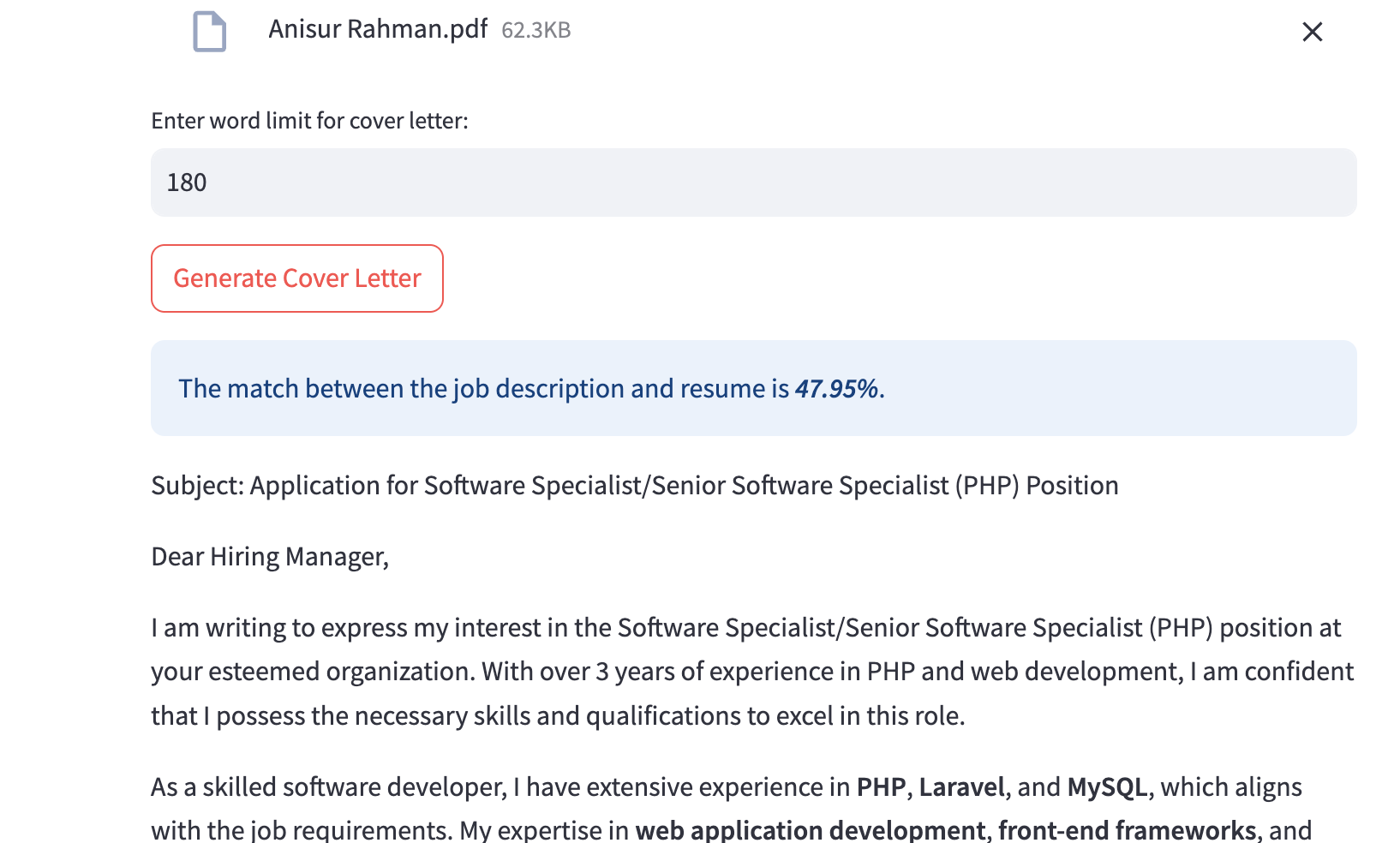
The process of crafting personalized cover letters for job applications can be time-consuming and inefficient. This project introduces a novel system for automated cover letter generation by leveraging semantic matching between job descriptions and resumes. The system utilizes Natural Language Processing (NLP) techniques and Large Language Models (LLM), specifically applying Retrieval-Augmented Generation (RAG) to ensure the generated cover letter is contextually aligned with the job role. By analyzing the semantic content of job descriptions and matching them with key qualifications from resumes, the system efficiently generates tailored cover letters that highlight relevant skills and experiences. This method offers a streamlined, scalable solution to improve the job application process, saving candidates time while ensuring a professional output that aligns closely with the specific requirements of each job posting. Implementing semantic matching and RAG-based LLM models enhances the accuracy and relevancy of the generated content, making it suitable for a wide range of professional roles.
