Traffic monitoring plays an important role in modern urban infrastructure management and public safety. In this study, an ensemble-based traffic monitoring model is developed utilizing traditional machine learning techniques. The ensemble model integrates K-Nearest Support Vector Machine (SVM), Decision Trees, and Random Forest algorithms to classify and identify vehicles (trucks and motorcycles) within a traffic video. The approach involved the conversion of traffic video into images, manual annotation of vehicles in images, feature extraction, and the training of machine learning models. Performance of these models was evaluated using the metrics of Area Under the Curve (AUC), Precision, Recall, and F1 score. Furthermore, an ensemble model from the 3 top-performing algorithms was constructed and its efficacy compared against individual models. Experimental results demonstrated the effectiveness of the ensemble approach, with the ensemble model showcasing superior performance compared to individual models. This research contributes to the advancement of traffic monitoring model experimentation, offering insights into the application of ensemble learning in improving classification accuracy and robustness.
Traffic congestion is a growing problem in urban areas worldwide. It leads to increased travel times, fuel consumption, and pollution. Traffic monitoring systems are essential for understanding traffic patterns and implementing strategies to improve traffic flow. These systems typically involve collecting data on traffic volume, speed, and vehicle types. This study details the development of a traffic monitoring system that utilizes traditional ensemble machine learning techniques to analyze a video feed and detect specific vehicle types of motorcycles and trucks.
Despite the advancements, the accurate detection and classification of diverse vehicle types, particularly motorcycles and trucks, remain a complex task due to their varying sizes, shapes, and dynamic behaviors in traffic. Additionally, the core computational challenge in this study is to overcome the limitations of traditional machine learning models that often lack robustness in diverse and dynamic environments. Therefore, by harnessing the power of ensemble learning, the study aims to construct a model that can reliably indentify motorcycles and trucks from other vehicles in traffic.
This research aims to design and develop a traffic monitoring model that employs an ensemble of traditional machine learning models. Specifically:
Historically, traffic monitoring systems relied on manual counting methods, which were labor-intensive and prone to inaccuracies [9]. The introduction of automated systems marked a significant shift, with technologies such as loop detectors and video cameras enabling real-time data collection and analysis [10]. Currently, this manual work of human operators to manually tally vehicles and discern vehicle flow and density has been partiality or fully replaced with introducing high-tech solutions that amplify precision and mitigate the need for manual labor in some areas [11].
Furthermore, the integration of machine learning algorithms has seen a significant stride in the evolution of traffic monitoring systems. The strength of ML lies in its ability to assimilate and learn from extensive datasets, equipping it with the capability to understand complex patterns and behaviors that often skip the human eye. The shift from manual counting to automated, to intelligent systems has been extensively studied, with some studies focusing on unsupervised learning techniques for vehicle traffic flow behavior analysis [2]. Research has also highlighted the use of feature selection and clustering algorithms like K-means to categorize network traffic [4], and attempts of enhancing the efficiency of smart transportation systems [7]. The incorporation of machine learning (ML) has further proven to be a transformative force in developing systems for real-time vehicle detection, categorization, and accident identification [?]. Consequently, ML applications in the domain of vehicle traffic monitoring are in high demand, geared by their promise to augment road safety measures and streamline the management of traffic systems. More studeies has explored various aspect such as investigating preprocessing effects in road traffic scene analysis using machine learning models [8], comparative analysis of machine learning methods for lane change intention recognition using vehicle trajectory data [13], and fatality prediction for motor vehicle collisions using deep learning and ensemble methods [6].
One of the standout machine learning strategies employed in vehicle classification system based on machine learning is the utilization of ensemble methods. Ensemble methods capitalise on the predictive power of multiple classifiers to formulate a unified, more accurate decision-making process, often exceeding the performance of standalone classifier models [5]. Several experiments have been made including a proposition of an ensemble-based machine learning model for forecasting network traffic in VANET [1], predictio and analyzing of road traffic injury severity using boosting-based ensemble learning models with SHAPley Additive exPlanations [5] and applying machine learning-enabled data analysis for road car accident prediction [3].
However, despite the significant strides made in the application of ML to traffic analysis, the field still struggles with challenges regarding to the precision of detection mechanisms, the issue of real-time data processing, and the scalability of data annotation methodologies [12]. These ongoing challenges underscore the need for continued research and innovation to refine the functionality and expand the capabilities of traffic monitoring systems.
