
Safe Steps is a multimodal AI navigation assistant designed for visually impaired individuals. Performing day to day tasks for a blind person is extremely challenging as they are totally dependent on their caretakers to help them navigate through their surroundings and provide them with necessary assistance. This application can improve their quality of life by providing them a platform to take charge of their own movement. It captures real-time video, detects objects, calculates their orientation and distance from the user, and provides audio instructions about upcoming obstacles so that they may navigate smoothly maintaining their safety. This solution can significantly boost the productivity and confidence of the visually impaired individuals.
The application has been implemented using Streamlit as a frontend. Real time video is captured and processed using the OpenCV library. Object detection is performed using the cutting-edge Ultralyics YOLO11 model pre-trained on COCO dataset and fine-tuned on a custom indoor objects detection dataset from Kaggle. Audio feedback is generated using Python pyttsx3 library for text-to-speech conversion. Together, these technologies create a comprehensive and reliable multimodal navigation assistant.
Imagine a system that sees, hears, and understands just like we do. That's the power of Multimodal AI!
With the latest advancements in artificial intelligence, multimodal AI has emerged as one of the most influential trends in generative AI, getting significant attention across diverse fields. Natural language processing, speech recognition, and computer vision have long been at the core of artificial intelligence, forming the foundational building blocks for modern multimodal applications. Combining vision, language, and other modalities enables machines to better understand and interact with the world, therefore, the blend of these technologies have made it possible to bridge the gap between human intelligence and artificial intelligence.
Multimodal AI systems can integrate and process data from multiple sources and formats such as text, images, audio, and video. Different modalities combined together create a more comprehensive understanding of the information. This is a step towards making human-like perceptions, essential for interacting with the real world. Just as humans use different senses to perceive their environment, these multimodal AI systems use different types of data to get a holistic interpretation of a concept. For example, combining vision and language allows an AI to describe an image or interpret a scene, while integrating audio and video data can enable advanced applications like real-time translation and context-aware navigation.

Modality refers to the different types of data to represent the information, for example, text, images, audio, and video. Multimodal AI is a type of artificial intelligence that can process and integrate these multiple types of data. A unimodal AI system focuses on one type of data whereas multimodal AI systems can perform more complex tasks by combining different modalities. By creating interactions between these modalities, they achieve a more comprehensive understanding of the world. In short, multimodal AI applications can combine multiple types of inputs and generate outputs in various formats.
Humans interact with the world using their five sense organs - eyes to see, ears to hear, nose to smell, skin to touch, and tongue to taste. Can you think about machines who can experience all these five senses like humans do? Well, that seems impossible, right? Through advancements in artificial intelligence, machines have begun to approximate these human capabilities. Nowadays computers have in built cameras which act as their eyes. Since the conception of deep neural networks, there has been a rapid advancement in the field of computer vision. Similarly, computers can listen and produce audio sounds through microphones. The speakers act as the ears of these machines. They can also understand the language that we speak. All these different forms of interaction with the computers are possible through different modalities like text, images, and sound. Isn't that interesting!
The future of artificial intelligence lies in the integration of different modalities, making multimodal AI an essential component in today's world. As AI continues to advance at a rapid pace, the incorporation of various modalities into applications has become unavoidable. People want to make their lives easier. They want to give maximum control to the machines so that they can perform various tasks for them.
Intelligent machines have become a necessity, with applications in many industries including healthcare, education, and entertainment. Multimodal AI systems try to replicate human intelligence, simplifying tasks along with improving decision-making and user experiences.
Multimodal AI opens up countless possibilities across various domains. Here are a few notable examples:
Personal AI Assistant - Imagine you are a busy individual having numerous daily activities. How about a personal assistant powered by multimodal AI who helps manage your day to day tasks efficiently and effectively. By integrating modalities such as text and speech, this assistant can plan your schedule, provide reminders at the right time, and even take instructions through speech.
