Accident Detection and Criticality Assessment System
Abstract
This project presents an innovative system that integrates advanced vision-language models with geolocation technology to provide a comprehensive emergency response and damage assessment solution. The system is designed to detect accidents in real time and evaluate the criticalness of the situation using cutting-edge computer vision and natural language processing. Upon detecting an emergency, it identifies the nearest hospital via GPS and sends alerts to emergency services while allowing user-initiated service requests. Additionally, the system estimates the cost of damage and connects users with repair service providers, offering a seamless and efficient post-accident experience. By combining real-time detection, critical evaluation, and end-to-end service facilitation, this solution aims to enhance emergency response efficiency and streamline accident recovery processes.
Introduction
Accidents pose significant challenges, including delayed response times, lack of critical situation assessments, and inefficient post-incident recovery processes. Current systems often focus on singular aspects of accident management, leaving gaps in holistic response mechanisms. This project addresses these gaps by developing an integrated system that combines accident detection, emergency response, and recovery facilitation.
The system leverages a vision-language model to accurately assess the criticalness of accidents, ensuring prompt and appropriate responses. GPS technology is utilized to locate the nearest hospital and facilitate rapid coordination with emergency services. Beyond immediate response, the system offers a damage cost estimation feature and seamlessly connects users with repair service providers, ensuring a complete solution from accident detection to recovery. This project not only enhances safety and response times but also introduces convenience and efficiency in post-accident processes, making it a valuable contribution to accident management systems.

Methodology
This project employs a multi-module approach integrating state-of-the-art technologies for accident detection, critical assessment, emergency alerting, and post-accident recovery facilitation. The methodology comprises the following key components:
1. Accident Detection using YOLOv11
- The system utilizes YOLOv11, a cutting-edge object detection model, to identify accidents in real time. YOLOv11's high accuracy and speed ensure rapid detection even in complex environments, enabling prompt activation of subsequent modules.
Dataset Link
Training Notebook
Setting Up the Model and Paths
- Model Loading: The YOLO model is loaded from the specified path, ready for real-time accident detection.
- Video Input and Output Paths: Paths for the input video (to process) and output video (with detections) are defined.
- Accident Frame Folder: A folder is created where all frames containing accidents will be saved separately.
import os from ultralytics import YOLO import cv2 import random # Load your YOLO model model = YOLO(r"F:/Projects/Accident_Detection/best(5).pt") # Path to your YOLO weights # Input and output video paths input_video_path = r"F:\Projects\Accident_Detection\Indian_Car_Accident_Narrow_Escapes(720p).mp4" # Your input video file output_video_path = "output_video_with_detections.mp4" # Output video file # Directory to save accident frames (detected parts only) accident_folder = r"F:/Projects/Accident_Detection/accident_frames" os.makedirs(accident_folder, exist_ok=True)
Detecting Accidents and Annotating Frames
- Class Colors: The script assigns a unique color to each class, specifically marking the "Accident" class with red. Other classes get random colors.
- Accident Detection: For each frame, YOLO detects objects. If an "Accident" is detected, that region is cropped and saved as a separate image in the accident_frames folder.
- Drawing Annotations: Bounding boxes and labels are drawn around the detected objects, with a clear distinction for accidents.
- Video Output: The annotated frames are written to an output video, and the frame is displayed in real-time for monitoring.
