![]()
TL;DR
This project presents a query-based topic modeling approach aimed at identifying emerging and trending topics within a specific scientific domain, leveraging NLP techniques on a large corpus of abstracts. The process involves encoding abstracts using the “allenai-specter” SBERT model, clustering similar abstracts via HDBSCAN, and performing topic modeling with Latent Dirichlet Allocation (LDA). This method allows for trend analysis to highlight rising themes within the domain, which are then summarized using GPT-3.5-turbo. The approach was tested on the field of Natural Language Processing (NLP), uncovering key topics like pretrained language models, multimodal processing, and text generation techniques.
Abstract
The number of scientific publications grows every year. This growth has contributed to the continuous emergence of new trends across various scientific domains, where researchers and investors are eager to predict these trends in advance. Using Natural Language Processing (NLP) techniques, I aimed to develop a topic modeling approach to identify possible emerging trendy topics in a predetermined scientific field based on a given query and a set of thousands of abstracts. The proposed approach involves abstracts preprocessing, abstracts and query encoding with the “allenai-specter” Sentence-BERT (SBERT) model, retrieving abstracts similar to the user query, and clustering them using the Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) algorithm. Subsequently, Latent Dirichlet Allocation (LDA) is applied to each cluster for topic modeling, and the resulting topics are labeled and analyzed over time to discover their trending status. Finally, abstracts discussing these emerging topics are summarized using the OpenAI “gpt-3.5-turbo-0125” model. Our approach, combining these technologies, achieved its objectives. Tested on data from 2016 to 2023, it accurately identified and summarized relevant emerging trends within the specified field in that period.
Introduction
In today's digital age, the exponential growth of information, driven by the internet, has resulted in a vast and diverse range of textual content, from personal stories to significant scientific discoveries. This massive influx of data, from sources like social media and academic databases, presents the challenge of accurately interpreting words in their contextual meaning.
As staying informed on the latest news, trends, and scientific advancements becomes increasingly important, the demand for automated methods to analyze and extract insights from textual data has surged. Whether it's tracking emerging scientific trends, monitoring public sentiment, or enhancing language translation, artificial intelligence, particularly Natural Language Processing (NLP), plays a crucial role in addressing these challenges.
One promising application of NLP is in analyzing research literature. With scientific knowledge constantly evolving, researchers face the daunting task of navigating extensive collections of research papers to uncover emerging trends and discoveries. Manual analysis is impractical, necessitating the development of automated techniques for trend analysis and knowledge discovery.
This study leverages NLP techniques to analyze a large corpus of research abstracts across various scientific fields. The goal was to develop a query-based topic modeling approach that identifies trending topics within a specific field and presents them in variable-length summaries.
Data Collection and Preprocessing
For this project, a dataset provided by Kaggle is used. This dataset is a comprehensive collection of research papers from the computer science domain, comprising over 200,000 papers. It is well-suited for tasks related to text classification, topic modeling, and other Natural Language Processing (NLP) tasks, which aligns with the objectives of the project.
Initially, we focused on extracting research papers related to Artificial Intelligence (AI) to test our pipeline. To efficiently gather relevant papers, we aimed to include those that broadly associate with AI, allowing us to capture a wider range of topics. We then modified the dataset to facilitate analysis by segmenting the publication dates into year and month. Papers published between 2016 and 2023 were selected, which was essential for conducting trend analyses on publication patterns over time. After all the processing and preparation steps, more than 23,000 papers related to the AI field were obtained, spanning from 2016 to 2023.
