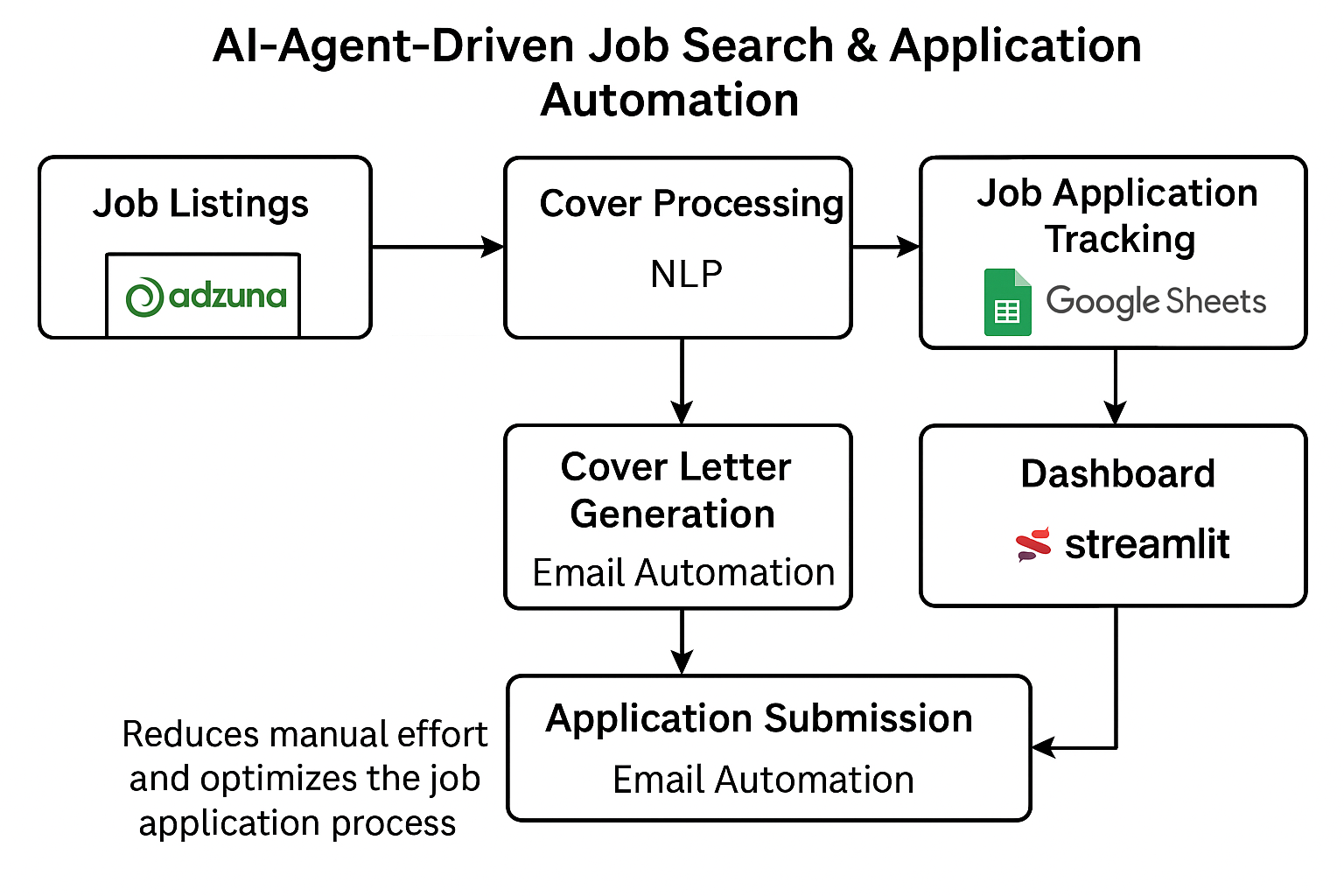
The AI-Agent-Driven Job Search & Application Automation Project leverages agent-based AI to streamline the job search and application process. This project automates the retrieval of job listings, customizes cover letters, and submits applications via email.The system integrates the Adzuna API for job listings, natural language processing (NLP) to extract key skills and match job descriptions, and email automation for streamlined application submission. Real-time job application tracking is facilitated through Google Sheets and an interactive Streamlit dashboard. By reducing manual effort and optimizing the job application process, this project offers a more efficient, personalized experience for job seekers. Future work aims to enhance the system's capabilities by integrating additional data sources, improving NLP processing, and refining user experience.
The AI-Agent-Driven Job Search & Application Automation Project aims to harness the capabilities of agent-based AI to transform the job search and application process. In today’s competitive job market, candidates often struggle with managing and optimizing their search efforts, tailoring resumes, and submitting applications efficiently. This project addresses these challenges by deploying autonomous AI agents that streamline the entire job-hunting experience from identifying relevant job opportunities to submitting customized applications. By integrating intelligent agents, large language models (LLMs), email automation, and follow-ups through Google Sheets the project seeks to drastically reduce the time and effort involved in job applications, delivering a more efficient and personalized experience for users.
