Abstract
This project explores Medical Visual Question Answering (VQA) by developing deep learning models trained on the PathVQA dataset. The dataset comprises pathology images and corresponding question-answer pairs, enabling the development of two models: one for binary yes/no questions and another for free-form answers. Leveraging a combination of VGG-19 for image feature extraction and BERT for text processing, the models utilize attention mechanisms to integrate image and textual information.
The yes/no model achieved a test accuracy of 92%, outperforming the reference model's 84%, while the free-form model improved upon benchmarks with a test accuracy of 55%. Data preprocessing included augmentation techniques, and training utilized the AdamW optimizer with early stopping based on validation performance. Limitations include handling complex medical queries and diverse answers, suggesting opportunities for advanced architectures and dataset expansion in future work. This research highlights the potential of VQA systems to aid medical diagnostics and treatment planning.
Introduction
Github
In the realm of medical image analysis, the ability to comprehend and interpret pathological images is crucial for diagnosis and treatment planning. To enhance this capability, we propose a deep learning project focused on Medical Visual Question Answering (VQA) using the PathVQA dataset. PathVQA is a curated dataset containing question-answer pairs associated with pathology images sourced from authoritative textbooks and digital libraries. This report presents the development and evaluation of Visual Question Answering (VQA) models using the PathVQA dataset. Two models were developed: one for binary yes/no questions and another for free-form questions. The performance of these models was compared with a reference model from the article "PathVQA: Pathology Visual Question Answering" by Jerri Zhang.
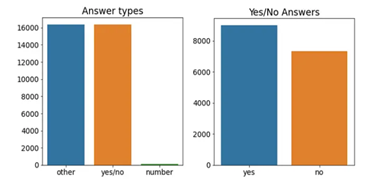
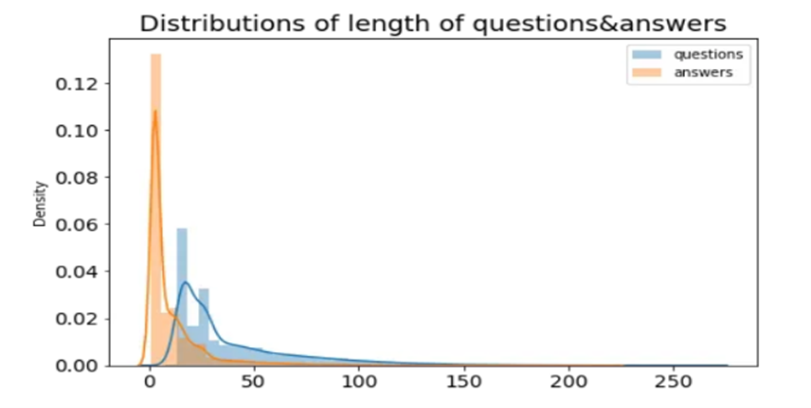
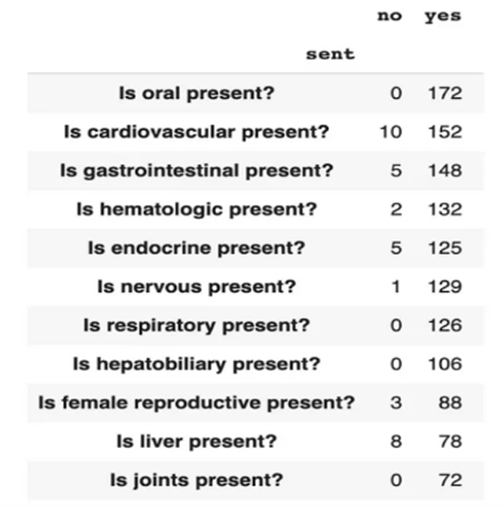
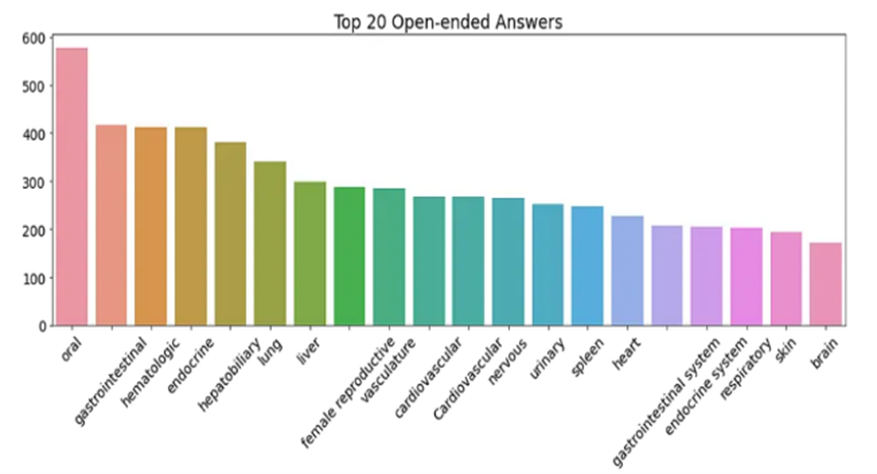
PathVQA Dataset Statistics
The PathVQA dataset consists of pathology images paired with questions and answers. The dataset is split into training, validation, and test sets. Below are some statistics about the dataset:
-
Number of Images:
The dataset contains 4,998 images, which are a diverse set of images representing different pathological conditions. -
Number of Questions:
Each image is associated with multiple questions, leading to a large and diverse set of question-answer pairs.- Training Set: 19,703 QAs, 2,835 images
- Validation Set: 6,318 QAs, 1,068 images
- Test Set: 6,778 QAs, 1,095 images
Methodology
The proposed methodology for the Medical Visual Question Answering (VQA) project involves several key phases: data preprocessing, model development, training, and evaluation.