Methodology
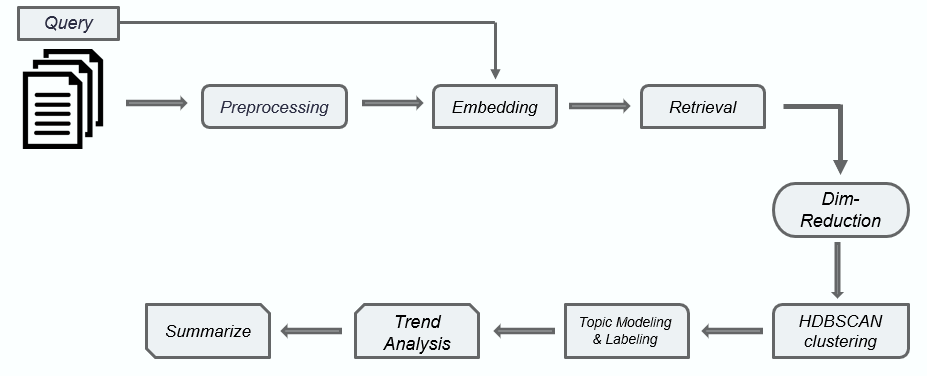
The approach taken in this project consisted of several steps, and in the following, each of these steps will be thoroughly examined.
1-Abstracts Preprocessing
The decision to use abstracts as representatives of entire research papers was based on several factors. Firstly, abstracts are concise summaries of key points, making them suitable for topic modeling. Secondly, their shorter length simplifies preprocessing, saving both time and resources. Additionally, acquiring datasets of abstracts is generally easier than obtaining full research papers, and similar studies have successfully used abstracts, yielding positive results.Abstract preprocessing is a crucial step in the pipeline, leading to more accurate embeddings that capture the contextual and semantic meaning of words within the text [1]. For this project, basic preprocessing was performed using the Natural Language Toolkit (NLTK) in Python, which involved removing common English stop words, performing word lemmatization to transform words into their base forms based on context, and removing any irrelevant data, like URLs.
2- Abstracts and Query Embedding
Encoding the preprocessed abstracts and the query is a crucial step in the pipeline, as the quality of embeddings significantly impacts the results in subsequent stages. Traditional methods like TF-IDF are insufficient for capturing contextual meanings, which are essential for clustering and topic modeling. Instead, transformer-based language embeddings are preferred due to their improved runtime efficiency in similarity calculations.Among the available models on HuggingFace, such as “all-MiniLM-L6-v2,” “all-mpnet-base-v2,” and “allenai-specter,” the latter was selected after experimentation. The “allenai-specter” model is specifically designed for estimating similarities between publications and yielded the best results for our task. The decision was made to use sentence-BERT (SBERT) over Bidirectional Encoder Representations from Transformers (BERT), as SBERT is more effective for generating sentence embeddings [2].
3-Relevant Abstracts to Query Retrieval
A key step in the framework is retrieving relevant abstracts based on the entered query. This is commonly achieved by computing the similarity between the embeddings of each abstract and the query. Abstracts exceeding a certain similarity threshold are considered relevant. Various methods, such as cosine similarity and Euclidean distance, can be used to compute this similarity.Various methods can be used to compute similarity, such as cosine similarity and Euclidean distance. For this project, cosine similarity is regarded as the optimal choice for handling embeddings of text data, as it effectively measures the angular distance between vectors in high-dimensional space, making it suitable for text analysis.
4-Clustering
Clustering abstracts plays a crucial role in optimizing the topic extraction process by grouping similar abstracts, thereby simplifying dataset complexity. Initially, K-means clustering was employed but faced challenges in determining the optimal number of clusters and handling noise effectively. To overcome these issues, HDBSCAN clustering was adopted for its ability to automatically determine cluster numbers based on density and connectivity [3].However, applying HDBSCAN directly to high-dimensional embeddings resulted in most data points being labeled as noise and uneven cluster sizes due to the curse of dimensionality. To mitigate these challenges, dimensionality reduction techniques, specifically Uniform Manifold Approximation and Projection (UMAP), were utilized. UMAP was preferred over Principal Component Analysis (PCA) for its capability to handle complex data characteristics while preserving the integrity of global structures.
5-Topic Modeling and Labelling
In the topic modeling stage of the pipeline, Latent Dirichlet Allocation (LDA) was applied to each cluster independently. To determine the optimal number of topics, various values were tested based on the highest coherence score, which measures the semantic similarity between words within each topic. Due to LDA's inherent variability in topic generation [4], each topic value underwent multiple consecutive runs, with the selection based on the highest average coherence score.In this project, topic numbers ranging from 5 to 10 were experimented with, conducting 20 trials for each topic number. To provide meaningful titles for each topic based on their word distributions, manual labeling was performed using generative AI tools. For this project, Microsoft’s Copilot was utilized, as it produced more relevant and meaningful labels compared to GPT-3.5.
