Serena is a modern, voice-controlled AI assistant application built with Python that combines speech recognition, natural language processing, and text-to-speech capabilities to create an interactive and helpful digital companion.

Serena is designed to be a versatile assistant that can help with web searches, system controls, application management, media controls, voice typing, and information retrieval—all through natural language commands. The assistant features a clean graphical user interface with an animated character and supports both English and Hindi languages.
The project is structured around three main files:
This simple entry point initializes and launches the application:
import tkinter as tk from serena_assistant import SerenaAssistant def main(): root = tk.Tk() app = SerenaAssistant(root) root.mainloop() if __name__ == "__main__": main()
class handles the main functionality
def __init__(self, root): self.root = root self.setup_window() self.setup_voice() self.setup_recognizer() self.setup_openai() self.setup_personality() self.create_gui()
The speech recognition component is configured for optimal performance
def setup_recognizer(self): self.recognizer = sr.Recognizer() self.recognizer.dynamic_energy_threshold = True self.recognizer.energy_threshold = 3000 self.recognizer.pause_threshold = 0.8 self.listening = False self.listen_thread = None
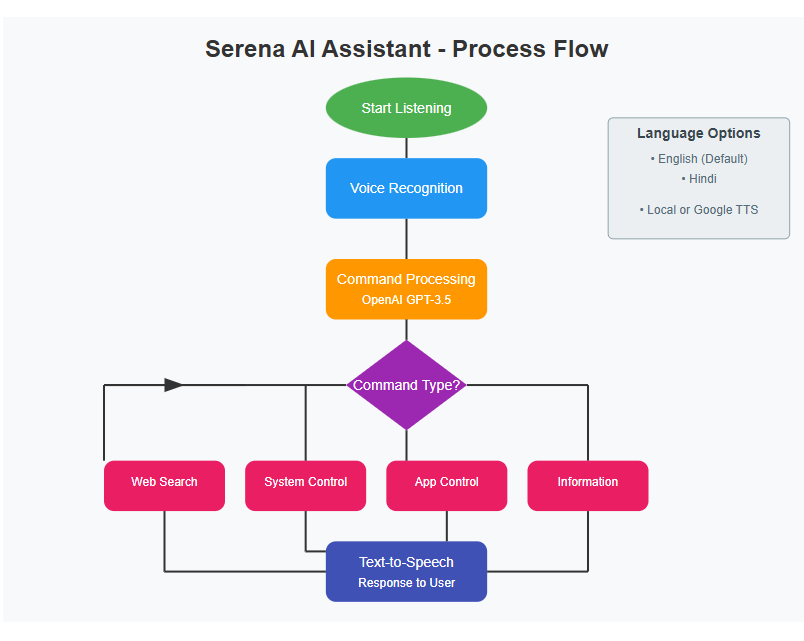
When a voice command is detected, Serena processes it using OpenAI's GPT-3.5
def process_command(self, command): try: # Language switching commands if any(phrase in command.lower() for phrase in ["switch to hindi", "speak in hindi", "use hindi"]): self.tts.switch_to_hindi() self.say("अब मैं हिंदी में बोलूंगी") return # Process other commands via OpenAI response = self.client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are Serena, a helpful female voice assistant. Analyze the command and respond with a JSON object containing: category (web_search/system_control/application/media_control/voice_typing/information), action, and parameters."}, {"role": "user", "content": command} ] ) result = json.loads(response.choices[0].message.content) # Handle different command categories category = result.get('category') parameters = result.get('parameters', {}) if category == 'web_search': self.web_search(command) elif category == 'system_control': self.system_control(command) # Additional categories handled here
For knowledge-based questions
def get_information(self, query): try: response = self.client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are Serena, a female personal friendly and interactive AI assistant. Respond to the following user input in a conversational and engaging manner. Provide comprehensive and very short but concise information about the query."}, {"role": "user", "content": query} ] ) answer = response.choices[0].message.content self.say(answer) except Exception as e: self.say("I'm sorry, I couldn't find that information.")
The TextToSpeech class provides flexible speech output options
class TextToSpeech: def __init__(self, rate=150, volume=1.0, use_indian_english=True): self.use_gtts = True self.use_indian_english = use_indian_english self.engine = pyttsx3.init() self.engine.setProperty('rate', rate) self.engine.setProperty('volume', volume) voices = self.engine.getProperty('voices') if len(voices) > 1: self.engine.setProperty('voice', voices[1].id) self.speak_lock = threading.Lock()
Two different speech engines are supported:
def _speak_gtts(self, text): if self.use_indian_english: lang = "en" tld = "in" else: lang = "hi" tld = "com" mp3_fp = BytesIO() tts = gTTS(text=text, lang=lang, tld=tld) tts.write_to_fp(mp3_fp) mp3_fp.seek(0) audio = AudioSegment.from_mp3(mp3_fp) play(audio) def _speak_pyttsx3(self, text): self.engine.say(text) self.engine.runAndWait()
Serena features a clean, modern interface with:
def create_gui(self): # Main frame setup self.main_frame = ttk.Frame(self.root, style='Custom.TFrame', padding="20") self.main_frame.grid(row=0, column=0, sticky="nsew") # Status indicator self.status_var = tk.StringVar(value="Ready") self.status_label = ttk.Label( self.main_frame, textvariable=self.status_var, style='Status.TLabel' ) # Conversation history self.history_text = scrolledtext.ScrolledText( self.history_frame, wrap=tk.WORD, font=('Arial', 10) ) # Animated character self.gif_label = tk.Label(self.main_frame) self.gif_path = "gif.gif" self.gif = Image.open(self.gif_path) self.gif_frames = [ImageTk.PhotoImage(img) for img in ImageSequence.Iterator(self.gif)]
The project relies on several Python libraries:
Serena demonstrates the power of combining various Python libraries to create a functional, interactive voice assistant. The modular design allows for easy expansion of features and capabilities, making it an excellent foundation for more advanced personal assistant applications.