Project
We have developed a Q&A bot for our new employees by leveraging various Retrieval-Augmented Generation (RAG) techniques, using the Llama 3.1 70B model. This project showcases the different results obtained after training the RAG system on 150+ company manuals and onboarding documents. Implementing an interactive chatbot for new joiners streamlined HDFC Bank's onboarding process by providing 24*7 instant support, reducing HR dependency, and ensuring consistent responses to repetitive queries. This automation enables HR to focus on strategic tasks, enhancing overall efficiency for both central HR teams and new joiners. This publication aims to present our findings and demonstrate the effectiveness of RAG in enhancing the employee onboarding experience.
Introduction
For a large-scale bank of HDFC's stature, the new employees crave for immediate support for smoother integration in their formative months with the Bank. Hence, having a readily available assistance would foster confidence, speed up acclimation, and enhance the overall experience during the initial 6 months, laying a strong foundation for long-term engagement.
Background
HDFC Bank, one of India's largest and most prominent private sector banks, was incorporated in August 1994 as a part of the Housing Development Finance Corporation (HDFC) Group. The bank was established with a vision to offer a wide range of banking and financial services to individuals and businesses, and over time, it has grown into a leader in the Indian banking sector.
As of 31st Mar'24, the Bank employs 2.2 lakh individuals across 9k+ locations. Roughly, 5,000 new employees join the Bank every month - naturally have multiple doubts related to the Bank's policies/ processes / onboarding process. 5 central onboarding teams typically handle these queries. New employees often reach out to their respective HR Business Partners (HRBPs) for assistance, and the HRBPs, receive around 1k queries/day across the Bank, for which their TAT hovers anywhere between an hour to 2 working days depending on the backlog created. This entire process introduces significant human dependency, leading to delays and inefficiencies.
Moreover, the repetitive nature of the questions often creates a bottleneck in the onboarding process, with HRBPs handling multiple similar queries instead of focusing on higher-value tasks. The manual nature of addressing these concerns not only slows down communication but also increases the potential for human error. The volume of queries typically overwhelm the centralized teams, further extending response times and leading to dissatisfaction among new joiners.
To streamline this process, there was a dire need for an automation solution, such as an AI-powered chatbot or self-service knowledge platform, which would provide immediate and consistent responses. Implementing such systems would significantly enhance the onboarding experience, improve response times, and ensure that new employees can access the information they need quickly and accurately.
Ref:- HDFC Bank
Approach
The 10 step high level process for building the requisite solution could be summarized as below -
- 1. Data Aggregation: Collection of diverse data across formats and topics, including 150+ process manuals, documents, HTML files, pdfs and spreadsheets, to ensure a broad information base
- 2. Domain-Specific Evaluation: Utilizing domain experts to manually evaluate and enrich data, enhancing relevance and accuracy for end-users
- 3. Development of the RAG Lifecycle: Development of a comprehensive framework for RAG to guide the chatbot’s response generation process
- 4. Initial RAG Implementation: Deploying a basic RAG model to serve as a foundation for information retrieval and response accuracy
- 5. Adaptive RAG Development: Refining the RAG model to adjust dynamically based on query complexity and context
- 6. Raptor Integration: Enhancing the solution with Raptor for increased speed and efficiency in query handling
- 7. Self-RAG Advancement: Implementing a self-learning RAG model to improve response quality through adaptive feedback
- 8. Graph-RAG Application: Integrating Graph-RAG to leverage graph structures for more contextualized information retrieval
- 9. Human Evaluation: Conducting thorough assessments with central HR teams to validate chatbot responses and ensure quality standards
- 10. Feedback Loop: Looping back insights/feedback into the system for continuous improvement and relevancy.
