Abstract
This project applies deep learning techniques to the segmentation of retinal blood vessels based on spectral fundus images, presenting a network and training strategy that leverages data augmentation to enhance the efficiency of available annotated samples. By incorporating shape, size, and arteriovenous crossing types, the project aims to provide valuable insights into numerous eye diseases. Furthermore, the application of deep learning, specifically the U-Net convolutional network, to real patients’ fundus images yields high performance, surpassing the manual methods employed by skilled ophthalmologists. The project's findings demonstrate the potential of deep learning in revolutionizing the segmentation of retinal blood vessels and its implications for advancing diagnostic capabilities in ophthalmology.
Introduction
The project "Retina Blood Vessel Segmentation Using A U-Net Based Convolutional Neural Network" aims to improve the diagnosis and treatment of eye diseases by utilizing advanced image analysis techniques. It focuses on accurately segmenting retinal blood vessels through the use of cutting-edge imaging and data analysis methods. The project also aims to optimize the use of annotated samples by incorporating data augmentation and leveraging deep learning advancements to achieve high-performance results.
Additionally, it explores the potential of deep learning techniques in segmenting retinal blood vessels using spectral fundus images, with the goal of extracting valuable information about various eye diseases. Overall, this project is a significant advancement in the field of medical imaging and diagnostics for eye diseases.
This project was introduced with the goal of improving the diagnosis and treatment of eye diseases through advanced image analysis techniques. It aims to achieve this by accurately segmenting retinal blood vessels, using advanced imaging and data analysis methods to enhance diagnostic capabilities for various eye diseases.
Additionally, the project seeks to develop a network and training strategy that efficiently uses available annotated samples through data augmentation, aiming for more scalable and cost-effective diagnostic solutions. Leveraging the advancements in deep learning, particularly the effectiveness of feature learning through artificial neural networks, the project aims to achieve high-performance results in retinal blood vessel segmentation, outperforming manual methods used by skilled ophthalmologists. Furthermore, the project aims to explore the application of deep learning techniques for retinal blood vessel segmentation using spectral fundus images to extract valuable evidence about numerous eye diseases based on the characteristics of the retinal blood vessels.
Methodology
Eye diseases can be diagnosed by studying the retinal blood vessels using proper imaging techniques and data analysis methods. In the past, training deep networks required thousands of annotated training samples, but a new approach uses data augmentation to make better use of available annotated samples. This approach is based on the U-Net convolutional neural network, known for its success in the ISBI cell tracking challenge 2015.
Proper technologies are crucial for automating the diagnostic process, especially in eye examinations where retinal image segmentation plays a key role. While many existing algorithms for this task rely on classical machine learning methods, recent advancements in deep learning offer a more effective way for feature learning. This study is the first to apply deep learning techniques for segmenting retinal blood vessels using spectral fundus images, achieving high performance that surpasses manual assessment by skilled ophthalmologists.
The eye is an organ of sight which typically has a spherical form and located in an orbital cavity. The human eye has a complicated structure. Usually three layers of the eyeball are distinguished: the outer fibrous layer, the middle vascular layer, and the inner nervous tissue layer.
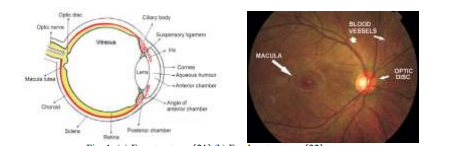
Eyes diseases include macular, hypertensive retinopathy, diabetic retinopathy and etc. Most of the retinal diseases are usually detected by identifying the size, shape and widen of vessels in the manual way. Thus, it will be helpful for diagnosis if we can get vessel diameter automatically.
Over the past few years major computer vision research efforts have concentrated on convolutional neural networks, commonly referred to ConvNet or CNNs. These research works have produced a better performance on a wide range of classification and regression tasks. A typical neural network architecture is made of an input layer, x, an output layer, y, and a stack of multiple hidden layers, h, where each layer consists of multiple cells or units. Usually, each hidden unit, hj, receives input from all units at the previous layer and is defined as a weighted combination of the inputs followed by a nonlinearity according to

where, wij, are the weights controlling the strength of the connections between the input units and the hidden unit, bj is a small bias of the hidden unit and F (∙) is a certain saturating nonlinearity such as the sigmoid function. Deep neural networks can be seen as a modern-day instantiation of Rosenblatt’s perceptron and multilayer perceptron.
