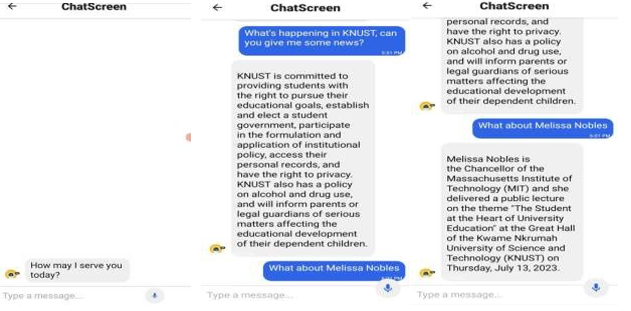
This project presents a university enquiry chatbot solution tailored for incoming students at **Kwame Nkrumah University of Science and Technology (KNUST). Developed as a capstone project, the chatbot leveraged LlamaIndex and OpenAI GPT-3 to provide conversational responses to common inquiries from freshmen.
At the time of development, frameworks such as LangChain and LlamaIndex were just gaining traction, and the modality of Generative AI (GenAI) applications was still evolving. Tools for building agents with seamless web scraping and data retrieval capabilities were not readily available.
The project relied on manual web scraping, implemented through custom Python functions, and utilized the scheduler library to periodically update the dataset. These limitations required innovative problem-solving and early adoption of GenAI techniques.
Future additions and features to this project will include a location-based search functionality, allowing users to request specific locations on campus using the Google Maps API, and an integrated speech-to-text feature to enhance accessibility and user convenience.
Other potential multimodal features include text-to-speech integration for voice-assisted responses, image recognition for campus landmarks to identify and provide information about campus locations, making it a versatile tool for students.
Freshmen at KNUST often face significant challenges in accessing timely and accurate information about registration processes, campus facilities, academic programs, and extracurricular activities.
These difficulties are exacerbated by the overwhelming demand placed on administrative staff during peak enrollment periods, leading to delays and frustration for students.
The absence of a centralized, intelligent system for handling student queries left a critical gap in addressing the needs of incoming students. This gap created an opportunity to explore the application of conversational AI to provide accurate, personalized assistance.
The absence of automated, end-to-end solutions for building such systems created a pressing need for innovative approaches to developing a chatbot capable of providing accurate, context-aware, and conversational assistance to new students.
This work demonstrates how early GenAI techniques bridged this gap and foreshadows the possibilities offered by the rapid evolution of GenAI tools and frameworks.
The methodology for this project involved a structured approach across four key stages: data preprocessing, data encoding, model evaluation, and response generation. Data was collected and cleaned from various sources, including KNUST guides, websites, and third-party files, and organized into a structured knowledge base. Using LlamaIndex, the data was indexed with vector embeddings for efficient retrieval.
The GPT-3 text-davinci-003 model was selected and fine-tuned for its contextual awareness and conversational response capabilities. Real-time query processing was implemented through FastAPI, while Firebase and React Native facilitated user authentication and a seamless frontend experience.
This framework ensured accurate, context-aware, and user-friendly interactions.
pip install APScheduler
pip install beautifulsoup4
import bs4 as bs import urllib.request import time from apscheduler.schedulers.blocking import BlockingScheduler
# Function to perform text preprocessing on the document def preprocess_document(document): # Remove special characters, URLs, and numbers document = re.sub(r'http\S+|www.\S+', '', document) # Remove URLs document = re.sub(r'\d+', '', document) # Remove numbers document = re.sub(r'[^\w\s]', ' ', document) # Remove special characters except whitespace # Convert all text to lowercase document = document.lower() # Remove extra whitespaces document = re.sub(r'\s+', ' ', document).strip() # Add any other preprocessing steps you may need, such as removing stopwords, stemming, etc. return document
import requests import time from apscheduler.schedulers.background import BackgroundScheduler
# Function to scrape the website and save the data to a file with a specific title def scrape_website(): url = 'https://www.knust.edu.gh/' response = urllib.request.urlopen(url) html_content = response.read() # Taking the data out of the site using beautiful soup data = bs.BeautifulSoup(html_content, 'lxml') data_paragraphs = data.find_all('p') data_text = '' for para in data_paragraphs: data_text += para.text # Perform text preprocessing preprocessed_data_text = preprocess_document(data_text) # Add the title to the document desired_title = "KNUST News" # Replace "KNUST News" with your desired title document_with_title = f"# {desired_title}\n\n{preprocessed_data_text}" filename = r'/content/drive/MyDrive/Web crawler/KNUST News.txt' with open(filename, 'w', encoding='utf-8') as file: file.write(document_with_title)
def job(): print("Scraping the website...") scrape_website() scheduler = BackgroundScheduler() scheduler.add_job(job, "interval", seconds = 5) scheduler.start() for i in range(5): #print(i) time.sleep(1)