Additionally, it in noteworthy, that emerging studies have starting leveraging technological advancements to address challenges in traffic monitoring and analysis. High-performance computing architectures, such as GPUs and distributed computing frameworks, enabling faster processing of large-scale traffic datasets, facilitating real-time analysis.
This study seeks to contribute by exploring the application of ensemble machine learning techniques specifically tailored for vehicle type identification and classification from a road traffic video.
A video feed was the primary data source. It is a 50 minute video that was recorded on a light during day light time at Nakawa, Kampala Uganda. The video can be access HERE. The videos was carefully studies by the author by visual inspection to confirm the presence of the target vehicle classes (motorcycles and trucks) and appropriateness.
A Python script using OpenCV was used to process the video, extracting frames at a rate of 30 frames per second (FPS). This frame rate was selected to find a balance between temporal resolution and computational efficiency. The captured images were then manually annotated with the CVAT online open-source tool, chosen over the LabelImg package for its ease of use. Each image was labeled with bounding boxes around motorcycles and trucks, with the remaining vehicles falling into the "other" category. The annotations were exported in CSV format, containing information for each frame, such as filename (the unique identifier for each frame), bounding box coordinates, and class labels indicating the type of vehicle within each box ("motorcycle", "truck", "other").
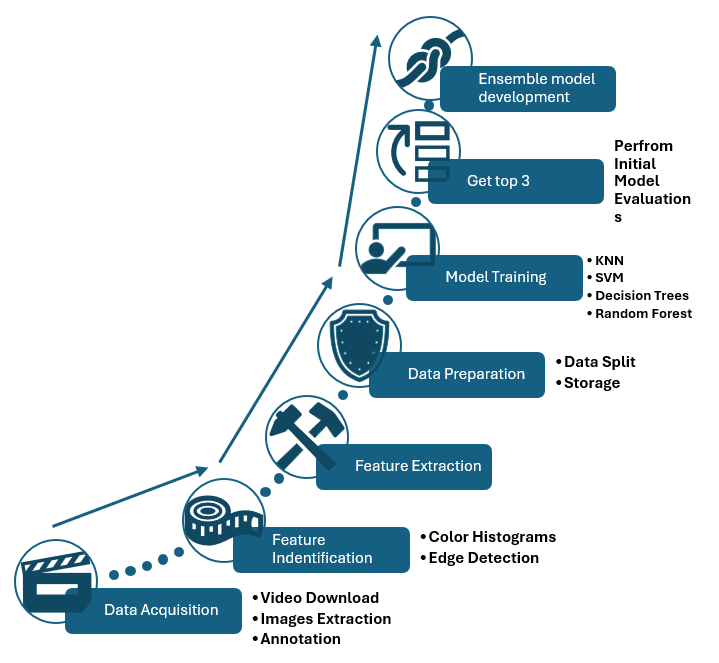
[Figure 1. A figure showing the implementation approach]
The features of color histograms, and edge detetction were considered. Color histograms represent the distribution of colors in an image and are particularly useful for distinguishing between different types of vehicles and edges highlight the boundaries and shapes of objects within an image, aiding in the differentiation of vehicle types based on their structural characteristics.
A Custom Python function was developed to automate the extraction of the identified features from the annotated images. The script utilized libraries such as NumPy and OpenCV to calculate color histograms and perform edge detection. The extracted features were then compiled into a dataset, with each instance corresponding to an annotated vehicle and its features and corresponding labels.
The dataset was split into training and testing sets using an 80% to 20% ratio. This split ensured that a substantial amount of data was available for model training while still providing a representative sample for evaluation.
| Class | Count | %age |
|---|---|---|
| motorcycle | 73 | 6.1% |
| other | 1,061 | 89.2% |
| truck | 55 | 4.6% |
| Total | 1,189 | 100.0% |
Table 1. A table showing the data label distributions
The annotation resulted to a dataset with 1,189 labels records with majority of the classes as other (89.2%), motorcycle (6.1%) and truck with (4.6 %) and shown in table 1
Four traditional machine learning models, namely K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Decision Trees, and Random Forest, were employed in order to accurately identify and classify different types of vehicles. The objective of this study was to train these models so that they could effectively recognize various vehicle types based on their inherent characteristics and features.
