
TL;DR
In this project, we focused on predicting drone energy consumption using a Random Forest regression model. We trained the model using key features such as wind speed, altitude, payload weight, and speed, achieving an RMSE of 7.95 and an R² of 0.95. To go beyond just accuracy, we incorporated SHAP values to enhance the explainability of the model. This allowed us to break down the contribution of each feature to individual energy consumption predictions, providing drone operators with deeper insights and enabling more informed, energy-efficient decision-making
Introduction
In this project, we set out to predict drone energy consumption by leveraging a dataset containing detailed information on various factors influencing energy usage, including wind speed, altitude, payload weight, and more. Our primary objective was to develop a reliable regression model capable of accurately forecasting power consumption, which would help in optimizing resource planning and improving operational decision-making.
However, in real-world scenarios—especially in energy management—accuracy alone is not enough. It is equally important to understand how the model arrives at its predictions. To address this, we incorporated SHAP values to ensure that our model is not only accurate but also interpretable and transparent. This approach allowed us to break down the contribution of different features to each individual prediction, offering critical insights into energy consumption dynamics.
Through this project, we demonstrate how building an interpretable regression model for drone energy consumption can lead to more informed and efficient operational strategies, with SHAP values playing a key role in explaining the model's decisions.
Motivation
With the increasing deployment of small drones in critical applications such as aerial imaging, delivery services, and disaster response, optimizing energy consumption has become essential for extending flight durations and ensuring mission success. Inaccurate energy consumption predictions can lead to operational inefficiencies, reduced flight range, and, in extreme cases, mission failure. This challenge becomes even more pronounced in swarm deployments, where efficient collective energy management is crucial.
In this project, we set out to develop accurate energy models that not only predict energy consumption but also help identify the most energy-efficient flight speeds and configurations. By doing so, we aim to maximize operational efficiency and improve mission outcomes. Furthermore, we provide a cost function tailored for managing energy consumption in swarm operations, optimizing overall performance and enhancing the success rate of drone missions.
Dataset Overview
At the core of our project is a dataset that captures various factors influencing drone energy consumption, including wind speed, altitude, and drone weight. Each of these features plays a critical role in determining the power consumption of the drone, and our task is to predict the actual power consumption in watts based on this data.
The objective of this regression task is to develop a model that can reliably estimate energy consumption using the provided features. This dataset offers a valuable opportunity to analyze how these different factors interact and affect energy usage, giving us a practical framework for building and refining our predictive model.
Although the dataset is not publicly available, it can be shared upon reasonable request.
Building the Regression Model
Our first objective was to build a robust regression model to predict drone energy consumption. For this, we used a Random Forest Regressor, which is well-suited for tabular data and can handle both linear and non-linear relationships between the features and the target variable.
We trained the model using the features provided in the dataset, which include:
- Wind (m/s): The speed of the wind, which affects the power needed to stabilize or move the drone.
- Speed (m/s): The drone's speed, one of the most significant factors in determining energy consumption.
- Altitude (m): The height at which the drone is flying.
- Weight (g): The weight of the drone, which influences the energy required to keep it aloft.
Once the model was trained, we evaluated it on the test set using Root Mean Squared Error (RMSE). The RMSE on the test set was 7.95, and the R-squared value was 0.95, indicating a strong fit between the predicted and actual energy consumption.
Imports and preprocessing
import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error train_file = './drone_energy/drone_energy_train.csv' test_file = './drone_energy/drone_energy_test.csv' y_test_file = './drone_energy/drone_energy_test_key.csv' train_data = pd.read_csv(train_file) test_data = pd.read_csv(test_file) y_test = pd.read_csv(y_test_file) train_data.drop(columns=['Move', 'Equivalent Wind (m/s)'], inplace=True) test_data.drop(columns=['Move', 'Equivalent Wind (m/s)'], inplace=True) X_train = train_data.drop(columns=['Sample Id', 'Calc. Power (W)']) y_train = train_data['Calc. Power (W)'] X_test = test_data.drop(columns=['Sample Id']).copy()
Model Training & Evaluation
model = RandomForestRegressor(n_estimators=100, random_state=42) model.fit(X_train, y_train) predictions = model.predict(X_test) mse = mean_squared_error(y_test['Calc. Power (W)'], predictions) rmse = round(np.sqrt(mse), 2) r_squared = r2_score(y_test['Calc. Power (W)'], predictions) r_squared = round(r_squared, 2) print(f'RMSE: {rmse}') print(f'R^2: {r_squared}')
output:
RMSE: 7.95
R^2: 0.95
The Need for Explainability in Regression
After successfully training a high-performing regression model, we needed to go beyond accuracy and assess the model's interpretability. In real-world applications such as energy management for drones, it is essential to understand why the model makes certain predictions. Stakeholders often require justifications for the reasoning behind predictions, and relying on a "black box" model can lead to trust issues.
