Abstract
Automated segmentation of biomedical image has been recognized as an important step in computer-aided diagnosis systems for the detection of abnormalities. Despite its importance, the segmentation process remains an open challenge due to color, texture, shape diversity and boundary variations. Semantic segmentation often requires deeper neural networks to achieve higher accuracy, making the segmentation model more complex and slower. Due to the need to process many biomedical images, more efficient and cheaper image processing techniques for accurate segmentation are needed. In this article, we present a modified deep semantic segmentation model that utilizes the backbone of EfficientNet-B3 along with UNet for reliable segmentation. We trained our model on non-melanoma skin cancer segmentation for the histopathology dataset to divide the image into 12 different classes for segmentation. Our method outperforms the existing literature with an increase in average class accuracy from 79 to 83%. Our approach also shows an increase in overall accuracy from 85 to 94%.
Introduction
Image segmentation is partitioning of an image into different clusters on basis of distinctive features. It is done to better explain the global context of an image1. Segmentation separates all of the objects in an image based on their instances, where each instance belongs to a class. Image segmentation has many types, but research shows that for medical images, semantic segmentation has proved to be a successful approach for image analysis and understanding. Semantic Segmentation can be used to differentiate various parts of the tissues and help in highlighting different anomalies.
Medical imaging plays an important role in disease diagnosis, treatment planning and clinical monitoring2. Semantic segmentation is mostly used to segment medical images on the basis of different features and its goal is to label each pixel of an image with the corresponding class of the objects. Semantic segmentation of clinically relevant structures in different biopsy images plays a key role in automated diagnosis systems. Deep learning based algorithms learn from data to distinguish objects between different classes in images. The evolution of semantic segmentation started with the advent of computer vision applications. Depending on the quality of data, type of model output, learning techniques, etc., different deep learning models are used in computational pathology. This procedure is gaining increased attention as it reduces the labor required by different specialists and the algorithms also helps in processing a framework that achieves consistent results across different labs for better investigation of various abnormalities. Currently, the incidences and prevalence of skin cancer are increasing worldwide. Early detection, appropriate treatment, and prevention of recurrence are major challenges for researchers today3. A biopsy is the only way to confirm a skin cancer diagnosis. A skin biopsy is a procedure that involves removing a small piece of skin tissue and examining it under a microscope to diagnose skin conditions and diseases. However determining precise skin disease from brightfield microscope images using manual technique requires considerable experience, time, and complex screening and could still be erroneous. Whereas automated methods face many other challenges like presence of hair, inconspicuous lesion margins, low contrast on dermoscopic images, and variability in skin lesion color, texture, and shape4. Advanced computation and optimized code can be used to extract some meaningful information from brightfield images that may not be readily perceived by humans5. The tissue extracted during a biopsy undergoes investigation after the process of staining, where different anomalies are investigated. This investigation is again influenced by the type of processing it has received, leaving a lot of ambiguities even after quite a laborious work. It has been highlighted that due to these challenges, pathologists disagree on up to 60% of cases6. This indicates that research in related computations and segmentation algorithms to help in quick and uniform outcome for easy diagnosis of different anomalies present in the tissue is needed.
The objective of this article is to address the problems of current computational histopathology works, which include subpar accuracy, complications in feature extraction, and the unsatisfactory performance of different techniques. Our solution involves utilizing EfficientNet-B3, a proficient encoder architecture, to allocate the image into layers and designate each layer to a class. This methodology resulted in improved outcomes with enhanced accuracy and reliability. Furthermore, our approach provides an upgraded structure for feature extraction and facilitates smoother predictions. We also scrutinized the efficiency of various backbones on a U-Net for semantic segmentation duties and achieved a 95% accuracy, surpassing the inadequacies of prior research.
The rest of the paper is organized for relevant literature survey in the “Literature review” section, while methodology and dataset is provided in the “Materials and methods” section. The “Experiments and results” section represents results and discussion, while conclusive remarks of this study will be provided in the “Conclusion and future work” section.
