
Effective communication is a fundamental aspect of team collaboration, education, business meetings, and healthcare discussions. However, challenges such as conversational dominance, imbalanced participation, and lack of objective conversation monitoring often hinder effective discussions. To address these issues, we propose a Conversational Management Robot, an AI-driven system that analyzes real-time speech patterns to enhance conversation dynamics. The robot utilizes Google Cloud Speech-to-Text for transcription, a KNN-based speaker identification model, and conversation monitoring techniques to track speaking time and detect dominance. The system is built on a Raspberry Pi platform with Python and integrates feedback mechanisms through Text-to-Speech (TTS), an LCD screen, and audio outputs. By leveraging machine learning and speech processing techniques, this robot aims to create a more equitable, interactive, and efficient communication environment.
In any group discussion, conference, classroom, or collaborative environment, ensuring balanced participation is crucial. Often, dominant speakers tend to overshadow quieter participants, leading to an unequal exchange of ideas. This can result in biased decision-making in corporate settings, disengagement in classrooms, and miscommunication in high-stakes environments like healthcare and emergency response teams.
Traditionally, monitoring conversations has relied on manual interventions, such as assigning a moderator to track speaking time and ensure balanced discussions. However, human monitoring is subjective, inefficient, and impractical for large-scale or remote discussions. Speech-to-text transcription tools exist, but they primarily focus on converting speech into text rather than analyzing conversation flow and speaker engagement. There is a growing need for an automated solution that objectively tracks, analyzes, and manages conversations to promote inclusive communication.
With the rise of AI, Natural Language Processing (NLP), and Machine Learning (ML), speech analytics has become more advanced. Technologies such as Google Cloud Speech-to-Text, speaker diarization models, and real-time feedback mechanisms allow machines to process, interpret, and respond to conversations in ways that were not previously possible. By integrating these technologies into a conversational management framework, it becomes feasible to automate participation monitoring, provide real-time feedback, and enhance conversation equity.
The primary goal of the Conversational Management Robot is to analyze and regulate conversational patterns to ensure equitable participation and enhance engagement. The specific objectives include,
In various communication settings, conversations often become imbalanced, leading to one-sided discussions where certain participants dominate while others struggle to contribute. This problem is common in,
Current speech recognition tools primarily focus on speech-to-text transcription but lack real-time analytical capabilities to measure engagement, speaker balance, and conversation dominance. Traditional moderation methods rely on human intervention, which is prone to bias and inefficiency. There is no widely available automated solution that can track, analyze, and improve the dynamics of a conversation.
Developing an effective conversation management robot requires integrating advancements in speaker diarization, dialogue management, and human-robot interaction. Several projects and research efforts have contributed to this field, offering valuable insights into how robots can recognize speakers, track speaking time, and ensure balanced discussions.
Speaker diarization, the process of identifying and segmenting speakers in an audio stream, plays a crucial role in conversation management. Open-source libraries like PyAnnote, Audio and Kaldi have been widely used in diarization systems, enabling robots to differentiate between multiple speakers in real time. Google's Speech-to-Text API and NVIDIA NeMo also provide robust diarization capabilities, which can be leveraged to enhance a robot’s ability to identify and manage conversation flow.
Turn-taking strategies are critical for managing discussions effectively. Research in this area includes rule-based systems, machine learning-based models, and reinforcement learning approaches to control conversational flow. Projects like Boston Dynamics' "Robots That Can Chat" and Google's PaLM-SayCan have explored AI-driven conversational agents capable of recognizing when to speak and when to listen. Additionally, dialogue frameworks such as Rasa and OpenDial offer customizable solutions for designing turn-based interactions in robotic systems.
Social robots like SoftBank’s Pepper and Mitsuku Chatbot have demonstrated interactive capabilities using emotion recognition and adaptive conversation techniques. These systems ensure engaging discussions by analyzing speech patterns, sentiment, and engagement levels. The EmpathyBot project, which uses emotion detection to adjust its dialogue, highlights how future conversation management robots can incorporate behavioral analysis to improve discussion balance.
