
Self-driving cars in Egypt face challenges due to chaotic traffic, diverse road conditions, and a lack of localized datasets. Global datasets don't reflect Egypt's unique driving environment, including unstructured traffic, diverse vehicle types, and cultural driving norms. To address this, researchers collect their own data, capturing local nuances and annotating it for training models. While resource-intensive, this effort helps tailor autonomous systems to Egypt’s specific needs, improving their viability and safety.
Advanced-Lane-Detection
Advanced Lane Segmentation - Computer vision
In Advanced Lane Segmentation, we apply computer vision techniques to augment video output with a detected road lane, road radius curvature and road center offset.
Steps of this project are the following: Compute the camera calibration matrix and distortion coefficients given a set of chessboard images. Apply a distortion correction to raw images. Use color transforms, gradients, etc., to create a thresholded binary image. Apply a perspective transform to rectify binary image (“birds-eye view”). Detect lane pixels and fit to find the lane boundary. Determine the curvature of the lane and vehicle position with respect to center. Warp the detected lane boundaries back onto the original image. Output visual display of the lane boundaries and numerical estimation of lane curvature and vehicle position.
Camera Calibration Every camera has some distortion factor in its lens. The known approach to correct for that in (x,y,z) space is apply coefficients to undistort the image. To calculate this a camera calibration process is required. It involves reading a set of warped chessboard images, converting them into grey scale images before using cv2.findChessboardCorners() to identify the corners as imgpoints.
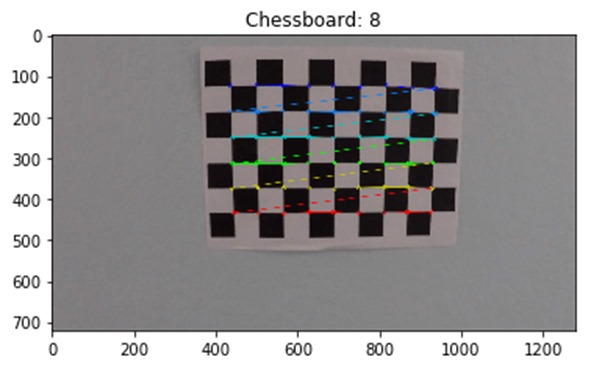
Initial experimentation occurred in a separate notebook before being refactored back into the project notebook in the combined_threshold function. It has a number of default thresholds for sobel gradient x&y, sobel magnitude, sober direction, Saturation (from HLS), Red (from RGB) and Y (luminance from YUV) plus a threshold type parameter (daytime-normal, daytime-bright, daytime-shadow, daytime-filter-pavement). Whilst the daytime-normal threshold worked great for the majority of images there were situations where it didn't e.g. pavement colour changes in bright light and shadow.

Warped box seek and new polynomial fit Radius of curvature calculation and vehicle from centre offset In road design, curvature is important and its normally measured by its radius length. For a straight line road, that value can be quite high. In this project our images are in pixel space and need to be converted into meters. The images are of US roads and I measured from this image the distance between lines (413 pix) and the height of dashes (275 px). Lane width in the US is ~ 3.7 meters and dashed lines 3 metres. Thus xm_per_pix = 3.7/413 and ym_per_pix = 3./275 were used in calc_curvature. The function converted the polynomial from pixel space into a polynomial in meters. To calculate the offset from centre, I first determined where on the x plane, both the left lx and right rx lines crossed the image near the driver. I then calculated the xcentre of the image as the width/2. The offset was calculated such (rx - xcenter) - (xcenter - lx) before being multiple by xm_per_pix.
lane.result_decorated

Speed-Bump-Detection-marked-unmarked
Speed-Bump-Detection-marked-unmarked
Object detection Addressed a real-world challenge in our graduation project by detecting unmarked speed bumps on Egyptian streets, a task complicated by limited data. Collected our own data and utilized YOLO and SSD to achieve optimal results.