6- Trend Analysis
In this stage, the goal was to identify trending and emerging topics within the specified field by analyzing publication trends over time. Initially, the approach involved plotting the number of publications annually. However, this method had drawbacks due to the uneven distribution of papers across different years in the dataset, which led to biased results and made it difficult to distinguish genuine trends from artifacts caused by dataset irregularities.To overcome this challenge, alternative methodologies were explored. One method involved calculating the percentage of papers associated with each topic relative to the total number of retrieved papers over multiple years. While this approach provided a normalized view of topic popularity and mitigated the impact of uneven distributions, it also introduced fluctuations. To smooth out these variations, the moving average technique was employed, averaging adjacent data points over a specified window to highlight underlying trends more clearly.
7-Abstracts Summarization
This stage aims to perform abstractive summarization on abstracts discussing the identified trending topics. Abstractive summarization utilizes natural language techniques to interpret text and generate human-like summaries. Initially, models like PEGASUS, BART, and T5 were tested but produced unsatisfactory results. Consequently, the decision was made to use the GPT-3.5 turbo model, specifically “gpt-3.5-turbo-0125.”A limitation encountered was the model’s context window. To address this, topic labels were embedded and compared with the abstract embeddings, prioritizing abstracts that showed higher similarity to the topic labels. In this project, the top 50 abstracts were selected for summarization.
Results
In this section, the results of some stages in the framework are discussed. For testing purposes, a specific query from the user was assumed, specifying Natural Language Processing as the scientific field to be examined. On using this query, 3044 abstracts were retrieved in the abstracts retrieval stage.
1- Clustering Results
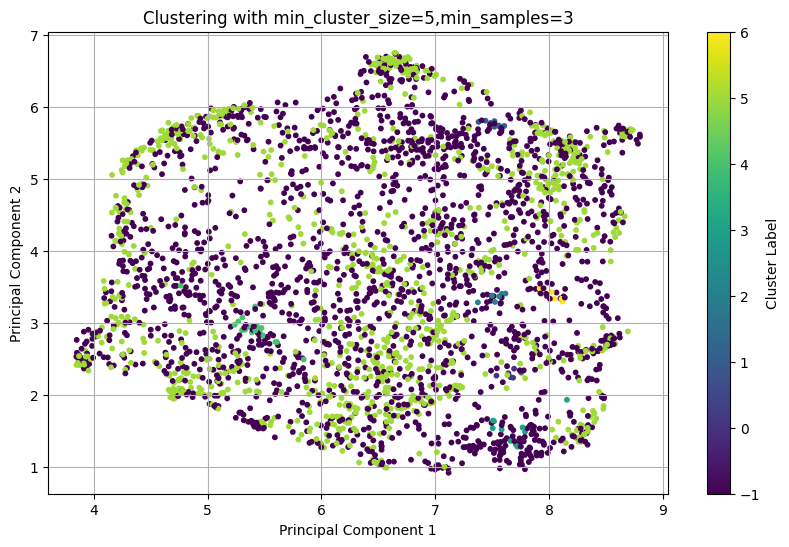
In this subsection, I wanted to show the effect of applying UMAP dimensionality reduction on the clustering results.Before UMAP:
7 Clusters were generated with the following distribution:
| Topic(s) Number | Label |
|---|---|
| Cluster 0 | Number of abstracts: 6 |
| Cluster 1 | Number of abstracts: 8 |
| Cluster 2 | Number of abstracts: 7 |
| Cluster 3 | Number of abstracts: 12 |