For instance, if the model predicts a significant increase in power consumption, it is crucial to identify which factors—such as wind speed or weight—are driving this increase. SHAP values allow us to achieve this by attributing the prediction to individual features, enabling us to clearly see how much each feature contributes to the final output.
Introduction to Explainable AI (XAI)
In our project, transparency and interpretability were crucial when developing the model for predicting drone energy consumption. We implemented Explainable AI (XAI) techniques to ensure that the model's predictions could be understood and trusted by stakeholders, especially since the model's outputs would guide critical decisions in energy management.
To achieve this, we used SHAP values, which allowed us to break down the model's predictions by quantifying how much each feature—such as wind speed, altitude, or weight—contributed to the predicted energy consumption. This enhanced the transparency of the model’s decision-making process, making it more reliable and actionable for real-world applications.
Understanding Shapley Values
Shapley values, a key part of our XAI approach, helped us distribute the impact of each feature on the final prediction by considering all possible combinations of feature interactions. This provided a clear understanding of each feature's contribution to the model's output.
Though calculating Shapley values can be computationally intensive, we utilized efficient algorithms from libraries like SHAP, making the process feasible and enhancing the interpretability of our model without sacrificing performance.
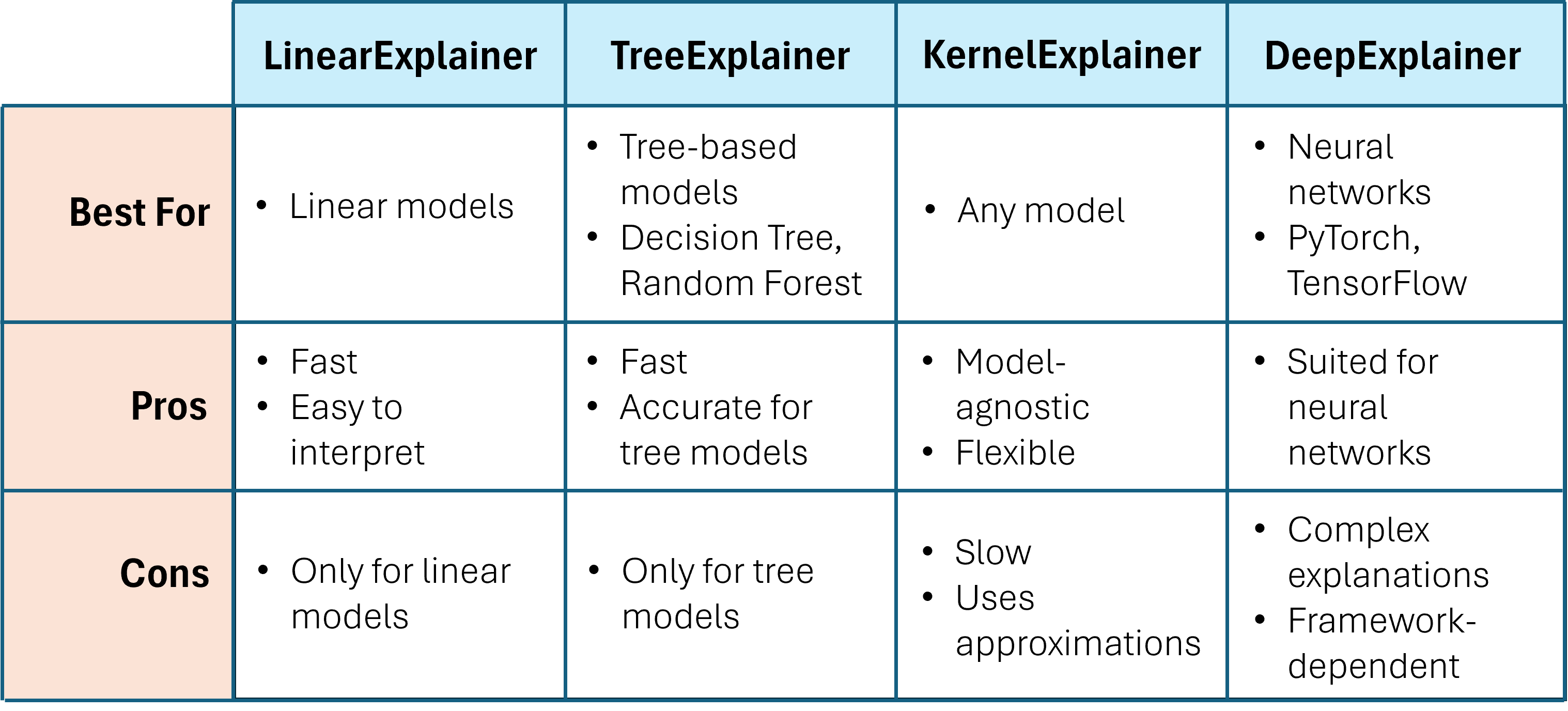
Explainers
In our project, understanding why the model made certain predictions was just as important as achieving accurate results. To provide these insights, we used model explainers to analyze the contribution of each feature to the predictions. The SHAP library offers several explainers tailored to different types of models. Below is a breakdown of the SHAP explainers we considered—TreeExplainer, DeepExplainer, KernelExplainer, and LinearExplainer—and how we selected the appropriate one for our model.
Using SHAPLEY
Below is an example of how we applied SHAP on the drone energy consumption dataset using a random forest model:
Imports and data pre-processing:
import shap import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestRegressor train_file = './drone_energy/drone_energy_train.csv' test_file = './drone_energy/drone_energy_test.csv' y_test_file = './drone_energy/drone_energy_test_key.csv' train_data = pd.read_csv(train_file) test_data = pd.read_csv(test_file) y_test = pd.read_csv(y_test_file) train_data.drop(columns=['Move', 'Equivalent Wind (m/s)'], inplace=True) test_data.drop(columns=['Move', 'Equivalent Wind (m/s)'], inplace=True) X_train = train_data.drop(columns=['Sample Id', 'Calc. Power (W)']) y_train = train_data['Calc. Power (W)'] X_test = test_data.drop(columns=['Sample Id']).copy()
Model training and Shap explanations:
model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train) explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X_test)
Expected Value
explainer.expected_value.round(2)
output:
array([162.32])
In this regression task, the expected value represents the model’s average prediction across the training data. If no information were available about the input features, the model would predict 162.32 watts as the energy consumption.
SHAP Values for Features
feature_names = X_train.columns shap_instance = shap_values[0] shap_instance = {feature_names[i]: round(shap_instance[i].tolist(), 2) for i in range(len(feature_names))} print(shap_instance)
output:
{
'Wind (m/s)': 13.89,
'Speed (m/s)': 98.56,
'Altitude (m)': 0.94,
'Weight (g)': -19.92
}
This output provides the SHAP values for a single prediction, which explain the contribution of each feature to the model's final prediction for that instance. Let's break down what these SHAP values mean.
-
Wind (m/s): 13.89 – The "Wind (m/s)" feature increases the model's prediction by around 13.88 units. This indicates that when the wind speed increases, the prediction made by the model is also expected to increase, relative to the baseline prediction.
-
Speed (m/s): 98.56 – The "Speed (m/s)" feature is the largest contributor, adding a whopping 98.55 units to the model's prediction. This is the most influential feature for this instance, showing that speed has a very strong positive impact on the prediction.
-
Altitude (m): 0.94 – The "Altitude (m)" feature slightly increases the prediction by around 0.94 units.
-
Weight (g): -19.92 – The "Weight (g)" feature has a significant negative contribution, reducing the prediction by 19.91 units. This means heavier instances tend to lower the model’s predictions for this specific case.
In SHAP, every prediction is explained as a sum of feature contributions (SHAP values) starting from the model’s expected value, which is the mean prediction over the entire dataset if no features were known. For example, if the expected prediction of the model for the entire dataset is 162.32 (this is called the base value), the final prediction for this specific instance is calculated as:
Final Prediction = Expected Value + Sum of SHAP Values
Final Prediction = 162.32 + (13.89 + 98.56 + 0.94 - 19.92) = 255.79
If you try predicting this sample with the model, you will get the same number
round(float(model.predict(X_test)[0]), 2)
output:
255.79
Plots
SHAP offers powerful visualization tools, such as summary plots and force plots, to interpret how features contribute to model predictions. Below, we explore these plots and provide examples of how they were used in our project to better understand the model’s behavior.
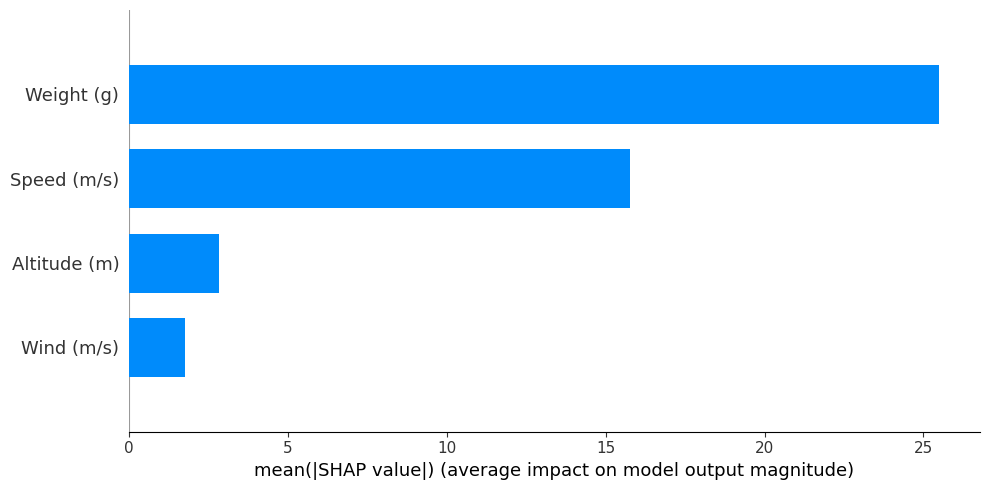
Summary Plot
The Summary Plot aggregates SHAP values for all features across the dataset, giving a clear view of feature importance and impact. It highlights which features have the greatest influence on predictions and shows the direction of that influence.
shap.summary_plot(shap_values, X_test, plot_type="bar", plot_size=(10, 5))
This plot shows that Weight and Speed are the most important features that influence the decision of the model.
Force Plot
The Force Plot visualizes the contribution of each feature to a specific prediction, providing a detailed explanation of how individual features shift the model’s output from the base value. This plot is especially useful for examining single predictions, showing exactly how each feature’s value influences the final outcome.
# Displaying force plots for 3 instances shap.force_plot(explainer.expected_value, shap_values[0], X_test.iloc[0], matplotlib=True, figsize=(30, 5), contribution_threshold=0.1) plt.show() shap.force_plot(explainer.expected_value, shap_values[12], X_test.iloc[12], matplotlib=True, figsize=(30, 5), contribution_threshold=0.1) plt.show() shap.force_plot(explainer.expected_value, shap_values[4], X_test.iloc[4], matplotlib=True, figsize=(30, 5), contribution_threshold=0.1) plt.show()
This plot visually decomposes the prediction into the sum of effects from each feature. Features pushing the prediction higher are shown in red, and those pushing the prediction lower are shown in blue. The size of the colored bar indicates the magnitude of each feature's impact. This is an excellent tool for detailed case-by-case analysis in customer support, healthcare, and any field where understanding individual decisions is crucial.
Let's look at 3 example:
Extreme case: The Highest predicted value in the test set
The following sample is an extreme case where the model predicted a very large value. We want to understand why the model made such prediction.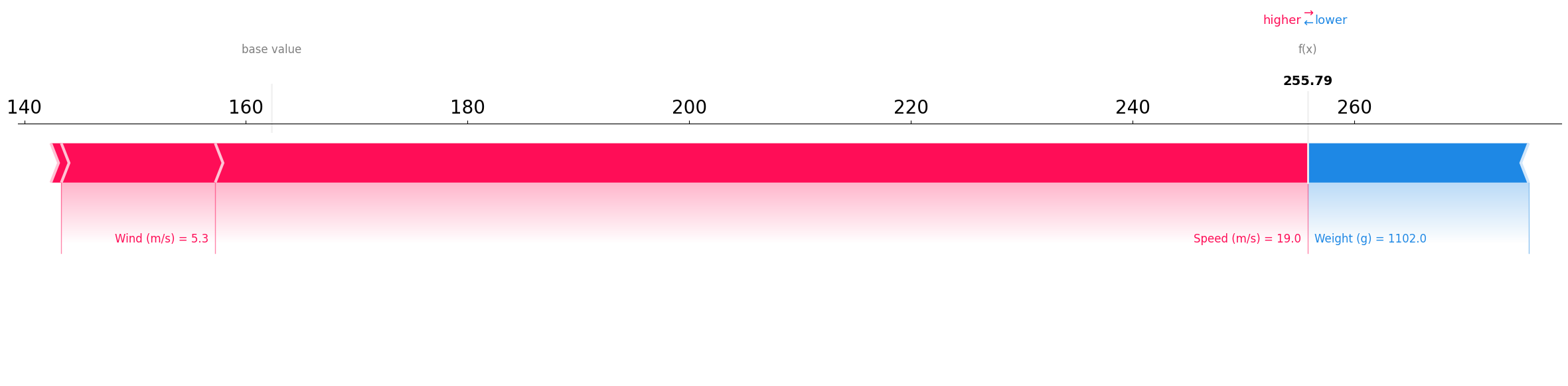
The plot suggests that the Weight of 1102 g (Which is the smallest weight in the dataset) is an indicator that the power consumption should be lower than the expected value since this is the smallest possible weight. But the speed of 19 m/s (Which is a high speed) pushes the prediction to be higher than the expected value, which is logical since higher speeds demand more energy consumption. For this instance, the effect of the high speed dominated the effect of low weight.
Extreme case: The Lowest predicted value in the test set
On the contrary, the following sample was predicted to have a very low power consumption.
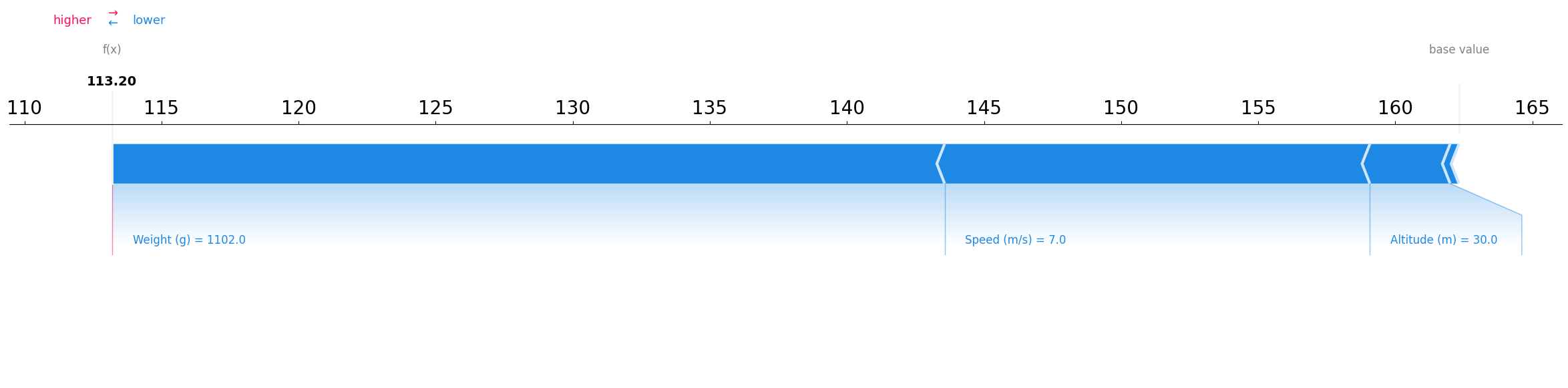
The plot shows another sample where the Weight increased compared to the first sample and the Speed is 7 m/s. Compared to the first example, we have a huge reduction in both Weight and Speed which are the most two effective factors. Huge reductions in these features caused the model to predict a very low power consumption which makes sense.
Average case
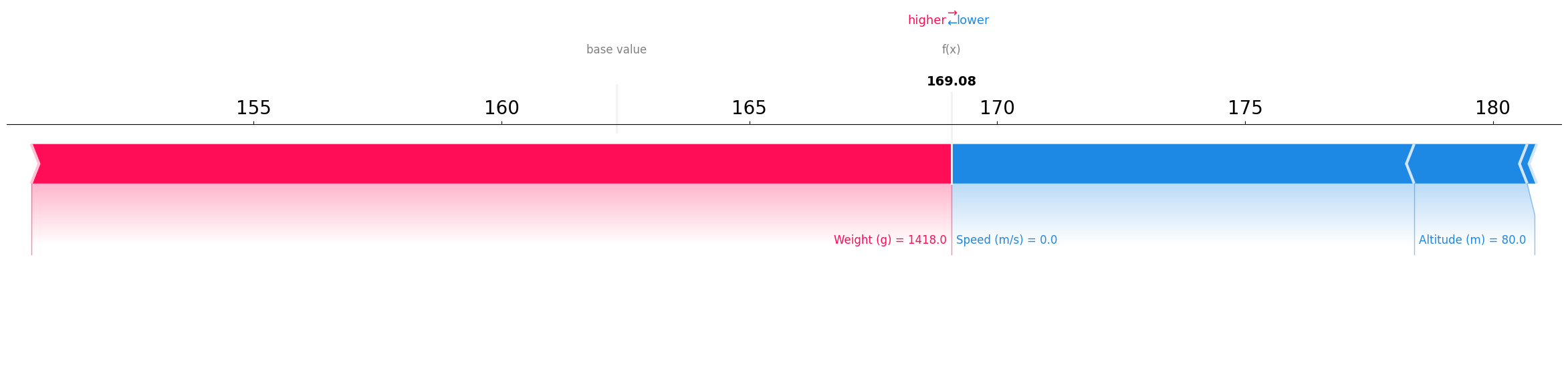
This example has a relatively high Weight but a Speed of zero. In this case, the two features almost negates each other making the prediction of the model (169.08) close to the expected value (162.32)
Conclusion
In this project, we tackled the task of predicting drone energy consumption using a Random Forest regression model. By utilizing a comprehensive dataset with features such as wind speed, altitude, weight, and speed, we developed a model that achieved an RMSE of 7.95 on the test set, reflecting its strong predictive capabilities.
However, accurate predictions alone weren’t sufficient for our needs. For practical applications—especially in energy management—it was crucial to understand why the model made specific predictions. To achieve this, we used SHAP values to explain the contributions of each feature, breaking down the complex interactions within the model and providing clear insights into the factors driving energy consumption.
The use of SHAP values not only enhanced transparency but also highlighted key influences, such as the positive impact of drone speed and the negative effect of weight, helping to guide decisions for optimizing drone operations.
By combining robust modeling with explainability, we demonstrated how machine learning can not only predict outcomes but also offer the insights needed for informed decision-making. This approach ensured that our model was both accurate and interpretable, making it more actionable and trustworthy for stakeholders.
References
- Lundberg, Scott M., and Lee, Su-In. "A Unified Approach to Interpreting Model Predictions." Advances in Neural Information Processing Systems 30 (NIPS 2017): 4765-4774. Link
shappython package: https://shap.readthedocs.io/en/latest/