
Variational Auto-Encoders (VAEs) are versatile deep learning models with applications in data compression, noise reduction, synthetic data generation, anomaly detection, and missing data imputation. This publication demonstrates these capabilities using the MNIST dataset, providing practical insights for AI/ML practitioners.
Variational Auto-Encoders (VAEs) are powerful generative models that exemplify unsupervised deep learning. They use a probabilistic approach to encode data into a distribution of latent variables, enabling both data compression and the generation of new, similar data instances.
VAEs have become crucial in modern machine learning due to their ability to learn complex data distributions and generate new samples without requiring explicit labels. This versatility makes them valuable for tasks like image generation, enhancement, anomaly detection, and noise reduction across various domains including healthcare, autonomous driving, and multimedia generation.
This publication demonstrates five key applications of VAEs: data compression, data generation, noise reduction, anomaly detection, and missing data imputation. By exploring these diverse use cases, we aim to showcase VAEs' versatility in solving various machine learning problems, offering practical insights for AI/ML practitioners.
To illustrate these capabilities, we use the MNIST dataset of handwritten digits. This well-known dataset, consisting of 28x28 pixel grayscale images, provides a manageable yet challenging benchmark for exploring VAEs' performance in different data processing tasks. Through our examples with MNIST, we demonstrate how VAEs can effectively handle a range of challenges, from basic image compression to more complex tasks like anomaly detection and data imputation.
Check the Models section for the github code repository for this publication.
Although the original MNIST images are in black and white, we have utilized color palettes in our visualizations to make the demonstrations more visually engaging.
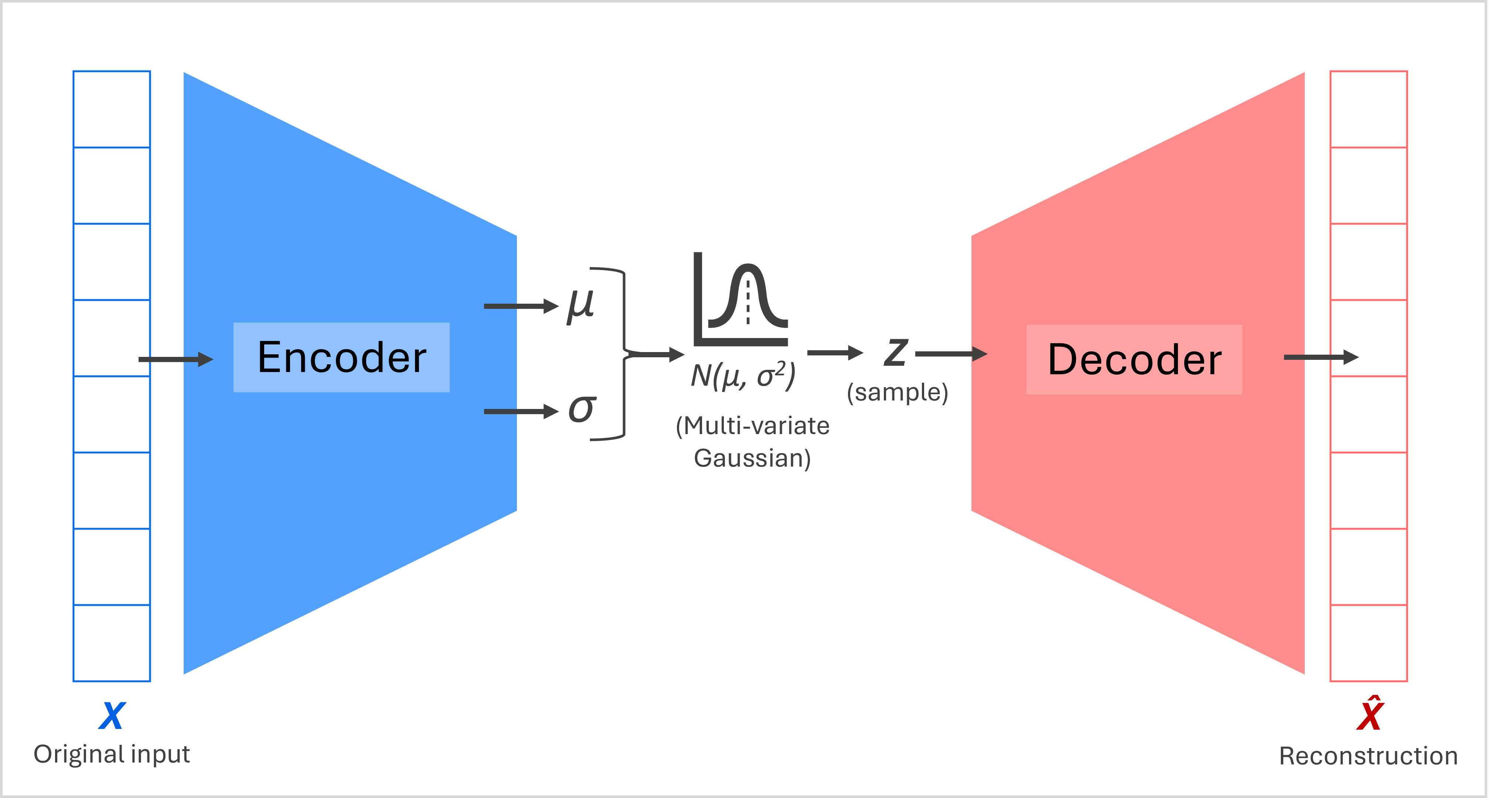
The diagram above illustrates the key components of a VAE:
The encoder takes an input, such as an image, call it
While VAEs share some similarities with traditional auto-encoders, they have distinct features that set them apart. Understanding these differences is crucial for grasping the unique capabilities of VAEs. The following table highlights key aspects where VAEs differ from their traditional counterparts:
| Aspect | Traditional Auto-Encoders | Variational Auto-Encoders (VAEs) |
|---|---|---|
| Latent Space | • Deterministic encoding | • Probabilistic encoding |
| • Fixed point for each input | • Distribution (mean, variance) | |
| Objective Function | • Reconstruction loss | • Reconstruction loss + KL divergence |
| • Preserves input information | • Balances reconstruction and prior distribution | |
| Generative Capability | • Limited | • Inherently generative |
| • Primarily for dimensionality reduction | • Can generate new, unseen data | |
