The source code for the project is available in this GitHub repository, and the deployed app can be accessed here.
Introduction
Nowadays, every business or organization possesses vast amounts of data across different formats, such as data warehouses or databases. The primary programming language used for managing these data is SQL (Structured Query Language), which is essential for querying, updating, and managing data within relational database management systems (RDBMS) like MySQL, PostgreSQL, Oracle, and Microsoft SQL Server. In contrast, non-relational databases (NRDBMS), often referred to as NoSQL databases, utilize a variety of languages and data models to manage data. For example, MongoDB employs a proprietary query language to access Document Stores. However, these languages can be challenging for many members of the organization to query or understand.
At the same time, Large Language Models (LLMs) have opened up significant potential in the field of artificial intelligence (AI), particularly through Generative AI. This category of AI focuses on generating new content rather than merely analyzing data, as traditional AI does. Generative AI learns patterns and structures from its training data to produce novel outputs, such as text, images, or even code. It can be utilized to explore new ideas, generate unique designs, and push the boundaries of creativity. The leading cloud providers—Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP)—are at the forefront of unlocking generative AI, offering a variety of tools and services that enable developers and businesses to integrate this technology into their applications, this article highlights each provider's strengths, weaknesses, and specific use cases.
Generative AI has numerous potential applications, including text generation, code generation, summarization, translation, and chatbots. One particularly promising area involves using natural language processing (NLP) to facilitate data access through SQL queries, thus eliminating the need for complex technical code. This generative AI task, known as text-to-SQL, allows non-technical users and analysts to pose questions related to a database using everyday language. The goal is to automatically convert natural language input into accurate SQL queries, transforming text into a structured format that can directly query a database and retrieve relevant results.
In this article, we propose a technical solution for converting natural language queries—whether in plain English or other languages—into accurate SQL queries. We will demonstrate how to execute these queries on a database created from the AdventureWorks dataset using Google’s advanced multimodal model, the Gemini 1.5 Flash LLM.
Texl to SQL Overview
Text to SQL bridges the gap for non-technical users who may find SQL daunting, enabling them to ask analytical questions in natural language and receive answers from the metadata store. For instance, users can ask, Which products had the highest sales last week?, and the model will return the query if it was prompted to do so. This functionality allows users to interact with data intuitively, making analytics more accessible and actionable.
The key components of the Text to SQL involves three main stages:
-
Natural Language Processing: involves processing the user's input query, extract its element and intent and convert it to a structured format.
-
Map the extracted elements into SQL syntax and generate a valid SQL query
-
Run the AI-generated query on the database, and retrieve the results and return it to the user.
The following diagram shows a basic Text to SQL workflow:
These LLMs can be prompted to understand natural language questions and generate corresponding SQL queries as output. They could benefit from adopting in-context learning (ICL) and fine-tuning settings as more data becomes available.
Text to SQL Architecture Patterns
There are several architectural patterns to consider when implementing a Text to SQL solution with LLMs. The primary approaches include Prompt Engineering, Fine-Tuning, and Retrieval-Augmented Generation (RAG). Each approach offers different benefits and challenges, depending on the complexity of the queries, the structure of the schema inference, and the availability in domain specific datasets. But they aim for the same purpose, to retrieve relevant results, and to reduce the LLM's hallucination.
1. Prompt Engineering
Prompting is the most basic way to interact with any LLM. It’s a straightforward approach where the LLM is guided through clear instructions to understand the user's intent. Effective prompt engineering is key to developing natural language to SQL systems and providing better results for the language model. In this setup, the user requests a SQL query along with relevant context, such as table/schema definitions, images, PDFs, and sample query results. The LLM then uses this prompt context to generate a SQL query, which can be executed on the database to retrieve the desired results.
2. Prompt Engineering with Fine-Tuning
In Prompt Engineering with Fine-Tuning, the basic prompt engineering approach is enhanced by adding a step of fine-tuning the LLM on a domain-specific dataset. This enables the model to generate more accurate SQL queries by leveraging domain-specific knowledge.
In this approach, a base LLM is further trained on domain-specific datasets, adapting it to handle questions and SQL generation more accurately for a particular industry or use case. Fine-tuning allows the model to develop deeper insights into complex database structures and schemas. It’s like taking the language model and making it learn about something new, such as the database. This approach can improve the accuracy of generated SQL queries, but it requires domain-specific datasets and computational resources.
3. Retrieval-Augmented Generation (RAG)
For scenarios with a large or frequently updated knowledge base, RAG combines prompt engineering with a retrieval component. In this setup, the LLM is assisted by a retriever that fetches relevant data from an external knowledge base to enhance the prompt context. This knowledge base can be a vector database, serving as a library of relevant information that the model looks up to collect data pertinent to the user's question, and then answers based on that information.
This approach can handle complex, dynamic queries that may require specific or up-to-date information and is ideal for domains where the database schema is extensive or frequently changes.
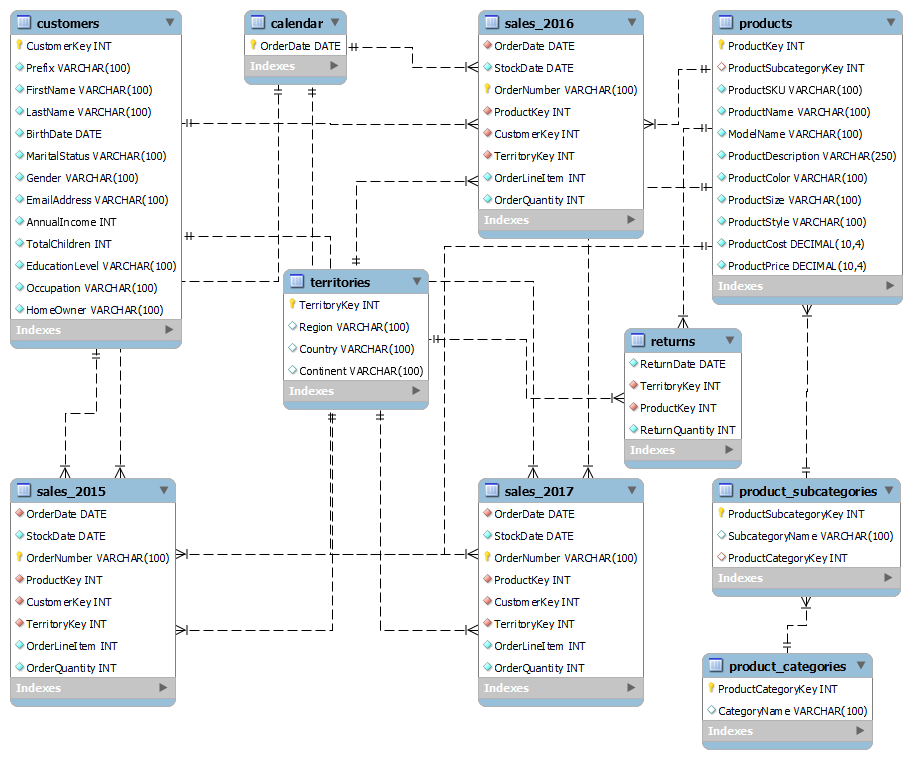
Adventure Works Database
The Adventure Works dataset was obtained from Kaggle, an open-source platform that offers a wide variety of datasets and challenges for users to explore. This dataset consists of ten different tables stored in .csv format and includes information on e-commerce analytics. It encompasses various types of data typically associated with customer transactions and product management.