Sign Detection
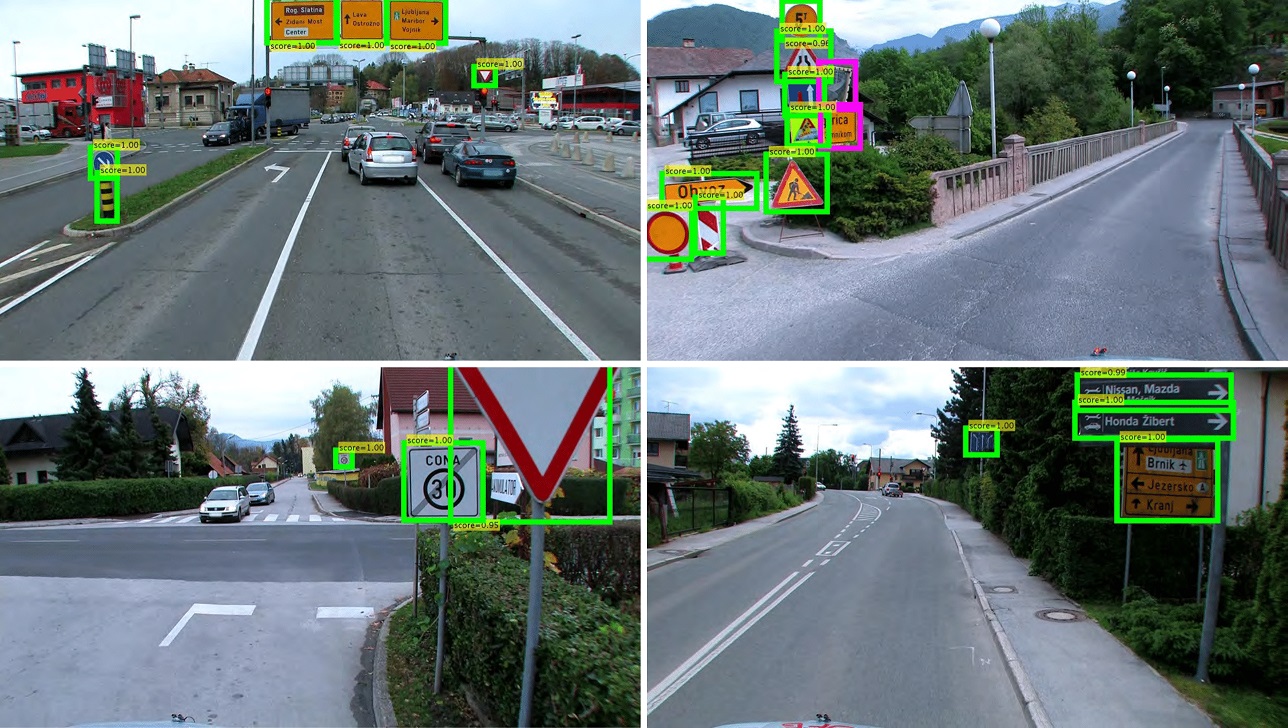
Due to the presence of a large number of signs, we paid attention to the most important signs, such as all speed signs, traffic signals, and stop signals. All of this to make the car able to make the correct decision in terms of speeding or stopping when detecting any of these signals also used YOLOv8.
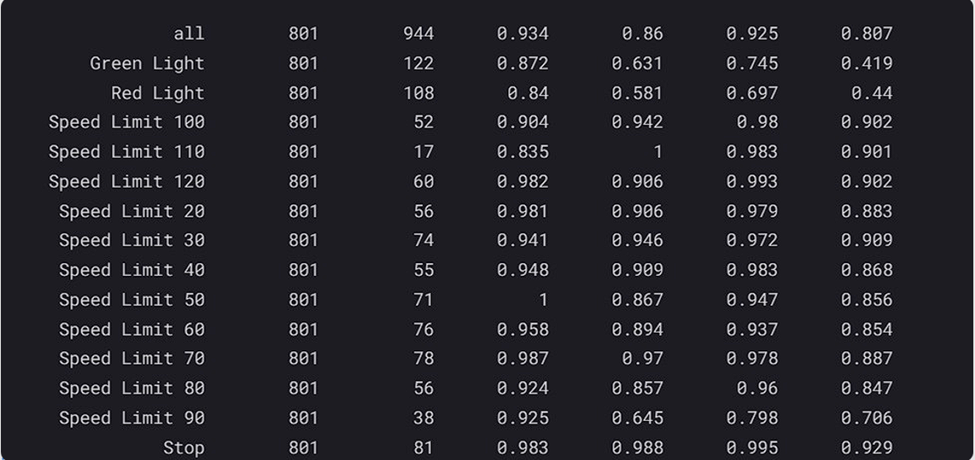
Here the classes and the accuracy of each class
Scene Segmentation
Unet
Introduction
The creation of the U-Net was a ground breaking discovery in the realm of image segmentation, a field focused on locating objects and boundaries within an image. This novel architecture proved to carry immense value in the analysis of biomedical images.