| Applications | • Feature extraction | • All traditional AE applications, plus: |
| • Data compression | • Synthetic generation | |
| • Noise reduction | ||
| • Missing Data Imputation | ||
| • Anomaly Detection | ||
| Sampling | • Not applicable | • Can sample different points for same input |
| Primary Function | • Data representation | • Data generation and representation |
To better understand the practical implementation of a Variational Autoencoder, let's examine a concrete example using PyTorch, a popular deep learning framework. This implementation is designed to work with the MNIST dataset, encoding 28x28 pixel images into a latent space and then reconstructing them.
The full code is available here: Jupyter Notebook
The following code defines a VAE class that includes both the encoder and decoder networks. It also implements the reparameterization trick, which is crucial for allowing backpropagation through the sampling process. Additionally, we'll look at the loss function, which combines reconstruction loss with the Kullback-Leibler divergence to ensure the latent space has good properties for generation.
class VAE(nn.Module): def __init__(self, latent_dim): super(VAE, self).__init__() # Encoder self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1) # Input is 1x28x28, output is 32x14x14 self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1) # Output is 64x7x7 self.fc1 = nn.Linear(64 * 7 * 7, 400) self.fc21 = nn.Linear(400, latent_dim) # mu self.fc22 = nn.Linear(400, latent_dim) # logvar # Decoder self.fc3 = nn.Linear(latent_dim, 400) self.fc4 = nn.Linear(400, 64 * 7 * 7) self.conv2_t = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1) # Output is 32x14x14 self.conv1_t = nn.ConvTranspose2d(32, 1, kernel_size=3, stride=2, padding=1, output_padding=1) # Output is 1x28x28 def encode(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = x.view(-1, 64 * 7 * 7) x = F.relu(self.fc1(x)) return self.fc21(x), self.fc22(x) def reparameterize(self, mu, logvar): std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return mu + eps * std def decode(self, z): z = F.relu(self.fc3(z)) z = F.relu(self.fc4(z)) z = z.view(-1, 64, 7, 7) z = F.relu(self.conv2_t(z)) z = torch.sigmoid(self.conv1_t(z)) return z def forward(self, x): mu, logvar = self.encode(x) z = self.reparameterize(mu, logvar) return self.decode(z), mu, logvar # Loss function def loss_function(recon_x, x, mu, logvar): # Calculate the Binary Cross Entropy loss between the reconstructed image and the original image BCE = F.binary_cross_entropy(recon_x, x, reduction='sum') # KL divergence measures how one probability distribution diverges from a second, expected probability distribution. # For VAEs, it measures how much information is lost when using the approximations of the distributions. KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) return BCE + KLD
Let's dissect each part of the code to understand how a VAE is built and operates using PyTorch, a popular deep learning library.