The MySQL database was created using a custom Python Script Importer from these .csv files. Subsequently, the MySQL dump was converted into a lightweight SQLite database. This conversion simplifies development, testing, and deployment by making the database more portable and easier to manage. The conversion was done using a shell script available on GitHub, which transforms MySQL dumps to a compatible SQLite3 format, including MySQL KEY statements from the CREATE block.
The Entity Relationship Diagram (ERD) below visualizes the database schema and the relationships between entities, providing a comprehensive view of the database structure. It illustrates the relational schema, which consists of ten tables: customers, products, product_subcategories, product_categories, calendar, territories, sales_2015, sales_2016, sales_2017, and returns.
In the ERD:
- Primary Keys (PK) are represented by a golden key symbol.
- Foreign Keys (FK) are depicted as a red rhombus.
Methodology
In this section, we describe in detail the two main methods we used for the Text-To-SQL task, Prompt Engineering, and Retrieval-Augmented Generation (RAG). These two approaches are using the same LLM, Gemini 1.5 Flash via Google AI Studio and the Gemini API. We implemented the model through the Google Gemini API library. The final goal is to interact with the AdventureWorks database, execute corresponding SQLite queries, and retrieve the results.
Prompt Engineering Approach
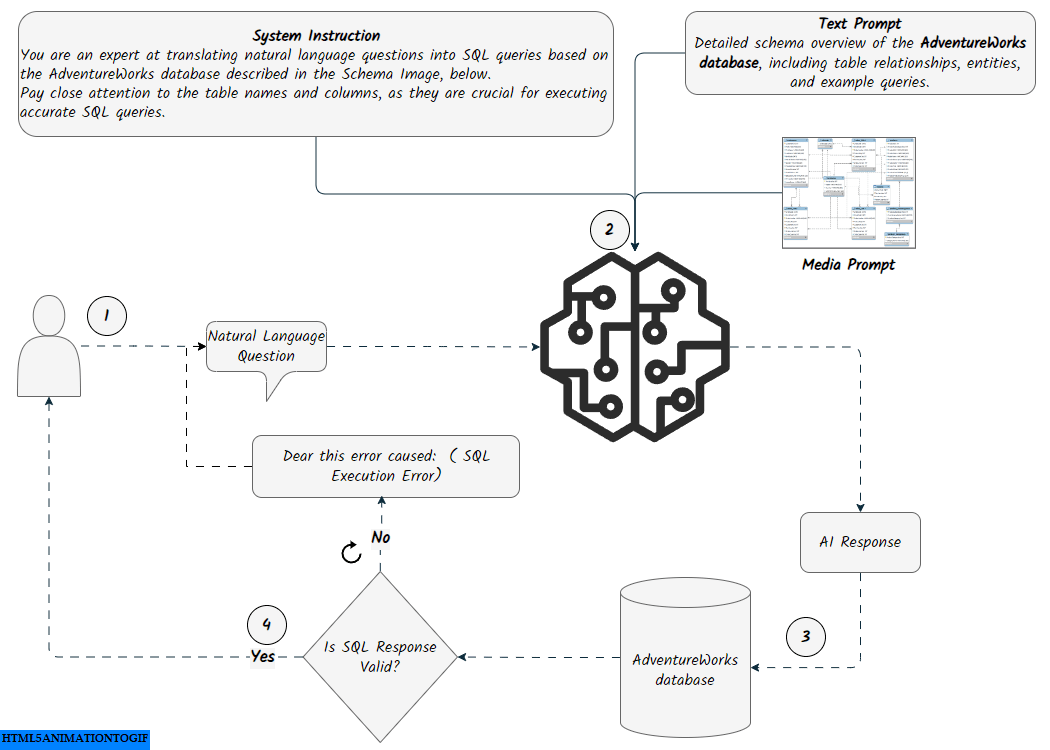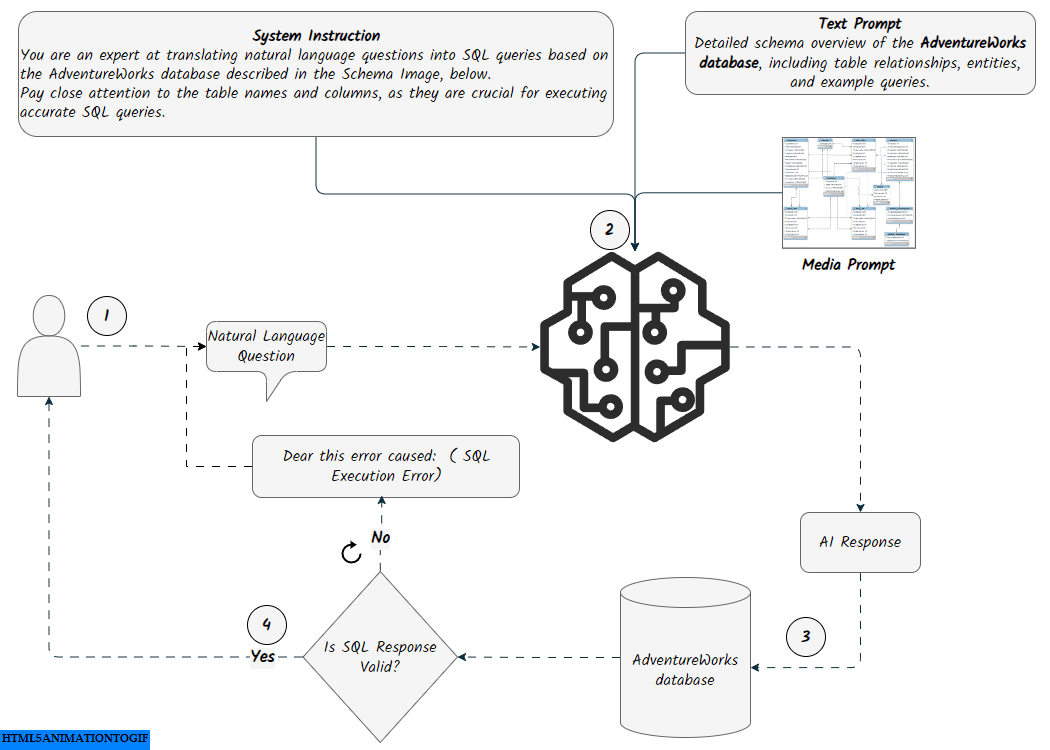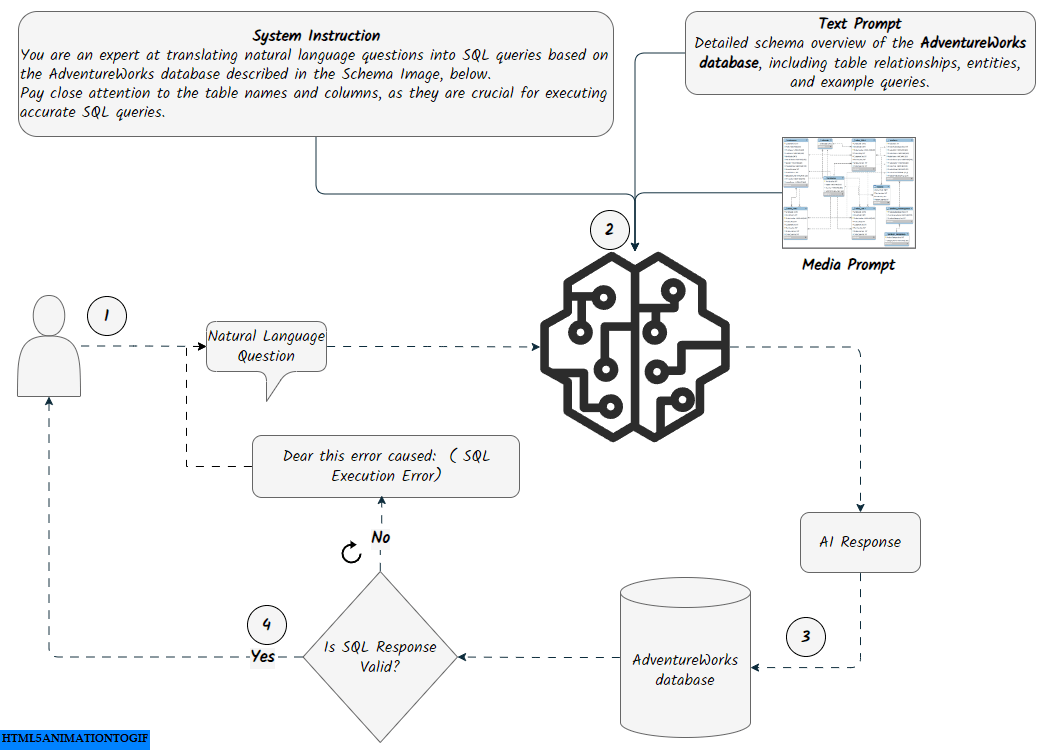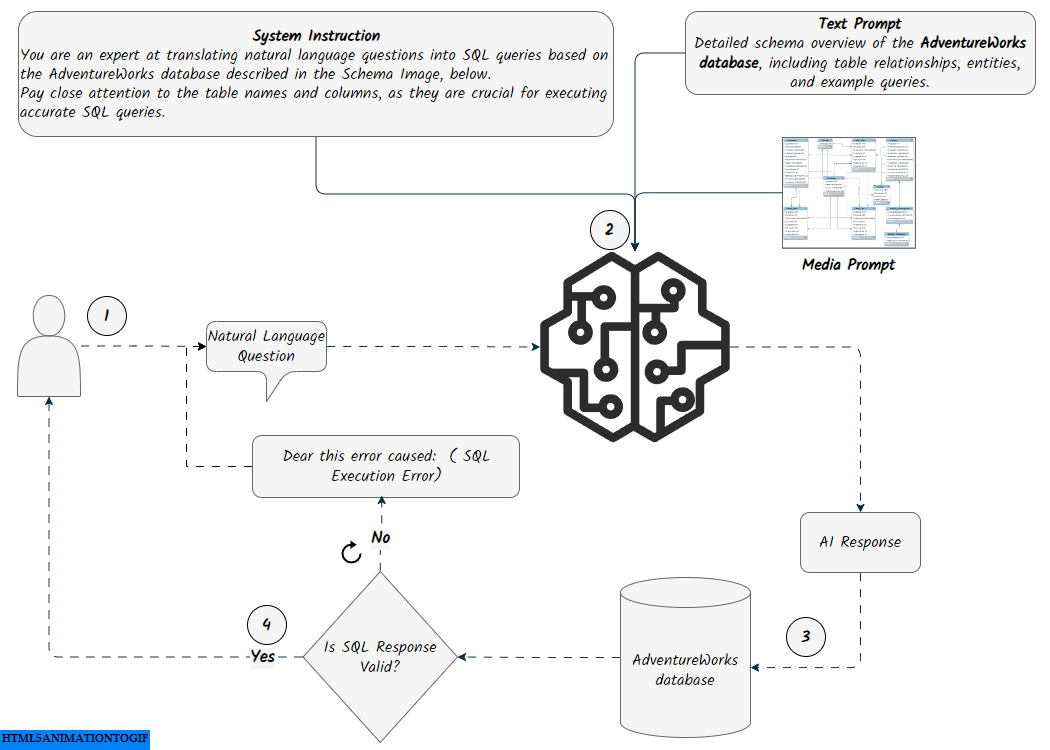
The Prompt Engineering approach uses specific instructions to guide the model. For generating content, we set up three inputs: Text Prompt, Media Prompt, and Question.
- Text Prompt :