# Generate a random color for each class, with red for the "Accident" class class_colors = {} for cls, name in model.names.items(): if isinstance(name, str) and name.lower() == "accident": # Ensure name is a string class_colors[cls] = (0, 0, 255) # Red color (BGR format) else: class_colors[cls] = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)) # Open the input video cap = cv2.VideoCapture(input_video_path) fps = int(cap.get(cv2.CAP_PROP_FPS)) width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Codec for .mp4 out = cv2.VideoWriter(output_video_path, fourcc, fps, (width, height)) frame_count = 0 while cap.isOpened(): ret, frame = cap.read() if not ret: break frame_count += 1 # Perform YOLO detection results = model.predict(frame) # Updated method for inference save_accident_frame = False # Flag to check if "Accident" class is detected # Draw detections on the frame for result in results: # Iterate over the Result objects for box in result.boxes: # Iterate over detected boxes x1, y1, x2, y2 = map(int, box.xyxy[0]) # Get bounding box coordinates conf = box.conf[0] # Get confidence score cls = int(box.cls[0]) # Get class ID label = f"{model.names[cls]} {conf:.2f}" # Assign color based on class color = class_colors[cls] # Check if the class is "Accident" if model.names[cls].lower() == "accident": save_accident_frame = True # Crop the detected region (ROI) detected_part = frame[y1:y2, x1:x2] # Extract region of interest (ROI) # Save the cropped part as a separate image accident_part_path = os.path.join(accident_folder, f"accident_frame_{frame_count:04d}_roi.jpg") cv2.imwrite(accident_part_path, detected_part) # Draw bounding box and label cv2.rectangle(frame, (x1, y1), (x2, y2), color, 3) # Bounding box thickness font_scale = 0.7 font_thickness = 2 text_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, font_scale, font_thickness)[0] text_x, text_y = x1, y1 - 10 if y1 - 10 > 10 else y1 + 10 cv2.rectangle(frame, (text_x, text_y - text_size[1] - 5), (text_x + text_size[0], text_y + 5), color, -1) cv2.putText(frame, label, (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 255, 255), font_thickness) # Write the frame with detections to the output video out.write(frame) # Display the frame in a window cv2.imshow("Video with Detections", frame) # Check for the 'q' key to quit early if cv2.waitKey(1) & 0xFF == ord('q'): break
Finalizing and Releasing Resources
- Resource Management: After processing, the video capture and writer objects are released to free up system resources.
- Completion Message: A message is displayed indicating that the detection is complete and showing the locations where the output video and accident frames are saved.
# Release resources cap.release() out.release() cv2.destroyAllWindows() print(f"Detection complete. Output video saved at: {output_video_path}") print(f"Accident frames (detected parts) saved in folder: {accident_folder}")
Accident Frame Folder:
.png?Expires=1783122047&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=oyBg4oyCu2PWXa4geNRGEWwROT1lND41bwGTln~S4OeyrmgvtWT5X-TkHCb~fWkjQBm6JnX3AFh-MfJzgnC10cl7qO8TCFCdRv64fLf3K8NZs64Xd~i1gjsC1B09qmnrfDy5Ei-xq2tE9fXko4vnHjxBCllqFfnjEAbzkUkeiX~2pnCx1JKFjlXEnaWeMNlxBs05NudBJB6qEhgRvnCfwI3IzMcP5qf1SDd8baYb6M7v4agDq2~kG94ra0CAfkczUi8zi8~nalGVLxVhx06by4zJ9mShNGUZJygNbuf49Xy6PFsJf~RY-v79No1rHSi0q~TD8PeXOwHoEK-Spy~OZg__)
2. Critical Situation Assessment using Vision-Language Models
- To evaluate the severity of the detected accident, the system incorporates BLIP (Bootstrapped Language-Image Pretraining) components:
BlipProcessor: Processes input images and prepares them for interpretation.
BlipForConditionalGeneration: Generates descriptive insights about the accident scene, enabling a better understanding of the situation's criticalness. This module translates visual data into detailed, actionable textual descriptions that assist in determining the response priority.
Setup:
- Loads the pretrained BLIP model for image captioning.
- Creates folders for storing accident frames and generated descriptions.
import os from transformers import BlipProcessor, BlipForConditionalGeneration from PIL import Image # Load BLIP model and processor (pretrained model for image captioning) processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base") model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base") # Directory where accident frames (detected parts) are saved accident_folder = "F:/Projects/Accident_Detection/accident_frames" description_folder = "F:/Projects/Accident_Detection/description" os.makedirs(description_folder, exist_ok=True) # Create description folder if not exist
Image Analysis:
- The
analyze_accident_imagefunction processes each image, generating a description. - Assigns a criticality ("High" or "Normal") based on whether "accident" is mentioned.
Processing Loop:
- Loops through all images in the
accident_folder, generates a description, and saves it in a text file in thedescription_folder.