Literature review
Existing work
Early detection of skin cancer can increase five year survival rate of patients from 18 to 98%. Automated diagnosis of skin disease consists segmentation, feature extraction, and its classification. Deep fully convolutional networks have achieved significant success in the task of semantic segmentation7. Segmentation has its own importance as feature extraction and classification rely on this part8. Adi Wibowo et al.9 presented a light weight encoder-decoder for segmentation by treating variability with the augmentation. The method shows efficiency in terms of computation. UNet, introduced by Ronneberger et al. in 201510, is a deep learning architecture for semantic segmentation, which aims to accurately classify each pixel in an image to a certain category. The UNet architecture consists of an encoder and a decoder part.The encoder part extracts low level image features and downsamples the input11, while the decoder part upsamples these features to the original image size, and then concatenates them with the corresponding features from the encoder to obtain the final segmentation map. The UNet architecture has shown impressive performance in various biomedical image segmentation tasks and has been widely adopted.
EfficientNet is another deep learning architecture that was proposed in 2019 by Tan and Le in their paper12. The EfficientNet architecture achieves state-of-the-art performance on various image classification tasks with much fewer parameters and Floating Point Operations per Second (FLOPS) compared to previous state-of-the-art models, by adopting a novel compound scaling method that efficiently scales up the depth, width, and resolution of the network. The authors also introduced a new scaling parameter called “compound coefficient” that uniformly scales all dimensions of the network based on a single scaling parameter. The EfficientNet architecture has been widely adopted in various computer vision tasks and has set a new standard for model efficiency. Utilizing these, Gouse Mohiddin et al.13 has offered a theory of preprocessing of images for color consistency, hair removal, noise filtering and edge enhancement. Pre-processed image is then fed to convolutional network to get better results. Fatemah Bagheri et al.8 proposed a two stage method to get the segmentation and masking separately to address different factors of dermoscopic images. This combination strategy has achieved the Jaccard Coefficient index of 80% for overall lesion segmentation. To address the boundry accuracy in leison segmentation, Lituan Wang et al.14 has proposed Deep edge convolutional neural networks based on an encoder-decoder structure to focus more on the skin lesion boundary information. An edge information guided module is designed to introduce more information about the boundary. A new loss function including full loss, center loss and edge loss is proposed to pay more attention to boundary optimization.
Different researchers have worked for the purpose of skin segmentation with different ideas. Some of them have used complete image whereas others have argued that to get more precision, it is better to find the respective region of interests on the image and apply Deep Learning models on that specific region rather than using it for complete image. Hao Zheng et al.7 has provided representative captions as an alternative for better image captioning. The proposed method relies on an unsupervised network that extracts features by directly targeting critical instances in the image followed by a fully connected trained supervised network to segment the image. The segmentation method selects the representative human annotations with reduced inter- and intra-cluster redundancy. Nooshin Moradi et al.5 has put forward a multi class image segmentation instead of binary segmentation based on combining data from different feature spaces to build more informative structure.Two dictionaries are jointly learned using the K-SVD algorithm and then final segmentation is accomplished by a graph-cut method to distinguish background and foreground based on topological information of lesions and the learned dictionaries.
Medical data is scarce and collecting it is a difficult and time consuming process, while their annotation has to be performed by multiple specialists to ensure its validity15. Different deep learning models have shown varying degrees of achievement to date which has shown acceptability of the clinicians. Blind evaluation of these results by board-certified pathologists has also demonstrated similarities with gold standard16. The grouping of radiology through the application of information technology has led to its digitization. The images are digitally created, stored, rapidly transmitted over long distances, and consulted by medical professionals. New advancements in information technology has brought the possibility of 3D/ 4D in MRI6 and further adding to the process of rapid diagnosis. Today, images are clearer, more detailed than ever and annotated15, which allows healthcare teams to ultimately take a better approach towards patient care.