The Text Prompt includes an overview of the database structure, notes, and examples of execution and response. We used a custom Python script that connects to the SQLite database (in this case, adventureworks.db) and retrieves information about its tables and their columns. This foundational setup allows the model to understand the database schema and its elements effectively. Additionally, since our database is in SQLite, we ensured that the model handles SQLite-compatible date functions, such as strftime(%Y', OrderDate), for extracting the year from dates. The final Text Prompt we used is available here
- Media Pompt:
Prompting with media files involves uploading the AdventureWorks schema snapshot to the model using the media.upload method. This snapshot provides the model with additional context and illustrates the relationships between the tables. See the docs and source-code for more info on how it works.
- Question:
This is the natural language question that will be passed to the model. It could be a random question from a predefined list or a question asked by the user.
The question will be passed to the prompted model, and the model will return an AI response, translating the natural language question into SQLite queries. The SQL query returned by the model will be cleaned by removing unnecessary formatting and whitespace. It will then be displayed to the user as a SQL Query. A connection to the SQLite database (adventureworks.db) will be established to execute the cleaned SQL against the database. If there are no errors during execution, the results will be shown to the user as Query Results in a formatted dataframe.
The function will check if the SQL query is a data manipulation operation (INSERT, UPDATE, DELETE). However, this feature is still under development, so it will not be executed against the database. Instead, a message of You are not allowed to manipulate the database will be returned.
If an error occurs during execution, the prompt will be updated by taking the original question asked by the user along with the error message as arguments, and sending it back to the model, entering a self-correction loop. A final answer template will be sent to the model as a prompt including a question, a query and result.