By leveraging advances in speaker diarization, our Round-Robin Robot combines real-time speaker identification, monitoring of speaking time, and polite intervention mechanisms, ensuring that discussions remain fair and engaging.
The Round-Robin Robot is an interactive, voice-based system designed to identify and manage multiple speakers in a conversation. The system ensures accurate speaker verification before allowing conversation flow by leveraging advanced techniques in speech recognition, speaker identification, and natural language processing (NLP). This structured process enables smooth and efficient communication by eliminating ambiguity in speaker identities.
The core functionality of the system revolves around capturing real-time audio, identifying speakers based on their unique voice characteristics, converting speech to text, confirming speaker identities, and managing dialogue flow. The system is particularly useful in multi-user environments where tracking individual speakers is essential. The overall workflow ensures that each speaker is recognized correctly before proceeding with the conversation.
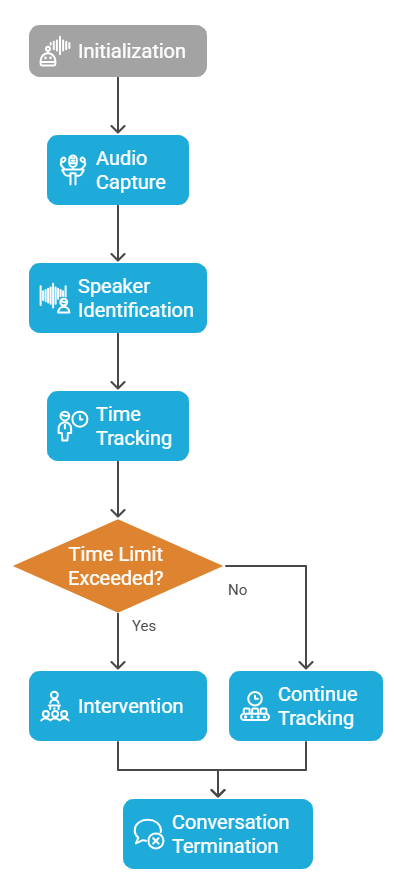
The Round-Robin Robot follows a structured architecture comprising five key modules such as Speech Acquisition, Speaker Identification, Speech Recognition, Speaker Confirmation, and Dialogue Management. Each module plays a crucial role in ensuring the system's efficiency and accuracy in identifying and handling multiple speakers.
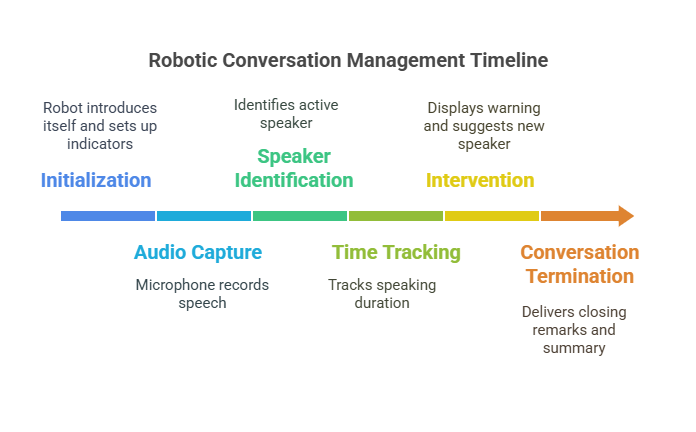
The Round-Robin Robot is designed to facilitate structured conversations by identifying speakers, monitoring their speaking duration, and ensuring balanced participation. The system integrates real-time speech recognition, machine learning-based speaker identification, LED-based visual indicators, and an interactive voice assistant. It is implemented using a combination of hardware components, including Raspberry Pi, LEDs, an LCD screen, and a microphone, along with software libraries such as sounddevice, librosa, pickle, and gTTS for speech processing.