The top three models, based on F1 scores from the initial testing, were selected to construct an ensemble model.

[Figure 2. A figure showing the ensemble model trained]
The ensemble approach employed a weighted voting system, where each model's vote was weighted according to its F1 score. This method aimed to leverage the strengths of each individual model to improve overall accuracy.
The performance of each model was assessed using metrics of AUC scores, precision, recall, and F1 scores and the confusion matrix. The results are then compared to determine the efficacy of the ensemble model over the individual models.
Confusion matrices offer a granular view of the classification performance, presenting the number of correct and incorrect predictions made by the models false positives and false negatives and for gauging the models' ability to correctly classify the vehicles.
The AUC scores reflect the models' capability to discriminate between the vehicle classes. A model with a high AUC score can effectively separate the positive and negative classes, which is crucial for a traffic monitoring system that relies on accurate vehicle detection.
Precision and recall are complementary metrics that, when combined into the F1 score, provide a balanced measure of a model's accuracy and robustness. Precision focuses on the correctness of the positive predictions, while recall assesses the model's ability to identify all relevant instances. The F1 score harmonizes these metrics to facilitate a comprehensive evaluation of the models' performance.
Furthermore, the comparative analysis juxtaposes the individual models against the ensemble model to highlight the benefits of the ensemble approach. This comparison was pivotal in demonstrating the added value of combining multiple models to achieve superior performance.
The four models were evaluated for the task of identifying classes of truck, motorcycle, and other vehicles as summarised in table 2. Generally, the SVM model demonstrated the highest overall performance with the highest AUC, indicating superior class separability.
| Model | AUC | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Random Forest | 0.883 | 0.865 | 0.899 | 0.854 |
| Decision Tree | 0.597 | 0.847 | 0.849 | 0.848 |
| SVM | 0.922 | 0.803 | 0.896 | 0.847 |
| KNN | 0.469 | 0.800 | 0.818 | 0.809 |
Table 2. A table showing model results
A evident from table 2, the Random Forest model exhibited a high performance across all metrics, with an AUC of 0.883, Precision of 0.865, Recall of 0.899, and F1 Score of 0.854. This indicates that the Random Forest model is effective in distinguishing between the different classes of vehicles with a strong balance between precision and recall. The high AUC value suggests that the model has a good measure of separability between the classes.
The Decision Tree model showed an AUC of 0.597, which is considerably lower than that of the Random Forest and SVM models. However, the Decision Tree achieved a high Precision of 0.847, Recall of 0.849, and F1 Score of 0.848. This suggests that while the Decision Tree may not be as effective in distinguishing between the classes overall (as indicated by the lower AUC), it still performs relatively well in terms of precision, recall, and F1 Score, indicating consistent performance in correctly identifying vehicle classes.
Similarly, the SVM model demonstrated the highest AUC of 0.922 among the models, indicating superior performance in distinguishing between the classes. The Precision of the SVM model was 0.803, Recall was 0.896, and the F1 Score was 0.847. These results show that the SVM model is highly effective at identifying vehicle classes with a strong ability to differentiate between them, though its precision is slightly lower compared to Random Forest and Decision Tree.
Furthermore, the KNN model achieved the lowest AUC of 0.469, which suggests that it has the least effective separability between the vehicle classes. Its Precision was 0.800, Recall was 0.818, and the F1 Score was 0.809. While the model's precision, recall, and F1 Score are reasonable, the low AUC indicates that the overall ability of the KNN model to differentiate between the classes is limited compared to the other models.
