -
LlamaIndex is a framework for creating LLM-powered agents and applications that enhance the ability of language models (LLMs) to interact with various types of data. Agents are assistants powered by LLMs that use tools to perform tasks such as research or data extraction. They can range from simple question-answering to more complex tasks involving decision-making and actions. Context augmentation is the process of making private or specific data accessible to LLMs so they can use it to solve problems. LlamaIndex helps with context-augmentation by allowing users to ingest, index, and process data from various sources like APIs, databases, PDFs, and more. LlamaIndex provides a comprehensive framework for building advanced LLM applications, combining agents, workflows, and context-augmentation to interact with diverse data sources. It supports a range of use cases, from simple question-answering to complex multi-modal applications and autonomous agents.

Key Features :
- Distributed Service Oriented Architecture
- Ease of deployment
- Scalability and resource management
- Customized orchestration flows
Description of class implemented(AgentWorkflow)
The AgentWorkflow is a tool that helps manage and run a system with one or more agents. It acts as an orchestrator, coordinating how agents interact and complete tasks. It ensures that tasks are completed in an orderly and efficient manner. It is especially useful for handling workflows that involve multiple steps or agents working together.
- Installation and Usage Instructions :
It is recommended to create a virtual environment on your local machine before installing any packages.
Please refer to installation guide for getting started.
Problem Statement Addressed: The need for automating AI-powered research and report generation, enabling efficient gathering, processing, and summarization of information to produce detailed reports.
import asyncio from llama_index.llms.azure_openai import AzureOpenAI from llama_index.core.agent.workflow import ( AgentOutput, ToolCall, ToolCallResult, ) from llama_index.core.workflow import Context from llama_index.core.agent.workflow import FunctionAgent from llama_index.core.agent.workflow import AgentWorkflow from langchain_community.tools import DuckDuckGoSearchRun # Azure OpenAI API credentials aoai_api_key = "ede5ff1d10f04521b9db46a6e15c19ff" aoai_endpoint = "https://azureaieu6682939841.cognitiveservices.azure.com/" aoai_api_version = "2024-08-01-preview" # Initialize the Azure OpenAI LLM llm = AzureOpenAI( engine="gpt-4o-Auto-Agent", model="gpt-4o", api_key=aoai_api_key, azure_endpoint=aoai_endpoint, api_version=aoai_api_version, ) # Define the search_web tool async def search_web(query: str) -> str: """Useful for using the web to answer questions.""" web_search = DuckDuckGoSearchRun() return str(web_search.run(query)) # Define the record_notes tool async def record_notes(ctx: Context, notes: str, notes_title: str) -> str: """Useful for recording notes on a given topic. Your input should be notes with a title to save the notes under.""" current_state = await ctx.get("state") if "research_notes" not in current_state: current_state["research_notes"] = {} current_state["research_notes"][notes_title] = notes await ctx.set("state", current_state) return "Notes recorded." # Define the write_report tool async def write_report(ctx: Context, report_content: str) -> str: """Useful for writing a report on a given topic. Your input should be a markdown formatted report.""" current_state = await ctx.get("state") current_state["report_content"] = report_content await ctx.set("state", current_state) return "Report written." # Define the review_report tool async def review_report(ctx: Context, review: str) -> str: """Useful for reviewing a report and providing feedback. Your input should be a review of the report.""" current_state = await ctx.get("state") current_state["review"] = review await ctx.set("state", current_state) return "Report reviewed." # Define the ResearchAgent research_agent = FunctionAgent( name="ResearchAgent", description="Useful for searching the web for information on a given topic and recording notes on the topic.", system_prompt=( "You are the ResearchAgent that can search the web for information on a given topic and record notes on the topic. " "Once notes are recorded and you are satisfied, you should hand off control to the WriteAgent to write a report on the topic. " "You should have at least some notes on a topic before handing off control to the