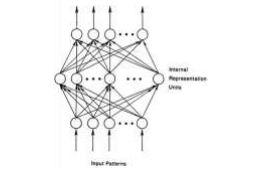
While neural network models have existed for many years, they were not widely used until more recent times due to several reasons. One significant advancement that contributed to progress in deep neural networks is layer-wise unsupervised pretraining using Restricted Boltzman Machines (RBMs). These machines can be viewed as two-layer neural networks where only feedforward connections are allowed in their restricted form, but they also have limitations that restrict their application.
Convolutional networks (ConvNets) are a specialized type of neural network particularly suited for computer vision applications. They excel at hierarchically abstracting representations using local operations. The success of convolutional architectures in computer vision is driven by two key design principles. First, ConvNets leverage the 2D structure of images and feature sharing, resulting in an architecture that requires fewer parameters compared to standard Neural Networks. Second, ConvNets introduce a pooling step that provides a degree of translation invariance and allows the network to gradually capture larger portions of the input. This enables the network to represent more abstract characteristics of the input as its depth increases.
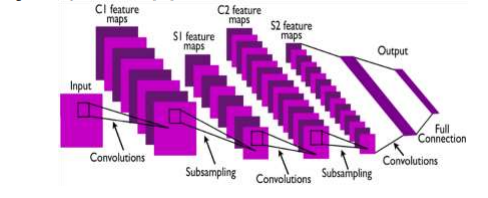
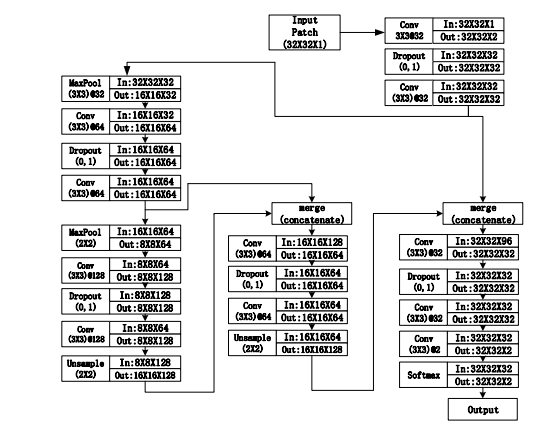
The U-Net architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. The U-Net architecture can be trained end-to-end from very few images and outperforms most of the methods on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks.
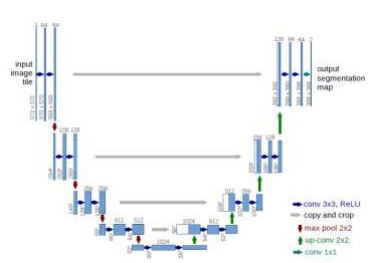
U-net architecture is shown above(example for 32x32 pixels in the lowest resolution). Each blue box corresponds to a multi-channel feature map. The number of channels is denoted on the top of the box. The x-y size is provided at the lower left edge of the box. White boxes represent copied feature maps and the arrows denote the different operations.
Experiments
The CNN architecture utilized for segmenting blood vessels in fundus images is derived from the U-Net network. The U-Net employs an encoder-decoder structure, with the decoder gradually reconstructing the input, resulting in a pixel-wise probability map. Unlike other CNN architectures, the U-Net doesn't necessitate a large number of training samples and can be effectively trained with just a few images, as observed in the dataset used for this study.
In comparison to the original architecture, several significant modifications were made to the CNN in this work. Firstly, the network was downsized by reducing its depth through the removal of two out of five levels of pooling/up sampling operations and the corresponding convolution. Additionally, the number of feature vectors at each level was halved, leading to a variation in the number of filters from 32 at the input to 128 in the lowest resolution. This downscaling was undertaken as a shallower architecture yielded comparable results to the original U-Net, while facilitating easier training and significantly reducing training time.