The U-Net is a special type of Convolutional Neural Network (CNN) and as a result, it is highly recommend to be familiar with them before delving into this article. If necessary please learn about CNNs here.
The U-Net is composed of two main components: a contracting path and an expanding path.
Contracting path: aims to decrease the spatial dimensions of the image, while also capturing relevant information about the image.
Expanding path: aims to upsample the feature map and produce a relevant segmentation map using the patterns learnt in the contracting path.
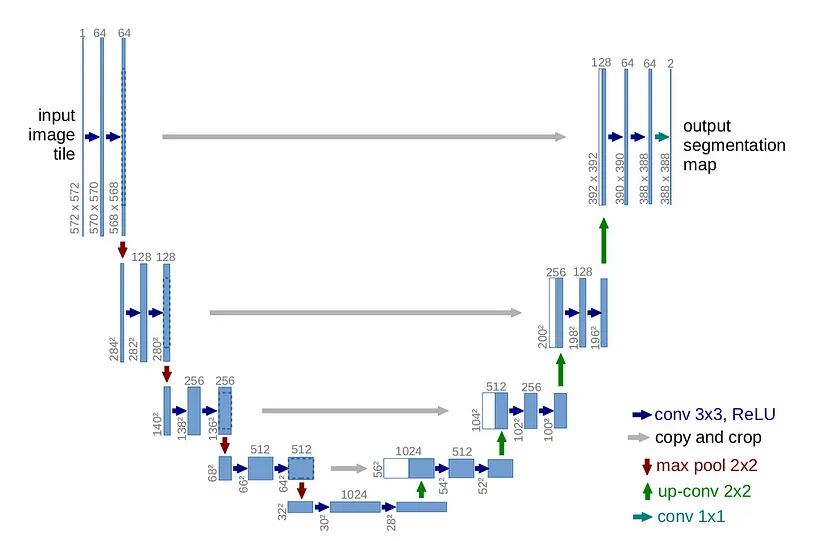
UNet is a deep learning model widely used for scene segmentation in self-driving cars due to its ability to classify each pixel in an image. Its encoder-decoder architecture with skip connections enables precise segmentation of roads, lanes, vehicles, and pedestrians, which is essential for understanding the driving environment. UNet’s efficiency makes it suitable for real-time applications, ensuring accurate object detection and boundary delineation, critical for safe navigation and decision-making in autonomous driving systems.
Scene Segmentation