Language Translator - If you travel a lot and visit different countries often, language barrier is a common problem which can hinder your conversation and growth. A multimodal language translator can help you interact with anyone in the world in their own language. You speak in your native language, your translation assistant translates your speech into the desired language, producing both text and audio as output. Similarly it translates back responses into your own language. This application combines speech-to-text, translation, and text-to-speech technologies, demonstrating the potential of multimodal AI in bridging global communication gaps.
Visual Navigation Assistant - Multimodal AI can significantly enhance accessibility for differently-abled individuals. For a visually impaired person, a multimodal navigation assistant can be a great option ensuring their safe indoor and outdoor movement. It can detect objects in real time and provide instructions about their position and distance from the user. This application includes vision, text, and speech modalities improving lives of the visually impaired individuals in many ways.
Medical Diagnostic Assistant - Doctors are very busy people and integrating multimodal capabilities into medical diagnosis can enhance their productivity and diagnostic power. A medical diagnostic assistant can combine medical images like X-rays or MRI scans with patient records or history in text documents to assist doctors in diagnosing diseases.
Interactive Educational Assistant - AI learning assistants can integrate speech-to-text with visual aids in order to enhance a student's learning experience. Such systems could respond to a student's questions and display interactive diagrams for further engagement.
Let's build a real-world multimodal AI application - a real-time navigation assistant for the visually impaired.
Here's what this application would look like.
The objective of this project is to improve accessibility for the visually impaired individuals. Navigating daily life poses multiple challenges for the blind, as obstacles can hinder their independence and mobility. This application can significantly improve their accessibility and make them less dependent on others so that they can easily move around their surroundings and perform their daily chores. Additionally, it helps them navigate the world around them with confidence. By breaking the barriers between the visually impaired individuals and the world around them, this project helps improve their performance and efficiency to a great extent.
We'll be using the following technologies to build this application:
The main components of Safe Steps include:
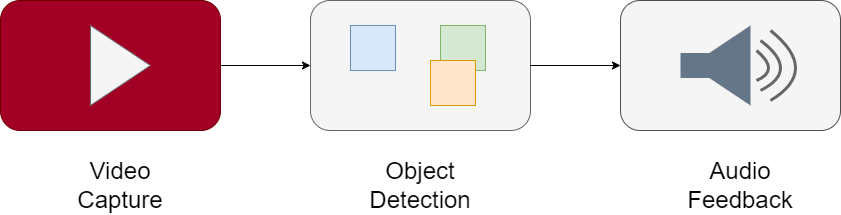
Let's discuss each component of the system in detail:
The video capture component is responsible for initializing the camera, capturing real-time video feeds, and sending the video frames to the object detection component. This component acts as the eyes of the system, continuously monitoring the user's surroundings for potential obstacles or hazards.
The object detection component identifies objects in real-time using two models - YOLO11 model pre-trained on the COCO dataset along with another YOLO model fine-tuned on a custom indoor objects dataset. By combining detections from these models, the system achieves high accuracy in recognizing indoor objects. It calculates the distance of the detected objects from the user, determines their orientation, and sends this information to the audio feedback component. This ensures precise and context-aware detection which is essential for smooth and safe navigation.
The audio feedback component provides verbal instructions to the user based on the detected object's distance and orientation. It also displays the navigation instructions on the interface besides the video feed for additional clarity. For instance:
This component ensures real-time, actionable feedback, enabling the user to navigate safely and confidently.
Users can control the system via the frontend interface, which allows them to start or stop the camera as needed. For optimal functionality, the camera should be positioned to face outward and away from the user. As the user moves through their environment, the system continuously processes the video feed, detects objects, and provides audio feedback. This seamless integration of components ensures that the user receives accurate and timely navigation assistance, significantly enhancing their mobility and independence.
YOLO (You Look Only Once) is a state-of-the-art real-time object detection algorithm. Unlike traditional object detection algorithms, YOLO processes the entire image in a single pass. YOLO is based on a Convolutional Neural Network architecture. It divides the image into a grid and predicts the bounding boxes and class probabilities for objects within each grid cell simultaneously. This approach makes the YOLO algorithm exceptionally fast and efficient, making it an excellent choice for real-time applications.