WriteAgent." ), llm=llm, tools=[search_web, record_notes], can_handoff_to=["WriteAgent"], ) # Define the WriteAgent write_agent = FunctionAgent( name="WriteAgent", description="Useful for writing a report on a given topic.", system_prompt=( "You are the WriteAgent that can write a report on a given topic. " "Your report should be in a markdown format. The content should be grounded in the research notes. " "Once the report is written, you should get feedback at least once from the ReviewAgent." ), llm=llm, tools=[write_report], can_handoff_to=["ReviewAgent", "ResearchAgent"], handoff_logic=lambda state: "ReviewAgent" if state.get("report_content") != "Not written yet." else "ResearchAgent" ) # Define the ReviewAgent review_agent = FunctionAgent( name="ReviewAgent", description="Useful for reviewing a report and providing feedback.", system_prompt=( "You are the ReviewAgent that can review the write report and provide feedback. " "Your review should either approve the current report or request changes for the WriteAgent to implement. " "If you have feedback that requires changes, you should hand off control to the WriteAgent to implement the changes after submitting the review." ), llm=llm, tools=[review_report], can_handoff_to=["WriteAgent"], ) # Define the agent workflow agent_workflow = AgentWorkflow( agents=[research_agent, write_agent, review_agent], root_agent=research_agent.name, initial_state={ "research_notes": {}, "report_content": "Not written yet.", "review": "Review required.", }, ) # Main function to run the agent workflow async def main(): handler = agent_workflow.run( user_msg=( "Write me a report on the Top 5 Agentic Frameworks. " "Briefly describe the all the frameworks in detail and give sample code implementations in python " "Also give technology stack used in each framework." ) ) current_agent = None current_tool_calls = "" # Process events from the agent workflow async for event in handler.stream_events(): if ( hasattr(event, "current_agent_name") and event.current_agent_name != current_agent ): current_agent = event.current_agent_name print(f"\n{'='*50}") print(f"🤖 Agent: {current_agent}") print(f"{'='*50}\n") # if isinstance(event, AgentStream): # if event.delta: # print(event.delta, end="", flush=True) # elif isinstance(event, AgentInput): # print("📥 Input:", event.input) elif isinstance(event, AgentOutput): if event.response.content: print("📤 Output:", event.response.content) if event.tool_calls: tool_names = [call.tool_name for call in event.tool_calls] current_tool_calls += f"🛠️ Planning to use tools: {tool_names}\n" print("🛠️ Planning to use tools:", tool_names) elif isinstance(event, ToolCallResult): tool_result = ( f"🔧 Tool Result ({event.tool_name}):\n" f" Arguments: {event.tool_kwargs}\n" f" Output: {event.tool_output}\n" ) current_tool_calls += tool_result print(tool_result) elif isinstance(event, ToolCall): tool_call = ( f"🔨 Calling Tool: {event.tool_name}\n" f" With arguments: {event.tool_kwargs}\n" ) current_tool_calls += tool_call print(tool_call) # Print a summary of tool calls print("\nSummary of tool calls:") print(current_tool_calls) # Run the main function if __name__ == "__main__": asyncio.run(main())
Code Explanation -
This code defines an agent-based workflow utilizing the llama_index and langchain_community libraries to create a collaborative environment where three agents work together to generate a report on a given topic. The workflow is designed to have each agent perform specific tasks in a sequential manner, with each agent's output serving as the input for the next one.
Azure OpenAI Initialization:
The script begins by initializing the Azure OpenAI LLM (Language Model) using the provided API credentials. This sets up the model that will power the agents, allowing them to generate natural language responses and process queries.
Tool Definitions:
Several tools are defined to assist the agents in carrying out their tasks;
search_web(Uses DuckDuckGo to search the web for information related to the topic at hand.)
record_notes(A tool that helps record notes about the topic, which will later be used by the writing agent to create the report.)
write_report(A tool designed to write a report on the given topic using the recorded notes.)
review_report(A tool that reviews the generated report and provides feedback for improvement.)
Agent Definitions:
The script defines three agents, each with a specific role;
ResearchAgent(This agent is responsible for searching the web for relevant information and recording notes.)