First, we have the constructor:
def __init__(self, latent_dim): super(VAE, self).__init__() # Encoder self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1) # Input is 1x28x28, output is 32x14x14 self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1) # Output is 64x7x7 self.fc1 = nn.Linear(64 * 7 * 7, 400) self.fc21 = nn.Linear(400, latent_dim) # mu self.fc22 = nn.Linear(400, latent_dim) # logvar # Decoder self.fc3 = nn.Linear(latent_dim, 400) self.fc4 = nn.Linear(400, 64 * 7 * 7) self.conv2_t = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1) # Output is 32x14x14 self.conv1_t = nn.ConvTranspose2d(32, 1, kernel_size=3, stride=2, padding=1, output_padding=1)
The __init__ method initializes the VAE. It takes latent_dim as an argument, specifying the size of the latent space, a key feature of the VAE that determines the dimensionality of the encoded representation. It contains the definition of the encoder and decoder parts.
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1) self.fc1 = nn.Linear(64 * 7 * 7, 400) self.fc21 = nn.Linear(400, latent_dim) # Mean (mu) self.fc22 = nn.Linear(400, latent_dim) # Log variance (logvar)
The Encoder consists of convolutional layers followed by fully connected layers. The convolutional layers help in capturing spatial hierarchies in the image data, reducing its dimensionality before it is mapped to the latent space parameters by the fully connected layers.
self.fc3 = nn.Linear(latent_dim, 400) self.fc4 = nn.Linear(400, 64 * 7 * 7) self.conv2_t = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1) self.conv1_t = nn.ConvTranspose2d(32, 1, kernel_size=3, stride=2, padding=1, output_padding=1)
The Decoder utilizes transposed convolutional layers to perform the inverse operation of the encoder, upscaling the encoded latent representations back to the original image dimensions.
def loss_function(recon_x, x, mu, logvar): BCE = F.binary_cross_entropy(recon_x, x, reduction='sum') KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) return BCE + KLD
The loss function combines binary cross-entropy (BCE) for reconstruction loss and the KL divergence (KLD) for regularizing the latent space distribution.
def encode(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = x.view(-1, 64 * 7 * 7) x = F.relu(self.fc1(x)) return self.fc21(x), self.fc22(x) def reparameterize(self, mu, logvar): std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return mu + eps * std def decode(self, z): z = F.relu(self.fc3(z)) z = F.relu(self.fc4(z)) z = z.view(-1, 64, 7, 7) z = F.relu(self.conv2_t(z)) z = torch.sigmoid(self.conv1_t(z)) return z def forward(self, x): mu, logvar = self.encode(x) z = self.reparameterize(mu, logvar) return self.decode(z), mu, logvar
def reparameterize(self, mu, logvar): std = torch.exp(0.5 * logvar) # Convert log-variance to standard deviation eps = torch.randn_like(std) # Generate random noise with a standard normal distribution return mu + eps * std # Scale and shift the noise to create the sample
std = torch.exp(0.5 * logvar)logvar) is transformed into the standard deviation (std). This transformation is necessary because the variance must be non-negative and the logarithm of variance can range from negative infinity to positive infinity, making it easier to optimize. The 0.5 factor is due to the properties of logarithms (since variance = exp(logvar) and std = sqrt(variance)).eps = torch.randn_like(std)eps is generated from a standard normal distribution (mean = 0, std = 1) with the same shape as the standard deviation. This randomness introduces the stochastic element needed for the generative process.return mu + eps * stdmu). This step effectively samples from the Gaussian distribution defined by mu and std, but in a way that allows the gradients to flow back through the parameters mu and logvar during training.Now that we've explored the theoretical underpinnings of VAEs and examined a concrete implementation in PyTorch, let's dive into the practical applications of this powerful model. We'll start by focusing on one of the most fundamental capabilities of VAEs: data compression.
In the following sections, we'll demonstrate how VAEs can be utilized for efficient data compression, using the MNIST dataset as our example. This application showcases the VAE's ability to capture the essence of complex data in a compact latent representation, a feature that has significant implications for data storage, transmission, and processing.