This project uses Ultralytics YOLO11 model for object detection which is pre-trained on the COCO dataset, which consists of 80 diverse object categories, ranging from everyday items to fruits and animals. The model is then fine-tuned on a custom dataset to enhance its capability in detecting indoor common objects including the following classes:
This dual training approach enhances the system's ability to detect objects critical for real-world navigation for visually impaired individuals. By combining the generalized detection capabilities of the pretrained YOLO11 model with the fine-tuned custom YOLO model, the system ensures accurate recognition of indoor objects.
Create a new virtual environment for the project and install all dependencies through the requirements.txt file.
requirements.txt
streamlit opencv-python ultralytics numpy pyttsx3
The project structure is as follows:
SafeSteps |__frontend |__app.py |__backend |__object_detector.py |__audio_feedback.py |__utils.py |__requirements.txt |__settings.py |__main.py
object_detector.py
This file contains the ObjectDetector class which handles each and everything related to object detection in the video frames. The camera is initialized through OpenCV video capture functionality. It uses the latest YOLO11 model from Ultralytics. YOLO11 has been pre-trained on the COCO dataset which detects generic objects. To further enhance the capability of this model for real-time indoor objects detection suitable for a navigation system, a custom indoor objects detection dataset has been picked from Kaggle which includes ten object categories. YOLO11 model has been trained or fine-tuned on this custom dataset which took around 22.946 hours for 100 epochs using the following CLI command.
yolo detect train data=indoor_objects_dataset/data.yaml model=yolo11n.pt epochs=100 imgsz=640
The summary of the custom trained model is as follows:
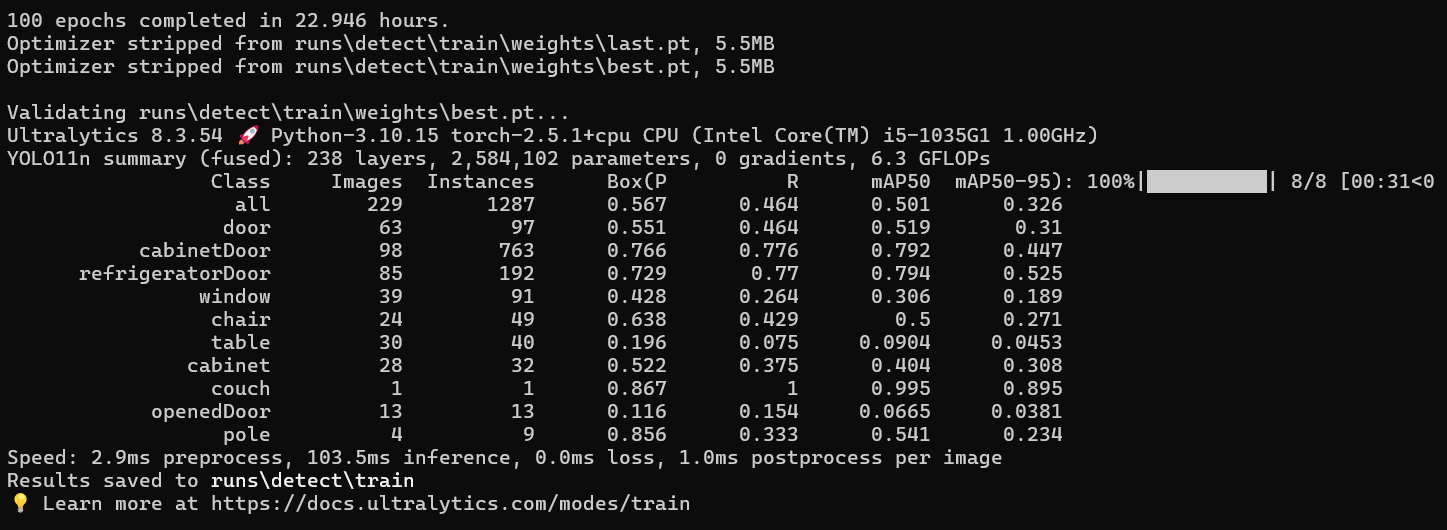
For the application to detect all object classes, the ones belonging to the COCO dataset and the ones in the new custom dataset, two models have been used, YOLO11n.pt from the pre-trained YOLO11 models and best.pt from the fine-tuned YOLO11 model. The detections are then combined and bounding boxes are drawn around the detected objects. While detecting objects, their distance is estimated from the user and their orientation is also determined. These detections, which include class name, confidence, distance, and orientation, are then sent to the AudioFeedback class for generating appropriate instructions for the user while navigation.