This research focuses on developing a chatbot that leverages large language models (LLMs) and Langchain to scrape website data and respond to user queries based on relevant information retrieved from the scraped content. The bot integrates various tools and techniques for data extraction, semantic processing, and retrieval augmented generation (RAG). The following steps outline the methodology used:
Website Data Scraping
The system begins by taking a URL provided by the user, which points to the desired website. Using BeautifulSoup and requests libraries, the HTML content of the website is fetched and parsed. The links are extracted, ensuring that internal URLs are identified and crawled recursively to gather as much relevant data from the site as possible.
Data Structuring and Splitting
The raw HTML content from the website is processed to strip unnecessary tags and format it into plain text. The Langchain RecursiveCharacterTextSplitter is then employed to split the extracted text into manageable chunks. This ensures that the documents used for training the model and retrieving data do not exceed token limits, improving the efficiency of data retrieval.
Embedding and Vector Store Creation
Once the data is prepared, it is embedded using pre-trained HuggingFace transformer models, such as sentence-transformers/all-MiniLM-L6-v2. These embeddings are used to transform the raw text into vectors for efficient semantic search. The FAISS (Facebook AI Similarity Search) index is employed to store and organize these vectors, allowing quick retrieval of relevant information based on user queries.
Retrieval Augmented Generation (RAG)
For question-answering, a Retrieval Augmented Generation (RAG) approach is used. The system uses Langchain’s RetrievalQAWithSourcesChain, where the LLM is combined with the FAISS vector store. When a user poses a question, the query is passed to the vector store to retrieve relevant chunks of data. These chunks are then fed into the language model to generate an answer, providing both the response and the relevant sources from the scraped website.
LLM Integration and Memory
The chatbot utilizes the Groq LLM for generating responses. To track the conversation history and allow the model to reference past exchanges, Langchain’s memory feature is integrated. This ensures that the chatbot can maintain context and provide coherent multi-turn conversations, where previous queries and responses are taken into account for more relevant answers.
Deployment and User Interaction
The final chatbot is deployed using Streamlit, which provides a user-friendly interface where users can input URLs, submit queries, and receive responses in real-time. The interface allows users to easily interact with the bot, while Streamlit ensures scalability and a smooth user experience. The chatbot is designed to handle multiple users and varying website structures, ensuring flexibility in terms of content and application.
The project follows a structured workflow to ensure the smooth operation of the chatbot from website scraping to user interaction:
Users input a website URL and submit the request.
The bot begins scraping the site for data.
The system fetches the website content using BeautifulSoup and requests.
All relevant links on the website are extracted and followed recursively.
Textual content is cleaned and structured for embedding.
The text data is divided into smaller chunks using the RecursiveCharacterTextSplitter.
This prepares the data for semantic embedding and efficient retrieval.
Embedding and Storage:
The cleaned data is embedded into vector representations using HuggingFaceEmbeddings.
These vectors are stored in a FAISS vector store for quick retrieval.
When a user submits a query, the chatbot uses the stored vector embeddings to find the most relevant information.
The LLM generates a response based on this information and presents it to the user, along with sources from the scraped website.
Contextual Memory:
The conversation history is stored and used to inform future queries.
The chatbot can reference previous exchanges to improve multi-turn conversational capabilities.
Users receive responses in real-time via the Streamlit interface.
The system displays the answer, followed by the sources where the information was extracted.