
With the growing need for Retrieval-Augmented Generation (RAG) and LLM-powered applications, ensuring their effectiveness is more crucial than ever. While RAG systems enhance language models by grounding responses in external knowledge, their performance can vary based on retrieval quality, relevance, and factual accuracy. This is where evaluation frameworks come into play.
Ragas provides a robust way to assess RAG pipelines, measuring key aspects like faithfulness, relevance, and answer correctness to ensure high-quality responses. Without proper evaluation, even well-designed RAG systems risk generating misleading or hallucinated outputs. In this guide, we’ll explore how to use Ragas to systematically evaluate a RAG system, ensuring it meets reliability standards for real-world applications.
In my previous publication, YouTube Videos Retrieval-Augmented Generation, I detailed the implementation of a timestamped YouTube video RAG pipeline, which enables users to search, summarize, and interact with video content using LLMs. The system integrates transcription, retrieval, and chat memory to provide context-aware responses and enhance knowledge accessibility from videos.
Building on that foundation, this article focuses on the evaluation of the RAG pipeline to assess its retrieval accuracy, faithfulness, and response relevance. Using Ragas, a specialized framework for evaluating retrieval-augmented LLM applications, we will systematically analyze how well the system retrieves and utilizes information from video transcripts. This evaluation will help identify areas for improvement, ensure factual consistency, and optimize performance, making the pipeline more robust and reliable for real-world applications.
Ragas is a comprehensive evaluation framework specifically designed to assess the effectiveness of Retrieval-Augmented Generation (RAG) pipelines. It offers a structured, metric-driven approach to evaluate key aspects of a RAG system’s performance, such as retrieval quality, answer accuracy, and context relevance.
By automating evaluations based on metrics like faithfulness, answer correctness, and context recall, Ragas enables developers to benchmark and optimize their RAG applications systematically. For more detailed information on how Ragas works and to access the full documentation, please visit Ragas Documentation.
![]()
All these steps are well explained in the previous article on ReadyTensor YouTube Videos Retrieval-Augmented Generation. So in order to understand properly please go through the previous article first.
!pip install --upgrade -q lark langchain-chroma youtube-transcript-api langchain_openai langchain-community langgraph langsmith pytube ragas nltk rapidfuzz datasets
from langchain_community.document_loaders import YoutubeLoader import getpass import os from youtube_transcript_api import YouTubeTranscriptApi import json from langchain_community.document_loaders import TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_chroma import Chroma from langchain_core.vectorstores import InMemoryVectorStore from langchain_core.documents import Document from langchain_openai import OpenAIEmbeddings from langchain.retrievers.multi_query import MultiQueryRetriever from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, PromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langgraph.graph import StateGraph, START, END from IPython.display import Image, display from langgraph.checkpoint.memory import MemorySaver from langchain_core.tools import tool from langchain_core.messages import SystemMessage from langgraph.prebuilt import ToolNode from langchain_community.document_loaders.youtube import TranscriptFormat from langgraph.graph import END,START from langgraph.prebuilt import ToolNode, tools_condition from langgraph.graph import MessagesState, StateGraph
def _set_env(var: str): os.environ[var] = getpass.getpass(f"{var}: ") _set_env("OPENAI_API_KEY")
VIDEO CREDITS: carwow
loader = YoutubeLoader.from_youtube_url( "https://www.youtube.com/watch?v=zJIGH3e3uhg", transcript_format=TranscriptFormat.CHUNKS, chunk_size_seconds=60, ) all_splits=loader.load()
llm = ChatOpenAI(model="gpt-4o-mini") embeddings = OpenAIEmbeddings() vector_store = Chroma.from_documents(documents=all_splits, embedding=embeddings)
def format_docs(docs): formatted_docs = [] for doc in docs: metadata_str = ", ".join(f"{key}: {value}" for key, value in doc.metadata.items()) formatted_docs.append(f"{doc.page_content}\nMetadata: {metadata_str}") return "\n\n".join(formatted_docs) @tool(response_format="content_and_artifact") def retrieve(query: str): """Retrieve information related to a query.""" retriever_from_llm = MultiQueryRetriever.from_llm( retriever=vector_store.as_retriever(), llm=llm) retrieved_docs = retriever_from_llm.invoke(query) serialized = format_docs(retrieved_docs) return serialized, retrieved_docs