import cv2 import sys from ultralytics import YOLO # Import YOLO for object detection from settings import FRAME_WIDTH, FRAME_HEIGHT, FPS, YOLO_MODEL_PATH, CUSTOM_MODEL_PATH, CONFIDENCE_THRESHOLD, REAL_HEIGHTS, FOCAL_LENGTH class ObjectDetector: def __init__(self): try: # Load the general YOLO model trained on the COCO dataset for general object detection self.model = YOLO(YOLO_MODEL_PATH) # Load the custom YOLO model trained on the custom dataset (indoor objects) for specific object detection self.custom_model = YOLO(CUSTOM_MODEL_PATH) print("YOLO models loaded successfully") except Exception as e: # If there is an error loading the models, print the error and raise it print(f"Error loading YOLO models: {str(e)}") raise # Define the list of class names from the COCO dataset for general object detection self.cocoClasses = ["person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"] # Define the list of custom classes for specific objects in the custom dataset self.customClasses = ["door", "cabinetDoor", "refrigeratorDoor", "window", "chair", "table", "cabinet", "couch", "openedDoor", "pole"] # Set general class names to COCO classes and custom class names to indoor objects class names in the custom dataset self.generalClassNames = self.cocoClasses self.customClassNames = self.customClasses # Method to initialize the camera def initialize_camera(self): try: # Open the default camera cap = cv2.VideoCapture(0) # Check if the camera was opened successfully if not cap.isOpened(): raise Exception("Could not open camera") # Set the camera's frame width, height, and FPS cap.set(cv2.CAP_PROP_FRAME_WIDTH, FRAME_WIDTH) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, FRAME_HEIGHT) cap.set(cv2.CAP_PROP_FPS, FPS) return cap except Exception as e: # If there is an error initializing the camera, print the error and return None print(f"Error initializing camera: {str(e)}") return None # Method to detect objects and draw bounding boxes on the frame def detect_and_draw(self, frame, confidence_threshold=CONFIDENCE_THRESHOLD): try: # Detect objects using both the general YOLO model and the custom YOLO model general_results = self.model(frame, stream=True) # Detect objects with the general model custom_results = self.custom_model(frame, stream=True) # Detect objects with the custom model detections = [] # List to store detections with relevant details # Loop through the results from both models (general and custom) for results, classNames in zip([general_results, custom_results], [self.generalClassNames, self.customClassNames]): for r in results: boxes = r.boxes # Extract bounding box information for each detected object for box in boxes: confidence = float(box.conf[0]) # Get the confidence score for the detected object # If the confidence score is above the threshold, process the detection if confidence > confidence_threshold: # Extract the bounding box coordinates x1, y1, x2, y2 = box.xyxy[0] x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2) # Get the class of the detected object cls = int(box.cls[0]) class_name = classNames[cls] # Approximate distance calculation based on the object height in the image # Get real height of the detected object from the dictionary real_height = REAL_HEIGHTS.get(class_name, 1.7) # Default height is 1.7 meters (for person) height = y2 - y1 # Height of the object in the image if height > 0: distance = round((FOCAL_LENGTH * real_height) / height, 2) # Calculate the distance to the object else: distance = float('inf') # If height is zero, distance is infinite (invalid detection) # Calculate the orientation of the object (left, center, right) based on its position center_x = (x1 + x2) / 2 frame_width = frame.shape[1] # Width of the frame (image) if center_x < frame_width / 3: orientation = "left" # Object is on the left side of the frame elif center_x < 2 * frame_width / 3: orientation = "center" # Object is in the center of the frame else: orientation = "right" # Object is on the right side of the frame # Draw the bounding box and label the object with confidence score label = f"{class_name} ({confidence:.2f})" label_y = max(y1 - 10, 20) # Position the label slightly above the bounding box # Draw rectangle and label on the frame cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 255), 2) cv2.putText(frame, label, (x1, label_y), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0), 2) # Append the detection details to the list of detections detections.append({ "class_name": class_name, "confidence": confidence, "distance": distance, "orientation": orientation }) return frame, detections # Return the processed frame and the list of detections except Exception as e: # If there is an error during object detection, print the error and return the frame with no detections print(f"Error in detect_and_draw: {str(e)}") return frame, []
audio_feedback.py
This class handles all the functionality related to the audio instructions maintaining a queue to store the latest instructions for speaking.