Architecture
A high level process flow is depicted in the image below
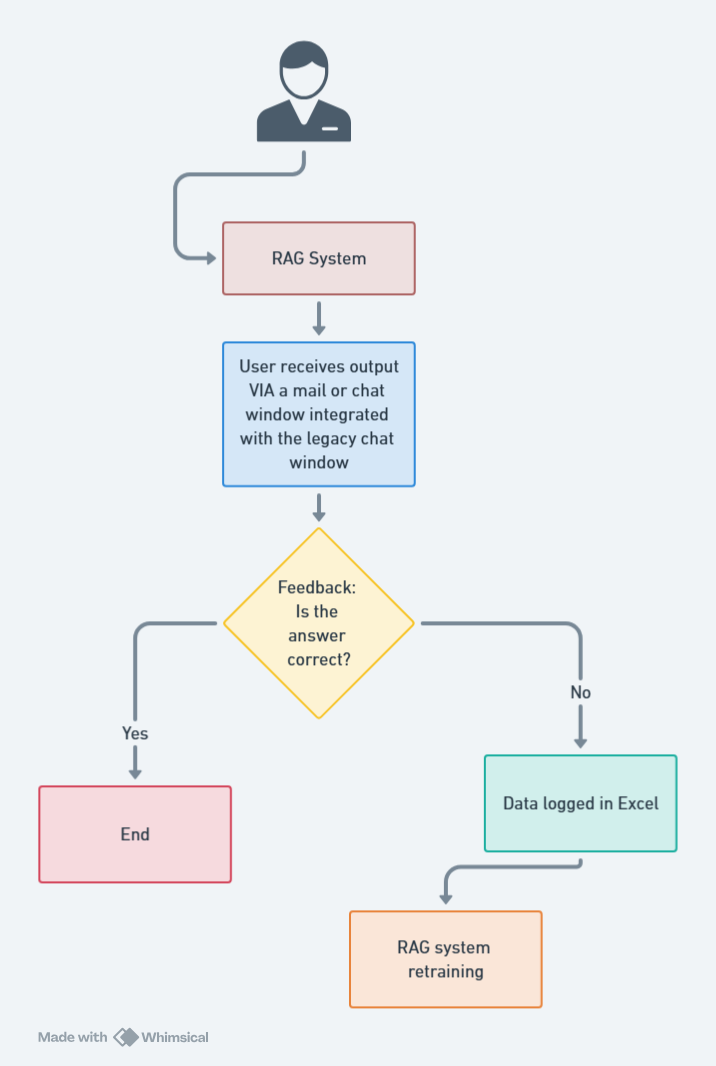
The code snippets and flowcharts for RAG implementations provided in this publication are illustrative examples sourced from publicly available references and repositories. They are intended for educational purposes to aid understanding of the concepts discussed. The actual code developed for this project is proprietary to HDFC Bank Ltd and is not disclosed publicly.
RAG Techniques with Code Implementations
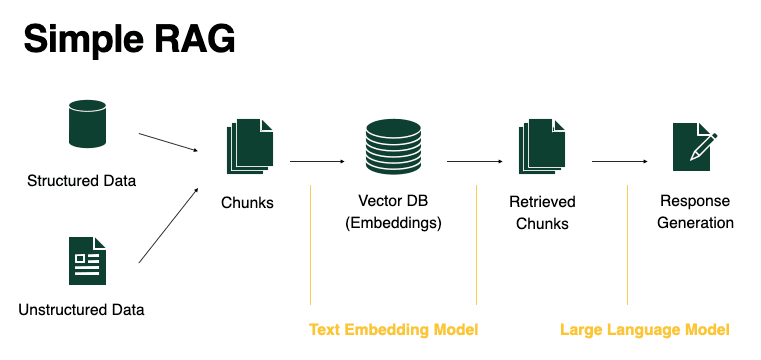
Simple RAG
We started with a basic implementation of a RAG system tailored for processing and querying PDF and word documents. The system encoded the content of the documents into a vector store, enabling efficient retrieval of relevant information based on user queries.
Key Features
Modular Design: The encoding process was wrapped in a single function for easy reuse and integration into larger systems
Configurable Chunking: Allowed adjustment of chunk size and overlap to fine-tune the balance between retrieval accuracy and performance
Efficient Retrieval: Employed Chroma
Evaluation Capability: Included an evaluate_rag function to assess the system's performance, enabling iterative improvements.
Usage Example
The code provides a test query—"How can I apply for a privilege leave?"—to demonstrate how the retriever fetched relevant context from the processed documents. This example showcases the system's ability to deliver precise information based on the encoded content.
def encode_pdf(path, chunk_size=1000, chunk_overlap=200): """ Encodes a PDF book into a vector store using nomic embeddings. Args: path: The path to the PDF file. chunk_size: The desired size of each text chunk. chunk_overlap: The amount of overlap between consecutive chunks. Returns: A Chroma vector store containing the encoded book content. """ # Load PDF documents loader = PyPDFLoader(path) documents = loader.load() # Split documents into chunks text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, length_function=len ) texts = text_splitter.split_documents(documents) cleaned_texts = replace_t_with_space(texts) # Create embeddings and vector store embeddings = nomic vectorstore = chroma return vectorstore chunks_vector_store = encode_pdf(path, chunk_size=1000, chunk_overlap=200) chunks_query_retriever = chunks_vector_store.as_retriever(search_kwargs={"k": 2}) test_query = "How can I apply for a privilege leave?" context = retrieve_context_per_question(test_query, chunks_query_retriever) show_context(context)
Code Example: NirDiamont/Rag_techniques
Impact:
This simple RAG system provided a solid foundation for building more complex information retrieval and question-answering systems. By encoding document content into a searchable vector store, we tried to enable efficient retrieval of relevant information in response to queries. This approach is particularly useful for applications requiring quick access to specific information within large documents or document collections. However, given its limitation in terms of context understanding, self-learning and accuracy in high-diversity data, this standalone architecture was inadequate to deploy.