Output:
- Each image's description and criticality are saved in a
.txtfile.
# Function to analyze images with BLIP model and get a description def analyze_accident_image(image_path): # Open image raw_image = Image.open(image_path).convert("RGB") # Preprocess the image and pass through the model inputs = processor(raw_image, return_tensors="pt") out = model.generate(**inputs) # Decode the output to get the description description = processor.decode(out[0], skip_special_tokens=True) # Here you can add additional logic for criticality detection if "accident" in description.lower(): criticality = "High" # Assuming the model detects something related to accidents else: criticality = "Normal" return description, criticality # Loop through all saved accident frames and analyze them for img_file in os.listdir(accident_folder): img_path = os.path.join(accident_folder, img_file) if img_file.endswith('.jpg'): print(f"Analyzing {img_file}...") description, criticality = analyze_accident_image(img_path) # Create a text file with the description and criticality level text_filename = os.path.join(description_folder, f"{img_file.replace('.jpg', '.txt')}") with open(text_filename, 'w') as file: file.write(f"Description: {description}\n") file.write(f"Criticality: {criticality}\n") # Displaying output for the user print(f"Text file saved: {text_filename}") print('-' * 50)
Example Image
.png?Expires=1783122047&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=xX~46IGZ~a9JKBHCvO-2w6NbhgPVNW1anVfPu5i7b8~RcvD6cZK31Z0Is7A-Mzg0VgpO03m3DgM-4eFQ8emZPDhQVUCMGsb-o1oLaHlgBtak-HvR5MLvNYrHm9IrauYt~joeNSmIOqKI4vyhSpk1fC1UVn4kJiKJ7aYyZ6WQuuTnVAzVdCk-EWidFlKlUWzt7So-0kEjR85K-PT2v1ZniLwSLv5ajcGD0Kl1KLDA9kCKJHCPiDiaZ1aVu~MclmHgNOFWSvPFloURY2sr5hvdjrYMFo90cgQxDM2SH~TPXiH1nKLuRhZfO9acDjEjX8p6a6D7gqIjogCDw8L5flMtcA__)
3. Emergency Response and Alert System
- The system employs GPS to locate the nearest hospital and establish an emergency alert mechanism. It allows users to manually request emergency services or automate alerts based on the criticalness assessment, ensuring rapid response.
4. Damage Cost Estimation using U-Net
- A U-Net model is deployed for damage cost estimation by segmenting and analyzing the affected areas in accident images. This deep learning-based approach provides precise damage identification, enabling accurate cost predictions.
5. Repair Service Provider Integration
- The system connects users to repair service providers based on the damage assessment. By integrating service provider data, it offers a tailored recommendation for repair services, promoting recovery efficiency.
Demo Video
After detecting an accident in the video, all relevant accident frames are stored in a separate folder for further analysis. Alongside this, a description of each frame, assessing the criticalness of the situation, is saved in another folder. This ensures organized storage and aids in evaluating the severity of the incident effectively.
Results
Our model has achieved the following performance metrics:
Precision: 0.93
- Measures the accuracy of detected accident frames. It shows the proportion of correctly identified accident frames out of all frames flagged as accidents by the model.
- The model demonstrates a Precision of 93%, indicating that 93% of the predicted instances are correct. However, a 7% false positive rate suggests further optimization is needed to enhance reliability.