The following Python script demonstrates this approach, and it is also available at the following GitHub link:
# src/utils.py import sqlite3 def execute_sql_query(sql, db_path): """Execute SQL query and return results along with column names and error (if any).""" try: with sqlite3.connect(db_path) as conn: cur = conn.cursor() cur.execute(sql) rows = cur.fetchall() col_names = [desc[0] for desc in cur.description] return rows, col_names, None except sqlite3.Error as e: return None, None, str(e) def format_answer_prompt(question, query, result): """Formats the prompt to get a final answer from the model based on SQL results.""" return ( "Given the following user question, corresponding SQL query, and SQL result, answer the user question.\n\n" "Reply with the user's language." "Question: {question}\n" "SQL Query: {query}\n" "SQL Result: {result}\n" "Answer: " ).format(question=question, query=query, result=result)
# src/prompting_text_to_sql.py import google.generativeai as genai import pandas as pd from src.config import API_KEY, DATABASE_DIR, MODEL_NAME, IMAGE_PROMPT_PATH import PIL.Image as PIL import logging from src.constants import prompt from src.utils import execute_sql_query, format_answer_prompt logging.basicConfig(level=logging.INFO) genai.configure(api_key=API_KEY) SYSTEM_INSTRUCTION = [ "You are an expert at translating natural language questions into SQL queries based on the AdventureWorks database described in the Schema Image, below.", "Pay close attention to the table names and columns, as they are crucial for executing accurate SQL queries.", ] LLM = genai.GenerativeModel(model_name=MODEL_NAME, system_instruction=SYSTEM_INSTRUCTION) def main(question): logging.info(f"Question: {question}") image_prompt = PIL.open(IMAGE_PROMPT_PATH) text_prompt = prompt[0] res = LLM.generate_content([text_prompt, question, image_prompt]) logging.info("Generating content using prompt engineering...") cleaned_sql = res.text.strip().strip("```").strip().strip("sqlite") logging.info(f'--LLM Responsed (SQL query)\n\n{cleaned_sql}') retry = False question_with_error = None if any(cmd in cleaned_sql.upper() for cmd in ["INSERT", "UPDATE", "DELETE"]): logging.warning("Data manipulation detected. Query not executed.") return cleaned_sql, None, "You are not allowed to manipulate the database.", retry, question_with_error rows, col_names, error = execute_sql_query(cleaned_sql, DATABASE_DIR) if error: logging.info('Retrying due to