While our examples use MNIST for simplicity, the principles of VAE applications extend to various real-world datasets. These techniques can be adapted for diverse scenarios, from image processing to tabular data to time series analysis, offering powerful solutions for data compression, generation, denoising, anomaly detection, and imputation across different domains.
Modern data-driven applications often require efficient methods for data compression and dimensionality reduction to manage storage, processing, and transmission costs. Variational Autoencoders (VAEs) offer a powerful solution to this challenge, particularly for complex, high-dimensional data like images.
To demonstrate the effectiveness of VAEs in compressing MNIST images, we can visualize the original and the reconstructed images side by side:
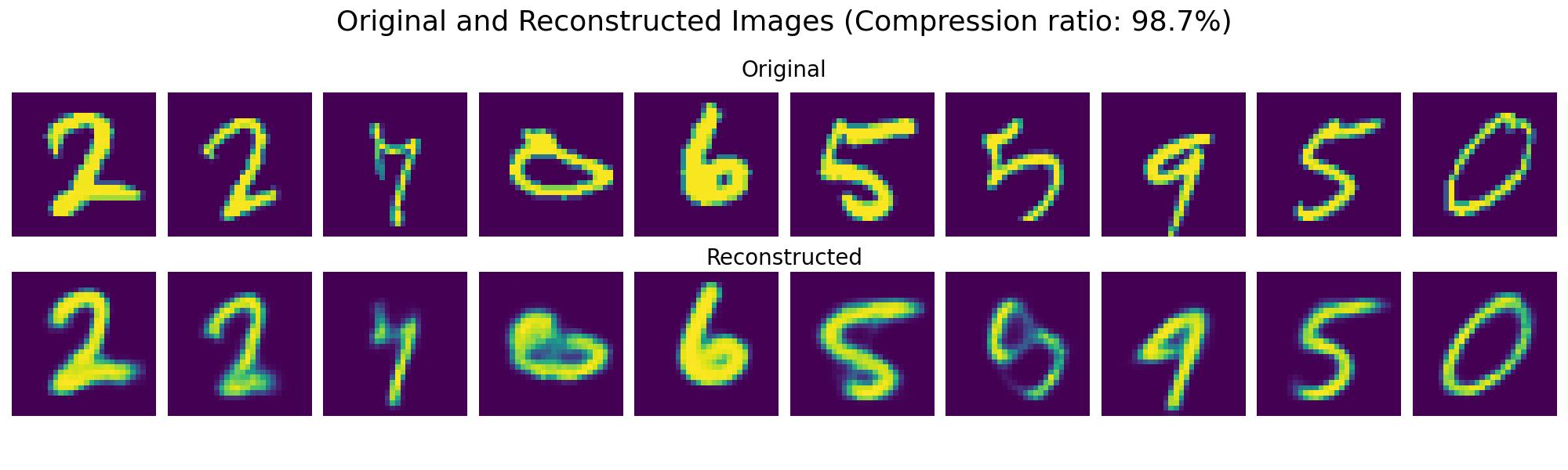
The results show how VAEs can effectively compress the 28x28 pixel images of handwritten digits into a lower-dimensional latent space of size 10 that is 1.2% of the original size. Despite this significant reduction in dimensionality, the reconstructed images closely resemble the originals, demonstrating the VAE's powerful ability to capture essential features while compressing the data.
We trained a VAE on MNIST with a 2D latent space for easy visualization and manipulation. This allows us to observe how changes in latent variables affect generated images. The figure below shows generated images for latent dimension values from -3 to 3 on both axes:

This exploration is not only a powerful demonstration of the model's internal representations but also serves as a tool for understanding and debugging the model’s behavior.
Noise in data is a common issue in various fields, from medical imaging to autonomous vehicles. It can significantly degrade the performance of machine learning models, making effective denoising techniques crucial.
