Nexus is an advanced AI-powered research system designed to automate and enhance the process of gathering, analyzing, and generating structured research content. Traditional research involves time-consuming manual searches, information filtering, and content structuring, which can introduce inefficiencies and inconsistencies. Nexus overcomes these challenges by utilizing a multi-agent AI architecture, integrating natural language processing (NLP), web scraping, and AI-driven content synthesis to streamline research workflows.
Nexus employs three specialized AI agents:
.md), JSON (.json), and PDF formats for accessibility and further usage.Key features of Nexus include customizable tone settings, a fact-checking mechanism using Google’s Fact Check API, and seamless user interaction via a frontend interface built with React and Tailwind CSS. With automation, AI integration, and structured workflows, Nexus significantly reduces research time, enhances accuracy, and ensures high-quality content generation.
Link to Project:
Nexus
Research is essential in academic, business, and technological domains, yet traditional research methods often require significant manual effort and verification. With the vast amount of online information, researchers face challenges such as misinformation, scattered data sources, and the need for structured content.
.md, .json, .pdf).Nexus eliminates information overload and research inefficiencies by using AI-powered automation.
Nexus follows a modular AI-driven agentic architecture, where three specialized AI agents work collaboratively.
.md and .json formats.main.py)The backend initializes the workflow pipeline, ensuring that the three AI agents execute sequentially.
from langgraph.graph.state import StateGraph from config import generate_response from state import ResearchState from workflow_nodes import get_research, generate_news_article, save_output def create_workflow(): workflow = StateGraph(state_schema=ResearchState) workflow.add_node("research_agent", get_research) workflow.add_node("reporting_agent", generate_news_article) workflow.add_node("storage_agent", save_output) workflow.add_edge("research_agent", "reporting_agent") workflow.add_edge("reporting_agent", "storage_agent") workflow.set_entry_point("research_agent") workflow.set_finish_point("storage_agent") return workflow.compile()
This function defines the workflow:
Research Agent → Extracts research data.
Reporting Agent → Generates a structured article.
Storage Agent → Saves the article and allows PDF export.
The Research Agent collects data from multiple sources and fact-checks the results.
def get_research(state: dict) -> dict: research_tool = ResearchTool() topic = state["topic"] google_results = research_tool.search_google(topic) wiki_results = research_tool.search_wikipedia(topic) arxiv_results = research_tool.search_arxiv(topic) fact_check = research_tool.fact_check(topic) research_summary = f"Google: {google_results}\n\nWikipedia: {wiki_results}\n\nArxiv: {arxiv_results}" return {"research_summary": research_summary, "fact_check_results": fact_check}
The Reporting Agent converts research data into a structured article.
def generate_news_article(state: dict) -> dict: research_state = state if not research_state["research_summary"].strip(): research_state["article"] = "No research data available." return research_state article_prompt = f""" Based on the following research, write a compelling and detailed news article: {research_state["research_summary"]} **Ensure the article follows this format:** - **Title** - **Introduction** - **Key Insights** - **Industry Impact** - **Future Prospects** - **Conclusion** """ response = generate_response(article_prompt) research_state["article"] = response.strip() return research_state
The Storage Agent saves research results in .md and .json formats.
def save_output(state: ResearchState) -> dict: topic = state["topic"].replace(" ", "_") article = state["article"] research_summary = state["research_summary"] if not article.strip(): state["message"] = "⚠️ No article content to save." return state article_path = os.path.join(BASE_DIR, f"{topic}.md") json_path = os.path.join(BASE_DIR, f"{topic}.json") os.makedirs(BASE_DIR, exist_ok=True) with open(article_path, "w", encoding="utf-8") as f: f.write(f"# {topic}\n\n{article}") return state
Nexus successfully streamlines the research process through automation, AI-driven content generation, and structured workflows. Below are the key outcomes observed:
.md), JSON (.json), and PDF.Nexus features a modern, responsive UI that allows users to input a topic, process research, and view/download results. Below are images illustrating different sections of the UI.
Description: The homepage where users can enter a research topic.