| Cluster 4 | Number of abstracts: 20 |
| Cluster 5 | Number of abstracts: 1070 |
| Cluster 6 | Number of abstracts: 7 |
| Cluster -1 (Noise) | 1914 |
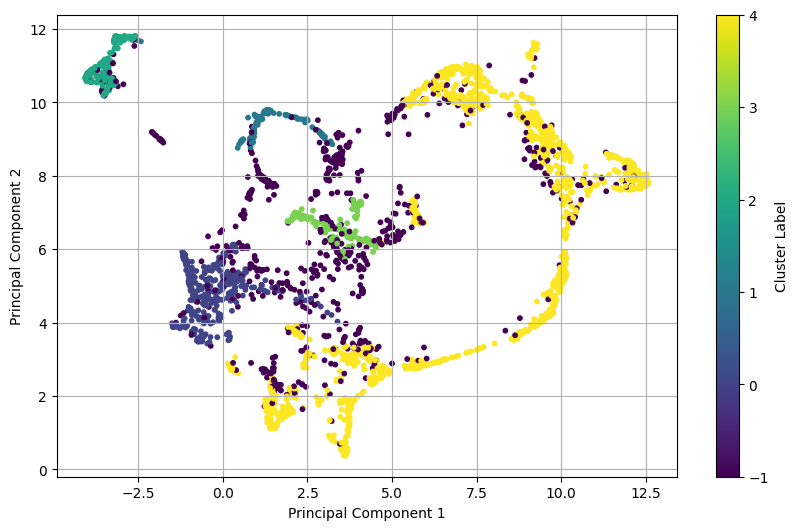
After UMAP:
5 Clusters were generated with the following distribution:
| Topic(s) Number | Label |
|---|---|
| Cluster 0 | Number of abstracts: 376 |
| Cluster 1 | Number of abstracts: 130 |
| Cluster 2 | Number of abstracts: 186 |
| Cluster 3 | Number of abstracts: 170 |
| Cluster 4 | Number of abstracts: 148 |
| Cluster -1 (Noise) | 702 |
2- Topic Modeling and Labeling Results
The topic distribution and labels per each cluster are as follows:
Cluster 0:
| Topic(s) Number | Label |
|---|---|
| Topic 0 | Multilingual Translation and Language Models |
| Topic 1 | Task-Specific Models and NLP Performance |
| Topic 2 | Performance Optimization and Pretrained Language Models |
| Topic 3 | Adversarial Learning and Attack Resilience in NLP |
| Topic 4 | Word Embeddings, Text Representation, and Sentence-Level Models |
Cluster 1:
| Topic(s) Number | Label |
|---|---|
| Topics 0, 2, 3, 5, and 8 | Multimodal Language Processing and Speech Technologies |
| Topics 1 and 7 | Conversational Systems and Audio-Visual Event Understanding |
| Topics 4 and 6 | Pattern Recognition in Audio and Language Systems |
Cluster 2:
| Topic(s) Number | Label |
|---|---|
| Topics 0, 2, 4, and 6 | Emotional and Social Media Analysis |
| Topics 1, 3, 5, and 8 | Sentiment, Bias, and Content Analysis |
| Topic 7 | Assessment of Sentiment and Content Analysis Models |
Cluster 3:
| Topic(s) Number | Label |
|---|---|
| Topics 0 and 4 | Human-Centric and Task-Oriented Large Language Models |
| Topics 1 and 5 | Code Generation, Reasoning, and Bias in Large Language Models |
| Topics 2 and 7 | Text Generation Methods and Algorithmic Advances in Large Language Models |
| Topics 3 and 6 | Data-Driven Text Generation and Pattern Recognition |
Cluster 4:
| Topic(s) Number | Label |
|---|---|
| Topic 0 | Learning Algorithms and Model Performance in Processing Language Data |
| Topic 1 | Information Retrieval Systems |
| Topic 2 | Logic and Domain-Specific Languages |
| Topic 3 | Feature Learning and Methodology |
| Topic 4 | Graph-Based Learning Systems |
| Topic 5 | Question Answering and Information Extraction |
| Topic 6 | Neural Networks and Language Processing for Knowledge Extraction |
It should be noted that certain topics within clusters have been merged into broader labels to provide more general and descriptive topic descriptions.