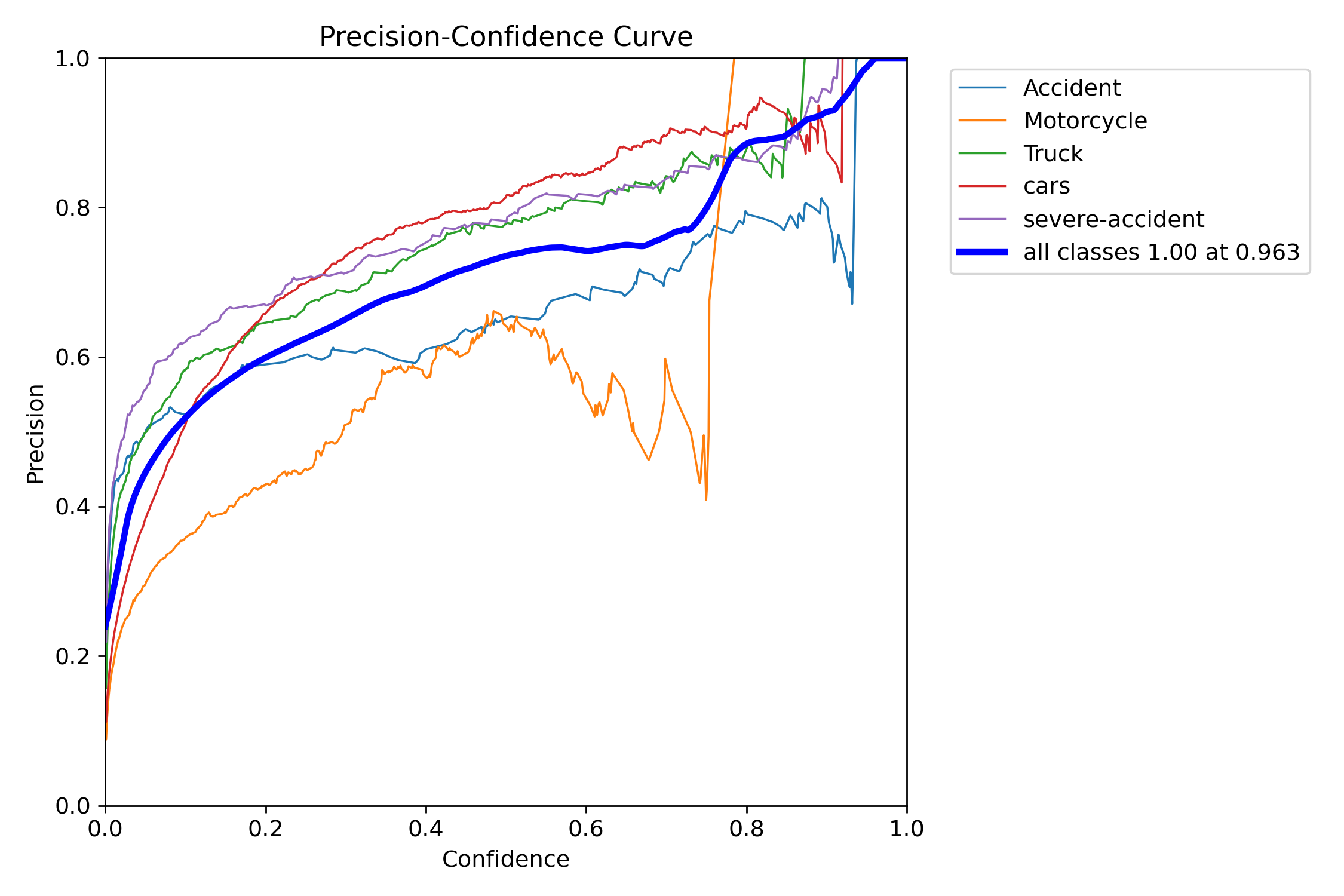
Recall: 0.91
- Measures the model's ability to find all actual accident frames in the video. A higher recall means fewer accidents are missed.
- The model successfully identifies 91% of the relevant instances, ensuring that the majority of the critical elements are detected. This high Recall is crucial for minimizing missed detections.