The final number of layers and their configuration were determined through experimentation, aiming to strike a balance between training time and network accuracy. Furthermore, dropout layers were introduced between the convolutional layers to enhance training performance.
The performance of this neural network is tested on the DRIVE database, and it achieves the best score in terms of area under the ROC curve in comparison to the other methods published so far. Also on the STARE datasets, this method reports one of the best performances.
Before training, the 20 images of the DRIVE training datasets are pre-processed with the following transformations:
- Gray-scale conversion
- Standardization
- Contrast-limited adaptive histogram equalization (CLAHE)
- Gamma adjustment
The proposed U-Net based network was trained using patches of a size 32*32 pixels. This patch size provided the best accuracy of pixel classification by CNN. Each patch is obtained by randomly selecting its center inside the full image. Also, the patches partially or completely outside the Field of View (FOV) are selected, in this way the neural network learns how to discriminate the FOV border from blood vessels.
A set of 190,000 patches is obtained by randomly extracting 9,500 patches in each of the 20 DRIVE training images. Although the patches overlap, i.e. different patches may contain same part of the original images, no further data augmentation is performed. The first 90% of the dataset is used for training (171,000 patches), while the last 10% is used for validation (19,000 patches).
The loss function is the cross-entropy and the stochastic gradient descent is employed for optimization. The activation function after each convolutional layer is the Rectifier Linear Unit (ReLU), and a dropout of 0.2 is used between two consecutive convolutional layers.
Training is performed for 150 epochs, with a mini-batch size of 32 patches. Using a GeForce GTX TITAN GPU, the training lasts for about 20 hours.

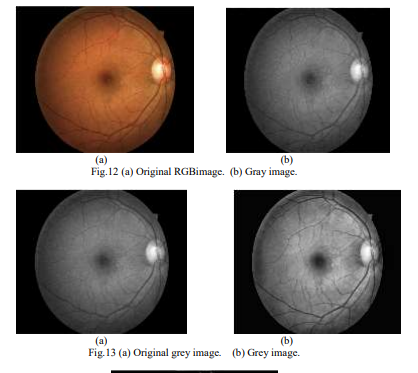
We use Python3.6 to transfer RGB images to gray images. Then the image is processed by contrast-limited adaptive histogram equalization (CLAHE) and gamma adjustment.
Results
In this project we are using CNN U-net model to segment retina images and to get retina blood vessel and to train this model we need thousands of images to get better result but those images are not available on internet and the images are available at DRIVE DATABASE but this website not allowing to download so we are using STARE dataset which contains only 28 images due to that reason our model not showing segmentation clearly but able to segmented image.
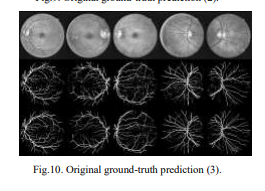
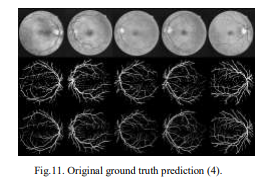
Below is the dataset screen shots used to train U-net model:
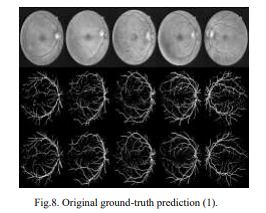
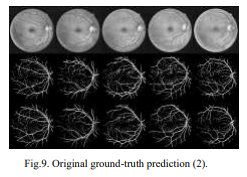
Below is the segmented images used to train U-net model:
By using above dataset we are training U-net model and when we upload new test image then U-net will give segmented image as output.