The literature indicates that different algorithms which have been used for the image segmentation purposes and have provided good results. It has also been observed that a combination of different algorithms either for pre-processing or post-processing, shows more promising result some extra computation. This factor has remained a motivational factor and many segmentation processes are now being implemented with grouping of different algorithms targeting different features in the image for better results. Y Zhang et al.17 has used an improved inception module in the encoder to efficiently extract and synthesize information from different receptive fields, followed by a new mesh synthesis strategy to gradually refine shallow features and further smooth the semantic gap for brain tumor segmentation. Similarly for breast cancer detection, KB Soulami et al.18 has used U-Net followed by loss function to improve the accuracy of the model. For segmentation of retinal vessel, H Wu et al.19 has first proposed a scale-aware feature synthesis module, which aims to dynamically adjust receptive fields to efficiently extract multi-scale features. An adaptive feature matching module is then designed to guide the efficient combination of adjacent hierarchical features to capture more semantic information
Kleczek et al.,20 developed a method for tissue segmentation in H &E-stained skin specimens, which aimed to separate the foreground (tissue) from the background (slide) of the images. Their method combined statistical analysis, CIELAB color thresholding, and binary morphology for precise tissue segmentation and evaluated results using the Jaccard index. Oskal et al.,21 used a U-net-based approach to separate the epidermis from the rest of the whole slide images for diagnostic analysis. The Dataset consisted of 380,000 image patches of size 512 x 512 pixels and was collected from 36 pathology images. The results were evaluated using mean Positive Predictive Value, Sensitivity, Dice Similarity Coefficient and Matthews Correlation Coefficient. Nofallah et al.,22 proposed a two-stage segmentation pipeline using U-Net to segment skin biopsy images with coarse and sparse annotations. The team trained their model on a small region of the whole slide image, and generate segmentation masks of different skin tissue entities. In the first stage, they segment the image into four classes: stratum corneum, epidermis, dermis, and background. In the second stage, they train two more models and use masks generated from the first stage to remove the epidermis from the dermis input and dermis from epidermis input, the goal of second stage is to reliably segment the classes of dermal nests and epidermal nests. The results were evaluated using mean intersection over union (IoU), Dice coefficient and opinion score from three pathologists. Thomas et al.23, developed an interpretable deep learning method for automatic diagnosis and analysis of the most common skin cancers. They collected the Non-melanoma skin cancer segmentation for histopathology dataset24 and used a modified U-Net based architecture with Resnet50 encoder, U-NET like decoder and skip connections to classify histological images of skin tissue into 12 dermatological classes that represented the skin tissue structures and layers. They used mean class accuracy and uncertainty maps to interpret trained model and evaluate network performance, and showed the applicability of their segmentation method for dermatopathological tasks such as measuring surgical margins. Kriegsmann et al.25 curated a dataset of 16 skin tissue classes and tumors from 386 cases. They trained an EfficientV2 based deep learning model on 129,364 image patches with a resolution of 395 x 395 pixels) for classifying anatomical tissue structures and neoplasms of the skin tissue. The model was evaluated using cross entropy loss, balanced accuracy and Matthews correlation coefficient. Table 1 shows the summary of all relevant articles discussed in this section.

Research gaps
The existing work suffers from several limitations, including inadequate accuracy, difficulties in extracting relevant features, and ineffective performance of different backbones on U-Net. Additionally, lower performance on some cancerous classes needed to be addressed especially with respect to segmentation. Another issue was the interpretation of overlap in patches of Whole Slide Images (WSIs) and the limited information of neighboring patches, which led to the problem of ragged patches.
Contributions
Our work aims to address above mentioned limitations and improve upon them. Our Efficient-Net model builds upon the works of Thomas et al.24 by training the model to disburse the image with respect to different layers available in that specific image and assign each layer to a class. Overall, by experimenting we are able to:
Analyze different backbones on a UNet, resulting in an efficient and powerful encoder architecture based on EfficientNet-B3 and Ensemble model.
Address limitations by training the model to disburse the image into layers and assign each layer to a class, leading to smoother predictions. Furthermore, uncertainty maps were used to show reliability of segmentation done by model.