import threading from queue import Queue import pyttsx3 import time from settings import SPEECH_RATE, SPEECH_VOLUME class AudioFeedback: def __init__(self): """ Initializes the AudioFeedback system. - Creates a message queue to hold audio messages. - Starts a background thread to process messages in the queue. """ self.message_queue = Queue(maxsize=1) # Queue holds one message at a time to prevent overlapping audio. self.running = True # Flag to indicate if the audio feedback system is running. self.thread = threading.Thread(target=self._process_messages) # Background thread to process audio messages. self.thread.daemon = True # Ensures thread exits when the main program ends. self.thread.start() # Start the background thread. def _process_messages(self): """ Processes messages in the queue and provides audio feedback. - Uses pyttsx3 for text-to-speech conversion. - Runs in an infinite loop until `running` is set to False. """ engine = pyttsx3.init() # Initialize the text-to-speech engine. engine.setProperty('rate', SPEECH_RATE) # Set speech rate from settings. engine.setProperty('volume', SPEECH_VOLUME) # Set volume level from settings. while self.running: try: try: message = self.message_queue.get_nowait() # Fetch a message from the queue if available. engine.stop() # Stop any ongoing speech before starting a new one. engine.say(message) # Queue the message for speech synthesis. engine.runAndWait() # Process and play the audio message. except Queue.Empty: time.sleep(0.1) # If no message is available, pause briefly to reduce CPU usage. except Exception as e: print(f"Error in audio processing: {str(e)}") # Log errors without crashing the program. time.sleep(0.1) # Pause briefly before retrying. # Attempt to reinitialize the audio engine in case of a failure. try: engine = pyttsx3.init() engine.setProperty('rate', SPEECH_RATE) # Fallback to default speech rate. engine.setProperty('volume', SPEECH_VOLUME) # Fallback to default volume. except: pass # Ignore further errors during engine reinitialization. def speak(self, message: str): """ Adds a new message to the audio queue for speech synthesis. - Removes any existing message in the queue to ensure the latest message is spoken. - If the queue is full, the new message is ignored to avoid blocking. """ try: while not self.message_queue.empty(): # Clear the queue to remove outdated messages. try: self.message_queue.get_nowait() except Queue.Empty: break self.message_queue.put(message, block=False) # Add the new message to the queue. except Queue.Full: pass # Ignore the new message if the queue is already full. def cleanup(self): """ Cleans up resources when the system is shutting down. - Stops the background thread and waits for it to terminate. """ self.running = False # Set the running flag to False to stop the processing loop. self.thread.join(timeout=1) # Wait for the thread to finish execution.
utils.py
This file contains the helper function which generates audio instructions based on the object details. These instructions are spoken as well as displayed beside the video on the application interface.