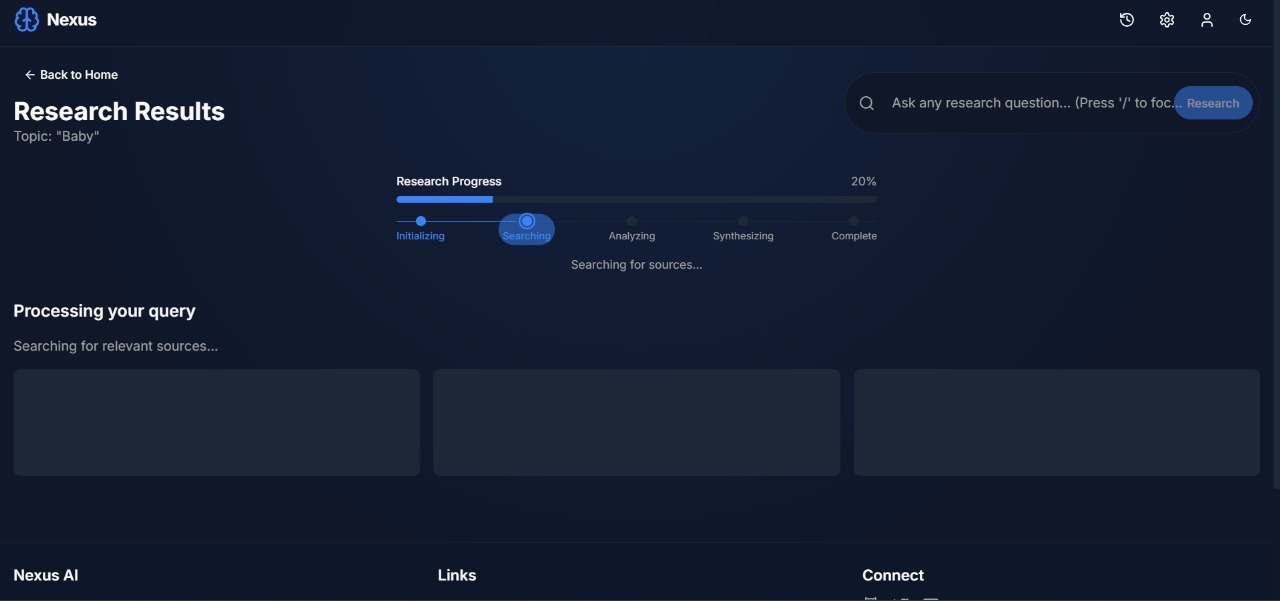
Description: The system processing the research request in real-time.
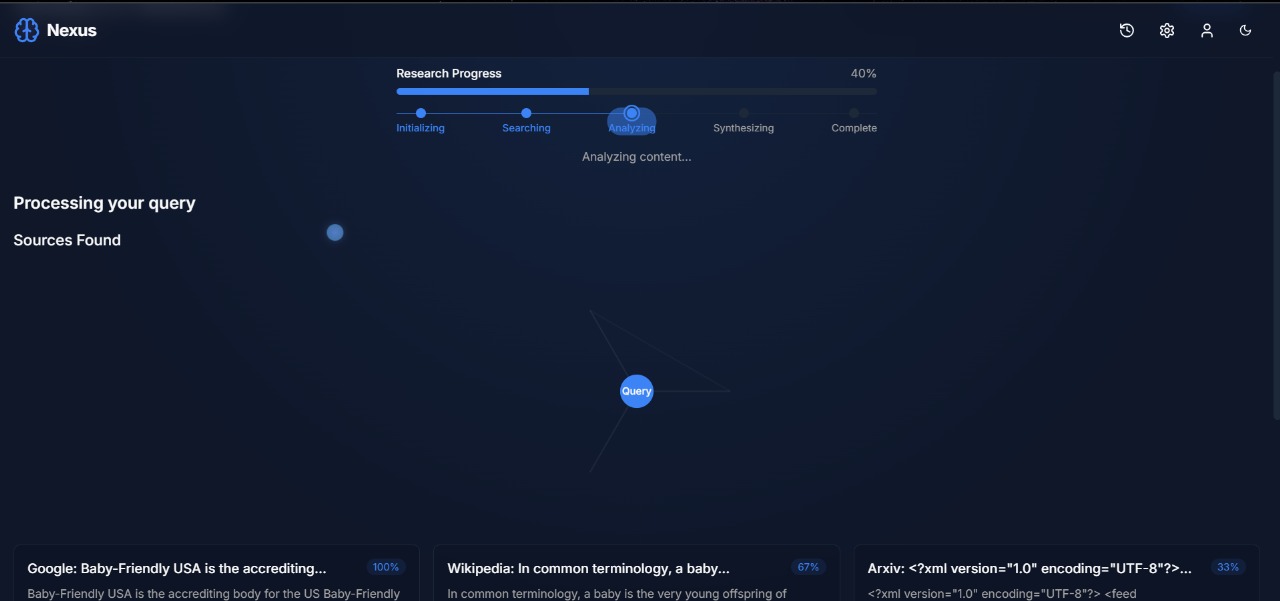
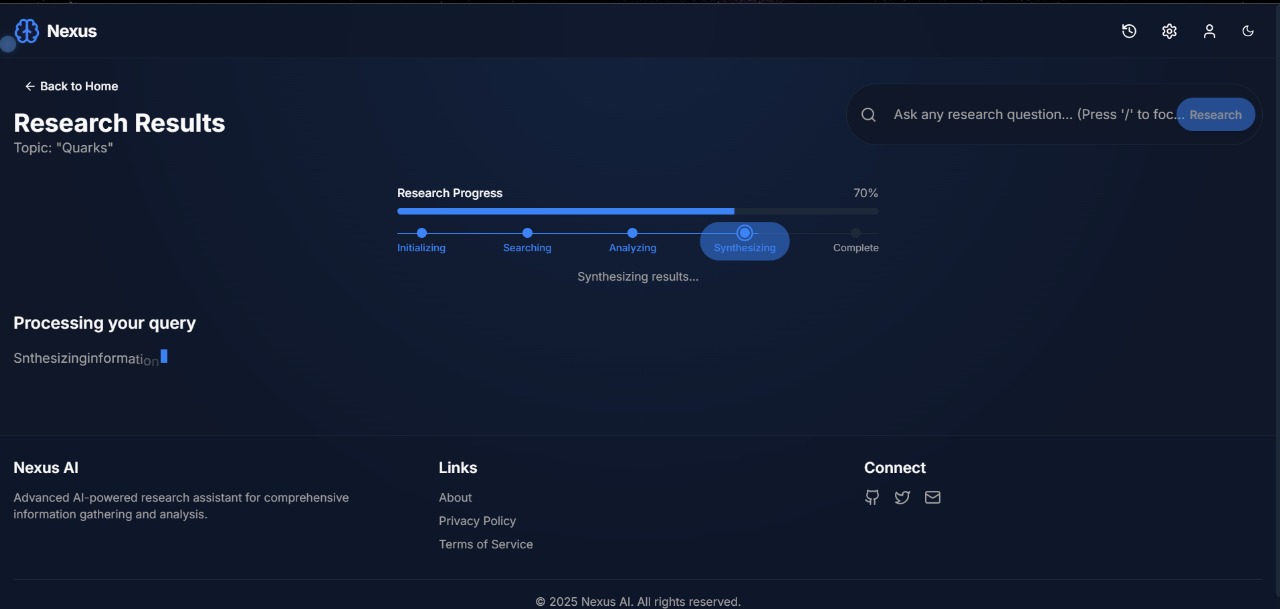
Description: A detailed article is displayed with structured content.
Description: Users can adjust the tone of the research article.
Nexus provides an AI-powered solution for efficient, accurate, and structured research. By automating information retrieval, content synthesis, and storage, Nexus eliminates the manual workload traditionally associated with research.
Nexus is built using modern web technologies to ensure efficiency, scalability, and a seamless user experience.