Adaptive Retrieval-Augmented Generation (RAG) System
Next we explored an advanced RAG approach that adapted its retrieval strategy based on the type of query. By leveraging Language Models (LLMs) at various stages, it provided more accurate, relevant, and context-aware responses to user queries.
Key Components
Query Classifier: Determines the type of query (Factual, Analytical, Opinion, or Contextual).
Adaptive Retrieval Strategies: Four distinct strategies tailored to different query types were tried:
-
Factual Strategy:- Beneficial for Direct Information Queries
Example:- New joiners often have straightforward questions requiring specific answers, such as
"What is the company's dress code?" or "How do I access my employee portal?" -
Analytical Strategy:-Beneficial for Complex Processes and Deep Understanding
Example:- New employees may need to understand intricate processes or systems, like "How does the annual performance review process work?" or "Explain the steps involved in project initiation." -
Opinion Strategy-Beneficial for Cultural Insights and Diverse Perspectives
Example: New joiners might be curious about company culture or employee sentiments, asking questions like "What do employees think about the remote work policy?" or "How is the work-life balance here?" -
Contextual Strategy-Beneficial for Personalized Guidance
Example: Queries that depend on the individual's role or previous interactions, such as "What training should I prioritize as a marketing associate?" or "Who should I contact for IT support?"
LLM Integration for Enhanced Retrieval and Ranking
By integrating Language Models (LLMs) throughout the retrieval process, the chatbot for new joiners was able to better understand the nuances and intent behind their questions. This enhanced the way information was fetched and prioritized, allowing the chatbot to refine search queries and rank the most relevant documents higher. As a result, new employees can receive more accurate and helpful information that is tailored to their specific needs during the onboarding process.
Llama Model for Contextualized Response Generation
We further used the Llama Model to generate responses from retrieved documents, for more accurate, detailed answers enriched with Bank's information.

Image Credit: NirDiamont/Rag_techniques
class AdaptiveRAG: def __init__(self, texts: List[str]): adaptive_retriever = AdaptiveRetriever(texts) self.retriever = PydanticAdaptiveRetriever(adaptive_retriever=adaptive_retriever) self.llm = Llama # Create a custom prompt prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. {context} Question: {question} Answer:""" prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"]) # Create the LLM chain self.llm_chain = prompt | self.llm def answer(self, query: str) -> str: docs = self.retriever.get_relevant_documents(query) input_data = {"context": "\n".join([doc.page_content for doc in docs]), "question": query} return self.llm_chain.invoke(input_data)
Code Example: NirDiamont/Rag_techniques
Impact :