SQL error...') question_with_error = f'Dear this error caused: `{error}`\n{question}' logging.info(question_with_error) res = LLM.generate_content([text_prompt, question_with_error, image_prompt]) cleaned_sql = res.text.strip().strip("```").strip().strip("sqlite") logging.info(cleaned_sql) rows, col_names, _ = execute_sql_query(cleaned_sql, DATABASE_DIR) retry = True if rows is not None: if not rows: return cleaned_sql, None, "No results found.", retry, question_with_error df = pd.DataFrame(rows, columns=col_names) logging.info(f'Results:\n{df}') if df.empty: result_summary = "The answer is 0." elif len(df) > 10: result_summary = f"The table explains df.head() results:\n{df.head()}" elif df.shape[0] == 1 and df.shape[1] == 1: # single integer case result_summary = f'The answer is {df.iloc[0, 0]}' else: result_summary = df.to_string(index=False) # send to model using answer prompt answer = format_answer_prompt(question, cleaned_sql, result_summary) # final response final_response = LLM.generate_content([answer]) logging.info(f"Model's final answer:\n{final_response.text.strip()}") return cleaned_sql, df, final_response.text.strip(), retry, question_with_error return cleaned_sql, None, "No results found.", retry, question_with_error if __name__ == "__main__": question = "Provide a breakdown of total sales quantities by region and country for each year from 2015 to 2017, from highest to lowest" sql, df, final_answer, retry, question_with_error = main(question) print(f'TEST:\n\n{final_answer}')
Retrieval-Augmented Generation Approach
The RAG approach combines the power of the LLMs with an external retrieval mechanism to provide contextually relevant information to the model. By integrating this approach, we enable the model to enhance SQL generation with targeted context derived from a vector database. The RAG setup ensures that the model’s responses are not only precise but also contextualized within the AdventureWorks database schema and its relationships.
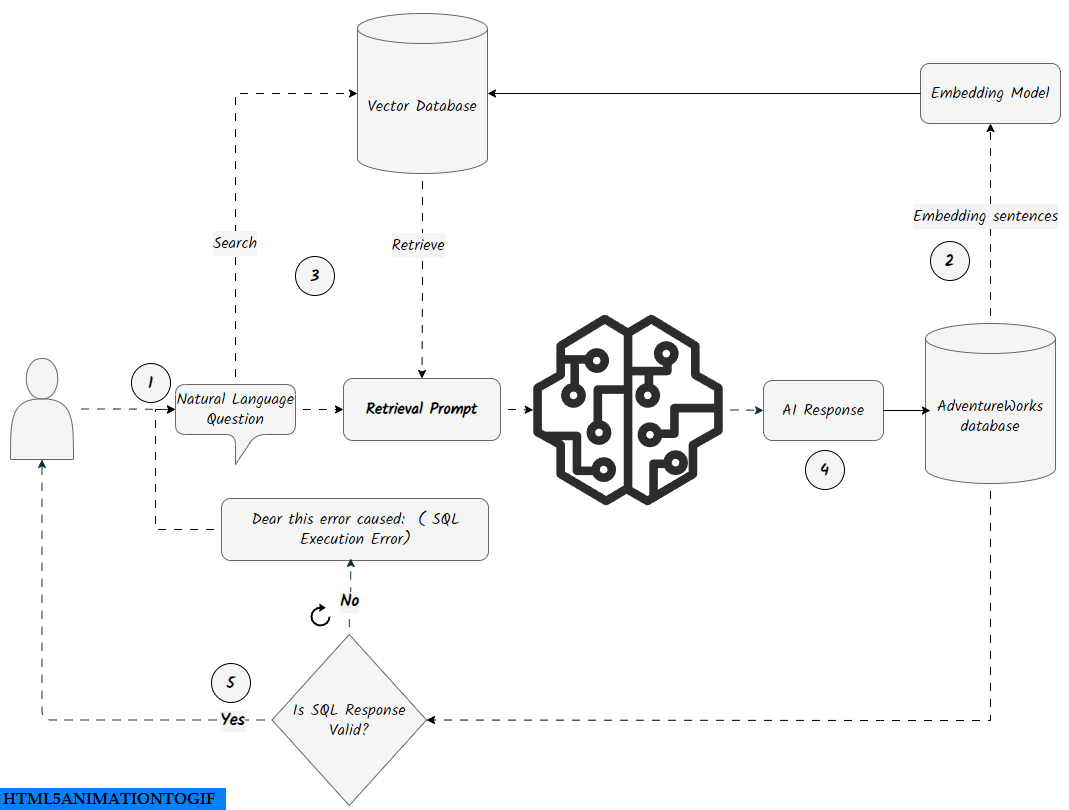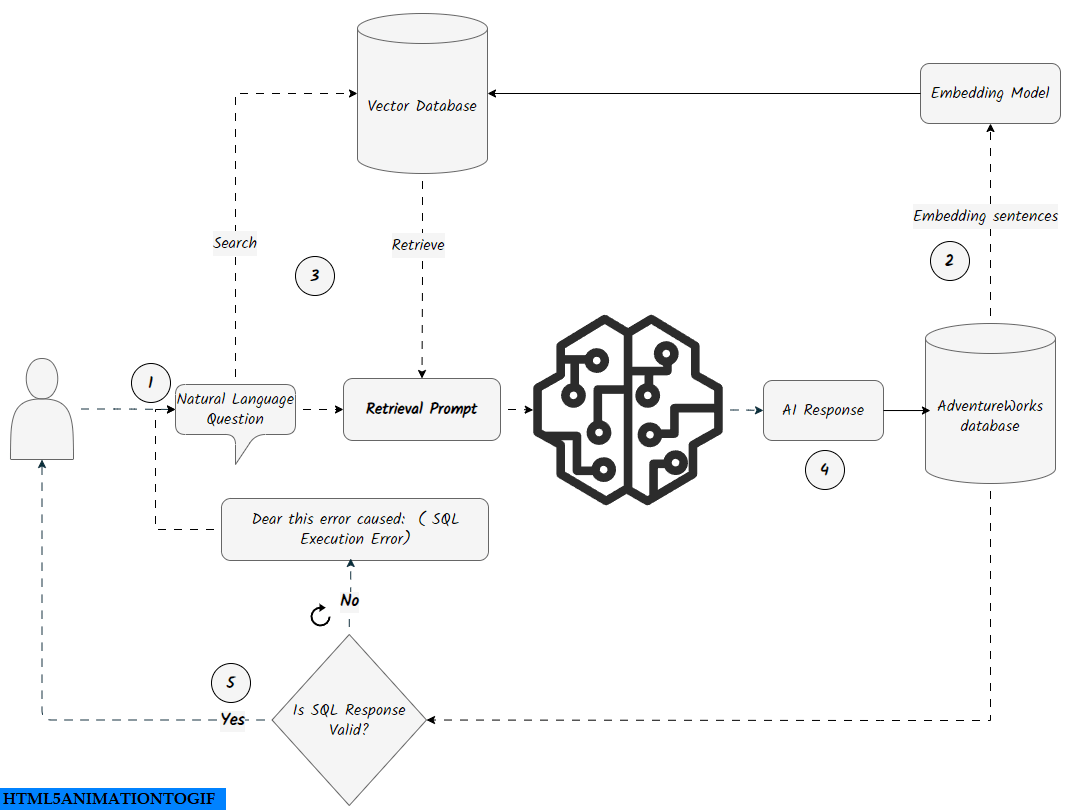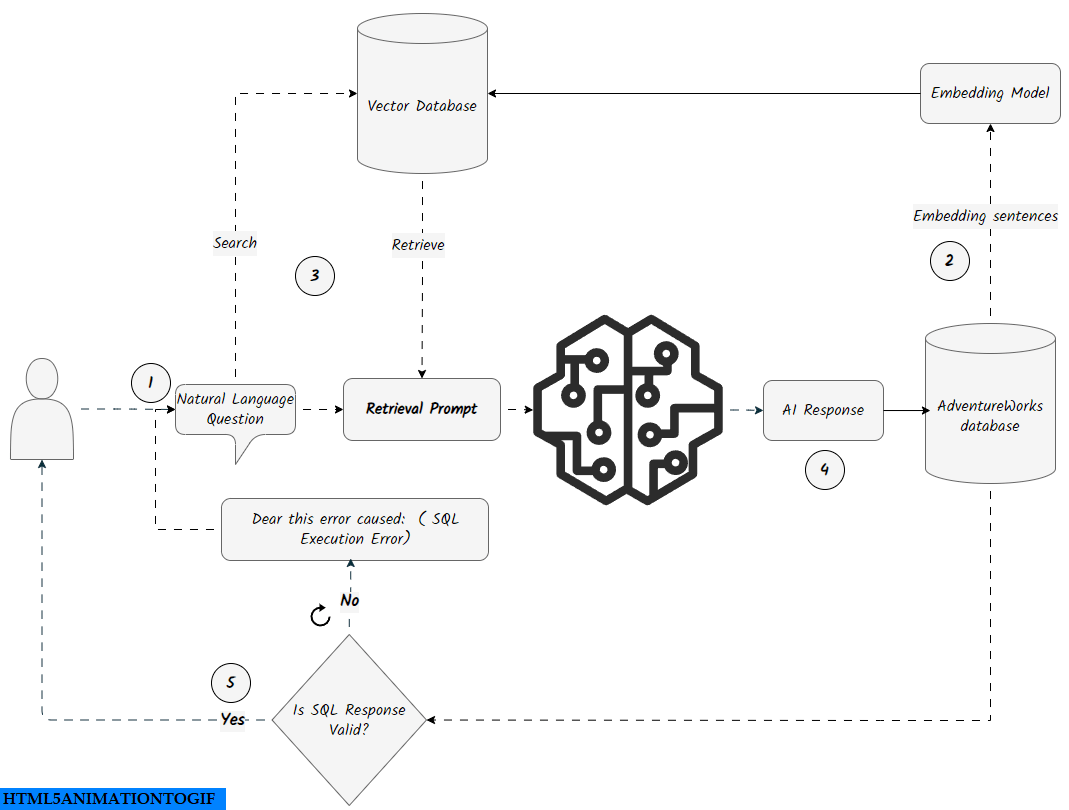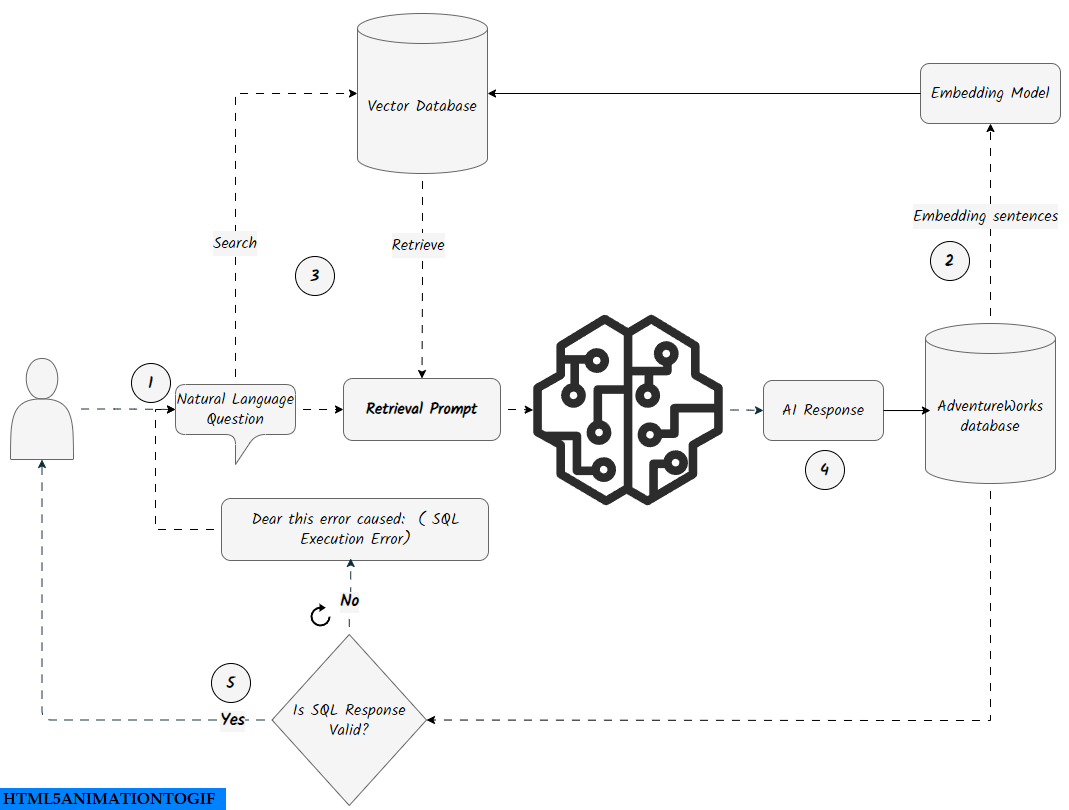
There are few additional components in this architecture that were not present in the previous Prompt Engineering Approach: creating a vector database and tables, inserting sentences into the tables, embedding sentences, and implementing a Retrieval-Augmented Generation (RAG) system with the vector database.