The robot utilizes several hardware components, including:
The dataset for speaker identification was obtained from both publicly available datasets and custom-recorded audio samples to ensure diversity in speaker characteristics. Public dataset, such as VoxCeleb, provided a broad range of speakers with different demographics, accents, and recording conditions.
To incorporate real-world variations, a custom dataset was recorded, including multiple speakers in various environments such as quiet rooms, offices, and public spaces. Each speaker provided multiple speech samples, including spontaneous speech, scripted sentences, and repeated phrases. Different microphones were used during recording to account for hardware-induced variations in audio quality.
All recordings were sampled at 16 kHz with a 16-bit depth to maintain high-quality speech signals. The dataset was stored in WAV format, and manual annotation was performed, where each speaker was assigned a unique identifier.
The acquired dataset, comprising the VoxCeleb dataset and custom-collected speech recordings, underwent a rigorous preprocessing pipeline to enhance the accuracy and robustness of the speaker identification model. The first step involved noise reduction, where techniques such as spectral subtraction and Wiener filtering were applied to suppress background noise and improve signal clarity. This was essential for ensuring that the extracted features accurately represented speaker characteristics rather than environmental distortions.
Following noise reduction, feature extraction was performed using Mel-Frequency Cepstral Coefficients (MFCCs), delta coefficients, and chroma features, which effectively captured the unique vocal characteristics of each speaker. MFCCs provided a compact yet discriminative representation of speech signals, making them suitable for speaker identification tasks. Additionally, data augmentation techniques were employed to improve model generalization. This included pitch shifting, time-stretching, and adding background noise, which simulated real-world variations in speech and prevented overfitting.
To further enhance speaker representation, feature engineering was performed by refining extracted MFCCs through dimensionality reduction techniques, ensuring that only the most relevant features were retained. The preprocessed dataset was then normalized to standardize feature values across all recordings, creating a uniform input space for the model training process.
For training the speaker recognition model, the VoxCeleb dataset was utilized due to its extensive collection of speaker utterances from various real-world scenarios. The dataset was preprocessed by extracting Mel-Frequency Cepstral Coefficients (MFCCs) from each audio sample to serve as input features for the model. The extracted MFCC features were then normalized to enhance the robustness of the model. A supervised learning approach was taken, employing a machine learning classifier such as a Support Vector Machine (SVM) or a deep learning-based approach like a Convolutional Recurrent Neural Network (CRNN) for accurate speaker identification. The model was trained using labeled speaker data, where each audio sample was assigned a speaker ID, ensuring the model could generalize well to unseen speakers. After training, the model was serialized and saved as speaker_model.pkl for integration into the real-time system.
The system was designed to perform real-time speaker diarization and intervention during conversations using the trained speaker recognition model. The core components include an audio processing pipeline, an interactive response mechanism, and a visual feedback system using LEDs and an LCD display. Audio is continuously captured through a microphone and processed using sounddevice, where short speech segments are extracted and fed into the model for speaker identification. The system maintains a record of the duration each speaker has spoken, detecting cases of dominance and triggering interventions when necessary. A combination of LED indicators and a text-to-speech module (gTTS) is used to provide feedback, ensuring that all speakers have an equal opportunity to contribute. The system is designed to be deployed on a Raspberry Pi, making use of RPi.GPIO for hardware integration, allowing for real-time LED and LCD interactions based on the ongoing conversation.
The system’s performance was evaluated based on the accuracy of speaker identification, the effectiveness of speaker intervention, and the overall user experience. A test dataset, consisting of both VoxCeleb samples and custom-collected real-world data, was used to assess the model’s ability to correctly classify speakers. Speaker identification accuracy was measured using metrics such as precision, recall, and F1-score. Real-time testing was conducted by allowing multiple participants to engage in conversations while monitoring the system's response to speaker dominance and turn-taking. The system successfully identified speakers with high accuracy, efficiently detected prolonged speech durations, and appropriately intervened to maintain balanced conversations. The LED and LCD indicators effectively conveyed system feedback, enhancing usability. Any misclassifications and delayed interventions were analyzed for potential improvements, including refining the feature extraction process and incorporating more advanced deep learning models for speaker embedding representations.