# Generate an AIMessage that may include a tool-call to be sent. def query_or_respond(state: MessagesState): """Generate tool call for retrieval or respond.""" llm_with_tools = llm.bind_tools([retrieve]) response = llm_with_tools.invoke(state["messages"]) # MessagesState appends messages to state instead of overwriting return {"messages": [response]} # Execute the retrieval. tools = ToolNode([retrieve]) # Generate a response using the retrieved content. def generate(state: MessagesState): """Generate answer.""" # Get generated ToolMessages recent_tool_messages = [] for message in reversed(state["messages"]): if message.type == "tool": recent_tool_messages.append(message) else: break tool_messages = recent_tool_messages[::-1] # Format into prompt docs_content = "\n\n".join(doc.content for doc in tool_messages) system_message_content = ( "You are an assistant for question-answering tasks for particular youtube videos " "Use the following pieces of retrieved context (retrieved from transcript of a youtube video) to answer " "the question. If you don't know the answer, say that you " "don't know. Use three sentences maximum and keep the " "answer concise. Also return accurate single timestamp from where" "you are extracting the answer in this format (start_seconds:----)" "\n\n" f"{docs_content}" ) conversation_messages = [ message for message in state["messages"] if message.type in ("human", "system") or (message.type == "ai" and not message.tool_calls) ] prompt = [SystemMessage(system_message_content)] + conversation_messages # Run response = llm.invoke(prompt) return {"messages": [response]}
graph_builder = StateGraph(MessagesState) graph_builder.add_node(query_or_respond) graph_builder.add_node(tools) graph_builder.add_node(generate) graph_builder.add_edge(START,"query_or_respond") graph_builder.add_conditional_edges( "query_or_respond", tools_condition, {END: END, "tools": "tools"}, ) graph_builder.add_edge("tools", "generate") graph_builder.add_edge("generate", END)
memory = MemorySaver() graph = graph_builder.compile(checkpointer=memory) # Specify an ID for the thread config = {"configurable": {"thread_id": "abc123"}}
def process_input_message(input_message): """ Processes the input message using the global graph and config. Args: input_message (str): The input message to process. Returns: None """ for step in graph.stream( {"messages": [{"role": "user", "content": input_message}]}, stream_mode="values", config=config, ): step["messages"][-1].pretty_print() return step["messages"]
from IPython.display import Image, display display(Image(graph.get_graph().draw_mermaid_png()))
input_message = "What cars were used?" results=process_input_message(input_message)
In this part evals will be explained along with the metrics.
This measures the factual consistency of the generated answer against the given context. It is calculated from answer and retrieved context. The answer is scaled to (0,1) range. Higher the better.
The generated answer is regarded as faithful if all the claims made in the answer can be inferred from the given context. To calculate this, a set of claims from the generated answer is first identified. Then each of these claims is cross-checked with the given context to determine if it can be inferred from the context.
The evaluation metric, Answer Relevancy, focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information and higher scores indicate better relevancy. This metric is computed using the question, the context and the answer.
Context Precision is a metric that evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Ideally all the relevant chunks must appear at the top ranks. This metric is computed using the question, ground_truth and the contexts, with values ranging between 0 and 1, where higher scores indicate better precision.
Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed using question, ground truth and the retrieved context, and the values range between 0 and 1, with higher values indicating better performance. To estimate context recall from the ground truth answer, each claim in the ground truth answer is analyzed to determine whether it can be attributed to the retrieved context or not. In an ideal scenario, all claims in the ground truth answer should be attributable to the retrieved context.