To run project double click on ‘run.bat’ file to get below screen
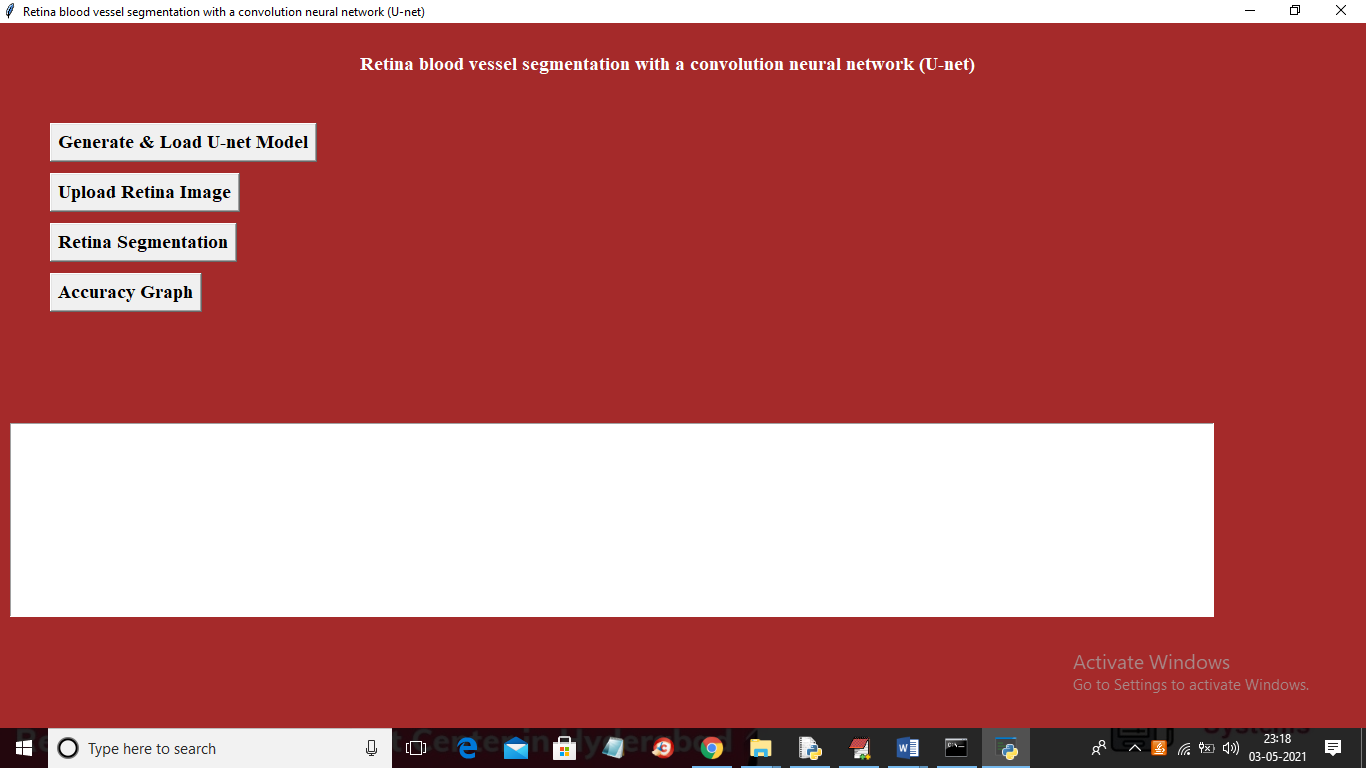
In above screen click on ‘Generate & Load U-net Model’ button to load U-net model
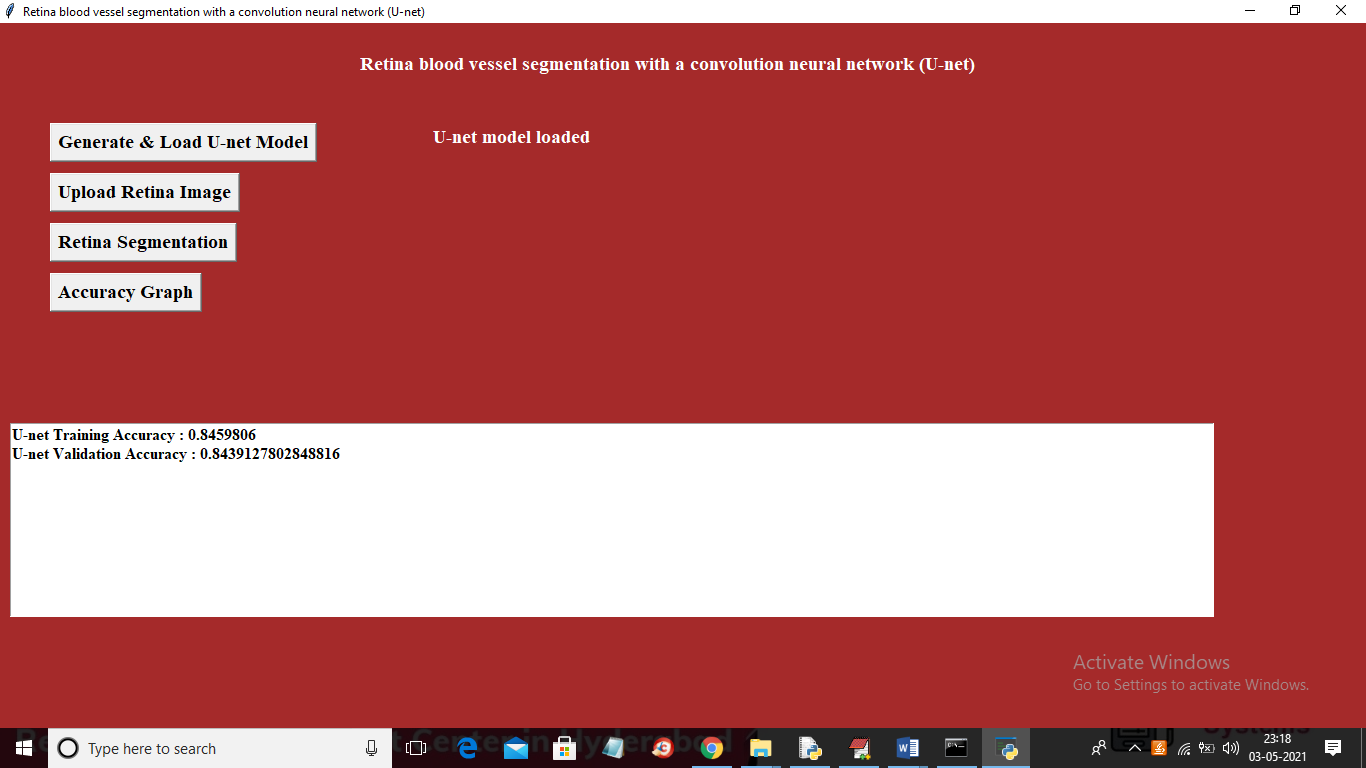
In above screen U-net model generated and we got its accuracy as 0.84% and because of less dataset size accuracy is not better and if you provide huge size dataset then this accuracy can be increase. Now click on ‘Upload Retina Image’ button to upload retina image
In above screen selecting and uploading ‘6.jpg’ file and then click on ‘Open’ button to load image and to get below screen
In above screen test image is loaded and now click on ‘Retina Segmentation’ button to get below output
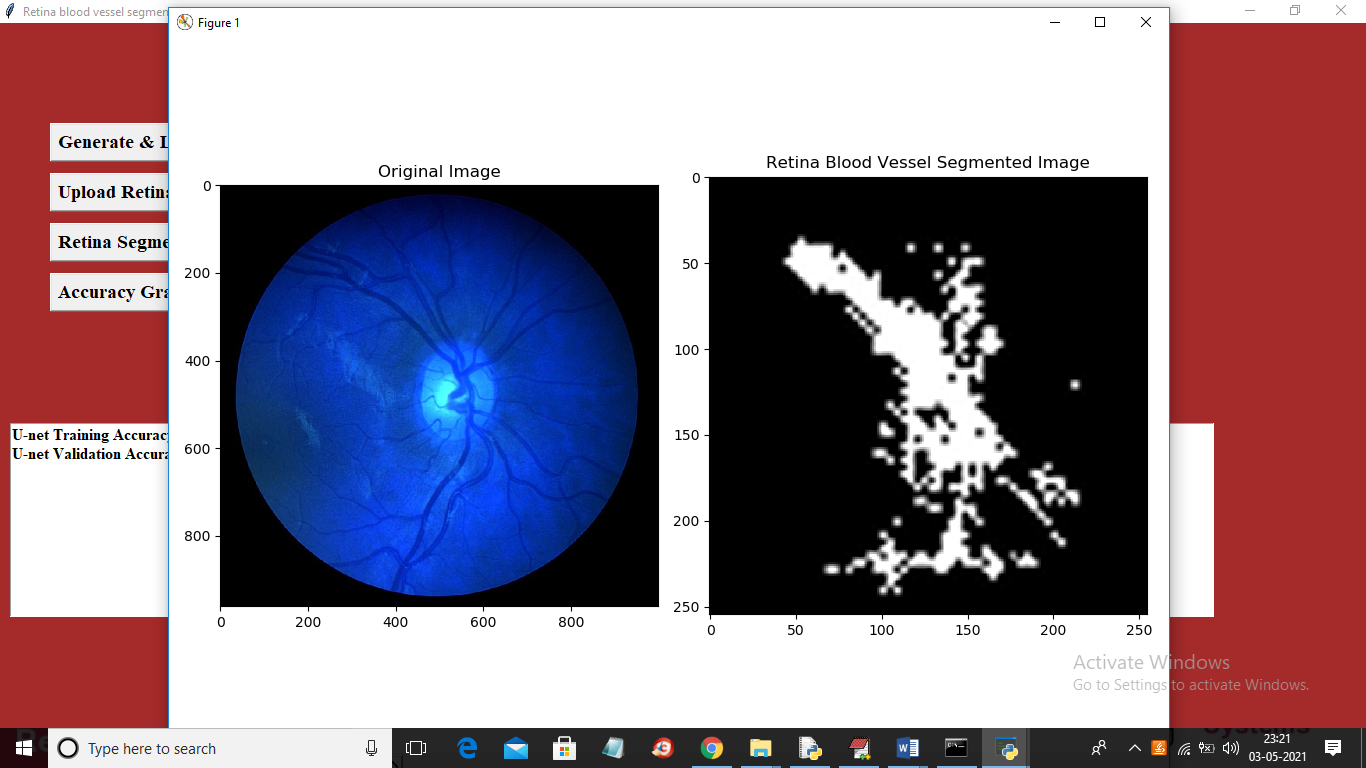
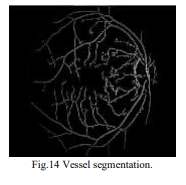