The adaptive RAG system was superior to the simple RAG system because it provided a more nuanced, accurate, and user-specific experience. It adapted to the nature of each query, ensuring that responses were relevant and comprehensive, and enhanced overall user satisfaction. For a chatbot assisting new joiners, these improvements translated into a smoother onboarding process, better understanding of company practices, and a more engaging interaction, all of which were less effectively achieved with a simple RAG approach.
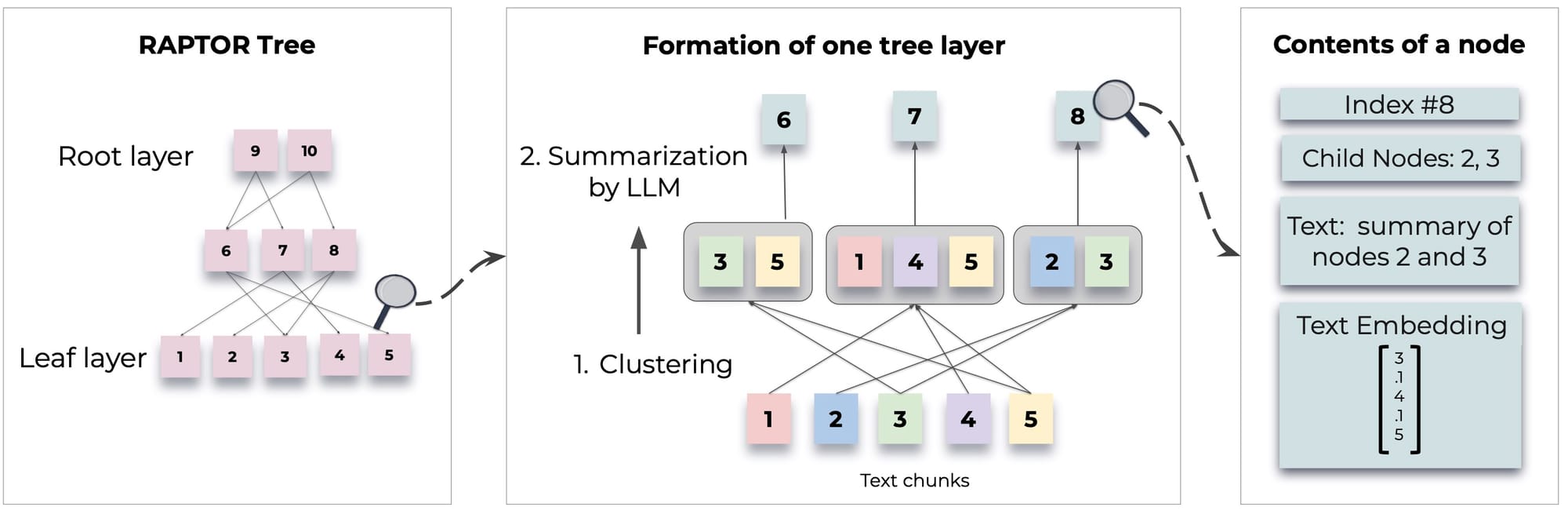
RAPTOR: Recursive Abstractive Processing and Thematic Organization for Retrieval
As speed and precision were critical for real-time responses we integrated RAPTOR, an advanced system to enhance information retrieval and question-answering capabilities. Here's how each component of RAPTOR enhanced the chatbot's effectiveness:
Key Components
-
Hierarchical Summarization (Tree Building)-Beneficial for Navigating Extensive Onboarding Materials
Use Case: New joiners often need to understand both high-level overviews and specific details about the Bank, such as organizational structure, policies, procedures, and culture. -
Embedding and Clustering-Beneficial for Organizing and Retrieving Relevant Information
Use Case: When a new joiner asks a question, the chatbot needs to search through vast amounts of Bank documents and resources to find the most relevant information. -
Vector store - Beneficial for Fast and Scalable Information Access
Use Case: New employees expect prompt and accurate responses from the chatbot, even when dealing with a large repository of documents. -
Contextual Retriever-Beneficial for Tailored and Precise Information Delivery
Use Case: The chatbot must provide answers that are not only accurate but also directly relevant to the specific context of the new joiner's query. -
Answer Generation Using Language Models-Beneficial for Creating Clear and Coherent Explanations
Use Case: New joiners may have questions that require synthesizing information from multiple sources to provide a comprehensive answer.
def build_raptor_tree(texts: List[str], max_levels: int = 3) -> Dict[int, pd.DataFrame]: """Build the RAPTOR tree structure with level metadata and parent-child relationships.""" results = {} current_texts = [extract_text(text) for text in texts] current_metadata = [{"level": 0, "origin": "original", "parent_id": None} for _ in texts] for level in range(1, max_levels + 1): logging.info(f"Processing level {level}") embeddings = embed_texts(current_texts) n_clusters = min(10, len(current_texts) // 2) cluster_labels = perform_clustering(np.array(embeddings), n_clusters) df = pd.DataFrame({ 'text': current_texts, 'embedding': embeddings, 'cluster': cluster_labels, 'metadata': current_metadata }) results[level-1] = df summaries = [] new_metadata = [] for cluster in df['cluster'].unique(): cluster_docs = df[df['cluster'] == cluster] cluster_texts = cluster_docs['text'].tolist() cluster_metadata = cluster_docs['metadata'].tolist() summary = summarize_texts(cluster_texts) summaries.append(summary) new_metadata.append({ "level": level, "origin": f"summary_of_cluster_{cluster}_level_{level-1}", "child_ids": [meta.get('id') for meta in cluster_metadata], "id": f"summary_{level}_{cluster}" }) current_texts = summaries current_metadata = new_metadata if len(current_texts) <= 1: results[level] = pd.DataFrame({ 'text': current_texts, 'embedding': embed_texts(current_texts), 'cluster': [0], 'metadata': current_metadata }) logging.info(f"Stopping at level {level} as we have only one summary") break return results