# Function to generate audio instructions based on detected object details def get_instruction(detection): # Extract relevant information from the detection dictionary distance = detection['distance'] # Distance of the detected object from the user class_name = detection['class_name'] # Name of the detected object class orientation = detection['orientation'] # Orientation of the detected object relative to the user # Generate appropriate instruction based on the distance to the object if distance < 0.5: # Stop if the object is too close return f"Stop! {class_name} detected very close at {orientation}." elif distance < 1.5: # Warning if the object is within a medium range return f"Caution! {class_name} detected at the{orientation}, approximately {distance:.1f} meters away." elif distance < 3.0: # Notification if the object is further away but still within detectable range return f"{class_name} detected at the {orientation}, at about {distance:.1f} meters." else: # No immediate obstacles detected return "Path is clear, you may move ahead."
app.py
This is the Streamlit frontend which handles video controls. The sidebar contains options for setting the detection threshold value. There is a video display option on the left which shows live video feed along with detected objects. The audio instructions for navigation are spoken as well as displayed besides the video.
import streamlit as st import cv2 import numpy as np from backend.object_detector import ObjectDetector from backend.audio_feedback import AudioFeedback from backend.utils import get_instruction import time from settings import CONFIDENCE_THRESHOLD # Set up the layout of the Streamlit app to be wide st.set_page_config(layout="wide") # Main function def main(): # Title for the Streamlit app st.title("Safe Steps") st.subheader("Real-Time Object Detection and MultiModal Navigation Assistant") # Check if session state variables exist, if not, initialize them if 'running' not in st.session_state: st.session_state.running = False # Track whether the camera/video is running or not if 'detector' not in st.session_state: st.session_state.detector = ObjectDetector() # Initialize Object Detector if 'audio_feedback' not in st.session_state: st.session_state.audio_feedback = AudioFeedback() # Initialize Audio Feedback if 'last_detection_hash' not in st.session_state: st.session_state.last_detection_hash = None # Keep track of the last detection for reference # Initialize camera if not already initialized in session state if 'cap' not in st.session_state: st.session_state.cap = st.session_state.detector.initialize_camera() # If camera initialization fails, show an error message and stop execution if st.session_state.cap is None: st.error("Failed to initialize camera") return # Sidebar to control settings of the app st.sidebar.title("Settings") confidence_threshold = st.sidebar.slider("Detection Confidence Threshold", min_value=0.0, max_value=1.0, value=CONFIDENCE_THRESHOLD) # Slider for adjusting detection confidence threshold st.sidebar.info("Navigate your surroundings with ease using our AI-powered assistant.") # Application instructions st.sidebar.header("Instructions") st.sidebar.write("1. Point the camera toward the scene.\n2. Follow the audio feedback for navigation.") # Button to toggle the camera on or off if st.button("Start/Stop"): st.session_state.running = not st.session_state.running # Toggle camera state # Create two columns: one for video display, another for displaying instructions col1, col2 = st.columns(2) with col1: st.header("Live Video Feed") video_placeholder = st.empty() # Placeholder for displaying video with col2: st.markdown("<h2 style='text-align:center'>Navigation Instructions</h2>", unsafe_allow_html=True) instruction_placeholder = st.empty() # Placeholder for displaying navigation instructions try: last_detections = [] # To store previous detections in case of no new detections while True: # If the camera/video is running, process the frames to detect objects and generate navigation instructions if st.session_state.running: ret, frame = st.session_state.cap.read() # Capture a frame from the camera if not ret: st.error("Failed to read frame") # If frame capture fails, show an error and break break # Process the frame to detect objects and draw bounding boxes processed_frame, detections = st.session_state.detector.detect_and_draw( frame, confidence_threshold) # If detections are found, store them; otherwise, use the last detections if detections: last_detections = detections else: detections = last_detections # Display the processed frame with object detections video_placeholder.image(processed_frame, channels="BGR", use_container_width=True) # If there are detections, find the closest one and give an instruction if detections: closest_detection = min(detections, key=lambda x: x['distance']) # Find the closest detected object instruction = get_instruction(closest_detection) # Get navigation instruction based on the closest object st.session_state.audio_feedback.speak(instruction) # Provide audio feedback # Display the instruction beside the video in bold instruction_placeholder.markdown(f"<h1 style='font-size:24px; text-align:center'>{instruction}</h1>", unsafe_allow_html=True) else: # If the camera is stopped, display a blank frame with a message "Camera Stopped" blank_frame = np.zeros((480, 640, 3), dtype=np.uint8) cv2.putText(blank_frame, "Camera Stopped", (200, 240), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2) video_placeholder.image(blank_frame, channels="BGR", use_container_width=True) time.sleep(0.1) # Small delay to avoid excessive CPU usage # Small delay to control the frame rate time.sleep(0.01) except Exception as e: st.error(f"Error: {str(e)}") # Handle any unexpected errors by showing an error message finally: # Ensure that the audio feedback system is cleaned up properly when the app stops if 'audio_feedback' in st.session_state: st.session_state.audio_feedback.cleanup() # Entry point for the application if __name__ == "__main__": main()
settings.py
This file contains all the frontend and backend settings and constants. This is a single point of maintenace which makes the application more reusable and scalable.