WriteAgent(The WriteAgent uses the research notes provided by the ResearchAgent to write a detailed report on the topic.)
ReviewAgent(After the report is written, this agent reviews the content and provides feedback or suggests improvements to ensure the quality of the report.)
Agent Workflow:
The agent workflow is structured to start with the ResearchAgent, which performs the web search and note-taking. After the research phase, the WriteAgent takes over, utilizing the notes to write the report. Finally, the ReviewAgent reviews the report, ensuring that it meets the desired quality before completion. This collaborative process allows the agents to hand off tasks and work together to create a polished, comprehensive report.
Main Function:
The main function runs the agent workflow and processes events as the agents perform their tasks. It prints the outputs and tool calls, allowing you to track the workflow and understand how each agent interacts with the tools and contributes to the final result. The agents' outputs are passed from one to the next in a smooth sequence, making the process of generating the report automated and efficient.
Sample Output -
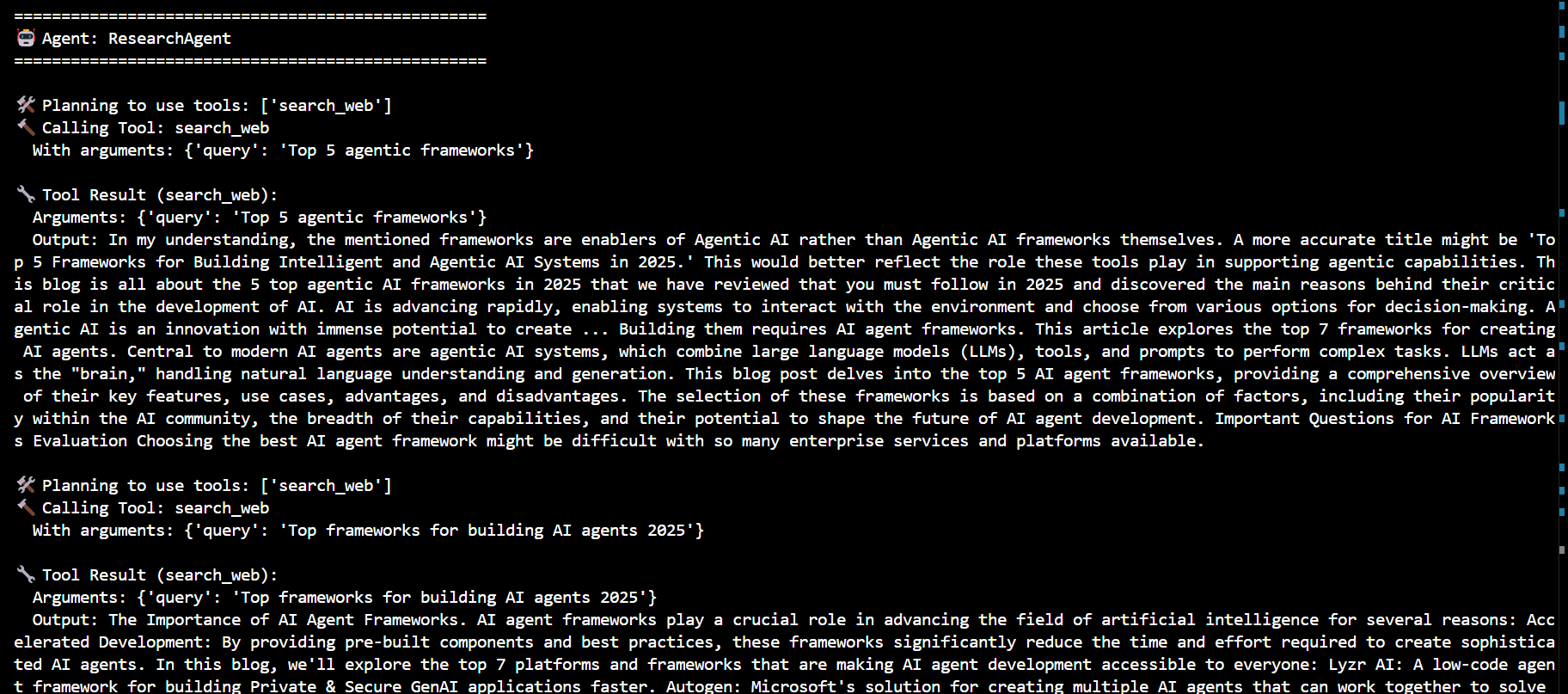
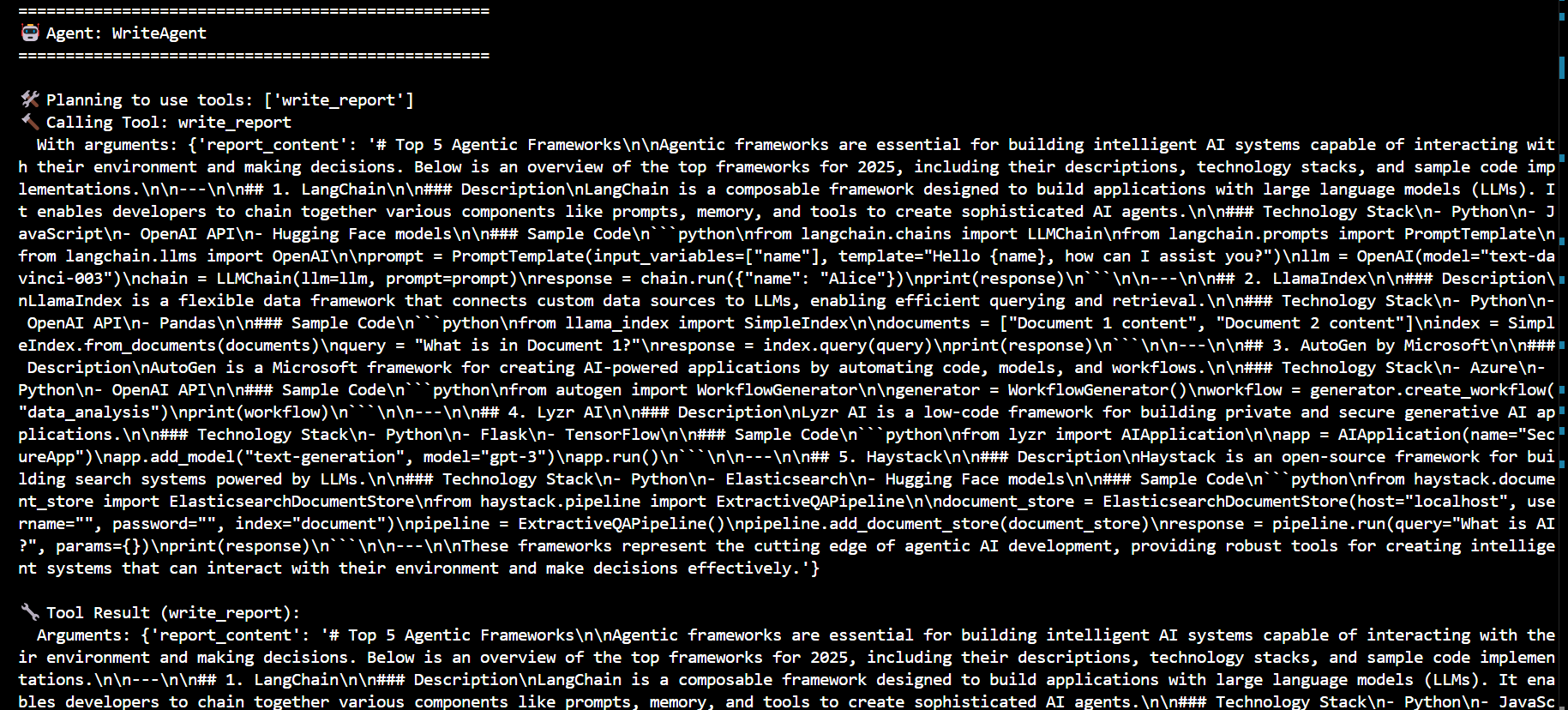
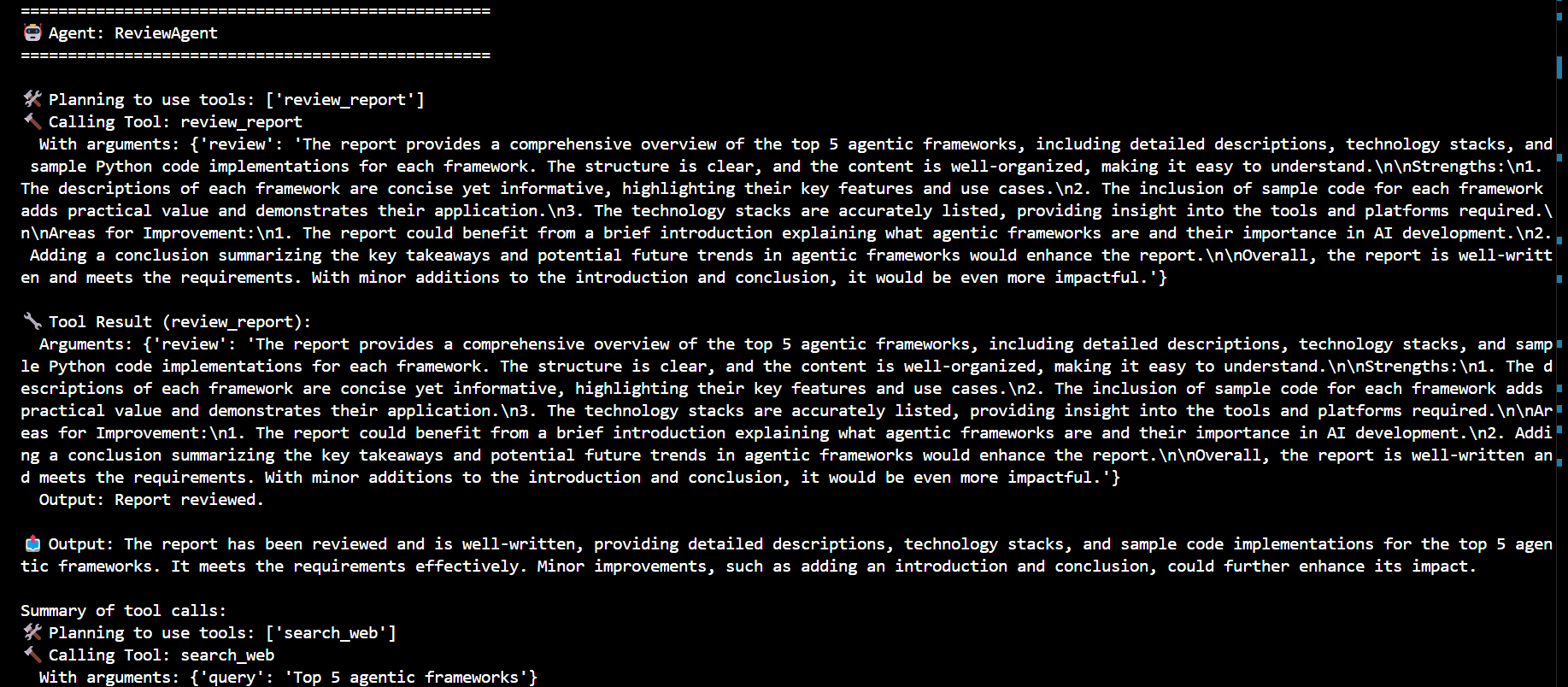
A simple multi-agentic approach to perform research, write reports, and review them, utilizing a combination of tools such as web search and note recording. The code demonstrates a multi-agent workflow to research a topic, generate a report, and refine it through feedback. The agents work together to handle the process from gathering information to producing a final reviewed report.