The most prevalent part of self-driving is semantic segmentation, which associates image pixels with useful labels such as sign, light, curb, road, vehicle etc. The main use for segmentation is to identify the drivable surface, which aids in ground plane estimation, object detection and lane boundary assessment. Segmentation labels are also being directly integrated into object detection as pixel masks, for static objects such as signs, lights and lanes, and moving objects such cars, trucks, bicycles and pedestrians.
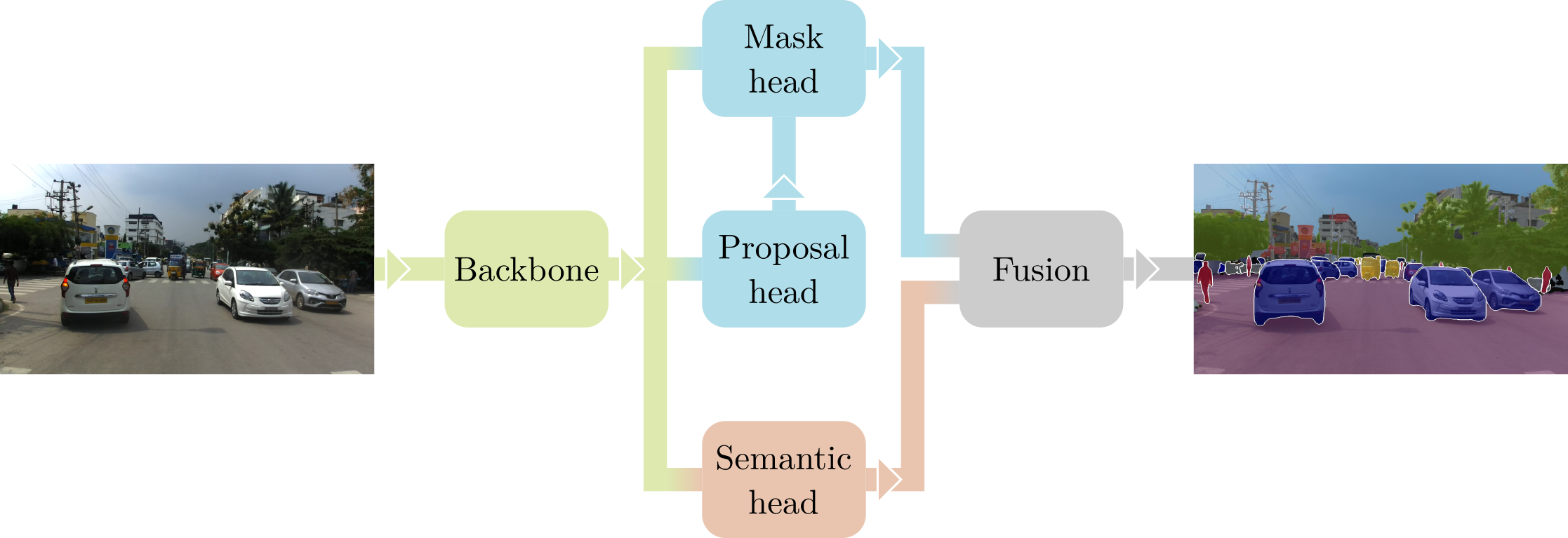
Seamless Scene Segmentation is a CNN-based architecture that can be trained end-to-end to predict a complete class- and instance-specific labeling for each pixel in an image. To tackle this task, also known as "Panoptic Segmentation", we take advantage of a novel segmentation head that seamlessly integrates multi-scale features generated by a Feature Pyramid Network with contextual information conveyed by a light-weight DeepLab-like module.
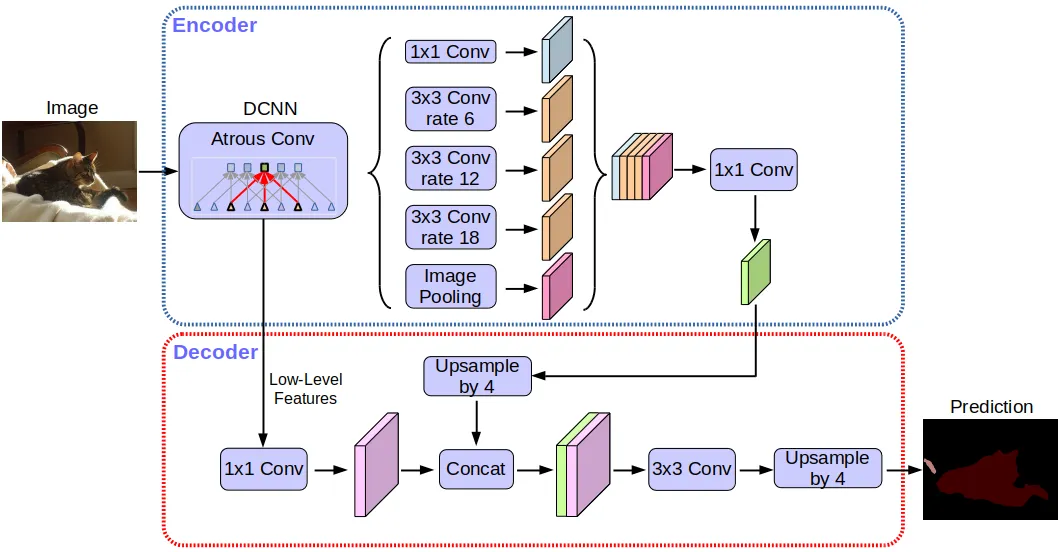
The State of the Art model for semantic segmentaiton (DeepLabV3+) DeepLab is a leading series of image semantic segmentation models renowned for their exceptional performance in pixel-level classification tasks. The latest iteration, DeepLabv3+, represents the state-of-the-art in this domain. One of its key innovations is the integration of the atrous spatial pyramid pooling (ASPP) operation, strategically placed at the end of the encoder.
