1. Abstract
Generating high-quality captions for images is a critical challenge in AI, requiring advancements at the intersection of computer vision and natural language processing. This study introduces a novel image captioning pipeline that integrates the CPTR (Full Transformer Network) architecture with Self-critical Sequence Training (SCST) for optimization. By using a two-step training process, we demonstrate substantial improvements in caption quality, as measured by the METEOR score. This work highlights the potential of combining state-of-the-art transformers with reinforcement learning techniques to address complex computer vision tasks.
2. Introduction
Image captioning, the task of generating textual descriptions for visual content, bridges the gap between vision and language understanding. While traditional models have achieved notable success in optimizing differentiable objectives, they often fall short when it comes to non-differentiable evaluation metrics such as METEOR and BLEU. These metrics, which better reflect human evaluation criteria, remain challenging to optimize directly with standard training approaches. Addressing this limitation is essential for improving alignment between model-generated captions and human judgment.
This study presents a two-step training pipeline that leverages the strengths of:
- CPTR, a transformer-based architecture with a Vision Transformer (ViT) encoder and transformer decoder.
- SCST, a reinforcement learning technique that directly optimizes non-differentiable metrics.
We hypothesize that reinforcement learning can significantly enhance alignment between model-generated captions and human evaluation metrics. The contributions of this work are as follows:
- Implementation of a CPTR-based baseline model for image captioning.
- Optimization of caption quality using SCST with METEOR as the reward signal.
- Evaluation on the Flickr8K dataset, showing noticeable improvements in METEOR score.
3. Related Work
3.1 Transformer Architectures in Image Captioning
The transformer model, initially proposed by Vaswani et al. (2017), has become a cornerstone of NLP and computer vision tasks. CPTR [1], a fully transformer-based image captioning model, eliminates the need for convolutional backbones by utilizing a Vision Transformer encoder.
3.2 Reinforcement Learning for Captioning
SCST [2], introduced by Rennie et al., revolutionized image captioning by enabling direct optimization of evaluation metrics. Unlike supervised learning, SCST trains models to generate captions that maximize rewards such as CIDEr, BLEU, or METEOR.
4. Methodology
4.1 CPTR Architecture
Our baseline model employs CPTR, which integrates:
- A Vision Transformer (ViT) encoder that processes images into sequences of visual tokens.
- A Transformer decoder that generates captions by attending to these visual tokens.

4.2 SCST Optimization
In the second training phase, we apply SCST to optimize captions using the METEOR score as a reward signal. The SCST loss function is defined as:
where:
: model parameters, : sampled sequence, : reward (METEOR score), : baseline reward (e.g., greedy-decoded sequence).
SCST encourages the model to generate captions with higher rewards than the baseline.

5. Loss Function
5.1 Baseline Loss: Zero-masked Categorical Cross Entropy
The baseline training uses:
where
5.2 SCST Loss
SCST optimizes METEOR directly, as defined in Section 4.2.
6. Dataset
We evaluate our pipeline on the Flickr8K dataset, which contains:
- Training: 23,890 image-caption pairs.
- Validation: 5,975 image-caption pairs.
- Testing: 7,470 image-caption pairs.
7. Experimental Setup
7.1 Platform and Tools
- Hardware: Colab L4 GPU.
- Pretrained Components:
- Tokenizer:
distilbert-base-uncased - Vision Encoder:
google/vit-base-patch16-384.
- Tokenizer:
7.2 Training Details
Baseline Training
- Warmup-cosine decaying learning rate schedule.
- Early stopping based on validation loss.
- Epochs: 15, stopped at epoch 10.

Figure: Baseline Training and Validation Loss by Epoch
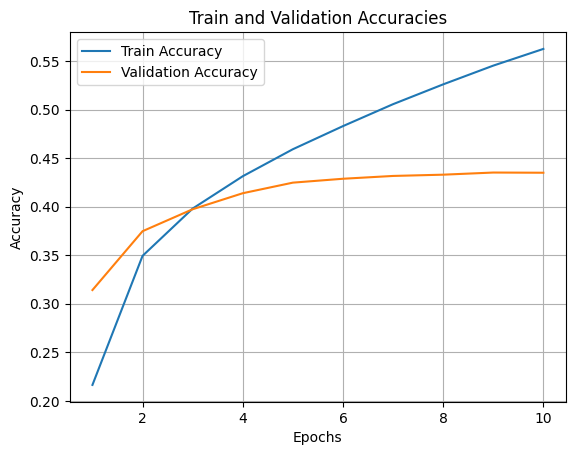
Figure: Baseline Training and Validation Accuracy by Epoch
SCST Optimization
- Train for 8 epochs.
- Initial learning rate:
. We then decay the learning rate by 0.5 for the remaining epochs. - Beam search (beam size: 3) for caption generation.
8. Results
8.1 Baseline Performance
We use a batched single-reference meteor score to evaluate our baseline and post-SCST captions on our test set.
| Metric | Score |
|---|---|
| Single METEOR | 0.276 |
8.2 Post-SCST Optimization
| Metric | Before SCST | After SCST |
|---|---|---|
| Single METEOR | 0.276 | 0.301 |
8.3 Final Evaluation Metrics (Beam Search)
We use beam search to decode our captions for final evaluation and generation, with a beam size of 3. A simple normalized function is used as the score function for beam search. It is defined as:
| METEOR | BLEU 1 | BLEU 2 | BLEU 3 | BLEU 4 |
|---|---|---|---|---|
| 0.4659 | 0.5528 | 0.4006 | 0.2714 | 0.1743 |
9. Discussion
9.1 Strengths
- Alignment with Human Evaluation: Optimizing METEOR ensures captions better reflect human judgment.
- Architecture Flexibility: CPTR allows seamless integration of transformer advancements.
9.2 Limitations
- Hardware Constraints: Limited by computational power and memory on machine, limiting the number of training epochs and decoder layers.
- Decoder Training: A pre-trained decoder with a deeper architecture could improve results and training time.
- Larger Dataset: Training on Flickr30k or MSCOCO would improve training size and generalization.
9.3 Future Work
- Train on larger datasets with high-performance hardware.
- Incorporate pre-trained decoders to boost performance.
- Gain access to stronger computational hardware to allow longer SCST training.
10. Conclusion
This study demonstrates the synergy between transformers and reinforcement learning in image captioning. By aligning model outputs with human evaluation metrics, the proposed pipeline achieves significant improvements in caption quality, providing a foundation for further research.
11. References
[1] Wei Liu, Sihan Chen, Longteng Guo, Xinxin Zhu, and Jing Liu. "CPTR: Full Transformer Network for Image Captioning." CoRR, vol. abs/2101.10804, 2021. Available: https://arxiv.org/abs/2101.10804.
[2] Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. "Self-critical Sequence Training for Image Captioning." CoRR, vol. abs/1612.00563, 2016. Available: http://arxiv.org/abs/1612.00563.