Limitations/Drawbacks: The system is heavily dependent on OpenAI, as it internally utilizes the entire OpenAI ecosystem. Additionally, there is a lack of conceptual documentation—while the documentation offers numerous code examples, it doesn't provide a clear understanding of the architectural framework.
Gaps in Existing Research: For this problem statement, I used the workflow concept from LlamaIndex, but there are many other orchestration deployment patterns available. The framework also supports older agent classes (such as OldOpenAIAgent and OldReActAgent), making it easier to migrate between different versions of the framework.
Deployment Considerations -
When implementing these agentic AI frameworks in a production environment, security considerations are crucial to ensure safe and reliable operation. For instance, frameworks like LangGraph that execute Python code via a REPL environment need strict safeguards to prevent the execution of malicious code. It's important to opt-in to certain features and use access controls to limit exposure to security risks. Additionally, frameworks such as SmolAgents and Autogen, which interact with external tools and APIs, must ensure secure communication and handle potential vulnerabilities in data exchanges. Crewai's sequential process must be closely monitored to avoid unauthorized task execution, while LlamaIndex workflows must maintain integrity to prevent malicious agents from hijacking task execution. In production, these frameworks should be deployed with comprehensive logging, access control mechanisms, and continuous security auditing to minimize risks and ensure safe deployment.
Reader next steps -
Now that you have an understanding of the prerequisites and requirements, the next step is to get hands-on with the frameworks. Start by setting up your development environment, installing the necessary libraries, and obtaining any required API keys. Once everything is set up, try experimenting with some basic examples to get familiar with how each framework works. Here are some more frameworks that you can consider exploring :
- Microsoft - Semantic Kernel Agents
- Microsoft - Prompt Flow
- AzureAI - Agent Service
Microsoft provide industry scalable solutions that you can directly integrate with your existing system or flow. You can also try out enterprise versions for including agentic frameworks into your organization.
Results
As we reach the end of this research and its findings, I’d like to note that while I initially intended to explore more frameworks, I focused on these key ones—Autogen, LangGraph, Crewai, SmolAgents, and LlamaIndex—to showcase their unique functionalities and applications in agentic AI.
For Autogen, I implemented the MagenticOneGroupChat system, which is a versatile, multi-agent architecture capable of tackling open-ended tasks across various domains. This system, built on the autogen-core library and upgraded with autogen-agentchat, is orchestrated through the MagenticOneGroupChat, which supports collaborative agent teams for task execution. This provided a highly modular and user-friendly interface.
In LangGraph, I worked with the create_pandas_dataframe_agent class, which allows language models to seamlessly interact with data in Pandas DataFrames using natural language queries. This feature greatly simplifies complex tasks like filtering, aggregation, and visualization. However, a potential security concern arises from executing Python code in a REPL environment, requiring users to opt-in and manage potential risks carefully.
For Crewai, I focused on implementing the sequential process class. This class ensures tasks are executed in a specific, linear order, which is perfect for projects needing clear, step-by-step execution. It’s simple yet effective for straightforward tasks, with easy monitoring for tracking progress.
In SmolAgents, I worked with the ToolCallingAgent, a specialized agent that facilitates task completion by invoking predefined tools or managed agents. The agent uses structured JSON-like tool calls to interact with external systems, such as APIs or databases, offering dynamic tool execution, state management, and transparent decision-making, which makes the entire process more efficient and organized.
Lastly, for LlamaIndex, I explored the AgentWorkflow, a tool that orchestrates and manages systems with multiple agents. This class enables smooth coordination between agents, ensuring that tasks are carried out in an orderly, efficient manner, making it ideal for workflows that involve several agents working together in a system.
Through these implementations, we’ve observed how each framework addresses different aspects of agentic AI, from task automation and data handling to security and workflow management. While each framework has its strengths, the results also highlight areas for improvement, such as scalability and adaptability, which are crucial for real-world applications.