These results are more evident as shown in the confusion matrix in figure 3
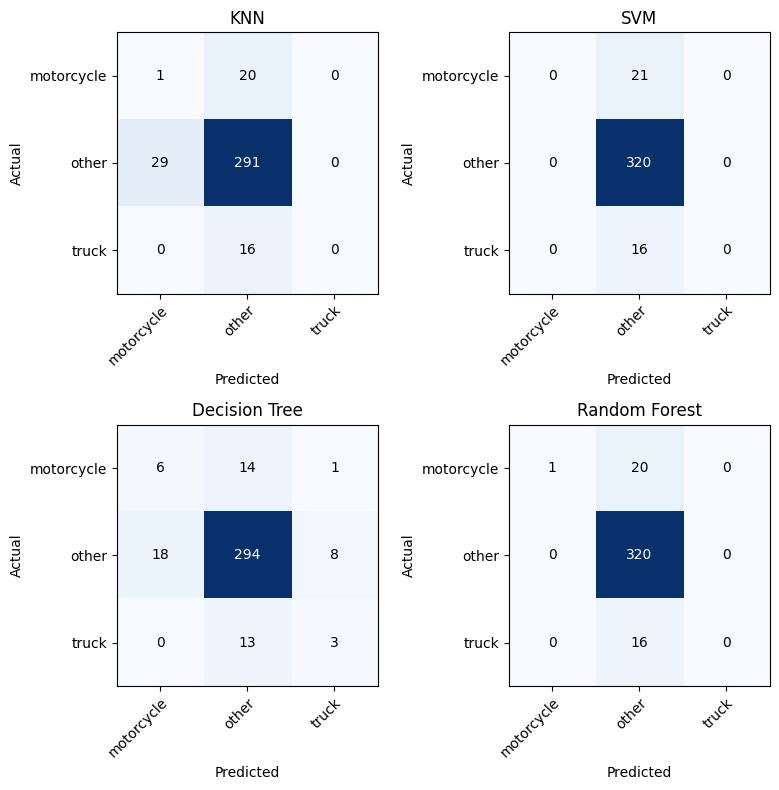
[Figure 3. A Combined Confusion Matrix for the individual models]
As shown from figure 4, the ensemble model has the a more superior precision and recall leading in the highest F1 score. This signifies its balanced performance and its accurateness in vehicle classification.
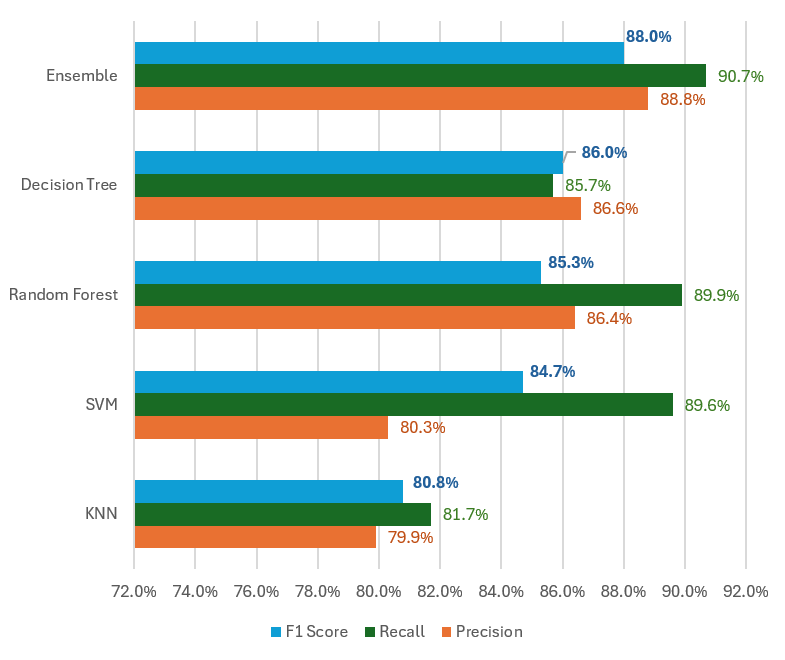
[Figure 4. Evaluation Metrics comparison with ensemble model]
On further comparison, it is evident that however much the SVM model achieves a high AUC score, it lacks precision, which is important for minimizing false positives in correctly classifying vehicles.
The Decision Tree and Random Forest models demonstrate strong performance, but do not match the overall accuracy of the ensemble model. The KNN model, with the lowest scores across all metrics, highlights the difficulties it encounters in this complex classification task.
SVM has the highest AUC score of 0.9205, indicating its strong ability to differentiate between motorcycles and trucks. Random Forest also boasts a high AUC score of 0.8946, indicating its effectiveness. Decision Tree falls behind with a lower AUC of 0.6507, suggesting more difficulty in classification compared to SVM and Random Forest. KNN has the lowest AUC score of 0.4686, signifying significant challenges in distinguishing between the two vehicle types.