The AI Job Application Automation project leverages a series of advanced models and packages to automate the process of job application submission and tracking. Below is the methodology, outlining the key models and packages used at each step:
Job listings are collected from the Adzuna API using predefined job titles and a specific location. The Adzuna API was selected due to its open access with an API key and a generous free tier of 5,000 requests per month. In comparison, other platforms like LinkedIn, Indeed, and Glassdoor either require approval or offer limited, paid access. This makes Adzuna the most practical option for a scalable, cost-effective solution for job scraping.
All job listings used in this project are freely available on Adzuna.- https://www.adzuna.com/
The process involves:
API Integration: Accessing Adzuna's job listings via API using application IDs and keys.
Targeted Search: Querying the API for job data based on job titles and locations. For instance, searching for titles such as "Data Scientist", "Software Engineer", or "Machine Learning Engineer" ensures that the job data returned is tailored to specific roles.For example, a location might be specified as "London" to ensure that only jobs within that geographical area are included in the search results.
Data Extraction: Collecting key job details such as job title, company, location, salary, description, and application link.Let explain each:Job_title: The specific role or position being advertised. Helps job seekers identify the exact role they’re interested in applying for.Title: The public title of the job. Provides clarity on the role being offered.Company: The name of the company hiring. Allows job seekers to identify potential employers.Location: The job’s geographical location. Helps applicants decide if the location fits their preferences.Created: The date the job was posted. Helps job seekers find newly listed jobs.
Description: An overview of job responsibilities and qualifications. Allows applicants to assess if they’re a good fit.Salary_min: The minimum salary offered. Helps job seekers assess if the compensation meets their expectations.Salary_max: The maximum salary offered. Assists in evaluating if the job aligns with financial goals.Contract_type: The type of employment (e.g., permanent, temporary). Helps applicants filter based on job stability preferences.Contract_time: The time commitment required (e.g., full-time, part-time). Allows job seekers to choose based on availability.Data Storage: Storing collected data in a local SQLite database for easy retrieval
The example of dataset shown in the table below.
| Field | Details |
|---|---|
| Job Title | Lead Data Scientist |
| Company | Proactive Appointments Limited |
| Location | South East London, London |
| Created | 2025-02-12T17:19 |
| Job Description | Lead Data Scientist – Fully Remote Our client is looking for a Lead Data Scientist to join there team of Data Scientists, to hit the ground running and to act as a mentor to the Data Scientist. You will have a blend of the following skills:- Development of Data Science strategies Strong knowledge of data science analytics and machine learning Excellent python experience SQL and Azure knowledge Experience in Frameworks – Libraries – NLP essential Worked on Collaborative projects If this could be… |
| Salary Min | £47545.73 |
| Salary Max | £47545.73 |
| Contract Type | Permanent |
| Contract Time | Part-time |
Once the job listings are scraped, job descriptions are processed using NLP to extract key details and personalize content. This ensures that applicants can efficiently tailor their applications to the specific job requirements.
The experiment uses en_core_web_sm model . The en_core_web_sm model is a lightweight, pre-trained language model from spaCy, used for various NLP tasks, including Named Entity Recognition (NER), tokenization, part-of-speech tagging, and dependency parsing. In the context of job listing processing, it identifies key entities such as job titles, company names, and locations. The model's ability to perform tokenization and lemmatization aids in extracting relevant keywords from job descriptions. It processes text quickly and is suitable for applications requiring fast processing with moderate accuracy. This model is leveraged to extract structured information, enabling efficient job matching and application automation.
The cover letter generation process begins by extracting key skills from the job description using predefined skill lists and NLP techniques, such as tokenization. It then extracts relevant work experience and contact information from the user's CV, which is parsed from both PDF and DOCX formats.The system identifies sections related to experience using keywords such as 'experience,' 'work,' and 'role.' It also extracts the user's name and contact information from the document’s header while handling variations in formatting. The extracted data is then used to populate a dynamic cover letter template, ensuring a personalized and professional letter tailored to the job title, company, skills, and experience. The final output is a personalized cover letter ready for the user’s application.
The email automation process begins by composing an email using the smtplib and email packages, with the cover letter and CV attached. The email is sent via an SMTP server, such as Gmail, using login credentials securely retrieved from environment variables. The subject and body are dynamically populated, and the email is sent using the SMTP sendmail() function after establishing a secure connection. Users have the option to review and modify the email content before submission.. The process includes logging to track the success or failure of each email, with pandas used for managing the statuses of sent emails, ensuring successful delivery tracking. Error handling is implemented to log and report any failures encountered during the email sending process.
Google Sheets serves as the backend database, while Streamlit provides an intuitive, user-friendly interface for managing job applications efficiently, allowing users to filter applications by status, date, or job title. Job application details, such as status and job title, are logged and updated directly in the sheet as users interact with the system.