Vector Database:
Vector databases are like a magical sorting tool that helps you find the sentences embedded in it quickly. When you submit a sentence, the tool quickly looks through all the sentences and finds the ones that are closest to the sentence you submitted. This way, you can easily pick out the sentences you want without searching through the whole database. Vector databases store data as high-dimensional vector embeddings, capturing semantic meaning and relationships. They utilize specialized indexing techniques like hashing, quantization, and graph-based methods to enable fast querying and similarity searches
Setting up a client/server vector database can be done using various open-source libraries, such as FAISS, and Pinecone, or even frameworks like langchain and Vanna. For our Text-to-SQL task, we chose sqlite-vec, a vector search extension for SQLite. It provides custom SQL functions and virtual tables for efficient vector operations, enabling seamless integration of embedding models with SQL queries. This makes it a fitting choice for our architecture, combining ease of use with powerful retrieval capabilities. Check out this gist I created earlier, which includes the setup and usage of sqlite-vec along with Google’s generative AI for embeddings.
For embedding sentences, we used a well-known model developed by the Google DeepMind team, specifically models/embedding-001. We utilized the google.generativeai.embed_content function to embed TABLES, SENTENCES, and TABLES SCHEMAS. The following Python script demonstrates the creation of a vector database, the insertion of data, and the embedding of sentences for efficient retrieval of similar content.
# src/rag/vector_db.py from src.rag.documents import SENTENCES, TABLES, SCHEMAS from google.generativeai.embedding import embed_content import sqlite3 import sqlite_vec import struct from typing import List from src.config import EMBEDDING_MODEL import logging logging.basicConfig(level=logging.INFO) class VectorDatabase: def __init__(self, db_path: str = ":memory:"): self.db = sqlite3.connect(db_path) self.db.enable_load_extension(True) sqlite_vec.load(self.db) self.db.enable_load_extension(False) self.create_tables() self.insert_sentences() @staticmethod def serialize(vector: List[float]) -> bytes: """serializes a list of floats into a compact "raw bytes" format""" return struct.pack("%sf" % len(vector), *vector) def create_tables(self): self.db.execute( """ CREATE TABLE IF NOT EXISTS sentences ( id INTEGER PRIMARY KEY, sentence TEXT, table_name TEXT, schema_definition TEXT ); """ ) self.db.execute( """ CREATE VIRTUAL TABLE IF NOT EXISTS vec_sentences USING vec0( id INTEGER PRIMARY KEY, sentence_embedding FLOAT[768] ); """ ) def insert_sentences(self): with self.db: for i, sentence in enumerate(SENTENCES): table_name = TABLES[i] schema_definition = SCHEMAS[i] self.db.execute( "INSERT INTO sentences(id, sentence, table_name, schema_definition) VALUES(?, ?, ?, ?)", [i, sentence, table_name, schema_definition], ) def embed_sentences(self): with self.db: sentence_rows = self.db.execute( "SELECT id, sentence, table_name, schema_definition FROM sentences" ).fetchall() embeddings = embed_content( model=EMBEDDING_MODEL, content=[row[1] for row in sentence_rows], task_type="SEMANTIC_SIMILARITY", )["embedding"] logging.info(f"Number of sentence_rows: {len(sentence_rows)}") for (id, _, _, _), embedding in zip(sentence_rows, embeddings): self.db.execute( "INSERT INTO vec_sentences(id, sentence_embedding) VALUES(?, ?)", [id, self.serialize(embedding)], ) def retrieval(self, query: str, k: int = 3): query_embedding = embed_content( model=EMBEDDING_MODEL, content=query, task_type="RETRIEVAL_DOCUMENT", title="Return", )["embedding"] results = self.db.execute( """ SELECT vec_sentences.id, distance, sentences.sentence, sentences.table_name, sentences.schema_definition FROM vec_sentences LEFT JOIN sentences ON sentences.id = vec_sentences.id WHERE sentence_embedding MATCH ? AND k = ? ORDER BY distance """, [self.serialize(query_embedding), k], ).fetchall() logging.info(f"Number of retrievals: {len(results)}") return results # Example if __name__ == "__main__": db = VectorDatabase(':memory') db.embed_sentences() # retrieve the top 3 results based on the query results = db.retrieval("how many items were returned in 2024?", 5) for i, row in enumerate(results): index = results[i][0] distance = results[i][1] sentence = results[i][2] table_name = results[i][3] table_schema = results[i][4] # print details of the first retrieval if i == 0: print(f'First table matched: {table_name}, Distance {distance}') print(sentence)
The following script illustrates the implementation of a Retrieval-Augmented Generation (RAG) approach for converting text to SQL. It demonstrates the creation of a vector database, the insertion of data, and the embedding of sentences for efficient retrieval of similar content. This workflow is similar to our previous approach, but now the retrieval prompt is updated with data retrieved from the vector database.
