ABSTRACT
The increasing prevalence of video content necessitates efficient methods for information retrieval. This paper introduces a novel system that combines automated transcription with a generative question answering (QA) approach, leveraging the power of a foundation model to enable interactive access to richer video information. Existing VideoQA systems often rely on extractive methods or smaller language models, limiting their ability to synthesize information and generate comprehensive answers. Our system addresses this limitation by utilizing the OpenAI Whisper API for accurate and efficient audio transcription, generating a textual representation of the video's content. This transcript is then indexed and used as the basis for a Langchain-based QA model that incorporates a foundation model (gpt-4o mini). Unlike extractive approaches, our system can perform abstractive summarization, contextual understanding, and generate more natural and fluent responses directly from the transcribed text. Users can upload video files through a Streamlit interface, pose natural language questions, and receive answers that are not simply extracted spans but rather synthesized responses tailored to the question's context. This system offers a significant improvement over manual video review and previous VideoQA systems, providing a scalable and user-friendly solution for extracting knowledge from video data through more informative and human-like interactions.
- Introduction
The explosive growth of video content on platforms like YouTube, TikTok, and educational repositories has created an urgent need for efficient methods to access and retrieve specific information within these dynamic media. Traditional approaches, such as manual skimming or reliance on user-provided metadata, are often inadequate for handling the sheer volume and complexity of modern video data (Smeaton, 2010). This has driven significant research into automated techniques for video understanding, with a particular focus on enabling natural language interaction through video question answering (VideoQA).
VideoQA aims to answer natural language questions based on video content, requiring models to integrate information from multiple modalities, including visual, audio, and textual cues (Zhong et al., 2022). Early VideoQA systems primarily focused on analyzing visual information, employing techniques like object detection, scene recognition, and activity recognition (Rohrbach et al., 2016). However, the rich information conveyed through audio, including speech, music, and sound effects, plays a crucial role in understanding video content. Therefore, recent research has increasingly emphasized the integration of audio information into VideoQA models.
Automated speech recognition (ASR) has become a cornerstone for incorporating audio information into VideoQA systems. Recent advancements in deep learning, particularly with transformer-based models like Whisper (Radford et al., 2023), have significantly improved the accuracy and robustness of ASR, even in challenging acoustic environments. These advancements have enabled the development of systems that can accurately transcribe spoken content from videos, providing a textual representation that can be further processed by natural language processing (NLP) techniques.
Building on the progress in ASR, retrieval-based QA approaches have demonstrated effectiveness in handling large text corpora and providing concise answers to natural language questions (Chen et al., 2017). These methods typically involve encoding questions and context into vector embeddings and performing similarity search to retrieve relevant information. Recent work has explored the use of large language models (LLMs) not only for answer generation but also for context retrieval and question understanding in VideoQA (Gao et al., 2023).
This paper introduces a novel VideoQA system that addresses this limitation by leveraging the generative power of a foundation model, specifically for content generation from transcribed video text. Unlike previous systems that primarily rely on extractive methods, our approach enables abstractive summarization, contextual understanding, and the generation of more natural and fluent responses. By utilizing Whisper for transcription and Langchain for QA orchestration, our system processes user questions and generates informative answers by synthesizing relevant information from the video transcript.
- System Architecture
Our VideoQA system employs a modular architecture comprising three main stages: (1) Video Upload and Transcription, (2) Question Processing, and (3) Generative Question Answering. Figure 1 provides a visual representation of the system architecture.
2.1 Video Upload and Transcription
The first stage involves processing the user-uploaded video. The system currently supports common video formats (MP3 &MP4). Upon upload, the audio track is extracted from the video file. This audio is then passed to the OpenAI Whisper API (Radford et al., 2023), a state-of-the-art ASR model based on the transformer architecture. The Whisper API transcribes the audio into text, producing a highly accurate textual representation of the spoken content. The resulting transcript is stored and made available for subsequent QA processing. This stage ensures that the system can effectively handle various audio conditions and produce reliable transcriptions.