We trained MobileNetV2 on the Cityscapes dataset specifically to improve its performance in semantic segmentation tasks tailored for Egyptian streets. This fine-tuning process optimized the model's ability to accurately classify objects and delineate semantic regions within urban scenes commonly found in Egyptian cities. The trained MobileNetV2 model now exhibits enhanced capabilities for scene understanding, making it a valuable asset for applications such as urban planning and autonomous navigation in Egyptian urban environments. Final output example
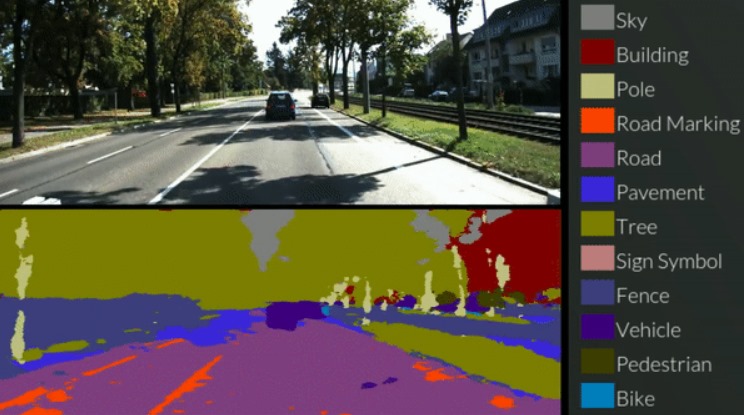
FINAL OUTPUT

Depth_Estimation
Depth_Estimation
The State of the Art of Depth Estimation from Single Images (SGDepth)
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during

This is the case for monocular depth estimation, where the goal is to help the computer understand the depth of images and predict how far scene elements are for each pixel of a single image.

In monocular depth estimation, the goal is the generation of pixel-wise estimates (a.k.a. a depth map) of how far each scene element is from the camera. Using SGDepth for Distance Evaluation: We employed SGDepth to evaluate the distance of moving cars and pedestrians in autonomous driving scenarios. By combining depth estimation with object detection and tracking, we achieved precise real-time evaluation of spatial relationships between the self-driving car and surrounding objects, enhancing safety and efficiency on the road.
ADAS (Advanced Driving Assistance System)
ADAS (Advanced Driving Assistance System)
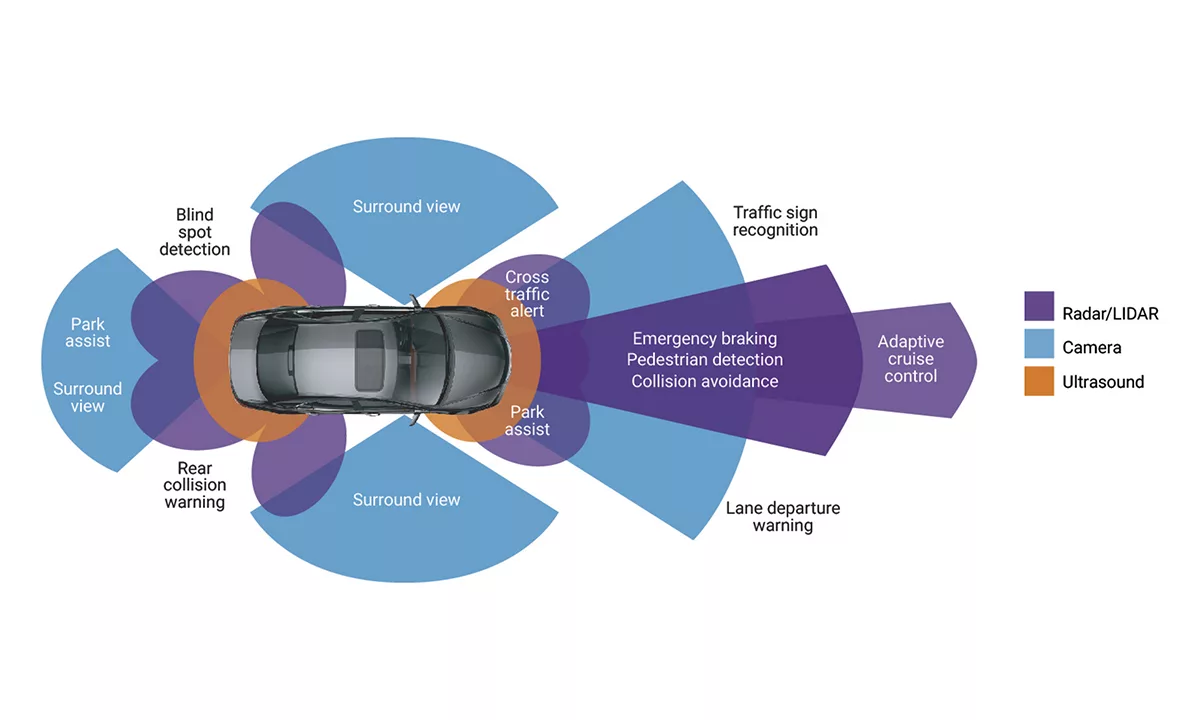
Essential safety-critical ADAS applications include:
1 - Pedestrian detection/avoidance
2 - Lane departure warning/correction
3 - Traffic sign recognition
4 - Automatic emergency braking
5 - Blind spot detection
These lifesaving systems are key to the success of ADAS applications. They incorporate the latest interface standards and run multiple vision-based algorithms to support real-time multimedia, vision coprocessing, and sensor fusion subsystems.