# src/utils.py def create_rag_prompt(number_of_retrieval, retrieval, schema_info, top_k): """Creates a RAG prompt based on retrieved data, schema, and instructions.""" table_info = ", ".join([row[3] for row in retrieval]) sentence_info = "\n".join([row[2] for row in retrieval]) return ( "You are a SQL expert. Given an input question, generate a syntactically correct SQL query to execute, returning ONLY the generated query. Unless specified, limit the output to {top_k} rows.\n\n" "**Target Tables**: Focus on the top {number_of_retrieval} tables from the Vector Database: '{table_info}'.\n\n" "**Contextual Information**:\n" "{sentence_info}\n\n" "**Schema Overview**:\n" "{schema_info}\n\n" "**Instructions for Query Creation**:\n" "- Ensure the columns queried exist in the tables and use aliases only when necessary.\n" "- **Use Only Defined Schema**: Reference only the tables and columns specified in the schema." "- Always utilize SQLite-compatible date functions like `strftime('%Y', OrderDate)` for date manipulations.\n" "- For multiple conditions, effectively use logical operators (AND, OR).\n" "- Apply appropriate SQLite functions for date arithmetic and extractions.\n" "- Use GROUP BY with aggregate functions for any required data grouping.\n" "- Enhance readability with aliases for tables and columns in complex joins or subqueries.\n" "- Employ subqueries or common table expressions (CTEs) as needed to simplify queries.\n" "- Note that the database holds data only until 2017.\n\n" "**Example Queries**:\n\n" "1. Find the 10 cheapest products in ascending order:\n" "SELECT ProductName, ProductPrice FROM products ORDER BY ProductPrice ASC LIMIT 10;\n" "2. Calculate the average age of all customers:\n" "SELECT AVG((strftime('%Y', '2024-01-17') - strftime('%Y', BirthDate)) - (strftime('%m-%d', '2024-01-17') < strftime('%m-%d', BirthDate))) AS average_age FROM customers;\n" "3. List all customers whose annual income is less than 20,000 and who bought products in 2015:\n" "SELECT FirstName, LastName, AnnualIncome, ProductName, YEAR(OrderDate) AS Year FROM sales_2015 JOIN products ON sales_2015.ProductKey = products.ProductKey JOIN customers ON sales_2015.CustomerKey = customers.CustomerKey WHERE AnnualIncome < 20000;" ).format( number_of_retrieval=number_of_retrieval, table_info=table_info, schema_info=schema_info, sentence_info=sentence_info, top_k=top_k, )
# src/rag_text_to_sql.py import google.generativeai as genai import pandas as pd from src.config import API_KEY, DATABASE_DIR, MODEL_NAME import logging from src.rag.vector_db import VectorDatabase from src.constants import schema_info from src.utils import create_rag_prompt, execute_sql_query, format_answer_prompt logging.basicConfig(level=logging.INFO) genai.configure(api_key=API_KEY) SYSTEM_INSTRUCTION = [ "You are an expert SQL translator. Your primary task is to convert natural language questions into precise and optimized SQL queries. When given a question, follow these guidelines:", "1. **Identify the Intent**: Understand what the user is trying to achieve.", "2. **Date Functions**: Use SQLite-compatible date functions such as `strftime('%Y', OrderDate)` to extract components from dates.", "3. **Schema Awareness**: Familiarize yourself with the database schema, including primary and foreign keys.", "4. **Efficiency**: Aim for optimized queries, minimizing resource usage." ] LLM = genai.GenerativeModel(model_name=MODEL_NAME, system_instruction=SYSTEM_INSTRUCTION) def get_vector_db_retrieval(question, k=3): vec_db = VectorDatabase() vec_db.embed_sentences() return vec_db.retrieval(query=question, k=k) def main(question, number_of_retrieval=3): logging.info(f"Question: {question}") retrieval = get_vector_db_retrieval(question, k=number_of_retrieval) top_k = 10 # number of lines to return rag_prompt = create_rag_prompt(number_of_retrieval, retrieval, schema_info, top_k) res = LLM.generate_content([rag_prompt, question]) logging.info("Generating content using RAG prompt...") cleaned_sql = res.text.strip().strip("```").strip().strip("sqlite") logging.info(f'--LLM Responsed (SQL query)\n\n{cleaned_sql}') retry = False question_with_error = None if any(cmd in cleaned_sql.upper() for cmd in ["INSERT", "UPDATE", "DELETE"]): logging.warning("Data manipulation detected. Query not executed.") return retrieval, cleaned_sql, None, "You are not allowed to manipulate the database.", retry, question_with_error rows, col_names, error = execute_sql_query(cleaned_sql, DATABASE_DIR) if error: logging.info('Retrying due to SQL error...') question_with_error = f'Dear this error caused: `{error}`\n{question}' logging.info(question_with_error) res = LLM.generate_content([question_with_error, schema_info]) cleaned_sql = res.text.strip().strip("```").strip().strip("sqlite") logging.info(cleaned_sql) rows, col_names, _ = execute_sql_query(cleaned_sql, DATABASE_DIR) retry = True if rows is not None: if not rows: return retrieval, cleaned_sql, None, "No results found.", retry, question_with_error df = pd.DataFrame(rows, columns=col_names) logging.info(f'Results:\n{df}') if df.empty: result_summary = "The answer is 0." elif len(df) > 10: result_summary = f"The table explains df.head() results:\n{df.head()}" elif df.shape[0] == 1 and df.shape[1] == 1: # single integer case result_summary = f'The answer is {df.iloc[0, 0]}' else: result_summary = df.to_string(index=False) # send to model using answer prompt answer = format_answer_prompt(question, cleaned_sql, result_summary) # final response final_response = LLM.generate_content([answer]) logging.info(f"Model's final answer:\n{final_response.text.strip()}") return retrieval, cleaned_sql, df, final_response.text.strip(), retry, question_with_error return retrieval, cleaned_sql, None, "No results found.", retry, question_with_error if __name__ == "__main__": question = "Provide a breakdown of total sales quantities by region and country for each year from 2015 to 2017, from highest to lowest" retrieval, sql, df, final_response, retrying, question_with_error = main(question)
Streamlit Application
The Streamlit app is designed to bridge the gap for non-technical users who may find SQL daunting. Users can ask analytical questions related to the AdventureWorks database, utilizing table schemas retrieved from the metadata store. The app incorporates both methods discussed in the methodology section across two separate pages: the Prompt Engineering Approach and the Retrieval-Augmented Generation (RAG) Approach.
View (live demonstration)
When a user submits a question through the application, it is sent to the language model, which returns a SQLite query to be executed against the AdventureWorks database. The results are displayed in a dataframe, along with a textual summary from the model. If the SQL query is valid but returns no relevant results, the app will indicate this. For example, when the question Give me the sales data in 2024 please was submitted, both apps gave similar results, indicating that the database does not contain any sales data for 2024. In cases where the SQL query executed correctly from a table but returned no results, the app could say, "No results were found."
The application also alerts users if an error occurs during validation, displaying the SQL error message and resubmitting the query to the model. On the RAG page, the first retrieved related data from the vector database will be shown.