2.2 Question Processing
In this stage, the user provides a natural language question through the Streamlit interface. The question is then encoded into a vector representation. While various embedding models could be used, the current implementation utilizes OpenAI embeddings. These embeddings capture the semantic meaning of the question, enabling effective comparison with the transcribed text.
2.3 Generative Question Answering
The core of the system lies in the generative QA stage. This stage is responsible for retrieving relevant context from the transcript and generating a comprehensive answer to the user's question. This process involves the following steps:
• Transcript Retrieval: The encoded question is compared to the encoded transcript using a similarity metric (e.g., cosine similarity). This step retrieves the most relevant segments of the transcript that are semantically closest to the user's question. We use a vector database DocArrayInMemorySearch for efficient retrieval.
• Contextualization with LLM: The retrieved transcript segments, along with the user's original question, are provided as context to a foundation model (GPT-4o mini). This contextualization step is crucial for the LLM to understand the specific context of the question within the video content.
• Generative Answer Generation: The foundation model then generates a natural language answer based on the provided context. Unlike extractive QA, the model can synthesize information from multiple parts of the transcript, generate summaries, and provide more contextually relevant and fluent responses. This generative capability is the key differentiator of our system.
3.0 Key Features
3.1 Video Upload Capability
Users can seamlessly upload video files, allowing for flexibility in content selection, whether it’s educational lectures, business presentations, or personal recordings. This feature is designed to cater to a wide range of users, from students to professionals, providing an inclusive platform for knowledge sharing.
3.2 Automatic Transcription
The system utilizes advanced speech recognition technologies, such as OpenAI's Whisper API, to automatically transcribe spoken content into text, ensuring high accuracy and efficiency. This feature significantly enhances accessibility and makes video content searchable, allowing users to quickly find the information they need without sifting through entire videos.
3.3 Interactive Text Display
Once the video is transcribed, users can view the text in an interactive area, which facilitates easy navigation through the content. Users can highlight specific sections, making it easier to refer back to relevant parts during Q&A sessions. This interactivity not only aids comprehension but also allows for a more engaging user experience.
3.4 Natural Language Questioning
Users can pose questions in natural language about the transcribed content, enabling a more user-friendly interaction with the system. This capability transforms the way individuals engage with video content, moving from passive consumption to active inquiry, and promotes a deeper understanding of the subject matter.
3.5 Retrieval-Based Answer Generation
The system employs a sophisticated retrieval-based QA model that processes the user's questions against the transcribed text to generate accurate and contextually relevant answers. This functionality not only saves time but also enhances the learning experience, empowering users to gain insights swiftly.
Technologies Used
• Streamlit
Streamlit serves as the foundation for building the interactive web application, allowing for quick deployment and a user-friendly interface. It simplifies the creation of data applications, making it an ideal choice for this system, which requires real-time interaction and responsiveness.
• LangChain
LangChain facilitates the development of modular natural language processing (NLP) pipelines, enabling the integration of various components, such as question processing and answer retrieval. This modular approach ensures that the system remains scalable and adaptable to future enhancements.
• OpenAI Whisper API
This powerful API provides the automatic transcription capabilities essential for converting spoken language into written text accurately. By leveraging this advanced technology, the system ensures high-quality transcriptions that form the backbone of the QA process.
Market Implications
Growing Demand for Video Content Accessibility
With the increasing consumption of video content across educational and professional sectors, there is a rising demand for tools that enhance accessibility. This retrieval-based QA system addresses this need by providing an avenue for users to engage with video content actively. As video becomes a dominant medium for learning and communication, systems like this will be essential.
Integration in Education and Corporate Training
The application of this technology is particularly relevant in educational settings, where students can interactively engage with lecture videos. In corporate training environments, employees can quickly retrieve information from training sessions, improving knowledge retention and application. This dual applicability underscores the system's versatility and potential for broad adoption.
Potential for Enhanced User Engagement
By allowing users to pose questions and receive immediate answers, the system not only improves engagement but also fosters a deeper understanding of the material. This interactivity could lead to more informed discussions and collaborative learning environments, which are critical in today’s fast-paced information landscape.