# Video settings FRAME_WIDTH = 640 # Width of the video frame FRAME_HEIGHT = 480 # Height of the video frame FPS = 30 # Frames per second (video processing speed) # YOLO Model paths YOLO_MODEL_PATH = "../backend/yolo11n.pt" # Path to the general object detection YOLO11 model CUSTOM_MODEL_PATH = "../backend/best.pt" # Path to the custom object detection model trained on a custom dataset # Detection confidence threshold CONFIDENCE_THRESHOLD = 0.5 # Minimum confidence level required for an object detection to be considered valid FOCAL_LENGTH = 615.0 # Approximate focal length of a camera for object distance estimation # Audio Feedback settings SPEECH_RATE = 150 # Rate (speed) at which the speech engine speaks (words per minute) SPEECH_VOLUME = 1.0 # Volume level of the speech engine (range 0.0 to 1.0) # Real-world heights in meters for each class. These will be used for calculating distance of the object from the user. REAL_HEIGHTS = { # COCO dataset classes "person": 1.7, # Average height of a person "bicycle": 1.0, # Average height of a bicycle "car": 1.5, # Average height of a car "motorcycle": 1.2, # Average height of a motorcycle "bird": 0.3, # Average height of a bird "cat": 0.3, # Average height of a cat "dog": 0.6, # Average height of a dog "horse": 1.5, # Average height of a horse "sheep": 1.0, # Average height of a sheep "bottle": 0.3, # Height of a bottle "chair": 1.0, # Height of a chair "couch": 1.0, # Height of a couch "potted plant": 0.5, # Average height of a potted plant "tv": 1.0, # Height of a TV (approximate) "cow": 1.2, # Average height of a cow "airplane": 10.0, # Approximate height of an airplane (body) "bed": 0.5, # Average height of a bed "laptop": 0.05, # Height of a laptop "microwave": 0.5, # Height of a microwave "sink": 0.8, # Height of a sink "oven": 1.0, # Height of an oven "toaster": 0.3, # Height of a toaster "bus": 3.5, # Average height of a bus "train": 3.5, # Average height of a train "dining table": 0.8, # Height of a dining table "elephant": 3.0, # Height of an elephant "banana": 0.2, # Height of a banana (approximated) "toilet": 1.0, # Height of a toilet "book": 0.02, # Height of a book "boat": 1.0, # Height of a boat "cell phone": 0.2, # Height of a cell phone "mouse": 0.05, # Height of a mouse "remote": 0.05, # Height of a remote "clock": 0.2, # Height of a clock "apple": 0.1, # Height of an apple "keyboard": 0.02, # Height of a keyboard "backpack": 0.5, # Average height of a backpack "wine glass": 0.2, # Height of a wine glass "zebra": 1.4, # Height of a zebra "scissors": 0.2, # Height of scissors "truck": 3.0, # Height of a truck "traffic light": 3.0, # Height of a traffic light "cup": 0.1, # Height of a cup "hair drier": 0.3, # Height of a hair dryer "umbrella": 1.0, # Height of an umbrella "fire hydrant": 1.0, # Height of a fire hydrant "bowl": 0.2, # Height of a bowl "fork": 0.2, # Height of a fork "knife": 0.2, # Height of a knife "spoon": 0.2, # Height of a spoon "bear": 1.5, # Average height of a bear "refrigerator": 1.8, # Height of a refrigerator "pizza": 0.02, # Height of a pizza "frisbee": 0.05, # Height of a frisbee "teddy bear": 0.5, # Height of a teddy bear "tie": 0.1, # Height of a tie "stop sign": 1.0, # Height of a stop sign "surfboard": 2.0, # Height of a surfboard "sandwich": 0.05, # Height of a sandwich "kite": 1.0, # Height of a kite "orange": 0.1, # Height of an orange "toothbrush": 0.2, # Height of a toothbrush "sports ball": 0.2, # Height of a sports ball "broccoli": 0.3, # Height of broccoli "suitcase": 0.5, # Height of a suitcase "carrot": 0.3, # Height of a carrot "parking