Data Preprocessing
The preprocessing stage involves:
- Resizing all pathology images to
224x224pixels. - Applying data augmentation techniques such as:
- Random affine transformations.
- Horizontal flips.
- Color jitter.
- Normalizing images based on ImageNet dataset statistics.
- Tokenizing questions and converting them into input IDs and attention masks using the BERT tokenizer, with padding and truncation to ensure uniform input length.
Model Development
Two VQA models were developed:
- Binary Yes/No Question Model
- Free-Form Question Model
Both models integrate:
- Image feature extraction using a VGG-19 pre-trained network.
- Question feature extraction using the BERT model.
- Dimensionality reduction via fully connected (FC) layers.
- Attention mechanisms to focus on relevant image regions in the context of the questions.
- Final classification layers to differentiate between yes/no answers or a broader set of possible answers for the free-form model.
Model Training
The training process involves:
- Using the AdamW optimizer with a learning rate of
5e-5. - Applying dropout regularization to prevent overfitting.
- Employing cross-entropy loss as the loss function.
- Using a learning rate scheduler and early stopping based on validation loss to ensure optimal performance.
- Training the models on the PathVQA training set and evaluating them on validation and test sets.
Evaluation and Result Analysis
The performance of both models is evaluated using accuracy metrics on training, validation, and test sets. The analysis includes:
- Generating visualizations of model performance.
- Comparing results with the reference model from the PathVQA paper.
- Anticipating the binary yes/no model's performance to exceed the reference model's accuracy.
- Demonstrating significant improvements in handling diverse answers with the free-form model.
Results and performances are thoroughly analyzed and documented, highlighting the advancements made by the developed models.
Experiments
Before finalizing the proposed methodology for Medical Visual Question Answering (VQA), we explored several approaches to determine the most effective pipeline for our task. These preliminary trials included:
Baseline Model Evaluation
- Initial trials with simpler architectures, such as standalone VGG-19 for image classification and a basic RNN-based model for text processing, were tested.
- Results indicated insufficient performance due to the lack of integrated multimodal analysis.
Alternate Feature Extractors
- Tried ResNet-50 and Inception networks for image feature extraction but faced challenges in capturing finer pathology-specific details compared to VGG-19.
- Tokenizers other than BERT, such as GPT-2 and GloVe embeddings, were considered but did not align well with the dataset requirements.
Hyperparameter Variations
- Experimented with different learning rates, optimizers (e.g., SGD, RMSprop), and batch sizes.
- AdamW emerged as the most stable optimizer for balancing convergence speed and generalization.
Attention Mechanisms
- Basic attention layers were integrated early but failed to capture the nuanced relationships between questions and pathology images.
- Enhanced multi-headed attention mechanisms were implemented in subsequent iterations.
Dataset Augmentation Techniques
- Initial trials with limited augmentation (e.g., random cropping and flipping) yielded moderate robustness.
- Advanced transformations, including color jitter and affine adjustments, significantly improved the training performance.
Preliminary Models for Yes/No and Free-Form Questions
- Early versions of the yes/no model achieved reasonable accuracy, guiding further optimization efforts.
- Free-form question models posed greater challenges, requiring iterative improvements to output handling and loss functions.
These explorations provided valuable insights, allowing us to refine our models and workflows to achieve optimal performance, as detailed in the proposed methodology.
Results
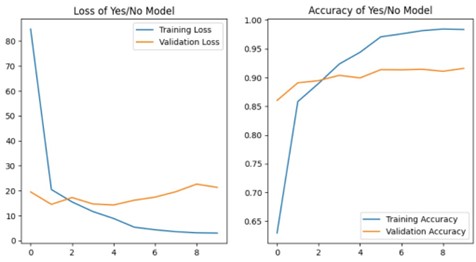
Yes/No Model Performance
- Training Accuracy: 98%
- Validation Accuracy: 92%
- Test Accuracy: 92%
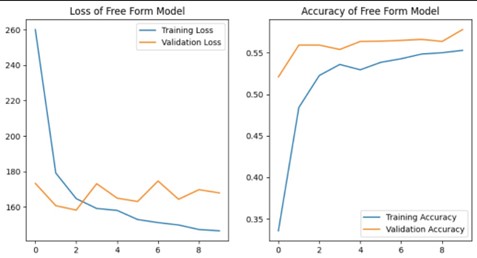
Free Form Model Performance
- Training Accuracy: 55%
- Validation Accuracy: 57%
- Test Accuracy: 55%
Comparison with Reference Model
- Yes/No Model: The performance of our yes/no model is better than the referenced article model. We reached a test accuracy of 92% while they reached 84%.
- Free Form Model: Our model performs even better in answering free-form questions. We reached a maximum test accuracy of 55% while they reached only 39%.
Limitations and Future Directions
Despite high accuracy, the models face limitations in generalizing to complex medical questions and handling diverse answers. The reliance on VGG-19 and BERT may not fully capture pathology-specific features. Future work should explore advanced architectures like Vision Transformers and domain-specific language models, along with expanding the dataset and employing sophisticated data augmentation and transfer learning techniques to enhance robustness and performance.
Conclusion
In conclusion, the developed VQA models demonstrate significant advancements in interpreting pathology images, particularly with the yes/no model achieving state-of-the-art accuracy on the PathVQA dataset. While the free-form model shows improvement over existing benchmarks, further refinement is needed to enhance its performance. By integrating advanced neural architectures and expanding the dataset, future work can build on these results to create more robust and generalizable models, ultimately aiding in more accurate and efficient medical diagnostics and treatment planning.