Materials and methods
Dataset
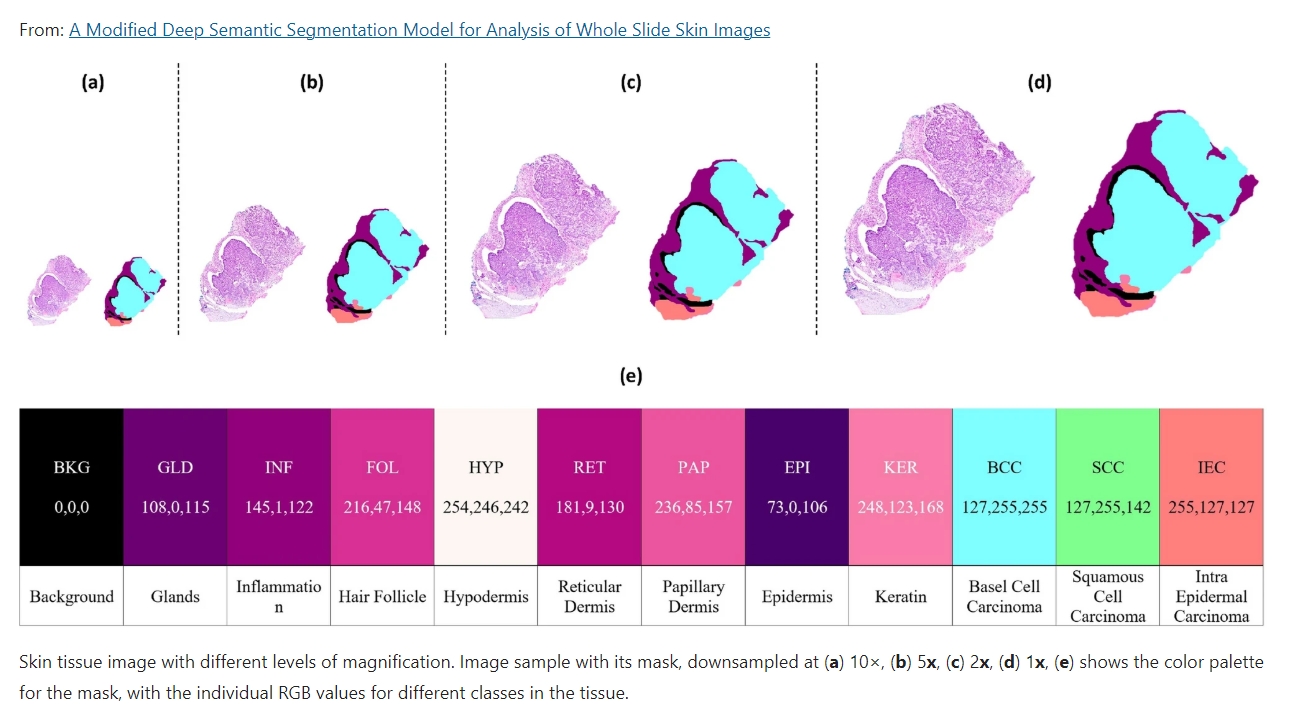
The primary dataset utilized in this research was the Histopathology Non-Melanoma Skin Cancer Segmentation dataset, provided by Queensland University24. The dataset consists of 290 high-resolution images of skin cancer specimens, which were down sampled at various factors, including 1×, 2×, 5×, and 10×. The dataset includes three cancer classes: Basal Cell Carcinoma (BCC), Squamous Cell Carcinoma (SCC), and Intra-Epidermal Carcinoma (IEC), with a total of 290 images. The specimens were obtained from patients aged between 34 and 96 years, with a median age of 70 years. The gender distribution in the dataset was 2/3 female and 1/3 male. The ground-truth segmentation was created by color-coding the images into 12 classification categories, as shown in Fig. 1, including Glands (GLD), Inflammation (INF), Hair Follicles (FOL), Hypodermis (HYP), Reticular Dermis (RET), Papillary Dermis (PAP), Epidermis (EPI), Keratin (KER), Background (BKG), BCC, SCC, and IEC. To determine the optimal down-sampling factor, the dataset was subjected to a series of experiments, which showed that the 5× and 10× down-sampling factors had minimal impact on the segmentation performance. Therefore, the 10× down-sampling factor was used in this study to ensure that the segmentation results were representative of the underlying data and that the performance of the method was not affected by external factors. Thus the Histopathology Non-Melanoma Skin Cancer Segmentation dataset, combined with the selection of an appropriate down-sampling factor, provided a reliable and rigorous foundation for the investigation of the proposed segmentation method in this research.