This metric gives the measure of recall of the retrieved context, based on the number of entities present in both ground_truths and contexts relative to the number of entities present in the ground_truths alone. Simply put, it is a measure of what fraction of entities are recalled from ground_truths. This metric is useful in fact-based use cases like tourism help desk, historical QA, etc. This metric can help evaluate the retrieval mechanism for entities, based on comparison with entities present in ground_truths, because in cases where entities matter, we need the contexts which cover them.
The concept of Answer Semantic Similarity pertains to the assessment of the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the ground truth and the answer, with values falling within the range of 0 to 1. A higher score signifies a better alignment between the generated answer and the ground truth. Measuring the semantic similarity between answers can offer valuable insights into the quality of the generated response. This evaluation utilizes a cross-encoder model to calculate the semantic similarity score.
The assessment of Answer Correctness involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the ground truth and the answer, with scores ranging from 0 to 1. A higher score indicates a closer alignment between the generated answer and the ground truth, signifying better correctness. Answer correctness encompasses two critical aspects: semantic similarity between the generated answer and the ground truth, as well as factual similarity. These aspects are combined using a weighted scheme to formulate the answer correctness score.
from datasets import Dataset from ragas.metrics import faithfulness,answer_relevancy,context_precision,context_recall,context_entity_recall,answer_similarity,answer_correctness from ragas import evaluate
To ensure compatibility with the framework, we need to structure our data in the specified format before converting it into a dataset. The framework relies on exact column names for evaluation. Below, we demonstrate the process using a single example, but multiple test sets can be created, stored in this format, and passed to the evaluator as needed.
data_samples = { 'question': [results[0].content], 'answer': [results[3].content], 'ground_truth': ["Bobcat's tech stack includes Raspberry Pi 4B, Arducam IMX708 Camera, Audio Core HAT WM8060, and an integrated microphone & speakers for hardware, while the software stack features DeepFace for facial recognition, Speech Recognition for transcription, OpenAI GPT-3.5 Turbo for empathetic chat responses, TTS-1-HD for natural voice synthesis, and UDIO for AI-generated song composition, all working together in a pipeline that processes facial and voice input, performs sentiment analysis, generates responses, and creates personalized music."], 'contexts':[results[2].content.split('\n\n')] }
dataset = Dataset.from_dict(data_samples) score = evaluate(dataset,metrics=[faithfulness,answer_relevancy,context_precision,context_recall,context_entity_recall,answer_similarity,answer_correctness])
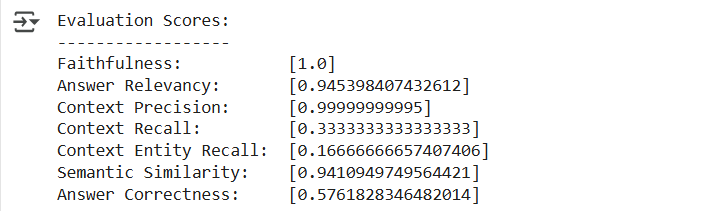
# Print the scores in a readable format print("Evaluation Scores:") print("------------------") print(f"Faithfulness: {score['faithfulness']}") print(f"Answer Relevancy: {score['answer_relevancy']}") print(f"Context Precision: {score['context_precision']}") print(f"Context Recall: {score['context_recall']}") print(f"Context Entity Recall: {score['context_entity_recall']}") print(f"Semantic Similarity: {score['semantic_similarity']}") print(f"Answer Correctness: {score['answer_correctness']}")
Along with evaluation, RAGAS also provides a streamlined approach to testset generation for RAG pipelines. This enables developers to create high-quality, structured datasets to systematically assess and refine their retrieval-augmented generation models.