def build_vectorstore(tree_results: Dict[int, pd.DataFrame]) -> Chroma: """Build a chroma vectorstore from all texts in the RAPTOR tree.""" all_texts = [] all_embeddings = [] all_metadatas = [] for level, df in tree_results.items(): all_texts.extend([str(text) for text in df['text'].tolist()]) all_embeddings.extend([embedding.tolist() if isinstance(embedding, np.ndarray) else embedding for embedding in df['embedding'].tolist()]) all_metadatas.extend(df['metadata'].tolist()) logging.info(f"Building vectorstore with {len(all_texts)} texts") # Create Document objects manually to ensure correct types documents = [Document(page_content=str(text), metadata=metadata) for text, metadata in zip(all_texts, all_metadatas)] return chroma.from_documents(documents, embeddings)
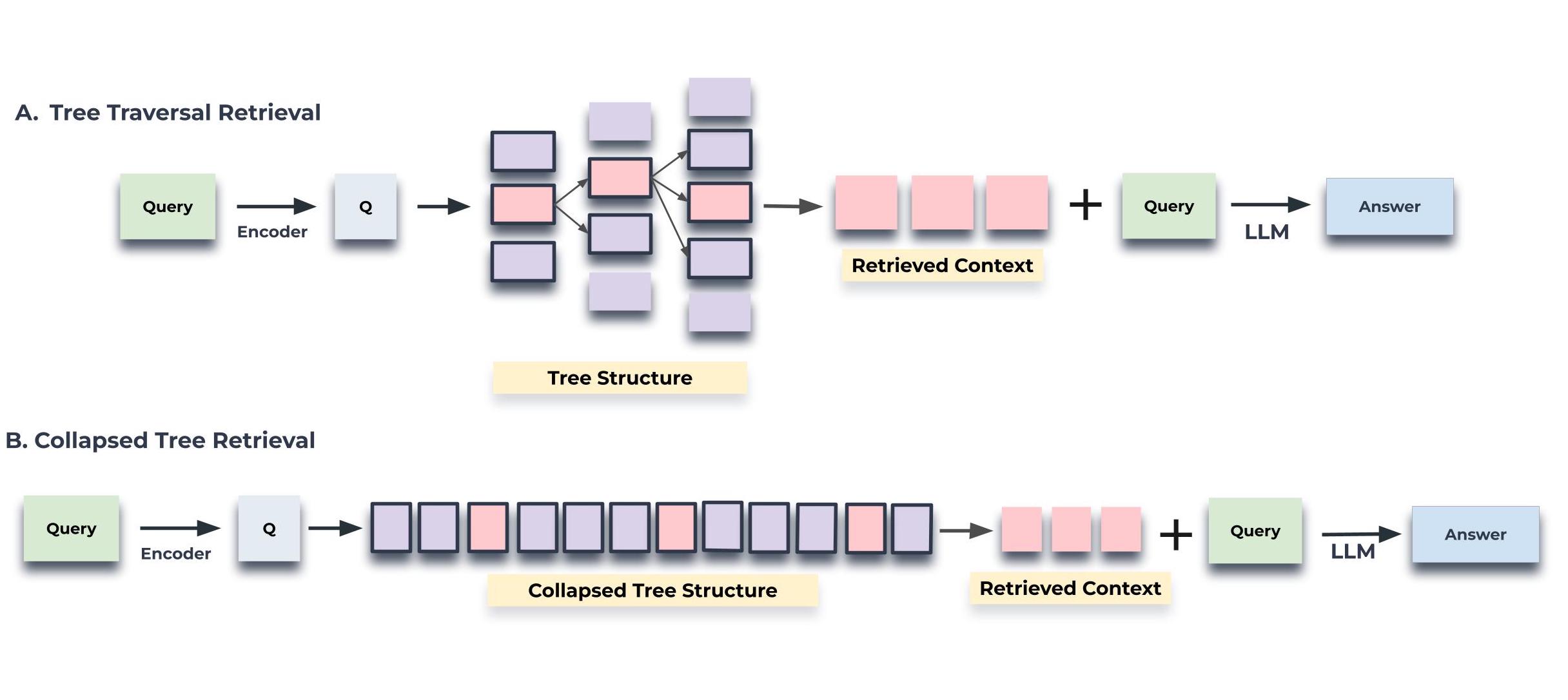
def tree_traversal_retrieval(query: str, vectorstore: chroma, k: int = 3) -> List[Document]: """Perform tree traversal retrieval.""" query_embedding = embeddings.embed_query(query) def retrieve_level(level: int, parent_ids: List[str] = None) -> List[Document]: if parent_ids: docs = vectorstore.similarity_search_by_vector_with_relevance_scores( query_embedding, k=k, filter=lambda meta: meta['level'] == level and meta['id'] in parent_ids ) else: docs = vectorstore.similarity_search_by_vector_with_relevance_scores( query_embedding, k=k, filter=lambda meta: meta['level'] == level ) if not docs or level == 0: return docs child_ids = [doc.metadata.get('child_ids', []) for doc, _ in docs] child_ids = [item for sublist in child_ids for item in sublist] # Flatten the list child_docs = retrieve_level(level - 1, child_ids) return docs + child_docs max_level = max(doc.metadata['level'] for doc in vectorstore.docstore.values()) return retrieve_level(max_level)
def create_retriever(vectorstore: Chroma) -> ContextualCompressionRetriever: """Create a retriever with contextual compression.""" logging.info("Creating contextual compression retriever") base_retriever = vectorstore.as_retriever() prompt = ChatPromptTemplate.from_template( "Given the following context and question, extract only the relevant information for answering the question:\n\n" "Context: {context}\n" "Question: {question}\n\n" "Relevant Information:" ) extractor = LLMChainExtractor.from_llm(llm, prompt=prompt) return ContextualCompressionRetriever( base_compressor=extractor, base_retriever=base_retriever )