Methodology
Figure 2 presents the proposed model for the task at hand along with the various data processing steps involved. The figure illustrates the different stages of data processing involved in the model. The first step is pre-processing, where the input images are subjected to a series of preprocessing steps to prepare them for the CNN model. In this stage, the input images are first resized to patches of size 256
256. This is done to reduce the complexity of the model and to enable faster processing. After pre-processing, the patches are then fed to a CNN model for segmentation. The CNN model uses a set of convolutional layers to extract features from the input patches, followed by pooling layers to downsample the features and reduce the computational cost. The output of the CNN model is a segmented image that highlights the areas of interest. Finally, in the post-processing stage, the segmented patches are stitched together to form the final segmented image. This is done to obtain a complete and coherent representation of the input image. The post-processing step also involves the removal of any small artifacts or noise that may be present in the segmented image.
Experiments and results
The proposed model was tested using skin biopsy labelled by pathologists.
Evaluation metrics
The final segmented whole slide images were compared to the ground-truth (GT) images. The testing results in terms of class-wise recall. To define these metrics, the individual pixels in both sets of GT and model outputs were categorized into four classes: True-Positive (TP), True-Negative (TN), False-Positive (FP), and False-Negative (FN) as follows:
TP: Pixels correctly segmented as the target class by the model.
TN: Pixels correctly identified as not belonging to the target class by the model.
FP: Pixels incorrectly identified as belonging to the target class by the model.
FN
incorrectly identified as not belonging to the target class by the model.The class-wise accuracy is defined as the recall:
Ablation study
our studies explored how different backbones on a U-Net performed. The predictions from these models were aggregated to form an ensemble, which included the original U-Net architecture as well. In our experiments, we employed an 80:10
data split for training, validation, and testing, respectively. This partitioning strategy ensures that the model is trained on a diverse set of examples, validated on a separate dataset to tune hyperparameters (as shown in Table 3), and finally tested on an independent set to evaluate its generalization performance. The rationale behind this split is to strike a balance between providing sufficient data for training and robustly assessing the model’s performance on previously unseen instances. The model EfficientNet-B3 took 6 hours to train and during inference stage it takes only 30sec to generate results from a single slice.Quantitative results
Based on the results, it is also important to mention that an ensemble of models did not improve the results significantly, and an individual model with an EfficientNet-B3 backbone would achieve the same results as those of an ensemble model approach. The results clearly highlight that proposed modified EfficientNet-B3 backbone network show improved results specifically for cancerous regions i.e. BCC, SCC and IEC. Our model performed most poorly on the FOL class with a recall of 0.67. This was primarily due to its unbalance in the dataset while also depending on the depth of the biopsy in the case of shave biopsies for example, some hair follicles may be included in the specimen obtained. However, since shave biopsies only remove a superficial layer of skin, the hair follicles may not be fully intact.
shows the confusion matrix for the EfficientNet-B3 model. This confusion matrix visualizes the performance of our segmentation model across 12 classes, with a focus on the recall metric. Each row of the matrix corresponds to the actual class, while each column represents the predicted class. The main diagonal, normalized to highlight recall, shows the percentage of correct predictions for each class. Notably, the model exhibits lower performance in identifying the ’PAP’ class, primarily due to its frequent confusion with the ’RET’ class. This confusion arises from the similarity in layers and proximity of these classes in the skin. Additionally, the limited data available for training the model on the ’PAP’ class exacerbated this issue. Another class where the model under performs is ’FOL’, again largely due to the insufficient data for effective training. Nevertheless the results are still better than the existing ones due to a strong pre-trained backbone.