In above screen first image is the original image and second image is the segmented image and in dataset also you can see segmented image contains only lines. Now test other image
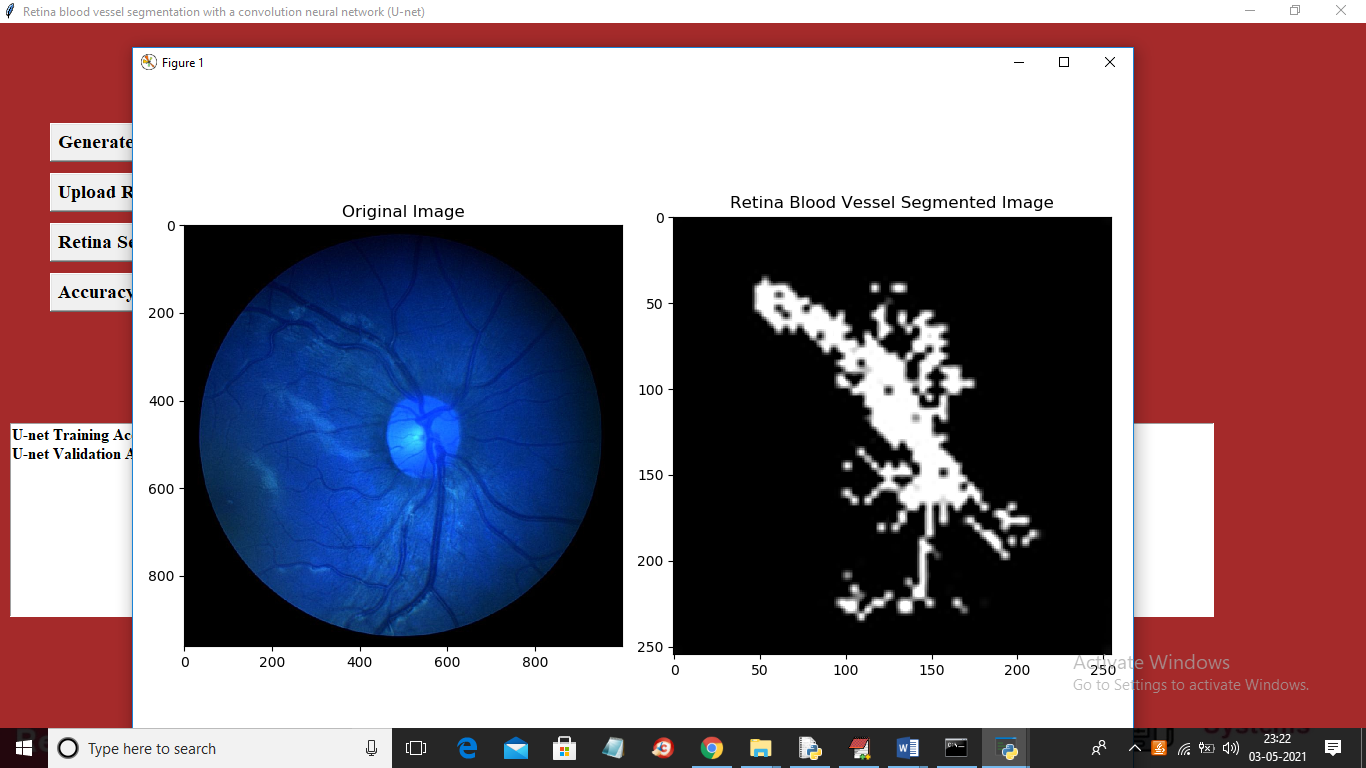
Similarly you can upload other images and test.
Note: Due to short dataset size segmentation output is not clear but still application able to do segmentation and if you provide nearly 3000 images dataset then application can perform segmentation properly and it will take days of time also for training. Now click on ‘Accuracy Graph’ button to get below graph
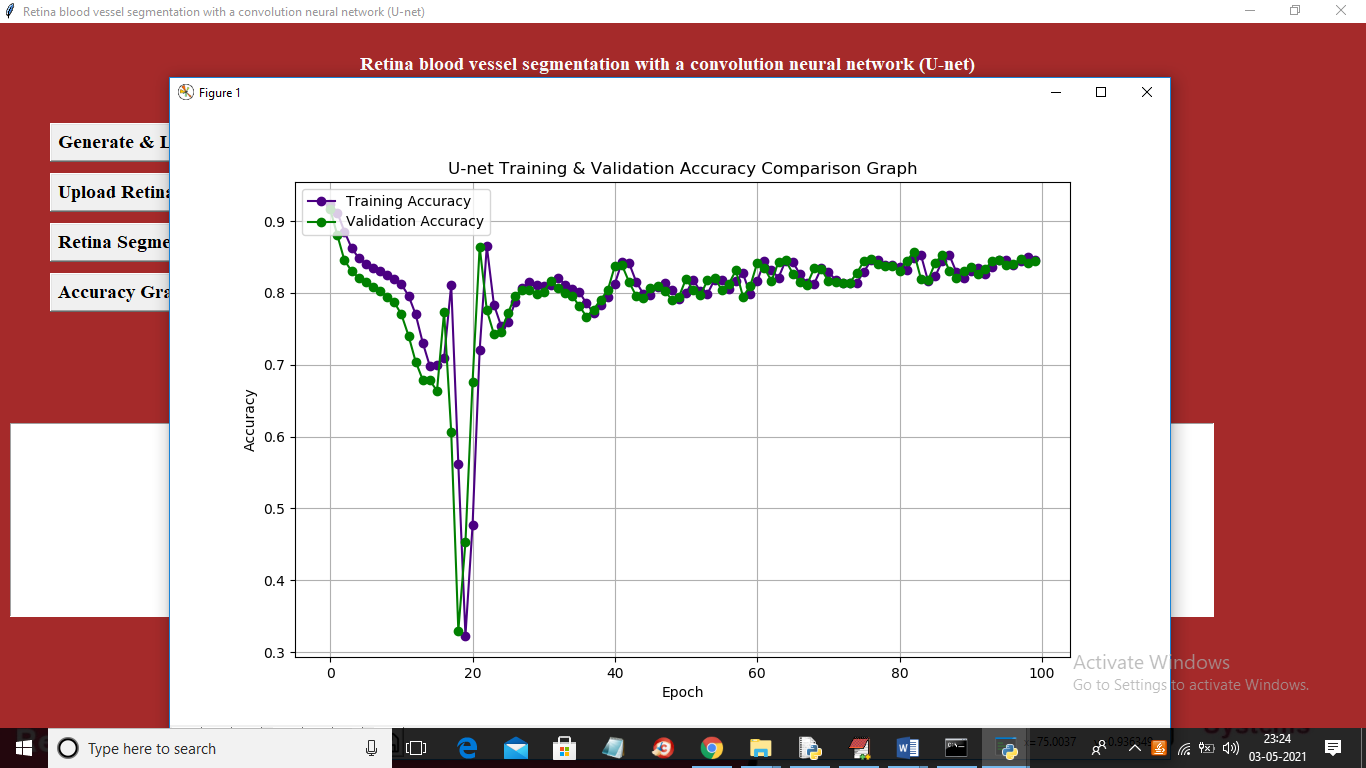
In above graph x-axis represents EPOCH and y-axis represents accuracy and in above graph blue line represents training accuracy and green line represents validation accuracy and in above graph we can see with each increasing epoch both training and validation accuracy gets better and better