The following images show the denoising performance of VAEs at different levels of noise contamination:
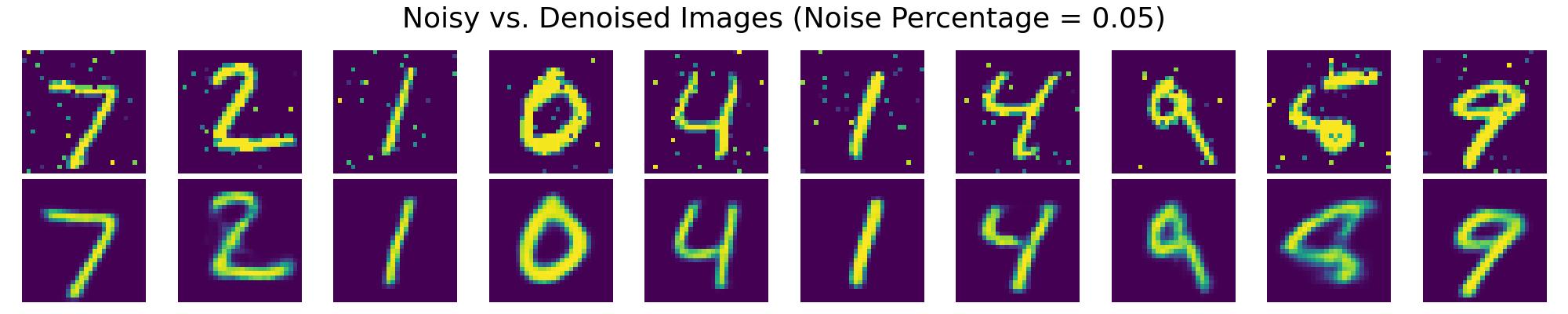
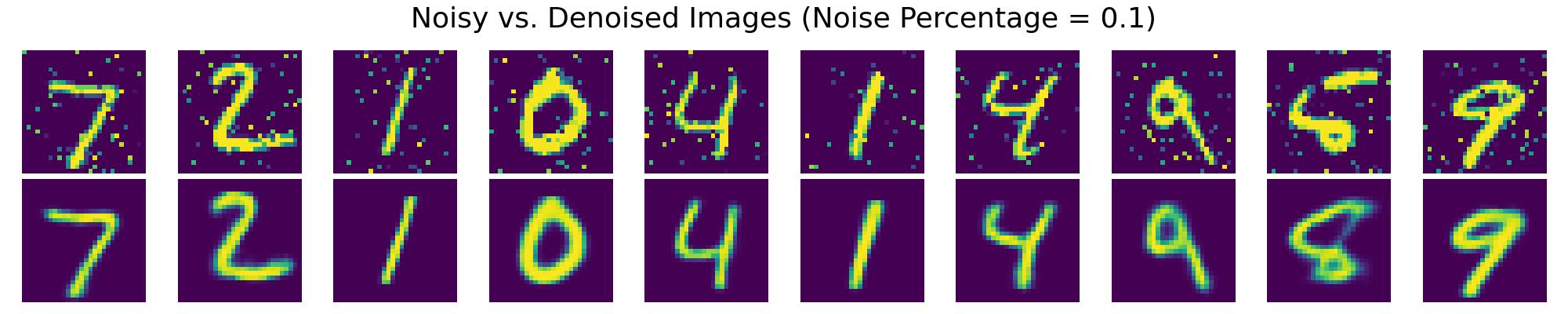
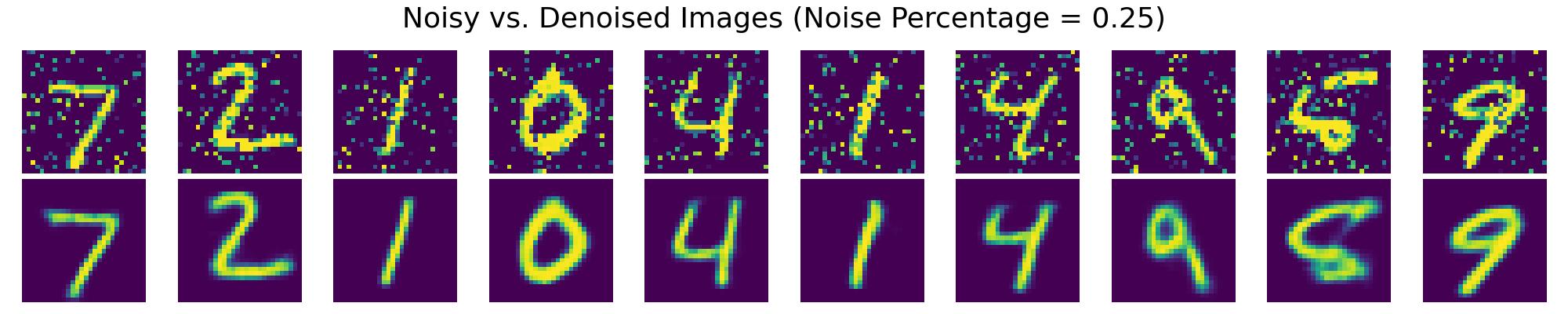
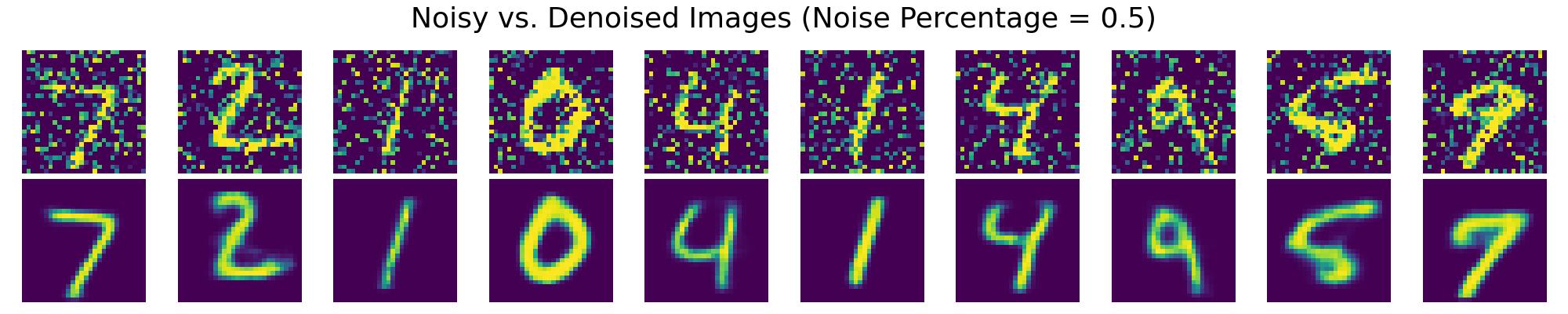
Results seen in the charts above demonstrate the VAE's capability in reconstructing clean images from noisy inputs, highlighting its potential in restoring and enhancing image data usability in practical scenarios.