def hierarchical_retrieval(query: str, retriever: ContextualCompressionRetriever, max_level: int) -> List[Document]: """Perform hierarchical retrieval starting from the highest level, handling potential None values.""" all_retrieved_docs = [] for level in range(max_level, -1, -1): # Retrieve documents from the current level level_docs = retriever.get_relevant_documents( query, filter=lambda meta: meta['level'] == level ) all_retrieved_docs.extend(level_docs) # If we've found documents, retrieve their children from the next level down if level_docs and level > 0: child_ids = [doc.metadata.get('child_ids', []) for doc in level_docs] child_ids = [item for sublist in child_ids for item in sublist if item is not None] # Flatten and filter None if child_ids: # Only modify query if there are valid child IDs child_query = f" AND id:({' OR '.join(str(id) for id in child_ids)})" query += child_query return all_retrieved_docs def raptor_query(query: str, retriever: ContextualCompressionRetriever, max_level: int) -> Dict[str, Any]: """Process a query using the RAPTOR system with hierarchical retrieval.""" logging.info(f"Processing query: {query}") relevant_docs = hierarchical_retrieval(query, retriever, max_level) doc_details = [] for i, doc in enumerate(relevant_docs, 1): doc_details.append({ "index": i, "content": doc.page_content, "metadata": doc.metadata, "level": doc.metadata.get('level', 'Unknown'), "similarity_score": doc.metadata.get('score', 'N/A') }) context = "\n\n".join([doc.page_content for doc in relevant_docs]) prompt = ChatPromptTemplate.from_template( "Given the following context, please answer the question:\n\n" "Context: {context}\n\n" "Question: {question}\n\n" "Answer:" ) chain = LLMChain(llm=llm, prompt=prompt) answer = chain.run(context=context, question=query) logging.info("Query processing completed") result = { "query": query, "retrieved_documents": doc_details, "num_docs_retrieved": len(relevant_docs), "context_used": context, "answer": answer, "model_used": llm.model_name, } return result
Code Example: NirDiamont/Rag_techniques
Impact
RAPTOR surpassed adaptive RAG and simple RAG by introducing hierarchical summarization to efficiently manage large document collections through a multi-level tree of summaries. This structure enabled the system to provide both high-level overviews and detailed information. By combining this approach with embedding-based retrieval and contextual answer generation, RAPTOR delivered more accurate and relevant responses.
Self-RAG: A Dynamic Approach to Retrieval-Augmented Generation
To further integrate self-learning, Self-RAG was deployed to combine the power of retrieval-based and generation-based approaches in natural language processing. It dynamically decides whether to use retrieved information and how to best utilize it in generating responses, aiming to produce more accurate, relevant, and useful outputs.
Key Components
Retrieval Decision: To determine if retrieval was necessary for a given query.
Document Retrieval: To fetch potentially relevant documents from a vector store.
Relevance Evaluation: To assess the relevance of retrieved documents to the query.
Response Generation: To generate responses based on relevant contexts.
Support Assessment: To evaluate how well the generated response is supported by the context.
Utility Evaluation: To rate the usefulness of the generated response.