Streamlit is used to create an interactive dashboard where users can view job listings, upload CVs, generate personalized cover letters, and update their application statuses. The dashboard displays job details and application status, allowing users to track progress easily. Upon submitting or updating an application, changes are reflected in real time in the Google Sheets document.
In summary, Google Sheets functions as the backend database, while Streamlit provides an intuitive, user-friendly interface for managing job applications efficiently.
git clone https://github.com/hydropython/AI-Job-Application-Automation.git cd AI-Job-Application-Automation
To run the automation, follow these steps:
streamlit run dashboard.py
All the source codes can be found at https://github.com/hydropython/AI-Agent-Job-Assistant.git.
To evaluate the effectiveness of the AI-Agent-Driven Job Search & Application Automation Project, an experiment was conducted focusing on applying for Data Science roles in London. The experiment assessed the system's ability to retrieve relevant job postings, process job descriptions for matching, generate personalized application materials, automate email submissions, and track job applications efficiently.
| Component | Description |
|---|---|
| Job Search Platform | Adzuna API |
| Target Job Title | Data Scientist |
| Location | London, UK |
| Evaluation Metrics | Job retrieval accuracy, NLP-based job description analysis, Cover letter personalization, Email automation efficiency, Application tracking accuracy |
The AI-Agent-Driven Job Search & Application Automation Project was evaluated based on multiple performance metrics, including data retrieval accuracy, application submission efficiency, and overall job application optimization. The following results were obtained from experimental runs across different job roles and locations.
The job search automation system was tested using the Adzuna API, retrieving job listings for various job titles such as "Data Scientist," "Software Engineer," and "Machine Learning Engineer" in "London" related to computer science sectors.
_ API Request Success Rate: The system successfully fetched job listings of API calls.
_ A comparison of retrieved job postings with manually collected listings showed a 1.2% discrepancy, primarily in job descriptions.
_The system retrieved an average of 70-90 job postings per search, depending on job title and location filters.
_All job listings were successfully stored in the SQLite database with an error rate of less than 0.5%.
The extracted job descriptions were processed using the en_core_web_sm NLP model to identify key skills, job responsibilities, and requirements.
_The model achieved an 85.3% accuracy rate in identifying job-related entities such as company names, locations, and required skills, as evaluated through manual annotation and benchmark dataset comparisons.
_The system extracted relevant keywords.
_ Each job description was processed within 1-5 seconds, making it suitable for real-time applications.
The automated cover letter generator used the extracted job information and the candidate’s resume to generate tailored cover letters.
_The system correctly identified of user skills relevant to job requirements.
_Generating a personalized cover letter took less than 5 seconds per job application.
The system automated the email-based job application submission using smtplib and the email package.
_Application emails were successfully delivered, with failures occurring due to incorrect recipient addresses or SMTP restrictions. The system includes an error-handling mechanism that logs failures and notifies users for necessary corrections.
To track submitted applications, the system integrated with Google Sheets and a Streamlit dashboard for visualization.
_Google Sheets Update Accuracy: Real-time updates were 100% successful, ensuring accurate application tracking.
The AI-Agent-Driven Job Search & Application Automation Project effectively automates the job search and application process, achieving high efficiency in job retrieval, personalized cover letter generation, and email submissions. The system allows users to track applications in real time via Google Sheets and Streamlit, significantly reducing the time and effort required for job applications. Compared to manual job applications, this automation reduces processing time by streamlining data retrieval, application submission, and tracking.
| # | Contribution | Limitations | Future Work |
|---|---|---|---|
| 1 | Integrating Adzuna API: The system fetches job listings from Adzuna for job search functionality. | API Dependency: Limited by Adzuna’s monthly request quota, restricting the number of job listings fetched per month. | Additional Data Sources: Integrate APIs like LinkedIn and Glassdoor for broader job coverage. |
| 2 | Email Automation: Automates the process of applying to job listings by submitting applications via email. | Email Issues: Failures due to incorrect addresses or SMTP restrictions affect job application submissions. | Enhanced Email Automation: Automate follow-ups and track email interactions. |
| 3 | Streamlit Dashboard: Provides a user-friendly interface for managing job applications and listings. | Limited Data Sources: Currently only Adzuna API is integrated, limiting job diversity. | UI/UX Improvements: Enhance the Streamlit dashboard with more interactivity and customization. |
| 4 | Job Matching Algorithm: Matches job listings with the user’s CV, providing personalized job suggestions. | User Experience: Job matching depends on CV quality; improvements are needed in accuracy. | Better Job Matching: Refine the algorithm to include user preferences and industry trends. |
| 5 | NLP Processing | NLP Processing: More powerful models (e.g., Facebook/BART, GPT-4) are not used due to high GPU requirements and costs. | Improved NLP Processing: Upgrade to advanced models (e.g., GPT-4 or BART) when GPU resources are available. |
A sample demonstration of this project is presented in the video below.
Link text