The following scripts demonstrate the app's development using Streamlit and st_pages
# app.py import streamlit as st import PIL.Image as PIL from st_pages import add_page_title, get_nav_from_toml def intro(): """Main Home page intro""" st.header("**Welcome to the AdventureWorks-Database!**") with st.expander("About the app"): st.info( "- This app uses Google [Gemini Flash](https://developers.googleblog.com/en/gemini-15-flash-8b-is-now-generally-available-for-use/) to convert natural language questions into SQL queries. \n" "- The **Prompt Engineering** method leverages a model trained with the database schema and ERD to ensure accurate query generation. \n" "- The **RAG** method enhances query accuracy by retrieving relevant context from a database before generating responses. \n" ) st.success( "- The app executes the generated SQL queries on a SQLite3 database and displays both the queries and the results. \n" "- If an error occurs during execution, the app automatically resubmits the original question along with the error message for improved accuracy. \n" "- You can explore the database structure to formulate relevant questions or click 'Random Questions'" ) def main(): """Main function to run the Streamlit app.""" st.set_page_config( page_title="Test to SQL Generator — by Ahmed Salim", page_icon=PIL.open("app/ui/static/favicon.ico"), layout="wide", ) st.markdown('<div class="main-content">', unsafe_allow_html=True) intro() rag = True nav = get_nav_from_toml( "app/.streamlit/pages_sections.toml" if rag else "app/.streamlit/pages.toml" ) st.logo("app/ui/static/favicon.ico") pg = st.navigation(nav) add_page_title(pg) pg.run() st.markdown("</div>", unsafe_allow_html=True) with open("app/ui/footer.html", "r", encoding="utf-8") as f: footer_content = f.read() st.markdown(footer_content, unsafe_allow_html=True) if __name__ == "__main__": main()
# app/_pages/utils.py import streamlit as st import random from src.constants import random_questions def init_values(key, value=None): """ set a key in st.session_state to a given value if it does not already exist session_states: https://docs.streamlit.io/develop/api-reference/caching-and-state/st.session_state """ if key not in st.session_state: st.session_state[key] = value def random_question(): question = random.choice(random_questions) st.session_state.question = question st.markdown(question) return question def validate_question(question): if not question: st.warning("Please write a question, or submit a random question.") return False return True
# app/_pages/prompt_page.py import streamlit as st from src.prompting_text_to_sql import main as handle_question_with_prompt from app._pages.utils import * c1, c2 = st.columns([5, 5]) init_values("final_response", "") init_values("question", "") init_values("sql", "") init_values("df", None) with c1: question = st.text_area("Your Question:", key="input", height=100) col1, col2, _ = st.columns([5, 5, 21], vertical_alignment="top") with col1: question_button = st.button("Ask a question") with col2: random_button = st.button("Random question") if random_button: question = random_question() if question_button or random_button: if validate_question(question): st.session_state.question = question st.session_state.sql, st.session_state.df, st.session_state.final_response, retrying, question_with_error = ( handle_question_with_prompt(question) ) if st.session_state.sql.startswith(("INSERT", "UPDATE", "DELETE")): # STILL UNDER DEVELOPMENT st.warning("You are not allowing to manipulate the database.") else: if retrying: st.info("Retrying with additional context...") if question_with_error: with st.expander("AI response (SQL query)", expanded=False): with st.chat_message("ai"): st.code(st.session_state.sql, language="sql") with st.chat_message("user"): st.write(f"{question_with_error}") if st.session_state.sql: st.markdown("##### AI response (SQL query)") st.code(st.session_state.sql, language="sql") if st.session_state.df is not None: st.markdown("##### SQL response (Query results)") st.dataframe(st.session_state.df) with c2: with st.expander("AdventureWorks Schema"): st.image("rdbms/adventureworks_schema.png") with st.expander("Prompting framework"): st.image("app/ui/static/prompt-engineering.gif") if st.session_state.final_response: st.markdown("##### Final LLM Answer") with st.chat_message("ai"): st.write(st.session_state.final_response)
# app/_pages/rag_page.py import streamlit as st from src.rag_text_to_sql import main as handle_question_with_rag from app._pages.utils import * c1, c2 = st.columns([5, 5]) init_values("final_response_2", "") init_values("retrieval", None) init_values("sql_2", "") init_values("df_2", None) init_values("question_2", "") def data_retrieved(retrieval): for i, _ in enumerate(retrieval): # index = retrieval[i][0] distance = retrieval[i][1] sentence = retrieval[i][2] table_name = retrieval[i][3] table_schema = retrieval[i][4] # return first retrieval data only if i == 0: return distance, sentence, table_name, table_schema with c1: question = st.text_area("Your Question:", key="input", height=100) col1, col2, _ = st.columns([5, 5, 21], vertical_alignment="top") with col1: question_button = st.button("Ask a question") with col2: random_button = st.button("Random question") if random_button: question = random_question() if question_button or random_button: if validate_question(question): st.session_state.question_2 = question ( st.session_state.retrieval, st.session_state.sql_2, st.session_state.df_2, st.session_state.final_response_2, retrying, question_with_error, ) = handle_question_with_rag(question, number_of_retrieval=3) if st.session_state.sql_2.startswith(("INSERT", "UPDATE", "DELETE")): # STILL UNDER DEVELOPMENT st.warning("You are not allowing to manipulate the database.") else: if retrying: st.info("Retrying with additional context...") if question_with_error: with st.expander("AI response (SQL query)", expanded=False): with st.chat_message("ai"): st.code(st.session_state.sql_2, language="sql") with st.chat_message("user"): st.write(f"{question_with_error}") if st.session_state.sql_2: st.markdown("##### AI response (SQL query)") st.code(st.session_state.sql_2, language="sql") if st.session_state.df_2 is not None: st.markdown("##### SQL response (Query results)") st.dataframe(st.session_state.df_2) with c2: with st.expander("AdventureWorks Schema"): st.image("rdbms/adventureworks_schema.png") with st.expander("RAG framework"): st.image("app/ui/static/rag.gif") if st.session_state.final_response_2 and st.session_state.retrieval is not None: distance, sentence, table_name, table_schema = data_retrieved( st.session_state.retrieval ) with st.expander( "View data retrieved from the vector database", expanded=False ): options = st.selectbox( label="Select an option", options=["Table", "Table Schema", "Sentence"], ) if options == "Table": st.markdown( f"The first table retrieved is **`{table_name}`** with a distance of **`{distance}`**" ) if options == "Sentence": st.info(sentence) elif options == "Table Schema": st.code(table_schema, language="sql") st.markdown("##### Final LLM Answer") with st.chat_message("ai"): st.write(st.session_state.final_response_2)
Future Learning
The architecture can be improved by integrating additional techniques or modifying existing methods. Researchers could focus on creating relevant sentences to add to the vector database, as increasing data is essential for enhancing language model performance. In fact, these language models could be fine-tuned if there were sufficient relevant datasets available.
Currently, we are using an in-memory vector database that is created only when a question is asked and contains only 10 rows (sentences, table names, and table schemas), corresponding to our 10 tables. However, there’s a potential enhancement: instead of relying solely on an in-memory vector database, we could implement a fixed vector database that get updated with the correct questions asked to the model and retrieved accurate results. This approach could expand the data stored in the vector database, ensuring that similar questions from new users are prioritized in retrieval.
As for the app, it can be enhanced by making the LLM more interactive, essentially creating a chatbot. Techniques like InMemoryChatMessageHistory and ConversationChain from LangChain could be used to build an in-memory implementation of chat message history, making the model learns about previous questions, the database, and ultimately improving the overall user experience.
Conclusion
In conclusion, our exploration of text-to-SQL transformation highlights the transformative potential of Generative AI in making data querying accessible to non-technical users. By leveraging advancements in natural language processing and large language models, we have demonstrated how natural language queries can be effectively converted into accurate SQL commands. The two methodologies discussed—Prompt Engineering and Retrieval-Augmented Generation (RAG)—each provide unique advantages in enhancing SQL query generation, thereby streamlining interactions with databases like AdventureWorks. The implementation of these approaches not only facilitates intuitive data access but also empowers users to engage with complex datasets without requiring deep technical expertise. As organizations continue to generate vast amounts of data, the integration of these AI-driven solutions represents a significant step toward democratizing data analytics, ultimately leading to more informed decision-making across various sectors. The accompanying source code and deployed application serve as practical resources for further exploration and application of these methodologies.
Reference
- Marr, Bernard. "The difference between generative AI and traditional AI: An easy explanation for anyone." Forbes, 2023a. Disponível em: Acesso em 16 (2023)
- Spair, Rick. "Generative AI Smackdown: AWS, Azure, and GCP Battle it Out." November 8, 2023. AI & DX strategist with decades of practical field expertise
- Reid, Machel, et al. "Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context." arXiv preprint arXiv.05530 (2024)
- Prompt Engineering vs Fine-Tuning vs RAG." MyScale, March 26, 2024.
- Lee, Jinhyuk, et al. "Gecko: Versatile text embeddings distilled from large language models." arXiv preprint arXiv.20327 (2024)
- Garcia, Alex. "Introducing sqlite-vec v0.1.0: A Vector Search SQLite Extension That Runs Everywhere." Alex Garcia's Blog, August 1, 2024
The source code for the project is available in this GitHub repository, and the deployed app can be accessed here.