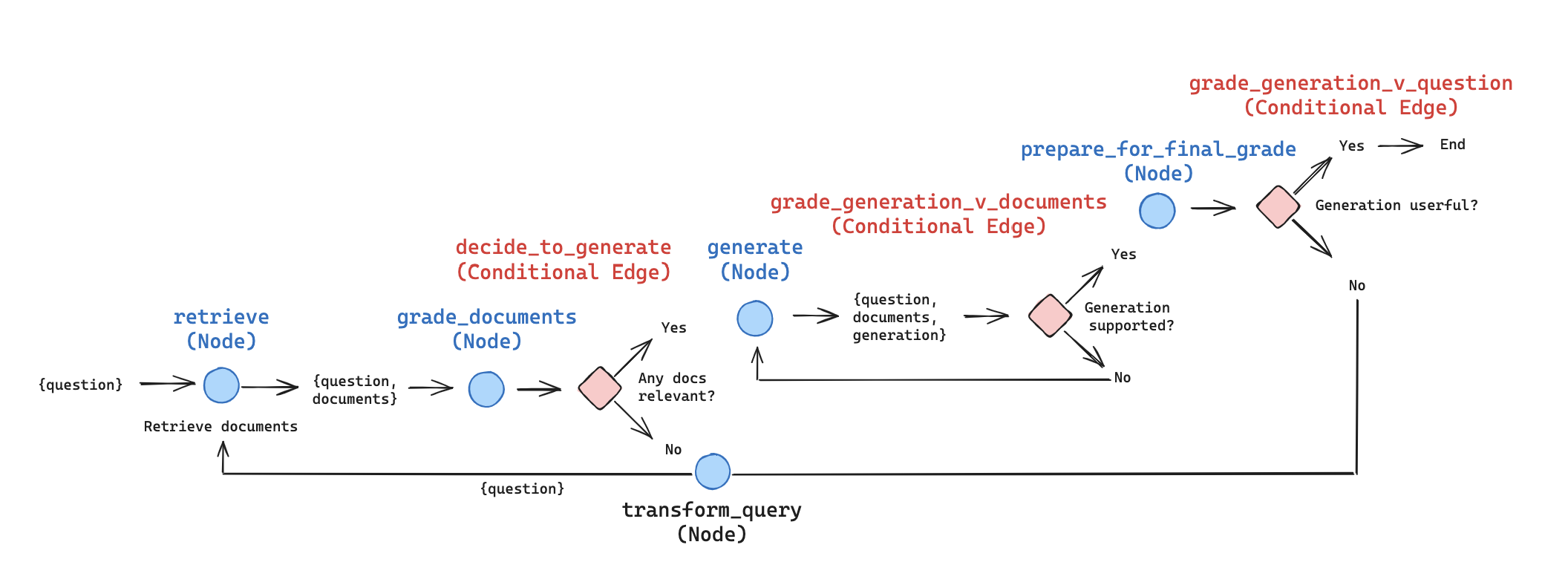
Image Credit: blog.langchain.dev
def self_rag(query, vectorstore, top_k=3): print(f"\nProcessing query: {query}") # Step 1: Determine if retrieval is necessary print("Step 1: Determining if retrieval is necessary...") input_data = {"query": query} retrieval_decision = retrieval_chain.invoke(input_data).response.strip().lower() print(f"Retrieval decision: {retrieval_decision}") if retrieval_decision == 'yes': # Step 2: Retrieve relevant documents print("Step 2: Retrieving relevant documents...") docs = vectorstore.similarity_search(query, k=top_k) contexts = [doc.page_content for doc in docs] print(f"Retrieved {len(contexts)} documents") # Step 3: Evaluate relevance of retrieved documents print("Step 3: Evaluating relevance of retrieved documents...") relevant_contexts = [] for i, context in enumerate(contexts): input_data = {"query": query, "context": context} relevance = relevance_chain.invoke(input_data).response.strip().lower() print(f"Document {i+1} relevance: {relevance}") if relevance == 'relevant': relevant_contexts.append(context) print(f"Number of relevant contexts: {len(relevant_contexts)}") # If no relevant contexts found, generate without retrieval if not relevant_contexts: print("No relevant contexts found. Generating without retrieval...") input_data = {"query": query, "context": "No relevant context found."} return generation_chain.invoke(input_data).response # Step 4: Generate response using relevant contexts print("Step 4: Generating responses using relevant contexts...") responses = [] for i, context in enumerate(relevant_contexts): print(f"Generating response for context {i+1}...") input_data = {"query": query, "context": context} response = generation_chain.invoke(input_data).response # Step 5: Assess support print(f"Step 5: Assessing support for response {i+1}...") input_data = {"response": response, "context": context} support = support_chain.invoke(input_data).response.strip().lower() print(f"Support assessment: {support}") # Step 6: Evaluate utility print(f"Step 6: Evaluating utility for response {i+1}...") input_data = {"query": query, "response": response} utility = int(utility_chain.invoke(input_data).response) print(f"Utility score: {utility}") responses.append((response, support, utility)) # Select the best response based on support and utility print("Selecting the best response...") best_response = max(responses, key=lambda x: (x[1] == 'fully supported', x[2])) print(f"Best response support: {best_response[1]}, utility: {best_response[2]}") return best_response[0] else: # Generate without retrieval print("Generating without retrieval...") input_data = {"query": query, "context": "No retrieval necessary."} return generation_chain.invoke(input_data).response
Code Example: NirDiamont/Rag_techniques
Impact
Self-RAG was a more sophisticated approach to question-answering and information retrieval tasks. By incorporating multiple evaluation steps and dynamically deciding on the use of retrieved information, it produced responses that were not only relevant and accurate but also useful to the end-user. This method showcases the potential of combining retrieval and generation techniques in a thoughtful, evaluated manner to enhance the quality of AI-generated responses.