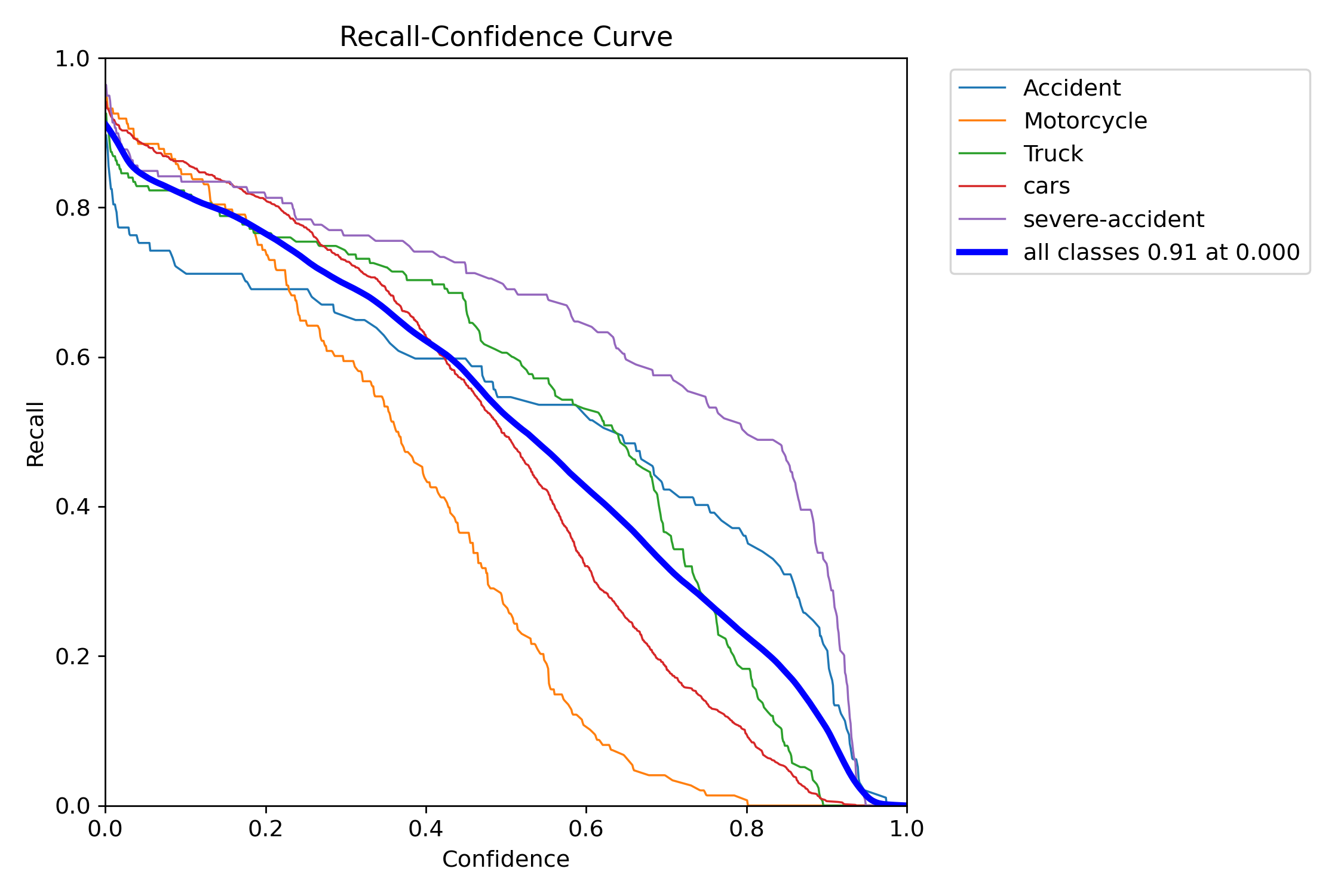
F1 Score: 0.80
- Combines precision and recall into a single metric to provide a balanced measure, especially useful when there's an uneven class distribution between accident and non-accident frames.
- The F1 Score reflects a balanced performance, highlighting the trade-off between Precision and Recall. While the overall performance is strong, there is scope for improvement to achieve an even better balance.