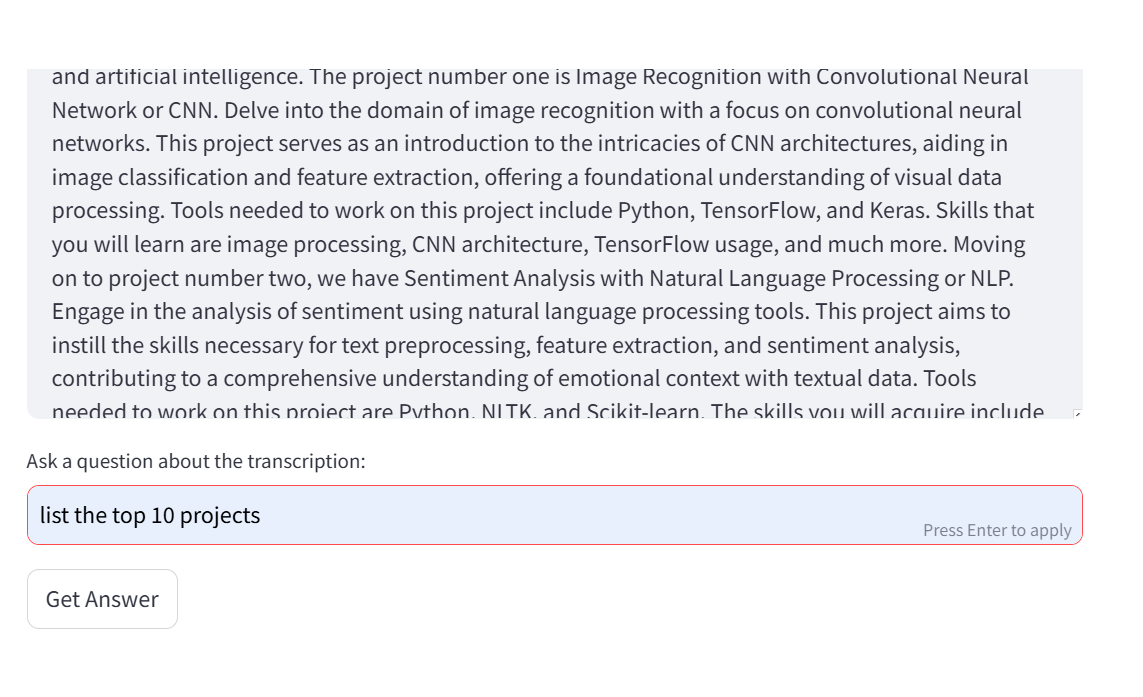
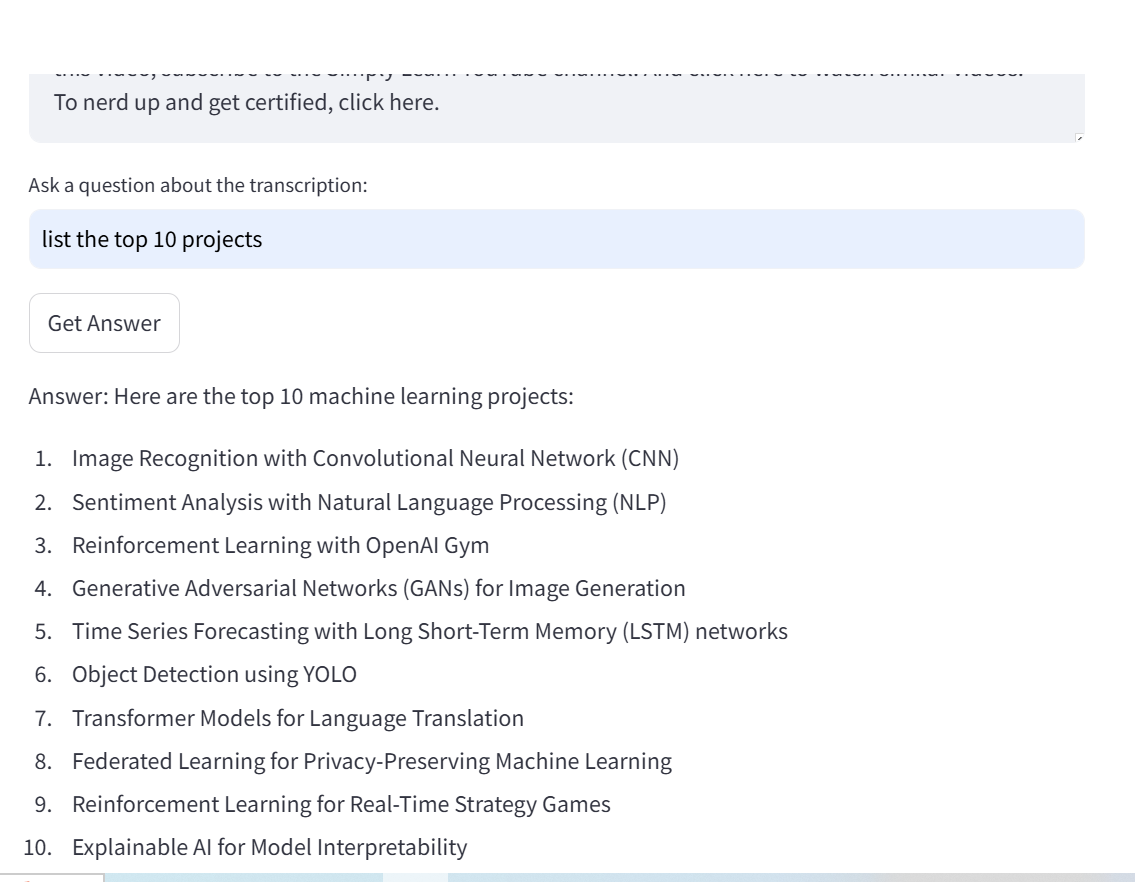
How to Use
- Clone the Repository:
git clone https://github.com/Alao001/Video-to-Text-Q-A-Bot.git - Install Dependencies:
pip install -r requirements.txt
4.0 Conclusion
The Retrieval-Based Question Answering System for transcribed videos represents a significant advancement in how we interact with video content. By leveraging cutting-edge technologies like OpenAI's Whisper and combining them with user-centric features, this system not only enhances accessibility but also transforms passive video viewing into an interactive learning experience. As demand for such solutions continues to grow, the potential for widespread application across various sectors is immense.
References:
• Chen, D., Fisch, A., Weston, J., & Bordes, A. (2017). Reading Wikipedia to Answer Open-Domain Questions. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1870–1880.
• Gao, T., Xiong, W., & Socher, R. (2023). Retrieval-Augmented Language Models for Few-Shot Learning: A Survey. arXiv preprint arXiv
• Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A. r., Jaitly, N., … Kingsbury, B. (2012). Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal Processing Magazine, 29(6), 82–97.
• Jurafsky, D., & Martin, J. H. (2023). Speech and Language Processing (3rd ed. draft).
• Radford, A., Kim, J. W., Xu, T., Gregori, G., Mustafa, K., Ramesh, S., ... & Sutskever, I. (2023). Robust Speech Recognition via Large-Scale Weak Supervision. arXiv preprint arXiv.04356.
• Rohrbach, M., Rohrbach, A., & Schiele, B. (2016). Video question answering. International Journal of Computer Vision, 117, 1-27.
• Smeaton, A. F. (2010). Personalisation in Video Information Retrieval. Personalization in Multimedia, 247–268.
• Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is All You Need. Advances in Neural Information Processing Systems, 30.
• Zhong, Y., Ji, W., Xiao, J., Li, Y., Deng, W., & Chua, T.-S. (2022). Video Question Answering: Datasets, Algorithms and Challenges. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 6439–6455.
• Reference to a survey paper: The inclusion of Zhong et al. (2022) provides a good overview of the VideoQA field.