from ragas.llms import LangchainLLMWrapper from ragas.embeddings import LangchainEmbeddingsWrapper from langchain_openai import ChatOpenAI from langchain_openai import OpenAIEmbeddings from ragas.testset import TestsetGenerator import pandas as pd generator_llm = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o")) generator_embeddings = LangchainEmbeddingsWrapper(OpenAIEmbeddings())
generator = TestsetGenerator(llm=generator_llm, embedding_model=generator_embeddings) bulk_dataset = generator.generate_with_langchain_docs(all_splits, testset_size=5) bulk_dataset.to_pandas()

# Convert bulk_dataset to a pandas DataFrame bulk_df = bulk_dataset.to_pandas() # Rename the columns bulk_df.rename(columns={'user_input': 'question', 'reference': 'ground_truth'}, inplace=True) # Define a function to process the input message and extract the required fields def process_and_extract(input_message): results = process_input_message(input_message) answer = results[3].content contexts = results[2].content.split('\n\n') return answer, contexts # Apply the function to the question column and create new columns for the results bulk_df[['answer', 'contexts']] = bulk_df['question'].apply(lambda x: pd.Series(process_and_extract(x))) # Convert the DataFrame to a dictionary data_dict = bulk_df.to_dict(orient='list') # Create a HuggingFace dataset from the dictionary syn_dataset = Dataset.from_dict(data_dict)
bulk_score = evaluate(syn_dataset,metrics=[faithfulness,answer_relevancy,context_precision,context_recall,context_entity_recall,answer_similarity,answer_correctness]) bulk_score.to_pandas()
| user_input | retrieved_contexts | reference_contexts | response | reference | faithfulness | answer_relevancy | context_precision | context_recall | context_entity_recall | semantic_similarity | answer_correctness |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Wut is carwow? | [Square Four Points each interesting testing t... | [which is the best off-road the new Toyota Lan... | The cars used in the video are the new Toyota ... | Carwow is a platform where vehicles are compar... | 1.0 | 0.765041 | 0.500000 | 1.000000 | 0.500000 | 0.826911 | 0.206728 |
| Who is Graham in the off-road event context? | [Square Four Points each interesting testing t... | [Toyota sent on the car and they knew what we ... | The cars used in the video are the new Toyota ... | Graham is the judge for the off-road event. | 1.0 | 0.751010 | 0.366667 | 1.000000 | 0.333333 | 0.784063 | 0.196016 |
| Land Cruiser performance in rock crawl competi... | [Square Four Points each interesting testing t... | [expert and he's about to start the race 2 1 [... | The cars used in the video are the new Toyota ... | The Land Cruiser achieved a clear win, indicat... | 1.0 | 0.790856 | 0.000000 | 0.000000 | 0.000000 | 0.852351 | 0.213088 |
| How did the Land Rover Defender perform in the... | [Square Four Points each interesting testing t... | [<1-hop>\n\nwhich is the best off-road the new... | The cars used in the video are the new Toyota ... | In the off-road challenges, the Land Rover Def... | 1.0 | 0.793777 | 0.887500 | 0.333333 | 1.000000 | 0.878998 | 0.219751 |
| How did the Land Rover Defender perform in the... | [Square Four Points each interesting testing t... | [<1-hop>\n\nToyota sent on the car and they kn... | The cars used in the video are the new Toyota ... | In the off-road competition, the Land Rover De... | 1.0 | 0.794652 | 0.950000 | 0.000000 | 0.500000 | 0.855751 | 0.213938 |
| How does the Land Rover Defender perform in of... | [Square Four Points each interesting testing t... | [<1-hop>\n\nwhich is the best off-road the new... | The cars used in the video are the new Toyota ... | The Land Rover Defender, along with the Toyota... | 1.0 | 0.793409 | 1.000000 | 1.000000 | 1.000000 | 0.873348 | 0.564491 |
RAGAS simplifies the evaluation of Retrieval-Augmented Generation (RAG) systems by providing an easy-to-use framework while incorporating complex and essential concepts like faithfulness, answer correctness, and context precision. Though straightforward in implementation, understanding these metrics is crucial for building reliable, scalable, and high-performing LLM-based systems.