The modernization of ADAS applications is the first step toward realizing autonomous vehicles.
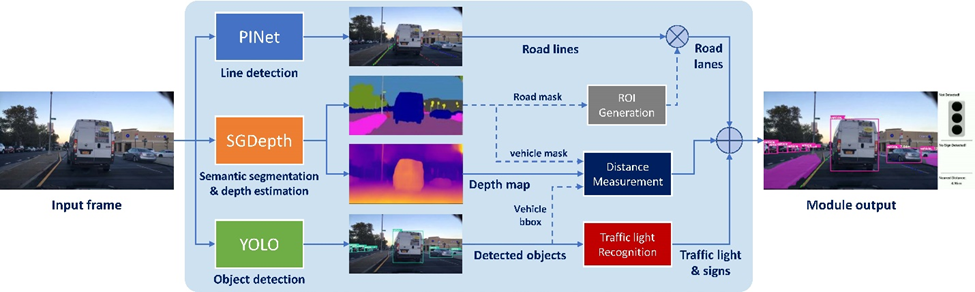
Integrating state-of-the-art models SGDepth for depth estimation, YOLO for object detection, DeepLabv3+ for scene segmentation, and PINet for lane detection creates a foundation for an Advanced Driver Assistance System (ADAS). SGDepth calculates depth information, important for understanding the layout of the environment, while YOLO detects objects such as vehicles, pedestrians, and cyclists in real-time. Also, SGDepth provides semantic segmentation, allowing the system to delineate road boundaries, lane markings, Additionally, PINet specializes in lane detection, enabling the ADAS to identify lane boundaries and assist drivers in lane keeping tasks. By integrating these models, the ADAS gains capabilities, enhancing its ability to assist drivers in various scenarios, from collision avoidance to lane keeping and night vision, improving road safety and driving experience.
PINET
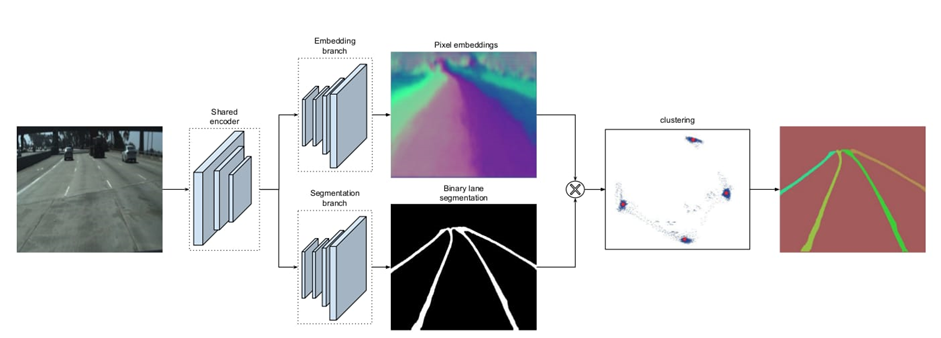
As is clear in the picture, for main script, the arrangement and way the models work together, where the YOLO is used in object detection, and then we send the bounding box of detected objects to the depth model to evaluate the distance of these objects. It is also used in scene segmentation to determine the road, the side walk, and the PINet model. It is used to divide the road into lanes, which facilitates the organization and movement of cars. PINet (key points estimation and point instance segmentation approach for lane detection

important approach for self-driving cars as they provide reliable lane detection. By identifying key points and segmenting lane instances, PINet enables the vehicle to maintain its position within lanes, navigate complex road layouts, and execute safe lane-changing maneuvers.
FINAL OUTPUT