The Ensemble model exhibits the highest precision of 0.8882, indicating a high rate of accurate predictions for the vehicle classes. Decision Tree and Random Forest also display commendable precision scores, 0.8660 and 0.8645 respectively. SVM and KNN have lower precision scores of 0.8035 and 0.7996, suggesting a higher rate of false positive predictions compared to the other models. The Ensemble model leads with a recall of 0.9076, indicating strong capabilities in identifying most of the motorcycles and trucks in the dataset.
Random Forest and SVM also show high recall scores, 0.8992 and 0.8964, suggesting their effectiveness in detecting the vehicles. Decision Tree and KNN have lower recall scores of 0.8571 and 0.8179, indicating a higher rate of missed positive instances.
The Ensemble model achieves the highest F1 score of 0.8803, signifying a better balance between precision and recall among all the models. Decision Tree follows with an F1 score of 0.8607, closely trailed by Random Forest with 0.8539 and SVM with 0.8474. KNN has the lowest F1 score of 0.8086, reflecting its overall lower performance in both precision and recall.
Overall, the Ensemble model surpasses individual models in terms of precision and recall, resulting in the highest F1 score. This suggests that combining the strengths of individual models into an ensemble can lead to a more accurate and reliable vehicle classification and identification model.
This research has introduced an application of ensemble machine learning methods for traffic monitoring, focusing on categorizing and distinguishing motorcycles and trucks in a video stream. The results showed that the ensemble model, combining SVM, Decision Trees, and Random Forest, performed better than individual models in terms of accuracy and identification, achieving the highest F1 score. Although SVM had the highest AUC score, indicating strong discriminatory power, it did not translate into the best overall performance. The ensemble model demonstrated its strength in balancing false positives and false negatives, which is crucial for practical traffic monitoring applications.
This study contributes to computer science and traffic management by demonstrating the effectiveness of ensemble models compared to single classifier systems for vehicle classification and identification, and it provides a framework for experimenting with traditional machine learning techniques in creating models.
To further research in this area, the following suggestions are proposed:
[Figure 5. A Combined Confusion]
[1] P. Amiri and S. Pierre. An ensemble-based machine learning model for forecasting network traffic in vanet. 2023.
[2] Ons Aouedi. Machine Learning-Enabled Network Traffic Analysis.
Theses, Nantes Universite, Dec. 2022.
[3] A. Ardakani et al. Machine learning-enabled data analysis for
road car accident prediction. 2023.
[4] Suresh Babu Changalasetty, Ahmed Said Badawy, Lalitha Saroja
Thota, and Wade Ghribi. Classification of moving vehicles using
k-means clustering. In 2015 IEEE International Conference on
Electrical, Computer and Communication Technologies (ICECCT), pages
1–6. IEEE, 2015.
[5] Y. Dong et al. Predicting and analyzing road traffic
in-juryseverityusingboosting-basedensemblelearningmodels with shapley
additive explanations. 2022.
[6] B. Emu et al. Fatality prediction for motor vehicle collisions
using deep learning and ensemble methods. 2022.
[7] S Kanakaprabha, G Ganeshkumar, A Sureshkumar, T Ud-hayakumar, M
Nisha, and P Poornaprakash. Advanced ma-
chine learning approaches for improving traffic flow predic-tions in
smart transportation systems. In XVIII International Conference on
Data Science and Intelligent Analysis of In-formation, pages 145–154.
Springer, 2023.
[8] J. Kim. Preprocessing effects in road traffic scene analysis
using machine learning models. 2023.
[9] Mishuk Majumder and Chester Wilmot. Accuracy assess-ment and
guidelines for manual traffic counts from pre-recorded video data.
Journal of Transportation Technolo-gies, 13(4)
[10] J Palo, Jacek Caban, Monika Kiktova, and Lubomır Cernicky. The
comparison of automatic traffic counting and manual traffic counting.
IOP Conference Series: Materials Science and Engineering, 710
[11] S. Srividhya, C. Kavitha, W. Lai, V. Mani, and O. Khalaf. A
machine learning algorithm to automate vehicle classifi-cation and
license plate detection.
[12] M. S. A. Talip, Mohd Zulhakimi Ab Razak, Mahazani Mo-hamad, A. S.
M. Khairuddin, and T. Izam. Enhancing
traf-ficmanagementwithembeddedmachinelearningforvehicle detection.
[13] L. Yuan et al. Comparative analysis of machine learning methods
for lane change intention recognition using vehicle trajectory data.
2023.