meter": 1.0, # Height of a parking meter "handbag": 0.3, # Height of a handbag "hot dog": 0.1, # Height of a hot dog "donut": 0.05, # Height of a donut "vase": 0.3, # Height of a vase "baseball bat": 0.8, # Height of a baseball bat "baseball glove": 0.2, # Height of a baseball glove "giraffe": 5.0, # Height of a giraffe "skis": 1.8, # Height of skis "snowboard": 1.5, # Height of a snowboard "skateboard": 0.2, # Height of a skateboard "tennis racket": 0.7, # Height of a tennis racket "cake": 0.2, # Height of a cake "bench": 1.0, # Height of a bench # Custom dataset classes (chair, table, and couch have already been covered in COCO dataset classes) "door": 2.0, # Height of a door "cabinetDoor": 2.0, # Height of a cabinet door "refrigeratorDoor": 2.0, # Height of a refrigerator door "window": 1.5, # Height of a window "cabinet": 1.5, # Height of a cabinet "openedDoor": 2.0, # Height of an opened door "pole": 3.0, # Height of a pole (e.g., street light) }
main.py
This is the main entry point of the application. It launches the Streamlit frontend through the CLI (command-line interface) from the application root directory.
# Import necessary modules for running the Streamlit app import streamlit.web.cli as stcli # Provides the Streamlit command-line interface to run apps import sys # Provides access to system-specific parameters and functions # Entry point of the application if __name__ == '__main__': # Modify the system arguments to imitate the Streamlit CLI command for running the app sys.argv = ["streamlit", "run", "frontend/app.py"] # Launch the Streamlit app by calling the CLI's main method stcli.main()
Run the following command to start the application in your browser.
python main.py
Multimodal AI is a groundbreaking technology which has crossed the traditional barriers in human computer interaction. It has made it possible for the machines to develop human like intelligence. Multimodal AI is the future of artificial intelligence as it focuses on surpassing human intelligence beyond our imagination. It has paved the way for creating more accessible, creative, and intelligent systems that can easily integrate into our daily lives making them easier and comfortable.
We have developed a real-time object detection and multimodal navigation assistant for visually impaired individuals using Streamlit, Ultralytics YOLO11, pyttsx3, and OpenCV. This application captures real-time video during navigation, detects obstacles, and provides audio instructions to help visually impaired users navigate their environment independently. By combining these technologies, this application sets a benchmark for building robust and scalable multimodal AI navigation systems designed to enhance accessibility and improve quality of life.
During the development and implementation of this project, several challenges were encountered, each presenting unique hurdles that required creative problem-solving. Here are the details of the challenges faced and the solutions used to address them:
Iterative problem-solving is extremely important in the development of AI-powered applications. By addressing the above challenges, this application proves to be a reliable, real-time navigation assistant for the visually impaired individuals. However, there is always a room for improvement and considering future enhancements can help converting this application into a more robust solution.
Safe Steps is a basic multimodal application which can be installed on any local system. To improve its efficiency and effectiveness, following enhancements can be introduced in the future: