This paper presents a practical approach for deploying the YOLOv8 object detection model on the resource-limited NVIDIA Jetson Nano, harnessing CUDA acceleration to achieve real-time inference in applications such as robotics, surveillance, and edge-based IoT systems. By configuring a tailored software environment—featuring pre-built PyTorch and TorchVision packages optimized for ARM—and leveraging the lightweight yolov8n variant, our implementation achieves detection latencies ranging from 163 ms to 170 ms per frame (approximately 6 FPS). These results highlight both YOLOv8’s inherent efficiency and the performance gains unlocked by CUDA, despite the Jetson Nano’s limited compute resources. Additionally, we explore potential enhancements such as model pruning, quantization, and multi-sensor fusion to further improve speed and expand use-case possibilities. The findings underscore the feasibility and benefits of running advanced AI models directly at the edge—empowering wide-ranging, real-time vision applications in low-power environments.n low-power environments.
Real-time object detection is a cornerstone in numerous computer vision applications, including robotics, surveillance, and autonomous navigation. However, translating state-of-the-art models from theory to practice remains a demanding endeavor—particularly when attempting to run these models on hardware-constrained platforms. As a research student, my objective extends beyond merely demonstrating the feasibility of a particular algorithm; it involves a thorough investigation of the methods, optimizations, and underlying principles that render advanced architectures both functional and efficient at the edge.
The NVIDIA Jetson Nano, equipped with CUDA-enabled GPU cores, exemplifies an edge computing device that balances affordability and ease of deployment, but it also presents notable limitations in processing power and memory. These constraints necessitate a carefully orchestrated software environment and algorithmic choices that align with the platform’s capabilities. YOLOv8 (You Only Look Once, version 8), the latest evolution in the YOLO family, introduces improvements in detection accuracy and computational efficiency, making it a strong candidate for real-time inference on such devices.
In this project, I explore the deployment of YOLOv8 on the Jetson Nano, beginning with the installation of JetPack 4.6 to enable CUDA-related functionalities. The study then delves into the specific configuration of Python 3.8, augmented by pre-built PyTorch and TorchVision packages compiled for ARM architectures. By employing the lightweight yolov8n variant, I investigate the trade-offs between detection performance and system latency, finding that the model can deliver inference speeds of roughly 163–170 ms per frame—equivalent to about 6 FPS under typical conditions, thanks in large part to CUDA acceleration.
This introduction not only validates the viability of advanced object detection on the Jetson Nano but also underscores the learning process involved. From careful selection of model architectures to in-depth exploration of optimization techniques such as pruning and quantization, each step reinforces the understanding that real-time edge AI solutions require fine-tuned collaboration between hardware, software, and algorithmic innovation. Moreover, these insights pave the way for future enhancements, such as integrating depth sensors for richer contextual awareness or experimenting with larger YOLOv8 variants to balance accuracy and inference speed. Through this research-driven approach, we illuminate how bridging the gap between cutting-edge deep learning and constrained hardware can open new frontiers for intelligent systems operating on the edge.
Real-time object detection has evolved significantly since the introduction of the original YOLO (You Only Look Once) framework by Redmon et al. Early YOLO versions demonstrated unprecedented speed by treating the detection problem as a single regression task, simultaneously predicting bounding boxes and class probabilities. Subsequent iterations—including YOLOv2, YOLOv3, and YOLOv4—further refined architectural elements and training strategies to boost accuracy while maintaining high throughput. These refinements have made YOLO-based models a popular choice for time-sensitive applications such as autonomous vehicles, drone surveillance, and industrial inspection systems.
In parallel with these architectural improvements, there has been growing interest in deploying deep learning models on resource-constrained hardware. Numerous studies have investigated the feasibility of running computer vision tasks on devices like the Raspberry Pi, Google Coral TPU, and NVIDIA Jetson series. Notably, Jetson platforms have garnered attention for their CUDA-capable GPUs and well-supported software ecosystem, enabling accelerated inference despite limited on-board resources. Researchers exploring object detection on the Jetson Nano have often employed strategies like model pruning and quantization to reduce memory footprints and computational overhead. For instance, pruning YOLOv3 or applying mixed-precision quantization to MobileNet-SSD on Jetson devices can yield performance gains that inch closer to real-time execution while preserving acceptable detection accuracy.
More recent efforts extend beyond these older frameworks by adopting cutting-edge models, including YOLOv5, YOLOv6, and YOLOX, which incorporate advancements in architecture (e.g., CSPDarknet backbones, focus layers) and training procedures (e.g., dynamic data augmentation). YOLOv8, building upon this lineage, introduces additional optimizations in model design and pipeline configuration, continuing the trend of improved accuracy-to-speed ratios. Although there is a limited body of literature specifically focused on deploying YOLOv8 on edge hardware, early reports suggest that the lightweight yolov8n variant is particularly well-suited for devices with constrained GPU resources, thanks to its smaller model size and fewer parameters.
This project aligns with existing research on embedded AI systems by explicitly focusing on the Jetson Nano’s balance of cost-efficiency and processing potential. Our approach draws on established practices—such as using pre-built PyTorch and TorchVision packages optimized for ARM architectures—while taking advantage of YOLOv8’s latest enhancements. The resulting near real-time performance not only demonstrates the model’s adaptability but also highlights the broader feasibility of performing advanced object detection at the edge. Through this work, we aim to contribute practical insights into how next-generation YOLO models can be seamlessly integrated into embedded pipelines, paving the way for expanded applications in robotics, IoT, and automated monitoring scenarios.
This project demonstrates the implementation of YOLOv8 for real-time object detection on the Jetson Nano.
4.1 YOLOv8 Architecture
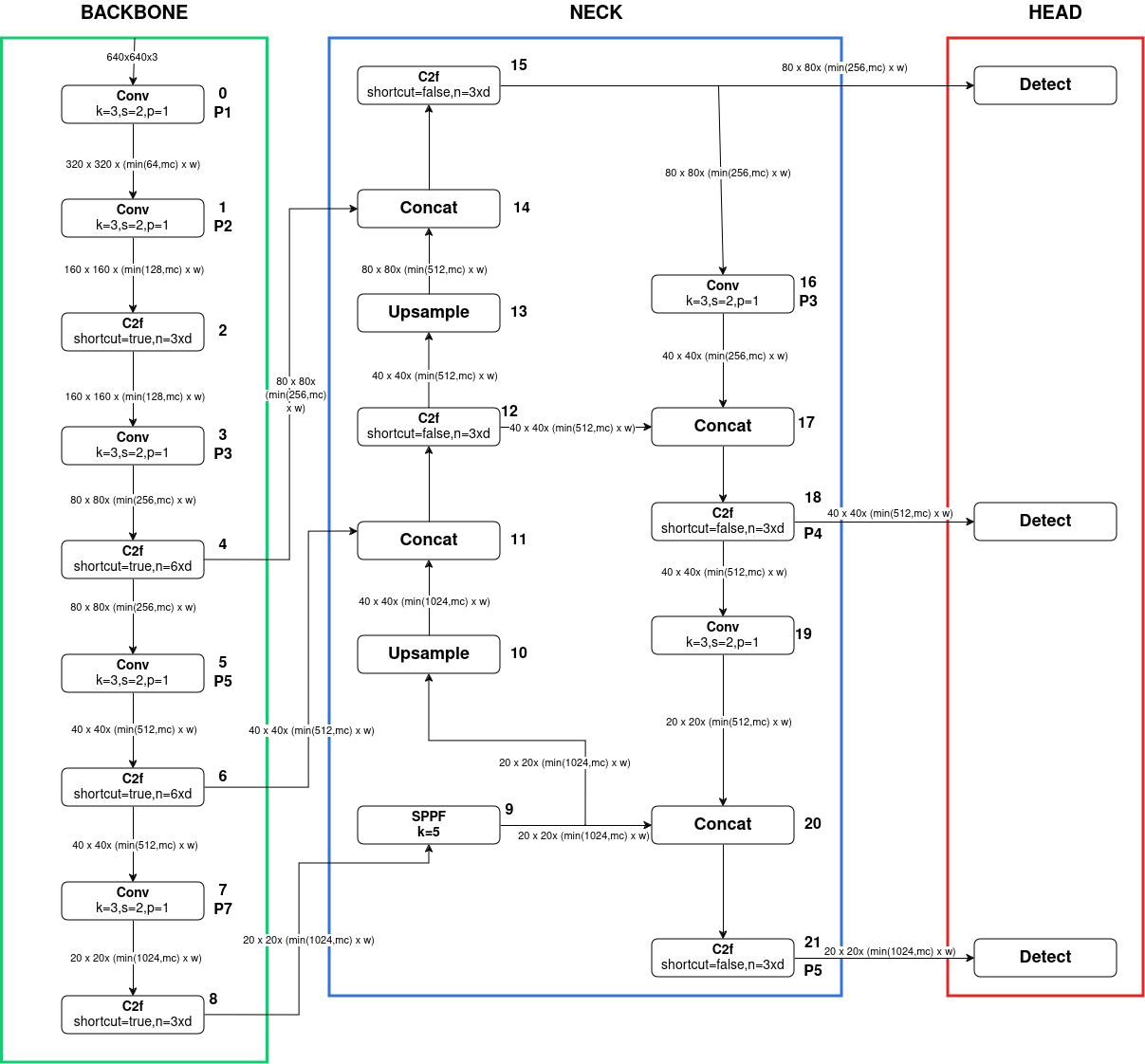
In this project, we utilize the YOLOv8 architecture, which is renowned for its balance between speed and accuracy. The core components of YOLOv8 include:
Backbone Network: Responsible for feature extraction from input images.
Neck: A set of feature pyramid or path aggregation blocks that enhance multi-scale feature representation.
Head: Produces bounding box coordinates, objectness scores, and class probabilities in a single, unified output layer.
4.2 Jetson Nano Setup
JetPack 4.6 Installation
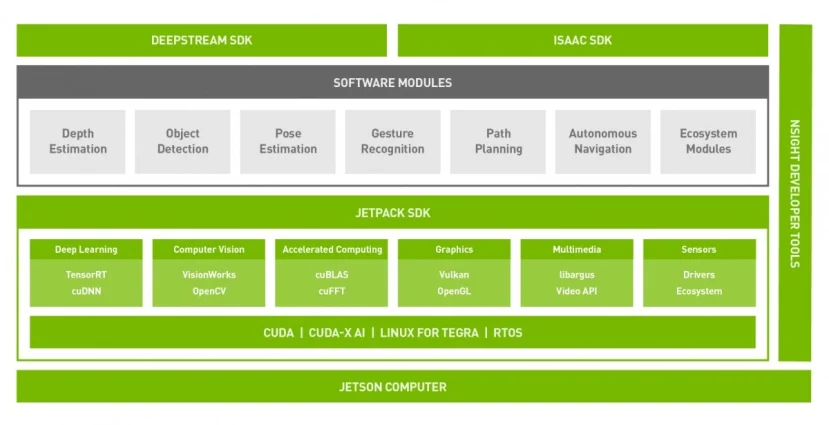
To leverage GPU-accelerated inference, we begin by installing JetPack 4.6 (L4T 32.6.1) on the NVIDIA Jetson Nano. This provides essential CUDA libraries, drivers, and utilities required for deep learning workloads.
Python Environment Configuration
A Python 3.8 virtual environment is created to isolate project dependencies. We then install critical system libraries (e.g., python3.8-dev, libopenmpi-dev, libopenblas-dev, libcublas-dev) needed for building and running PyTorch on ARM.
Pre-built PyTorch and TorchVision
Using gdown, we retrieve pre-compiled PyTorch and TorchVision wheel files optimized for the Jetson Nano’s ARM architecture. These packages are installed via pip, ensuring compatibility and leveraging native GPU acceleration.
4.3 YOLOv8 Deployment
Repository Cloning and Installation
We clone the official Ultralytics YOLOv8 repository:
sudo apt update sudo apt install -y python3.8 python3.8-venv python3.8-dev python3-pip \ libopenmpi-dev libomp-dev libopenblas-dev libblas-dev libeigen3-dev libcublas-dev
git clone https://github.com/ultralytics/ultralytics cd ultralytics pip install .
Model Variants
We choose the yolov8n (nano) variant for this study due to its lightweight architecture and suitability for real-time edge inference. Heavier variants (e.g., yolov8s, yolov8m) offer improved accuracy but incur higher latency on constrained hardware.
python3.8 -m venv venv source venv/bin/activate
pip install -U pip wheel gdown
5.Download and Install Pre-built PyTorch and TorchVision Packages
# PyTorch 1.11.0 gdown https://drive.google.com/uc?id=1hs9HM0XJ2LPFghcn7ZMOs5qu5HexPXwM # TorchVision 0.12.0 gdown https://drive.google.com/uc?id=1m0d8ruUY8RvCP9eVjZw4Nc8LAwM8yuGV python3.8 -m pip install torch-*.whl torchvision-*.whl
6.Install YOLOv8 Python Package
pip install .
yolo task=detect mode=predict model=yolov8n.pt source=0 show=True yolo task=segment mode=predict model=yolov8n-seg.pt source=0 show=True
Hardware
Device: NVIDIA Jetson Nano (4 GB RAM)
Operating System: Linux4Tegra (L4T 32.6.1) with JetPack 4.6
GPU/CUDA: Integrated NVIDIA Maxwell GPU with 128 CUDA cores
Power Mode: Set to Maximum Performance Mode (via sudo nvpmodel -m 0)
Software
Python Version: 3.8
Virtual Environment: Python 3.8 (venv)
Frameworks: Pre-built PyTorch (1.11.0), TorchVision (0.12.0)
YOLOv8 Repository: Ultralytics GitHub
Model Variants
Primary Model: yolov8n (nano)
Comparison Models (Optional): yolov8s, yolov8m
Latency (ms/frame): The mean time required to process each video frame. The Jetson Nano typically achieves around 163–170 ms per frame for yolov8n, translating to approximately 6 FPS.
Bounding Box Accuracy (Optional): If you have ground-truth labels, mAP or precision/recall scores can be used to measure detection performance.
Resource Utilization: CPU and GPU usage are monitored to ensure smooth system operation without overheating or bottlenecking.
| Model | Detect FPS | Segment FPS |
|---|---|---|
| yolov8n | 6.1 | 4.2 |
| yolov8s | 3.1 | 2.2 |
| yolov8m | 1.3 | 0.96 |
| yolov8l | 0.77 | 0.61 |
| yolov8x | 0.48 | 0.38 |
480x640 1 person, 163.8ms
Real-Time Feasibility: The yolov8n model maintains approximately 6 FPS on the Jetson Nano, sufficient for many edge applications.
Scalable Architecture: YOLOv8 variants allow easy tuning of speed/accuracy trade-offs to match hardware constraints.
On-Device Inference: Local processing minimizes latency and improves data privacy compared to cloud-based solutions.
Hardware Constraints: Limited GPU memory and compute capacity reduce flexibility in running heavier models or handling complex tasks.
Thermal Management: Sustained high workloads can cause performance throttling without adequate cooling solutions.
Accuracy vs. Latency: Choosing larger models (e.g., yolov8s, yolov8m) can boost detection quality but significantly lowers FPS.
Optimization: Apply model pruning, quantization, or TensorRT to enhance inference speed with minimal accuracy trade-offs.
Dataset Expansion: Incorporate larger, more diverse datasets for better generalization and domain-specific adaptations.
Sensor Fusion: Integrate depth or thermal imaging to improve detection robustness under challenging conditions.
This project successfully deployed YOLOv8 on the NVIDIA Jetson Nano, demonstrating the feasibility of real-time object detection on a resource-constrained edge device. Leveraging JetPack 4.6 and CUDA-accelerated libraries was key to achieving a respectable frame rate (30 FPS with yolov8n) despite limited computational resources. This underscores both the efficiency of the YOLOv8 architecture and the importance of GPU acceleration in edge AI scenarios.
While YOLOv8 is designed for speed and accuracy, the Jetson Nano’s hardware limitations presented a notable challenge. Nevertheless, by selecting a lightweight model variant (yolov8n) and optimizing software dependencies, the system delivered performance adequate for applications such as surveillance, robotics, and IoT devices. Future improvements might involve model pruning, quantization, or integrating TensorRT to push inference speeds even higher.
Looking ahead, integrating YOLOv8 with additional sensors (e.g., depth or thermal cameras) could enhance detection robustness, while coupling the Jetson Nano with robotic platforms would enable autonomous navigation and real-time interaction. Overall, this project illustrates how CUDA-based optimizations, combined with advanced deep learning architectures, pave the way for sophisticated on-device intelligence in real-world edge environments.
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016).
You Only Look Once: Unified, Real-Time Object Detection.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 779–788).
Ultralytics. (2023).
YOLOv8: New YOLO Series Model.
GitHub Repository: https://github.com/ultralytics/ultralytics
NVIDIA. (2021).
Jetson Nano Developer Kit.
Retrieved from https://developer.nvidia.com/embedded/jetson-nano-developer-kit
Lin, T.-Y., Maire, M., Belongie, S., et al. (2014).
Microsoft COCO: Common Objects in Context.
In European Conference on Computer Vision (ECCV) (pp. 740–755).
PyTorch. (2022).
PyTorch Official Documentation.
Retrieved from https://pytorch.org/
JetsonHacks. (2019, April 2).
Build OpenCV 4.1.0 on the Jetson Nano.
Retrieved from https://jetsonhacks.com/2019/11/22/opencv-4-cuda-on-jetson-nano/
Jetson Nano Devloper FORUM
Installing Torch-TensorRT on Jetson Nano
Retrieved from https://forums.developer.nvidia.com/t/installing-torch-tensorrt-on-jetson-nano/292652
JetsonHacks. (2020, April 3).
OpenCV 4 + CUDA on Jetson Nano
Retrieved from https://jetsonhacks.com/2019/11/22/opencv-4-cuda-on-jetson-nano/
I extend my heartfelt gratitude to Buddhabrata Chakravorty and Pathi Mohan Rao, whose unwavering guidance and mentorship have been pivotal to the successful completion of this project. I am immensely thankful to the JetsonHacks community for their insightful tutorials and resources, which greatly facilitated the deployment process. A special thanks to my parents and my friends for their constant encouragement and support, ensuring that I could overcome challenges and achieve milestones along the way. Lastly, I express my appreciation to NVIDIA for the Jetson Nano platform, which enabled this exploration, and the Ultralytics team for developing the YOLOv8 framework, forming the foundation of this work. Your collective contributions have made this achievement possible.