3- Trend Analysis Results
In this subsection, I want to show the result of the different tried methods for analyzing the topics' trends. For visualization purposes, I'll show the graphs obtained from Cluster2.Method 1
Analyzing based on the papers count.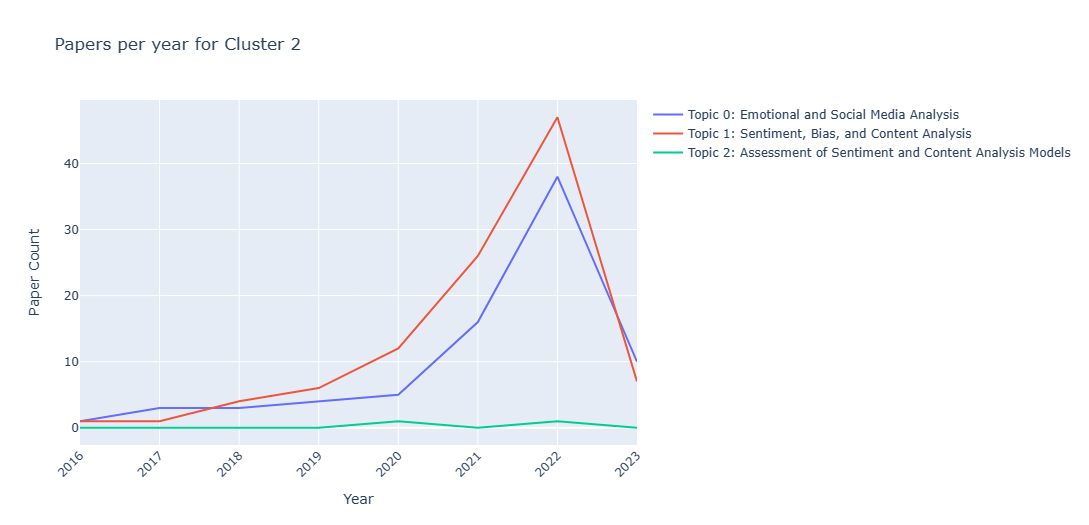
Method 2
Analyzing based on the papers count but with normalized ratios.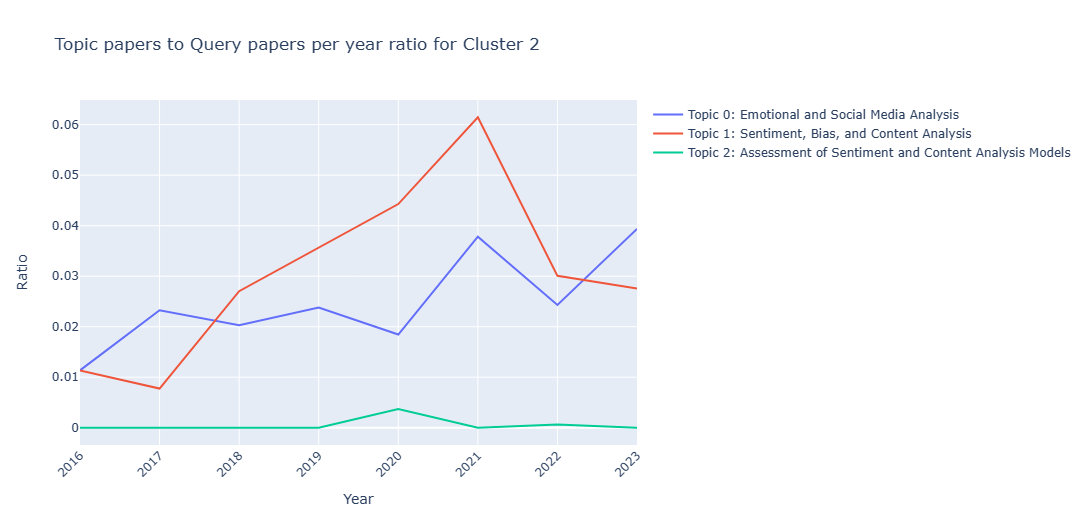
Method 3
Analyzing based on the papers count but with normalized ratios. using the moving average method with window size of 5.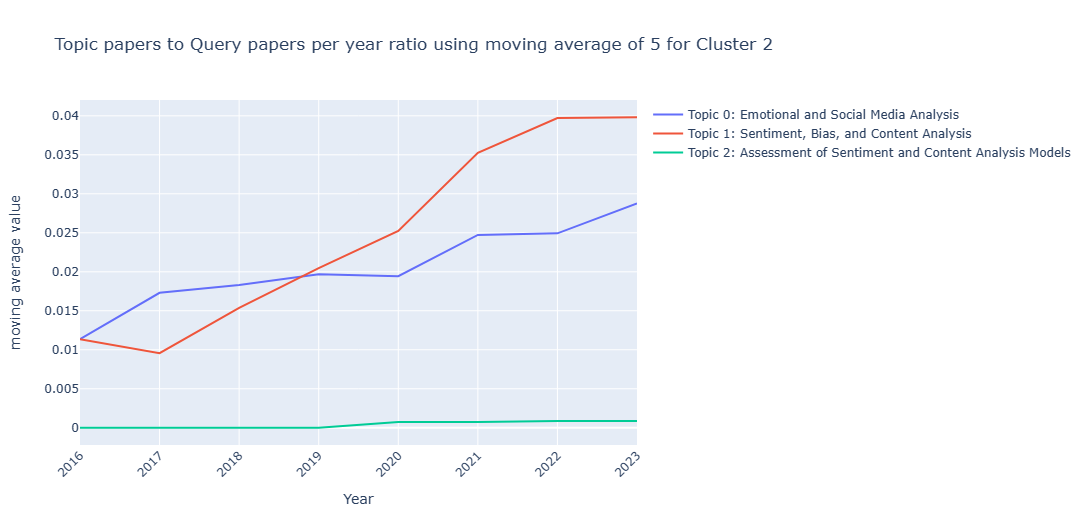
After analyzing all clusters, these are the topics found to be trending:
| Topic(s) Number | Emerging Topics |
|---|---|
| Cluster 0 | “Task-Specific Models and NLP Performance” and “Performance Optimization and Pretrained Language Models” |
| Cluster 1 | “Multimodal Language Processing and Speech Technologies” |
| Cluster 2 | “Sentiment, Bias, and Content Analysis” |
| Cluster 3 | All topics |
| Cluster 4 | No topic |
Conclusion
Analyzing scientific publications is a promising application of NLP. With the constant growth of scientific knowledge and the daily emergence of new topics, tracking these trends has become increasingly important. This paper aimed to overcome the lack of generality in previous approaches by developing a query-based topic modeling method that extracts emerging topics related to a specified scientific domain from a large set of paper abstracts covering various fields.
The approach comprises several stages: starting with abstracts preprocessing, followed by encoding the query and abstracts using the “allenai-specter” SBERT model. It then retrieves abstracts relevant to the query, clusters them using HDBSCAN, and performs topic modeling using LDA. Topics are labeled using Microsoft’s Copilot generative AI, followed by trend analysis and abstractive summarization using OpenAI’s “gpt-3.5-turbo-0125” model.
This method was tested on the domain of “NLP” and yielded satisfactory results, identifying approximately eight trending NLP topics.
As for the limitations, the approach faced challenges in operating dynamically across all stages. Human intervention is necessary for parameter tuning in the dimensionality reduction and clustering stages, as well as for labeling topics and conducting trend analyses. Another limitation is the variability inherent in the employed methods; techniques such as UMAP, LDA, and the labeling method are known to produce slightly different results upon each use. Therefore, rerunning the algorithms used in this paper, even with the same parameters and steps, may not yield identical results. Nevertheless, any differences observed are not radical.
References
[1] Schofield, A., Magnusson, M., Thompson, L., Mimno, D. (2017, July). Understanding text pre-processing for latent Dirichlet allocation. In Proceedings of the 15th conference of the European chapter of the Association for Computational Linguistics (Vol. 2, pp. 432-436).
[2] Reimers, N., Gurevych, I. (2019). Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv
.10084.[3] Campello, R. J., Moulavi, D., Sander, J. (2013, April). Density-based clustering based on hierarchical density estimates. In Pacific-Asia conference on knowledge discovery and data mining (pp. 160-172). Berlin, Heidelberg: Springer Berlin Heidelberg.
[4] Blei, D. M., Ng, A. Y., Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.