!pip install PyPDF2
from google.colab import drive drive.mount('/content/drive')
import pandas as pd import PyPDF2 import re def extract_text_from_pdf(pdf_path): with open(pdf_path, "rb") as f: reader = PyPDF2.PdfReader(f) num_pages = len(reader.pages) text = "" for page_num in range(num_pages): page = reader.pages[page_num] text += page.extract_text() return text def remove_non_alphanumeric(text): cleaned_text = re.sub(r'[^a-zA-Z0-9\s]', '', text) return cleaned_text if __name__ == "__main__": # Specify the path to your PDF file pdf_path = "/content/drive/MyDrive/Case Study1/Student Guide.pdf" # Extract text from the PDF text = extract_text_from_pdf(pdf_path) # Remove non-alphanumeric characters cleaned_text = remove_non_alphanumeric(text) # Print the cleaned text print(cleaned_text)
import os import pandas as pd import PyPDF2 import re def extract_text_from_pdf(pdf_path): with open(pdf_path, "rb") as f: reader = PyPDF2.PdfReader(f) num_pages = len(reader.pages) text = "" for page_num in range(num_pages): page = reader.pages[page_num] text += page.extract_text() return text def remove_non_alphanumeric(text): cleaned_text = re.sub(r'[^a-zA-Z0-9\s]', '', text) return cleaned_text if __name__ == "__main__": # Specify the directory containing your PDF files pdf_directory = "/content/drive/MyDrive/KnowledgeBase" # Specify the directory to save the output text files output_directory = "/content/drive/MyDrive/KnowledgeBase" # Iterate through each PDF file in the directory for filename in os.listdir(pdf_directory): if filename.endswith(".pdf"): pdf_path = os.path.join(pdf_directory, filename) # Extract text from the PDF text = extract_text_from_pdf(pdf_path) # Remove non-alphanumeric characters cleaned_text = remove_non_alphanumeric(text) # Save the cleaned text to a text file output_text_path = os.path.join(output_directory, filename.replace(".pdf", ".txt")) with open(output_text_path, 'w', encoding='utf-8') as text_file: text_file.write(cleaned_text) print("Converted:", pdf_path, "to", output_text_path)
Document Organization and Indexing:
docstore.json: Stored indexed text content.vector_store.json: Contained vector embeddings for retrieval.index_store.json: Maintained index IDs.graph_store.json: Represented relationships between data points.Efficient Data Retrieval:
!pip install langchain
!pip install openai
!pip install gpt_index
pip install llama-index==0.7.11.post1
from llama_index import SimpleDirectoryReader, GPTVectorStoreIndex, LLMPredictor, PromptHelper from llama_index import StorageContext, load_index_from_storage import openai openai.api_key = input("Paste your OpenAI key here and press enter") #openai.api_key = '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' import os # os.environ['OPENAI_API_KEY'] = openai.api_key from langchain import OpenAI import sys import os from IPython.display import Markdown, display def construct_index(directory_path): max_input_size = 4096 num_outputs = 300 max_chunk_overlap = 0.5 chunk_size_limit = 600 llm_predictor = LLMPredictor(llm=OpenAI(temperature = 0.5, model_name = "text-davinci-003", max_tokens=num_outputs)) prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit) documents = SimpleDirectoryReader("/content/drive/MyDrive/FYP code files/KnowledgeBase").load_data() index = GPTVectorStoreIndex.from_documents(documents) storage_context = StorageContext.from_defaults() index.storage_context.persist(persist_dir="/content/drive/MyDrive/FYP code files/index.json") return index def ask_ai(): #index = SimpleDirectoryReader("index.json").load_data() storage_context = StorageContext.from_defaults(persist_dir='/content/drive/MyDrive/FYP code files/index.json') index = load_index_from_storage(storage_context) query_engin = index.as_query_engine() #index = GPTVectorStoreIndex.load_from_disk('index.json') while True: query = input("Hey, there KNUST Fresher, how can I serve you today? ") response = query_engin.query(query) #response = index.query(query, response_mode="compact") display(Markdown(f"Response: <b>{response.response}</b>"))
#os.environ["OPENAI_API_KEY"] = input("Paste your OpenAI key here and press enter")
construct_index("/content/drive/MyDrive/FYP code files/KnowledgeBase")
ask_ai()
(a) ### Model Selection and Configuration:
(b) ### Parameter Tuning:
def construct_index(directory_path): max_input_size = 4096 num_outputs = 300 max_chunk_overlap = 0.5 chunk_size_limit = 600
Conducted manual testing with diverse scenarios, including:
Basic information queries.
Follow-up questions.
Context-dependent responses.
Real-time information retrieval.
User Authentication and Storage:
Used Firebase for managing user authentication and storing chat history.
Built the user interface using React Native, enabling seamless interaction with the chatbot system.