Anomaly detection is crucial in various industries, identifying patterns that deviate from expected behavior. These anomalies can indicate critical issues such as fraudulent transactions or mechanical faults.
The histogram below shows reconstruction errors on the test set:
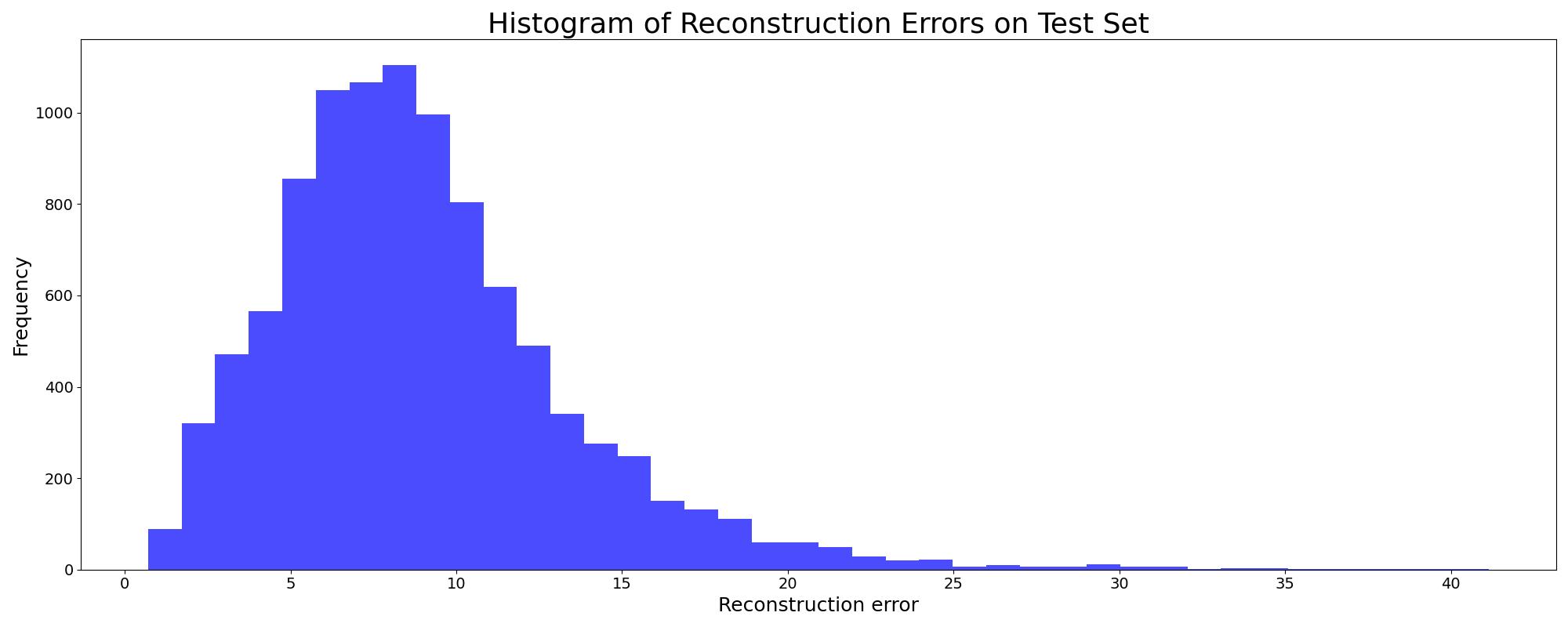
The following images show the top 10 digits with the highest loss, representing potential anomalies:

We can confirm that the 10 samples are badly written digits and should be considered anomalies.