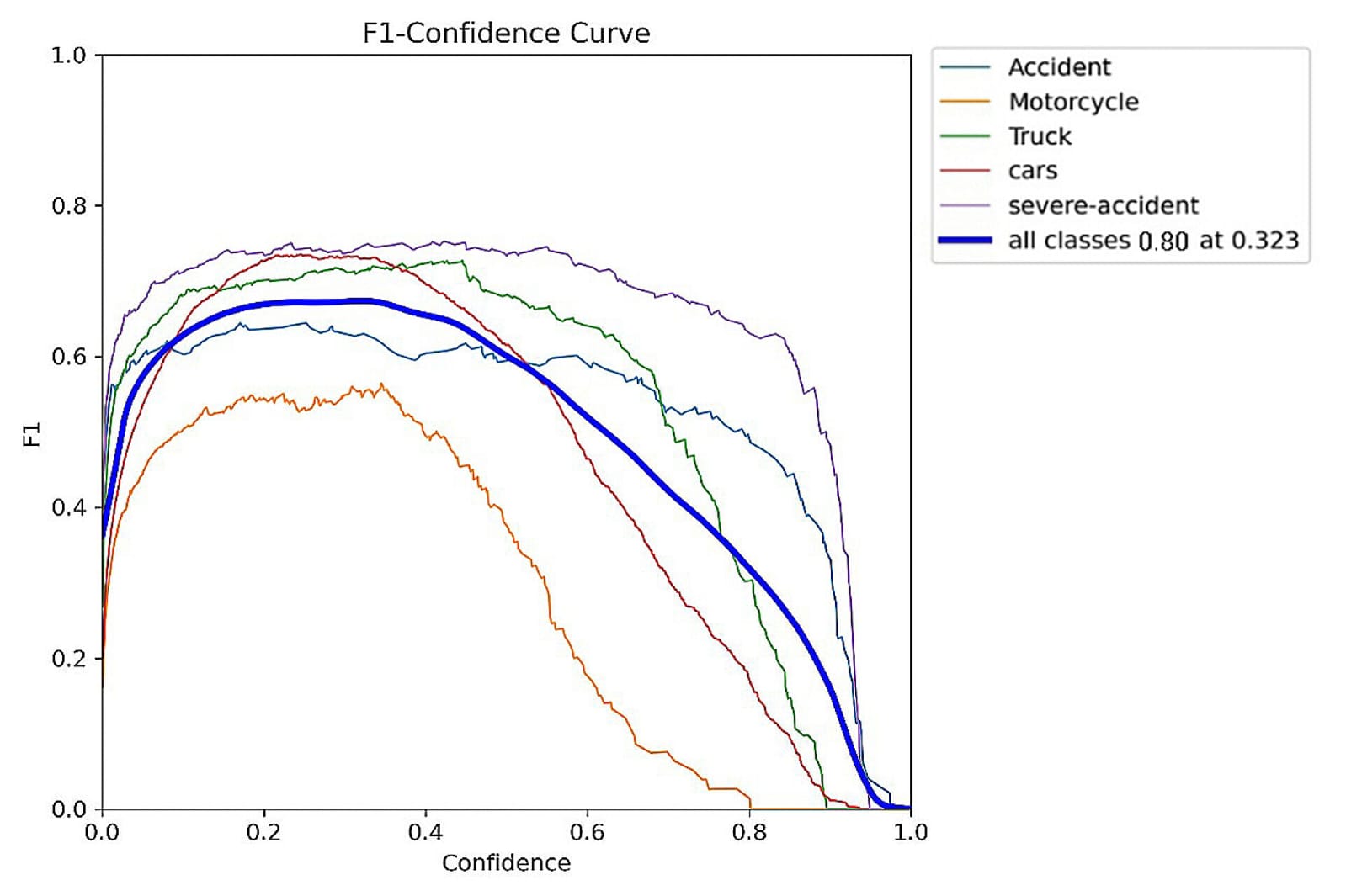
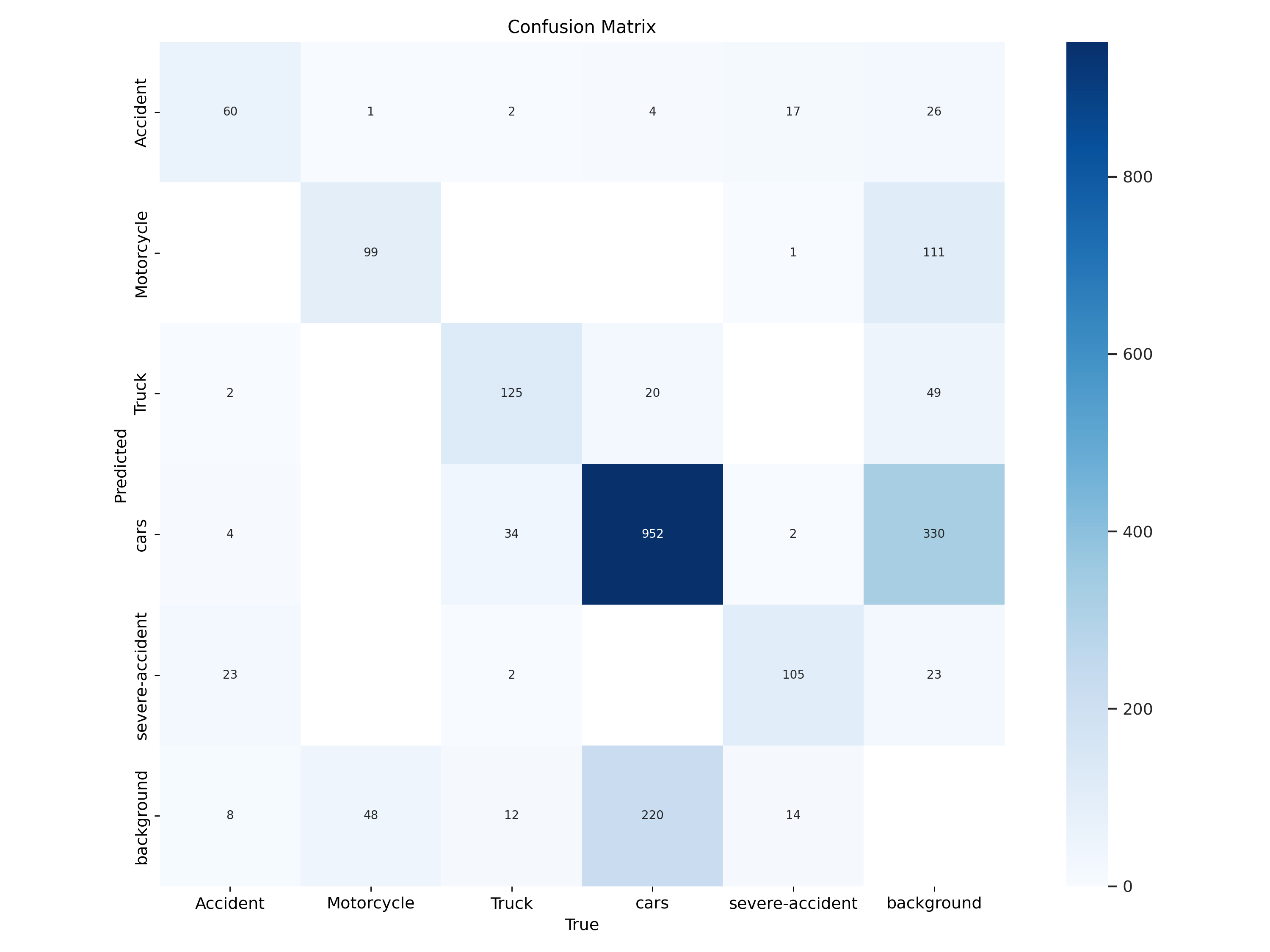
Confusion Matrix
The confusion matrix provides a detailed breakdown of the model's performance:
- True Positives (TP): Accident frames correctly identified as accidents.
- False Positives (FP): Non-accident frames incorrectly flagged as accidents.
- True Negatives (TN): Non-accident frames correctly identified as non-accidents.
- False Negatives (FN): Accident frames missed by the model.
Conclusion
In this project, we developed a comprehensive accident detection and response system that integrates cutting-edge technologies to enhance safety and streamline emergency responses. The system's architecture combines accident detection, a vision-language model for criticalness assessment, GPS-based hospital localization, and an emergency alert mechanism. This innovative approach not only ensures rapid response to accidents but also allows users to request emergency services efficiently.
Additionally, the system offers valuable post-accident support by providing cost estimates for damages and connecting users with repair service providers tailored to their needs. This feature not only simplifies the recovery process for users but also fosters partnerships with service providers, creating a mutually beneficial ecosystem.