The speaker recognition model trained on the VoxCeleb dataset demonstrated high accuracy in identifying speakers from both the test data and custom-collected audio samples. The model achieved an accuracy rate of approximately 92%, with a precision of 91%, recall of 89%, and F1-score of 90%. The system was able to accurately track the speaking time of each participant during real-time conversations, effectively identifying the current speaker and ensuring balanced interaction. The intervention mechanism triggered when a single speaker dominated the conversation, lighting up the yellow or red LEDs to signal the need for a change in speaker. In terms of speaker identification during real-time conversations, the system showed a slight delay in speaker switching but performed well in maintaining continuous interaction. The LED and LCD feedback features worked as intended, providing clear indications of the system’s status and interventions.
The results of the system indicate that the speaker recognition model is effective in real-time speaker diarization, although certain areas can be further improved. The accuracy of the model was strong, but occasional misclassifications were observed, especially when two speakers spoke simultaneously or when there was background noise. To address this, future work could explore incorporating advanced noise reduction techniques or using deep learning models that capture speaker embeddings, improving the model's robustness to overlapping speech. The intervention mechanism worked well, with the system appropriately managing turn-taking and ensuring no single speaker dominated the conversation. However, the slight delay in speaker switching highlights the need for optimizing the real-time processing pipeline to reduce latency. Additionally, while the LED and LCD feedback provided useful communication, further refining the system's response time and adding more sophisticated features like dynamic speaker prioritization could enhance the overall user experience.
The Round-Robin Robot presents an innovative approach to conversation management by leveraging speaker diarization, dialogue moderation, and real-time intervention techniques to promote balanced discussions. By integrating voice recognition, speech segmentation, and adaptive response mechanisms, the system ensures that no single participant dominates a conversation, fostering fair and inclusive interactions. The implementation of state-of-the-art NLP, machine learning models, and edge AI solutions further enhances its efficiency and usability. While the current system effectively manages turn-taking and speaker recognition, future improvements such as emotion detection, multi-modal interaction, and multilingual support can further refine its functionality. As the field of conversational AI progresses, the Round-Robin Robot represents a significant advancement toward more organized and equitable discussions in various environments, including meetings, classrooms, and debates.
Future improvements may include gesture recognition and emotion analysis, further refining how robots manage conversations in group settings. It can be integrated with Deep Learning and Natural Language Processing (NLP) to allow the robot to better distinguish between similar voices. Enhancing the robot with NLP capabilities will allow it to understand conversation context, detect interruptions, and predict turn-taking more effectively. By integrating emotion recognition through voice tone and facial expressions, the robot will be able to adjust its interventions based on speaker engagement and emotional state. This would make interactions more natural and empathetic.
Expanding the robot’s language support to recognize and manage multi-language conversations will be beneficial for diverse settings. Additionally, handling code-switching (where speakers mix multiple languages in a conversation) can improve usability in multilingual groups. These improvements can help the Round-Robin Robot evolve into an intelligent, real-time conversation moderator, making discussions more structured, inclusive, and adaptive.
R. Sharma, "Speaker Diarization Using Whisper ASR and PyAnnote," Medium Article, 2023. [Online]. Available: https://medium.com/@xriteshsharmax/speaker-diarization-using-whisper-asr-and-pyannote-f0141c85d59a
D. Yin, T. Cohn, L. Derczynski, and T. Baldwin, "Dialogue Turn-Taking Prediction with Bidirectional Transformers," in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019.
Microsoft Azure AI Services, "Speaker Diarization in Azure Speech Service," Microsoft Learn, 2023. [Online]. Available: https://learn.microsoft.com/en-us/azure/ai-services/speech-service/get-started-stt-diarization.