To further test the VAE's anomaly detection capabilities, we tested the VAE model on images of letters—data that the model was not trained on. This experiment serves two purposes:
The following chart shows the original images of letters and their reconstructions.

We also marked the reconstruction errors of the samples on the histogram of reconstruction errors from the test set.
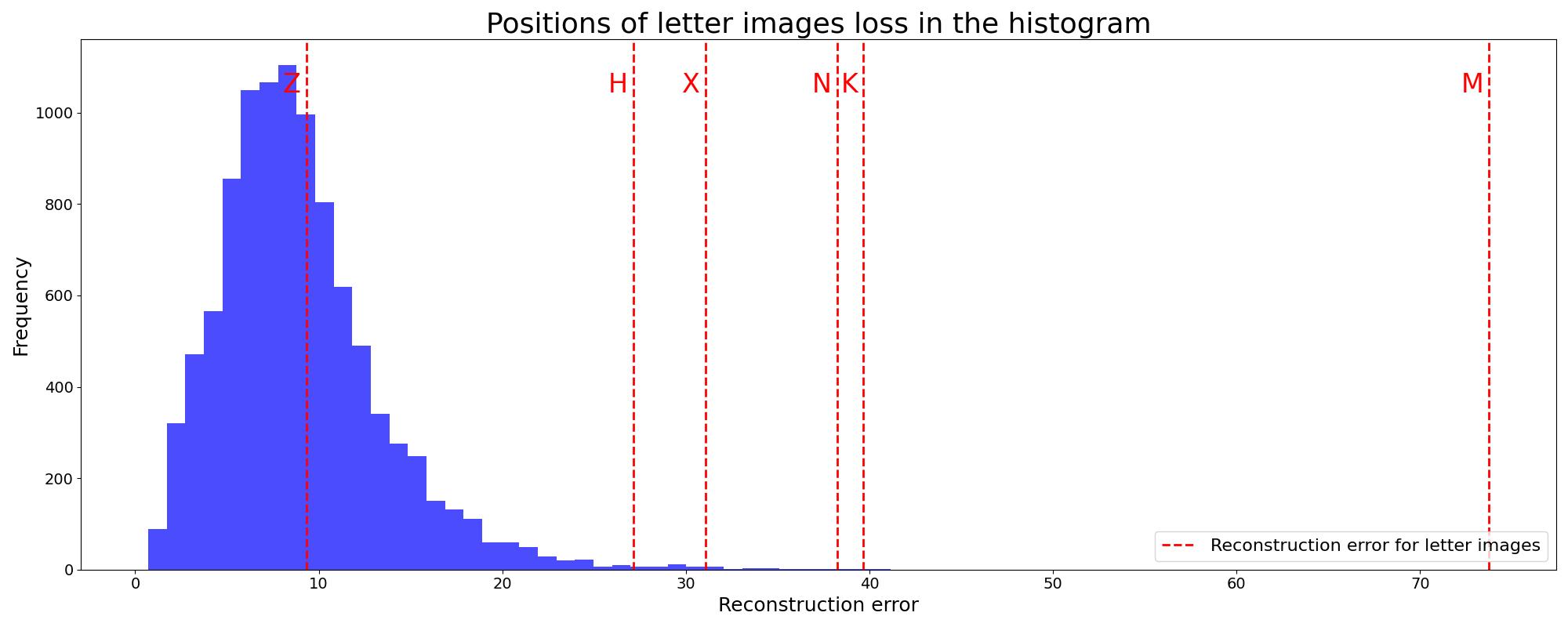
These visualizations reveal several interesting insights:
Most letters, except 'Z', show poor reconstructions and high reconstruction errors, clearly marking them as anomalies.