Conclusion and future work
Early evaluation of skin cancer is important and reliable detection of skin diseases is necessary in dermatology. Skin segmentation tasks provide important data insights relevant to patient’s disease management. Recently, dermatological researchers and regulatory agencies have been attentive on self-acting skin image recognition means to lessen the time, cost and need for human evaluation. In many cases, the outcome of the entire scan is highly dependent on the segmented approach, as evaluating the healing process and other treatment steps depend on the segmented areas. From traditional image processing methods to deep learning algorithms based on computer vision technology, skin segmentation is becoming more and more convenient and efficient. However, the process still receives backlash from the skin community over the use of automated technologies and mechanisms that cannot be easily explained. The proposed technique is able to apply semantic segmentation to extract 12 categories from skin tissue samples. The experiments have shown that U-net model with EfficentNet-B3 back bone gave promising results when compared with existing literature. Despite significant advances in recognition algorithms, a major limitation and challenge is to develop an up-to-date and comprehensive algorithm that excels in accuracy and flexibility across diverse datasets. The variability in staining protocols among labs, coupled with variations in color and contrast of tissue samples, poses hurdles for achieving precise skin segmentation. Additionally, the large resolution of Whole Slide images, often in Gigapixels, contributes to slower processing speeds. For future work in the field, it can be interesting to utilize latest transformers based deep learning models like Segformer and Swin-Unet and see how good they are in this semantic segmentation problem in comparison to convolutional models. Another requirement in this field is to have dataset agnostic algorithms. So experimenting with knowledge distillation along with above mentioned models is required.
Data Availibility
The authors have used publicly available dataset that can be accessed at https://espace.library.uq.edu.au/view/UQ:8be4bd024.
References
Asgari Taghanaki, S., Abhishek, K., Cohen, J. P., Cohen-Adad, J. & Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 54(1), 137–178 (2021).
Article
Google Scholar
Rezaei, M., Harmuth, K., Gierke, W., Kellermeier, T., Fischer, M., Yang, H., & Meinel, C.: A conditional adversarial network for semantic segmentation of brain tumor. In: International MICCAI Brainlesion Workshop 241–252 (Springer, 2017).
Schreiner, T. G., Turcan, I., Olariu, M. A., Ciobanu, R. C. & Adam, M. Liquid biopsy and dielectrophoretic analysis-complementary methods in skin cancer monitoring. Appl. Sci. 12(7), 3366 (2022).
Article
CAS
Google Scholar
Sarker, M. M. K. et al. Slsnet: Skin lesion segmentation using a lightweight generative adversarial network. Expert Syst. Appl. 183, 115433 (2021).
Article
Google Scholar
Moradi, N. & Mahdavi-Amiri, N. Multi-class segmentation of skin lesions via joint dictionary learning. Biomed. Signal Process. Control 68, 102787 (2021).
Article
Google Scholar
Stankovic, Z., Allen, B. D., Garcia, J., Jarvis, K. B. & Markl, M. 4d flow imaging with mri. Cardiovasc. Diagnos. Ther. 4(2), 173 (2014).
Google Scholar
Zheng, H., Yang, L., Chen, J., Han, J., Zhang, Y., Liang, P., Zhao, Z., Wang, C., & Chen, D.Z. Biomedical image segmentation via representative annotation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33 5901–5908 (2019)
Bagheri, F., Tarokh, M. J. & Ziaratban, M. Skin lesion segmentation from dermoscopic images by using mask r-cnn, retina-deeplab, and graph-based methods. Biomed. Signal Process. Control 67, 102533 (2021).
Article
Google Scholar
Wibowo, A., Purnama, S. R., Wirawan, P. W. & Rasyidi, H. Lightweight encoder-decoder model for automatic skin lesion segmentation. Inform. Med. Unlocked 25, 100640 (2021).
Article
Google Scholar
Ronneberger, O., Fischer, P., & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention 234–241 (Springer, 2015).
Haider, A., Arsalan, M., Nam, S.H., Hong, J.S., Sultan, H., & Park, K.R. Multi-scale feature retention and aggregation for colorectal cancer diagnosis using gastrointestinal images. Eng. Appl. Artif. Intell. 125, 106749 (2023). https://doi.org/10.1016/j.engappai.2023.106749.
Tan, M., Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning 6105–6114 (PMLR, 2019).
Kosgiker, G. M. & Deshpande, A. A novel segcap algorithm based enhanced segmentation of dermoscopic images of interest. Mater. Today Proc. 51, 779–787 (2022).
Article
Google Scholar
Gu, R., Wang, L. & Zhang, L. De-net: A deep edge network with boundary information for automatic skin lesion segmentation. Neurocomputing 468, 71–84 (2022).
Article
Google Scholar
Anthimopoulos, M. et al. Semantic segmentation of pathological lung tissue with dilated fully convolutional networks. IEEE J. Biomed. Health Inform. 23(2), 714–722 (2018).
Article
PubMed
Google Scholar
Li, D. et al. Deep learning for virtual histological staining of bright-field microscopic images of unlabeled carotid artery tissue. Mol. imaging Biol. 22(5), 1301–1309 (2020).
Article
CAS
PubMed
PubMed Central
Google Scholar
Zhang, Y. et al. Msmanet: A multi-scale mesh aggregation network for brain tumor segmentation. Appl. Soft Comput. 110, 107733 (2021).
Article
Google Scholar
Soulami, K. B., Kaabouch, N., Saidi, M. N. & Tamtaoui, A. Breast cancer: One-stage automated detection, segmentation, and classification of digital mammograms using unet model based-semantic segmentation. Biomed. Signal Process. Control 66, 102481 (2021).
Article
Google Scholar
Wu, H. et al. Scs-net: A scale and context sensitive network for retinal vessel segmentation. Med. Image Anal. 70, 102025 (2021).
Article
PubMed
Google Scholar
Kleczek, P., Jaworek-Korjakowska, J. & Gorgon, M. A novel method for tissue segmentation in high-resolution h &e-stained histopathological whole-slide images. Comput. Med. Imaging Graph. 79, 101686 (2020).
Article
PubMed
Google Scholar
Oskal, K. R., Risdal, M., Janssen, E. A., Undersrud, E. S. & Gulsrud, T. O. A u-net based approach to epidermal tissue segmentation in whole slide histopathological images. SN Appl. Sci. 1, 1–12 (2019).
Article
CAS
Google Scholar
Nofallah, S. et al. Segmenting skin biopsy images with coarse and sparse annotations using u-net. J. Digit. Imaging 35(5), 1238–1249 (2022).
Article
PubMed
PubMed Central
Google Scholar
Thomas, S. M., Lefevre, J. G., Baxter, G. & Hamilton, N. A. Interpretable deep learning systems for multi-class segmentation and classification of non-melanoma skin cancer. Med. Image Anal. 68, 101915 (2021).
Article
PubMed
Google Scholar
Thomas, S., & Hamilton, N. Histopathology Non-melanoma Skin Cancer Segmentation Dataset (2021).
Kriegsmann, K. et al. Corrigendum: Deep learning for the detection of anatomical tissue structures and neoplasms of the skin on scanned histopathological tissue sections. Front. Oncol. 13, 1201237 (2023).
Article
PubMed
PubMed Central
Google Scholar
Vooban. Smoothly-Blend-Image-Patches (GitHub, 2017)
Haider, A., Arsalan, M., Park, C., Sultan, H. & Park, K. R. Exploring deep feature-blending capabilities to assist glaucoma screening. Appl. Soft Comput. 133, 109918 (2023).
Article
Google Scholar
Real, E., Aggarwal, A., Huang, Y., Le, Q.V.: Regularized evolution for image classifier architecture search. In: Proceedings Of The Aaai Conference On Artificial Intelligence, vol. 33 4780–4789 (2019)
Huang, G., Sun, Y., Liu, Z. &, Sedra, D., Weinberger, K.Q. Deep networks with stochastic depth. In: European Conference on Computer Vision 646–661 (Springer, 2016).
Zagoruyko, S., Komodakis, N.: Wide Residual Networks. arXiv preprint arXiv
.07146 (2016)Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, D., Chen, M., Lee, H., Ngiam, J., Le, Q.V., Wu, Y., et al.: Gpipe: Efficient training of giant neural networks using pipeline parallelism. Adv. Neural Inf. Process. Syst. 32, 66 (2019).
Minhas, K. et al. Accurate pixel-wise skin segmentation using shallow fully convolutional neural network. IEEE Access 8, 156314–156327 (2020).
Article
Google Scholar