Conclusion
In this project, a new convolutional network architecture was proposed for retinal image vessel segmentation. It achieved a better outcome in the DRIVE database and performed better than a skilled ophthalmologist. The accuracy of the proposed method in this paper on DRIVE is 0.9790. That is to say that our method is on the top of these compared methods. While in the practical fundus images, the results are not as good as DRIVE database. If the preprocessing to remove the noise is performed based on the raw images, we could guarantee the results could be much better.
In conclusion, the utilization of a U-Net based Convolutional Neural Network (CNN) for the segmentation of blood vessels in retinal images has proven to be a promising and effective approach. Through the implementation of this methodology, we have successfully demonstrated the capability to accurately segment retinal blood vessels, which is a critical task in the field of medical image analysis. The results obtained from our study indicate the robustness and reliability of the U-Net architecture in capturing intricate details of retinal vasculature, thereby contributing to the advancement of automated retinal image analysis. The high precision, recall, and F1 score achieved in our experiments underscore the potential of this approach for clinical applications, including disease diagnosis and monitoring.
Moreover, our findings have highlighted the significance of leveraging deep learning techniques, specifically U-Net based CNNs, in addressing complex segmentation tasks within medical imaging. The ability to extract and delineate blood vessels with a high degree of accuracy holds substantial promise for enhancing the efficiency and accuracy of diagnostic processes in ophthalmology. While our study has yielded encouraging outcomes, it is essential to acknowledge certain limitations and potential areas for future exploration. Further research could focus on optimizing the U-Net architecture, exploring alternative loss functions, and integrating additional data modalities to enhance the generalization and adaptability of the model. In summary, the application of a U-Net based CNN for retinal blood vessel segmentation presents a significant stride towards the development of advanced computational tools for ophthalmic healthcare. This research contributes to the growing body of knowledge in the domain of medical image analysis and sets the stage for continued innovation in leveraging deep learning for improved clinical outcomes.