GraphRAG: Graph-Enhanced Retrieval-Augmented Generation
To further improve performance, we tested out GraphRAG, an advanced question-answering system that combines the power of graph-based knowledge representation with retrieval-augmented generation. It processes input documents to create a rich knowledge graph, which is then used to enhance the retrieval and generation of answers to user queries. The system leverages natural language processing, machine learning, and graph theory to provide more accurate and contextually relevant responses.
Key Components
DocumentProcessor: Handles the initial processing of input documents, creating text chunks and embeddings.
KnowledgeGraph: Constructs a graph representation of the processed documents, where nodes represent text chunks and edges represent relationships between them.
QueryEngine: Manages the process of answering user queries by leveraging the knowledge graph and vector store.

Image Credit: NirDiamont/Rag_techniques
class GraphRAG: def __init__(self): """ Initializes the GraphRAG system with components for document processing, knowledge graph construction, querying, and visualization. Attributes: - llm: An instance of a large language model (LLM) for generating responses. - embedding_model: An instance of an embedding model for document embeddings. - document_processor: An instance of the DocumentProcessor class for processing documents. - knowledge_graph: An instance of the KnowledgeGraph class for building and managing the knowledge graph. - query_engine: An instance of the QueryEngine class for handling queries (initialized as None). - visualizer: An instance of the Visualizer class for visualizing the knowledge graph traversal. """ self.llm = LLAMA self.embedding_model = NOMIC self.document_processor = DocumentProcessor() self.knowledge_graph = KnowledgeGraph() self.query_engine = None self.visualizer = Visualizer() def process_documents(self, documents): """ Processes a list of documents by splitting them into chunks, embedding them, and building a knowledge graph. Args: - documents (list of str): A list of documents to be processed. Returns: - None """ splits, vector_store = self.document_processor.process_documents(documents) self.knowledge_graph.build_graph(splits, self.llm, self.embedding_model) self.query_engine = QueryEngine(vector_store, self.knowledge_graph, self.llm) def query(self, query: str): """ Handles a query by retrieving relevant information from the knowledge graph and visualizing the traversal path. Args: - query (str): The query to be answered. Returns: - str: The response to the query. """ response, traversal_path, filtered_content = self.query_engine.query(query) if traversal_path: self.visualizer.visualize_traversal(self.knowledge_graph.graph, traversal_path) else: print("No traversal path to visualize.") return response
Code Example: NirDiamont/Rag_techniques
Impact
By incorporating a graph-based knowledge representation and intelligent traversal mechanisms, GraphRAG offered improved context awareness, decent accurate retrieval, and enhanced explainability. The system's ability to visualize its decision-making process provided valuable insights into its operation, making it a powerful tool for both end-users and developers. However, Graph RAG was much more resource intensive than Self-RAG and difficult to scale, also Self-RAG's continuous self-learning capability proved superior in terms of evaluation to GraphRAG over a definite period of training.
Results
Human evaluation was considered the primary evaluation criteria for all the RAG architectures.
On a sample of 200+ questions, each of the above RAG techniques were evaluated with the results being the following:-
| Technique | Human Evaluations % |
|---|---|
| SIMPLE RAG | 28 |
| ADAPTIVE RAG | 37 |
| RAPTOR | 43 |
| SELF RAG | 59 |
| GRAPH RAG | 64 |
Conclusion
Based on the highest score achieved by the Graph RAG system on the human evaluation metric, we have decided to move forward with this approach - we are able to address each query in less than 5 seconds, moving down the TAT drastically and work proportional to ~100 daily working hours has been considerably reduced to ~2 daily working hours. With the central HR team also kept in the loop for each query answered, the human element has not been totally removed, wherever the chatbot response has not been adequate enough. Overall, the entire onboarding experience has become much more seamless and efficient.
In addition, we are experimenting with different retrieval, chunking, and compression techniques to enhance the overall performance of the RAG system. The goal is to develop a more robust mechanism that can handle a wider range of user needs and further improve the system’s effectiveness.
References
- https://github.com/NirDiamant/RAG_Techniques
- https://blog.langchain.dev/agentic-rag-with-langgraph/
- https://www.langchain.ca/blog/efficient-information-retrieval-from-complex-pdfs-using-raptor-rag/
- https://www.langchain.com/
- https://huggingface.co/nomic-ai/nomic-embed-text-v1
- https://huggingface.co/meta-llama/Llama-3.1-70B
- https://www.hdfcbank.com/personal/about-us/overview/who-we-are
- https://www.bentoml.com/blog/building-rag-with-open-source-and-custom-ai-models