The letter 'Z' is reconstructed relatively well, likely due to its similarity to the digit '2'. Its reconstruction error falls within the normal range of the test set.
The letter 'M' shows the most distorted reconstruction, corresponding to the highest reconstruction error. This aligns with 'M' being the most dissimilar to any MNIST digit.
Interestingly, 'H' is reconstructed to somewhat resemble the digit '8', the closest MNIST digit in shape. While still an anomaly, it has the lowest error among the non-'Z' letters.
This experiment highlights:
These observations underscore the VAE's capability in anomaly detection while also revealing its limitations when faced with out-of-distribution data that shares similarities with in-distribution samples.
Incomplete data is a common challenge in machine learning, leading to biased estimates and less reliable models. This issue is prevalent in various domains, including healthcare and finance.
VAEs offer a robust approach to missing data imputation:
Training: A VAE learns the distribution of complete MNIST digits.
Simulating Missing Data: During training, parts of input digits are randomly masked. The VAE is tasked with reconstructing the full, original digit from this partial input.
Inference: When presented with new partial digits, the VAE leverages its learned distributions to infer and reconstruct missing sections, effectively filling in the gaps.
This process enables the VAE to generalize from partial information, making it adept at handling various missing data scenarios.
The image below demonstrates the VAE's capability in missing data imputation:

These examples illustrate how effectively the VAE infers and reconstructs missing parts of the digits, showcasing its potential for data imputation tasks.
While this publication has focused on Variational Autoencoders (VAEs), it's important to consider how they compare to other popular generative models, particularly Generative Adversarial Networks (GANs). Both VAEs and GANs are powerful techniques for data generation in machine learning, but they approach the task in fundamentally different ways and have distinct strengths and weaknesses.
GANs, introduced by Ian Goodfellow et al. in 2014, have gained significant attention for their ability to generate highly realistic images. They work by setting up a competition between two neural networks: a generator that creates fake data, and a discriminator that tries to distinguish fake data from real data. This adversarial process often results in very high-quality outputs, particularly in image generation tasks.
Understanding the differences between VAEs and GANs can help practitioners choose the most appropriate model for their specific use case. The following table provides a detailed comparison of these two approaches:
The following table provides a detailed comparison of these two approaches:
| Aspect | Variational Autoencoders (VAEs) | Generative Adversarial Networks (GANs) |
|---|---|---|
| Output Quality | Slightly blurrier, but consistent | Sharper, more realistic images |
| Training Process | Easier and usually faster to train, well-defined objective function | Can be challenging and time-consuming, potential mode collapse |
| Latent Space | Structured and interpretable | Less structured, harder to control |
| Versatility | Excel in both generation and inference tasks | Primarily focused on generation tasks |
| Stability | More stable training, consistent results | Can suffer from training instability |
| Primary Use Cases | Data compression, denoising, anomaly detection, controlled generation | High-fidelity image generation, data augmentation |
| Reconstruction Ability | Built-in reconstruction capabilities | No inherent reconstruction ability |
| Inference | Capable of inference on new data | Typically requires additional techniques for inference |
This article has demonstrated the versatility of Variational Auto-Encoders (VAEs) across various machine learning applications, including data compression, generation, noise reduction, anomaly detection, and missing data imputation. VAEs' unique ability to model complex distributions and generate new data instances makes them powerful tools for tasks where traditional methods may fall short.
We encourage researchers, developers, and enthusiasts to explore VAEs further. Whether refining architectures, applying them to new data types, or integrating them with other techniques, the potential for innovation is vast. We hope this exploration inspires you to incorporate VAEs into your work, contributing to technological advancement and opening new avenues for discovery.
Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv preprint arXiv
.6114. https://arxiv.org/abs/1312.6114Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. In Advances in Neural Information Processing Systems (pp. 2672-2680). https://papers.nips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf

