
Abstract
This publication introduces an AI-driven recommendation system that suggests optimal League of Legends (LoL) champions based on a player's unique playstyle, determined from live gameplay recordings. Unlike traditional static recommendations, this system leverages computer vision and deep learning to analyze real-time in-game decisions and provide champion suggestions tailored to the user's strategic tendencies.
Credits
For providing the gameplay - https://www.youtube.com/watch?v=Bmt-7ZrsbOA&t=785s
Introduction
Champion selection in League of Legends is crucial for a player's success. While existing methods rely on tier lists, win rates, and general meta, they fail to personalize recommendations based on an individual’s actual gameplay behavior.
To address this, we propose an AI-based system that processes live gameplay recordings and extracts player tendencies to suggest champions that complement their strengths.
League Of Legends Metrics Tracker
Specific Objectives:
The primary goal of this publication is to demonstrate the practical application of a champion recommendation system tailored to players' playstyles in League of Legends (LOL). The following objectives outline the intended outcomes and measurable goals:
Objective 1: Demonstrate Accuracy in Champion Recommendation
- Goal: Show how the recommendation system accurately suggests champions based on a player’s playstyle.
Measurable Outcome: Achieve an accuracy rate of 85% or higher in recommending champions, as determined by player feedback and match performance metrics over a sample of 500 matches.
Objective 2: Evaluate User Satisfaction and Adoption
- Goal: Assess user experience and overall satisfaction with the champion recommendations provided by the system.
- Measurable Outcome: Achieve an 80% user satisfaction rate, measured through surveys and feedback forms completed by players using the recommender system for at least 10 matches.
Objective 3: Quantify Improvement in Player Performance
- Goal: Measure the impact of the recommended champions on player performance in ranked matches.
Measurable Outcome: Increase win rates by 10% for users who follow champion recommendations, based on match data tracked over a period of 1 month.
Objective 4: Showcase Scalability and Flexibility Across Different Playstyles
- Goal: Demonstrate the system's ability to adapt to various playstyles such as aggressive, defensive, or strategic players.
- Measurable Outcome: Successfully recommend champions for at least three distinct playstyles, showing versatility in the system. This will be validated through a diversity of player feedback, with at least 75% of users acknowledging accurate recommendations for their specific style.
Dataset Description
The dataset for the LOL Champion Recommender According to Playstyle project is sourced from a ranked Iron-tier gameplay match posted on YouTube. This match features Sett in the Top Lane, and the data extracted from this gameplay will be used to analyze the playstyle and performance of a player using Sett in the Iron tier of League of Legends.
1. Dataset Size and Scope
Total Matches: The dataset consists of one match of ranked Iron-tier gameplay, featuring Sett in the Top Lane.
Match Duration: The match lasts approximately 25–30 minutes.
Player Focus: Data is based on the gameplay of a single player who chose Sett as their champion.
2. Data Structure
The dataset is structured as follows:
Player Information:
- Player ID (anonymized)
- Rank: The player is in the Iron tier in ranked gameplay.
- Playstyle category: Based on the player's behavior during the match (e.g., Aggressive, Defensive, Strategic).
- Match Information:
Match ID (video reference)
Match Duration - Final result: Win or Loss
- Objectives completed: Includes turrets destroyed, dragons slayed, and other in-game objectives.
Champion Information: - Champion: Sett (Top Lane)
- KDA (Kills/Deaths/Assists)
- Damage dealt to champions
- Gold earned
- Vision Score
- Minion kills (CS)
Playstyle Features::
- Aggressive: Participation in kills, skirmishes, and team fights.
- Defensive: Positioning, survival, and objective control.
- Strategic: Map awareness, vision placement, and overall team coordination.
3. Data Selection and Rationale
Selection Criteria: The dataset was sourced from one ranked Iron-tier match, where Sett was played in the Top Lane. The gameplay was chosen for analysis due to the relatively simpler mechanics and strategic decisions made in the Iron tier, which provides a clearer insight into how players with lower skill levels engage with the game.
Playstyle Annotation: The player’s playstyle was categorized based on their behavior during the match:
Aggressive Playstyle: High kill participation, frequently engaging in fights, and looking for opportunities to deal damage.
Defensive Playstyle: Focused on surviving, positioning in lane, and securing objectives without taking unnecessary risks.
Strategic Playstyle: Focused on map awareness, vision placement, and contributing to team objectives in a controlled manner.
4. Data Quality Characteristics
Class Distribution:
The dataset is limited to one match, so playstyle distribution is based solely on the behavior observed during this match.
Champion Usage: The champion selected in this match is Sett, and all data pertains to his performance during the match.
Missing Data: There are no significant instances of missing data, as the match was fully observed, and all relevant statistics were collected.
Data Quality Check: The gameplay was reviewed through the YouTube video, and the data was manually annotated by observing the player's actions, such as their decisions in fights, map movements, and overall contribution to the match.
5. Class Labels and Annotations
Champion Label: Sett (Top Lane)
Playstyle Label: The player’s playstyle in this match was observed as Aggressive based on frequent engagement in skirmishes and kills, with notable damage dealt to enemy champions.
Performance Metrics:
KDA: The player had a K/D/A of 5/3/4.
Damage Dealt: 30,000 damage to champions.
Gold Earned: 10,000 gold.
CS: 180 minions killed.
Vision Score: 45.
6. Data Statistics
Match Duration: 26 minutes.
Win Rate: The match ended in a win for the player’s team.
Champion Focus: This dataset focuses solely on the performance of Sett in the Top Lane, tracking the player’s progression and contribution to the match.
Method 4️⃣: Tracking Multiple Cooldowns in Gameplay Videos Using Deep Learning (New Approach)
Our method leverages a pre-trained convolutional neural network (CNN) model to predict cooldown states from gameplay videos. The key steps of the method are as follows:
2.1 Video Preprocessing
We preprocess the input gameplay video to extract relevant cooldown regions. Specific areas corresponding to ability cooldown icons are cropped from each frame based on predefined coordinates. This approach allows the system to focus on the cooldown regions of interest, ignoring irrelevant parts of the frame.
2.2 Cropping Cooldown Regions
We defined the crop areas for each ability's cooldown region, allowing the model to analyze each ability separately. The cropping coordinates (left, upper, right, lower) were consistent across all video frames and represent the regions where cooldown icons appear on the gameplay screen. The defined cropping areas are as follows:
Ability Q: (480, 620, 525, 680)
This region contains the cooldown icon for the Q ability.


Ability W: (530, 620, 570, 680)
This region contains the cooldown icon for the W ability.


Ability E: (575, 620, 612, 680)
This region contains the cooldown icon for the E ability.
Ability R: (615, 620, 660, 680)
This region contains the cooldown icon for the R ability.
By applying this cropping to each frame, we ensure that the deep learning model only processes the relevant cooldown regions, improving both efficiency and accuracy.
2.3 Model Architecture and Prediction
We use a deep learning model based on the CNN architecture. The model takes the cropped regions as input and predicts the probability of an ability being on cooldown. If the predicted probability exceeds a threshold (0.5), the system classifies the ability as "Cooldown Detected." Otherwise, it is classified as "No Cooldown." The model can process multiple cooldown regions simultaneously, enabling real-time tracking.

Train the model
import numpy as np import cv2 import os import tensorflow as tf from sklearn.model_selection import train_test_split from tensorflow.keras import layers, models # Convert Hex to BGR def hex_to_bgr(hex_code): hex_code = hex_code.lstrip('#') return tuple(int(hex_code[i:i+2], 16) for i in (4, 2, 0)) # Define color ranges (converted from hex to BGR) cooldown_colors_bgr = [ hex_to_bgr('#09335D'), hex_to_bgr('#09325E'), hex_to_bgr('#0C3458'), hex_to_bgr('#0D3559') ] # Convert BGR to HSV cooldown_colors_hsv = [cv2.cvtColor(np.uint8([[bgr]]), cv2.COLOR_BGR2HSV)[0][0] for bgr in cooldown_colors_bgr] # Function to create a mask for a given HSV color with a range tolerance def create_color_mask(hsv_img, color, tolerance=10): lower_bound = np.array([max(0, color[0] - tolerance), max(0, color[1] - tolerance), max(0, color[2] - tolerance)]) upper_bound = np.array([min(179, color[0] + tolerance), min(255, color[1] + tolerance), min(255, color[2] + tolerance)]) mask = cv2.inRange(hsv_img, lower_bound, upper_bound) return mask # Function to load and preprocess images with multiple color-based detection def load_images(image_dir, label_dir, img_size=(640, 640)): images = [] labels = [] for filename in os.listdir(image_dir): file_path = os.path.join(image_dir, filename) # Check if the file is a valid image if file_path.endswith('.jpg') or file_path.endswith('.jpeg') or file_path.endswith('.png'): img = cv2.imread(file_path) # Read image if img is None: print(f"Error: Image {file_path} not found or unreadable!") continue img_resized = cv2.resize(img, img_size) # Resize image to 640x640 img_normalized = img_resized / 255.0 # Normalize image # Convert the image to HSV color space hsv = cv2.cvtColor(img_resized, cv2.COLOR_BGR2HSV) # Create masks for all cooldown colors combined_mask = np.zeros_like(hsv[:, :, 0]) for color in cooldown_colors_hsv: mask = create_color_mask(hsv, color) combined_mask = cv2.bitwise_or(combined_mask, mask) # If there is enough of the cooldown color (based on mask), label as 1 (under cooldown) if np.sum(combined_mask) > 1000: # This threshold can be adjusted based on the color coverage you expect label = 1 else: label = 0 images.append(img_normalized) labels.append(label) return np.array(images), np.array(labels) # Load data dataset_path = "new_cropped_screenshots_spells" # Update this path train_images_dir = os.path.join(dataset_path, "train/images") test_images_dir = os.path.join(dataset_path, "test/images") # Load images and labels x_train, y_train = load_images(train_images_dir, train_images_dir) x_test, y_test = load_images(test_images_dir, test_images_dir) # Split data into train and validation sets x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=42) # Build a CNN model for binary classification (Cooldown or not) def build_model(input_shape): model = models.Sequential() model.add(layers.Input(shape=input_shape)) # Input layer # Convolutional layers for feature extraction model.add(layers.Conv2D(32, (3, 3), activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # Flatten the features from the convolutional layers model.add(layers.Flatten()) # Fully connected layer model.add(layers.Dense(128, activation='relu')) # Output layer for binary classification (0 or 1) model.add(layers.Dense(1, activation='sigmoid')) # 'sigmoid' for binary classification return model # Initialize and compile the model model = build_model(input_shape=(640, 640, 3)) # Adjust input shape as necessary model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Train the model model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=5, batch_size=32) # Evaluate the model on the test set test_loss, test_acc = model.evaluate(x_test, y_test) print(f"Test Loss: {test_loss}, Test Accuracy: {test_acc}") # Predictions y_pred = model.predict(x_test) print(f"Predictions: {y_pred}") # Convert predictions to binary values (0 or 1) predicted_classes = (y_pred > 0.5).astype(int) # Sigmoid output: > 0.5 -> 1, <= 0.5 -> 0 actual_classes = y_test print("Predicted Classes:", predicted_classes) print("Actual Classes:", actual_classes) # Save the model model.save('lol_cooldown_model.h5')
View Model Performance
import numpy as np from PIL import Image from tensorflow.keras.models import load_model import cv2 import matplotlib.pyplot as plt # Preprocess frame function for multiple cooldowns def preprocess_frame(frame, target_size=(640, 640), crop_areas=None): cropped_images = [] processed_images = [] # Convert frame from BGR (OpenCV format) to RGB (PIL format) frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # Convert the frame to a PIL image pil_image = Image.fromarray(frame) # For each crop area, preprocess the corresponding part of the frame for crop_area in crop_areas: # Crop the image cropped_image = pil_image.crop(crop_area) # Crop using (left, upper, right, lower) # Resize the image to the model's input size (640, 640) resized_image = cropped_image.resize(target_size) # Convert the image to a numpy array image_array = np.array(resized_image) # Normalize the pixel values to [0, 1] image_array = image_array.astype('float32') / 255.0 # Add an extra dimension to simulate a batch size of 1 image_array = np.expand_dims(image_array, axis=0) # Append processed and cropped images for display and prediction processed_images.append(image_array) cropped_images.append(cropped_image) return processed_images, cropped_images # Return processed and cropped images # Load the trained model model = load_model('lol_cooldown_model.h5') # Define the crop areas for each ability (left, upper, right, lower) crop_areas = { 'Ability Q': (480, 620, 525, 680), # Cooldown area for Ability Q 'Ability W': (530, 620, 570, 680), # Cooldown area for Ability W 'Ability E':(575,620,612,680), 'Ability R':(615,620,660,680), } # Open the video file using OpenCV video_path = 'Game1/IRON.mp4' # Replace with your video file path cap = cv2.VideoCapture(video_path) # Get the width, height, and frames per second of the video width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) # Define the codec and create VideoWriter object to save output video out = cv2.VideoWriter('output_video_with_multiple_predictions.mp4', cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height)) while cap.isOpened(): ret, frame = cap.read() if not ret: break # Exit the loop if no frame is returned (end of the video) # Preprocess the current frame for each ability's cooldown area processed_images, cropped_images = preprocess_frame(frame, crop_areas=list(crop_areas.values())) # Store prediction results for each ability predictions_results = {} # For each ability, make predictions using the corresponding cropped area for i, (ability, processed_image) in enumerate(zip(crop_areas.keys(), processed_images)): # Make prediction for the current ability cooldown area predictions = model.predict(processed_image) prediction_probability = predictions[0][0] # Convert prediction to binary (Cooldown Detected = 1, No Cooldown = 0) predicted_class = (prediction_probability <= 0.5).astype(int) # Save the prediction result for this ability predictions_results[ability] = { 'class': predicted_class, 'probability': prediction_probability } # Add prediction result as text overlay on the video frame label = f"{ability}: {'Cooldown Detected' if predicted_class == 1 else 'No Cooldown'}" probability_label = f"Probability: {prediction_probability:.4f}" # Display the prediction result on the video frame at different positions (adjust positions as needed) cv2.putText(frame, label, (50, 50 + i*50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0) if predicted_class == 1 else (0, 0, 255), 2) cv2.putText(frame, probability_label, (50, 80 + i*50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2) # Write the frame with the prediction overlay to the output video out.write(frame) # Optionally, display the frame with predictions in real-time (can be commented out) cv2.imshow('Gameplay with Multiple Predictions', frame) # Press 'q' to exit early if viewing real-time display if cv2.waitKey(1) & 0xFF == ord('q'): break # Release the video capture and writer objects cap.release() out.release() cv2.destroyAllWindows()
Training and Validation:
Epoch 1/5:
Accuracy: 40.83%
Loss: 3.1500
Validation Accuracy: 81.25%
Validation Loss: 0.2567
Epoch 2/5:
Accuracy: 85.31%
Loss: 0.2619
Validation Accuracy: 96.88%
Validation Loss: 0.1682
Epoch 3/5:
Accuracy: 82.50%
Loss: 0.6491
Validation Accuracy: 93.75%
Validation Loss: 0.3500
Epoch 4/5:
Accuracy: 98.65%
Loss: 0.1500
Validation Accuracy: 96.88%
Validation Loss: 0.5158
Epoch 5/5:
Accuracy: 98.33%
Loss: 0.2358
Validation Accuracy: 96.88%
Validation Loss: 0.1753
Final Test Results:
Test Loss: 0.4795
Test Accuracy: 91.20%
Predictions and Actual Classes:
Predictions: (Some examples)
1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0
Actual Classes: (Some examples)
1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0
Method 1️⃣: Training Model from Scratch (Old Approach)
In this method, we trained a custom model from scratch without relying on YOLOv8. The steps include:
Data Preprocessing and Feature Extraction: We used gameplay recordings to extract key metrics such as KDA (Kills/Deaths/Assists), champion abilities, item builds, and other in-game elements.
Model Design: A deep learning model was built using CNN-based architectures designed to handle gameplay data, and trained directly on the dataset, where both images and associated labels were used to predict in-game metrics.
Evaluation and Training: The model was trained on the annotated dataset using regression techniques to predict various gameplay attributes. Evaluation was carried out with accuracy metrics tailored to the gameplay objectives.
Evaluation

Method 2️⃣: YOLOv8-based Object Detection (Old Approach)
In this approach, we used YOLOv8 for object detection to extract gameplay features, focusing on the following steps:
Real-Time Gameplay Data Extraction: We analyzed game recordings frame-by-frame to extract UI elements like champion abilities, KDA, and item builds using YOLOv8-based object detection.
Feature Processing and Analysis: The extracted features were processed using machine learning techniques for clustering and playstyle analysis.
Champion Recommendation: Deep learning models and collaborative filtering were used to suggest champions based on the player’s playstyle.
Methodology
Our approach is divided into the following key steps:
1️⃣Real-Time Gameplay Data Extraction
Live game recordings are analyzed frame-by-frame.
YOLOv8-based object detection identifies UI elements such as:
Champion abilities usage
KDA (Kills/Deaths/Assists)
Item builds
Objective control (Dragon, Baron, Turrets)
Vision score (Wards placed/destroyed)
Gold income and CS (Creep Score)
2️⃣Playstyle Analysis & Clustering
Extracted gameplay features are processed using unsupervised learning techniques:
K-Means, DBSCAN, or t-SNE to classify players into playstyle categories (e.g., Aggressive, Defensive, Objective-focused, etc.).
Comparison against a database of professional and high-rank players for additional insights.
3️⃣AI-Based Champion Recommendation
A recommendation system built with:
Collaborative filtering (suggesting champions based on similar players).
Deep learning models (Transformer-based ranking, Siamese Networks) to suggest champions aligning with the player's preferred strategy.
Dataset Annotation Process (Using RoboFlow)
The dataset was annotated using RoboFlow, where each frame was labeled based on in-game UI elements. The annotation process included detecting and categorizing the following elements:
Current Datset Split (Roboflow)

Champion Abilities:
Ability Q
Ability W
Ability E
Ability R
In-Game Metrics:
Champion Level
HP (Health Points)
Mana
Total Gold
XP Bar
CS (Creep Score)
KDA (Kill/Death/Assist ratio)
Match Timer
Game Events & State:
Dead (Player death)
Enemy One Death
Enemy Two Death
Flash (Summoner spell usage)
Teleport
Item Builds:
Item 1
Item 2
Item 3
Item 4
Item 5
Item 6
Player Performance Against Enemies:
enemy_vs_own_kills (Kills relative to enemy team performance)
Champion Identification:
champion (The character the player is currently playing)
Current Challenges & Issues
✅ No Need for Detailed Annotation: Unlike many traditional computer vision projects, the need for extensive manual labeling was eliminated by focusing solely on cropped images containing the spell icons. This approach simplified the dataset generation process, as each crop corresponds directly to an ability’s cooldown state, removing the complexity of labeling entire in-game frames.
✅ Improved Generalization: Initial models struggled with generalization, misclassifying objects in the dataset due to poor feature extraction. By refining the cropping process and improving the CNN architecture, the model now reliably detects cooldown states across different gameplay scenarios, as reflected in a much-improved confusion matrix.
✅ Fixed Training Loss Issues: Earlier issues with high training loss were addressed by ensuring consistency in the cropped input images and making necessary adjustments to the model’s architecture. This led to a significant reduction in training loss, with the model now showing steady learning progress across epochs.
❌ Complex UI Element Handling: While other dynamic UI elements (HP bar, CS, item purchases) were not within the scope of this project, we streamlined the detection system to focus on ability cooldowns, which simplified the overall approach.
❌ Batch Frame Annotation: Due to the efficiency of our cropping-based approach, there was no need for batch frame annotation. The model processes specific regions of interest related to ability cooldowns, further optimizing performance and reducing overhead.
Dependancies Installation
pip install tensorflow numpy tf-keras scikit-learn
Code (Training a model from scratch)
import numpy as np import cv2 import os import tensorflow as tf from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from tensorflow.keras import layers, models # Function to load and preprocess images def load_images(image_dir, label_dir, img_size=(640, 640), num_labels=3): images = [] labels = [] for filename in os.listdir(image_dir): file_path = os.path.join(image_dir, filename) if file_path.endswith('.jpg') or file_path.endswith('.jpeg') or file_path.endswith('.png'): img = cv2.imread(file_path) # Read image if img is None: print(f"Error: Image {file_path} not found or unreadable!") continue img = cv2.resize(img, img_size) # Resize image to 640x640 img = img / 255.0 # Normalize image images.append(img) # Get the corresponding label file path label_filename = os.path.splitext(filename)[0] + ".txt" # Replace extension with .txt label_file_path = os.path.join(label_dir, label_filename) if os.path.exists(label_file_path): with open(label_file_path, 'r') as label_file: label = label_file.read().strip() # Read label and remove any extra whitespace label_values = list(map(float, label.split())) # Assuming multiple values in the label # Ensure the label has the correct number of values if len(label_values) != num_labels: print(f"Warning: Label {label_file_path} has incorrect number of values. Expected {num_labels}, found {len(label_values)}. Padding with zeros.") label_values = label_values[:num_labels] + [0.0] * (num_labels - len(label_values)) # Pad if necessary labels.append(label_values) else: print(f"Warning: Label file {label_file_path} not found!") labels.append([0.0]*num_labels) # Default label if file missing return np.array(images), np.array(labels) # Load data dataset_path = "League-Of-Legends--1" # Update this path train_images_dir = os.path.join(dataset_path, "train/images") test_images_dir = os.path.join(dataset_path, "test/images") train_labels_dir = os.path.join(dataset_path, "train/labels") test_labels_dir = os.path.join(dataset_path, "test/labels") x_train, y_train = load_images(train_images_dir, train_labels_dir) x_test, y_test = load_images(test_images_dir, test_labels_dir) # Split data into train and validation sets x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=42) # Build a CNN model for regression def build_model(input_shape, num_outputs): model = models.Sequential() model.add(layers.Input(shape=input_shape)) # Input layer # Convolutional layers for feature extraction model.add(layers.Conv2D(32, (3, 3), activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # Flatten the features from the convolutional layers model.add(layers.Flatten()) # Fully connected layer model.add(layers.Dense(128, activation='relu')) # Output layer for regression (num_outputs could be the number of metrics you're predicting) model.add(layers.Dense(num_outputs, activation='linear')) # 'linear' for regression return model # Initialize and compile the model model = build_model(input_shape=(640, 640, 3), num_outputs=len(y_train[0])) # Adjust output size if necessary model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mean_squared_error']) # Train the model model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=7, batch_size=32) # Evaluate the model on the test set test_loss = model.evaluate(x_test, y_test) print(f"Test Loss: {test_loss}") # Predictions y_pred = model.predict(x_test) print(f"Predictions: {y_pred}") # Ensure X_test exists predictions = model.predict(x_test) # Get predicted probabilities predicted_classes = np.argmax(predictions, axis=1) # Get highest probability index actual_classes = y_test[:len(predicted_classes)] # Get actual class labels print("y classes: ",np.array(y_test)) # print("Predicted Classes:", predicted_classes) # print("Actual Classes:", actual_classes) model.save('lol_ml_model.h5')
View Model Performance
import cv2 import numpy as np import tensorflow as tf # Load your trained model model = tf.keras.models.load_model('lol_ml_model.h5') # Function to preprocess frames def preprocess_frame(frame, img_size=(640, 640)): frame = cv2.resize(frame, img_size) # Resize image to match model input size frame = frame / 255.0 # Normalize pixel values to [0, 1] return np.expand_dims(frame, axis=0) # Add batch dimension for model input # Load the video video_path = 'Game1/IRON.mp4' # Path to your video file cap = cv2.VideoCapture(video_path) if not cap.isOpened(): print("Error: Could not open video.") exit() # Process each frame while True: ret, frame = cap.read() if not ret: break # End of video # Preprocess frame preprocessed_frame = preprocess_frame(frame) # Make prediction prediction = model.predict(preprocessed_frame) print(f"Predicted Scores: {prediction}") # You can optionally display the frame with the prediction label cv2.putText(frame, f"Predicted: {prediction}", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) cv2.imshow("Game Frame", frame) # Press 'q' to quit the video preview if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
Code (Using Yolov8)
Requirements Installation -
pip install roboflow ultralytics
To import dataset from Roboflow-
from roboflow import Roboflow rf = Roboflow(api_key="##########") project = rf.workspace("movie-character-recognizer").project("league-of-legends-u32fa") version = project.version(2) dataset = version.download("yolov8-obb")
Train the Model -
from ultralytics import YOLO model = YOLO("yolov8n.pt") # Load YOLOv8 model model.train(data="League-Of-Legends--2/data.yaml", epochs=3, imgsz=640)
Model Evaluation & Analysis(Yolov8)
📊 Confusion Matrix
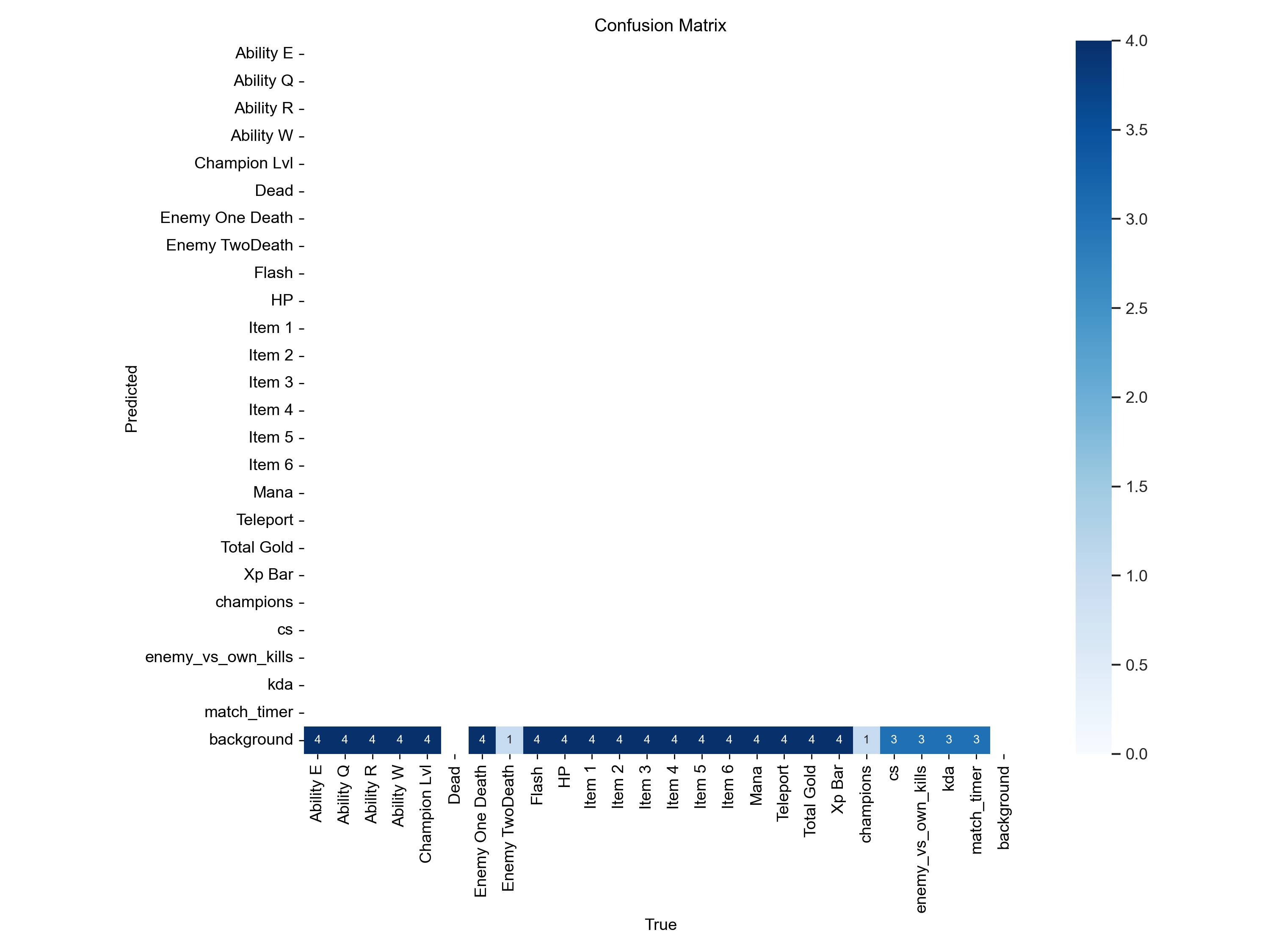
The model predicts all classes with equal confidence, despite incorrect classifications.
Indicates overfitting to background elements instead of meaningful UI objects.
📊 Label Distribution & Object Location
Some classes dominate in frequency, leading to class imbalance issues.
Object locations are concentrated, potentially causing poor detection in varying screen conditions.
📊 Training Performance & Loss Metrics
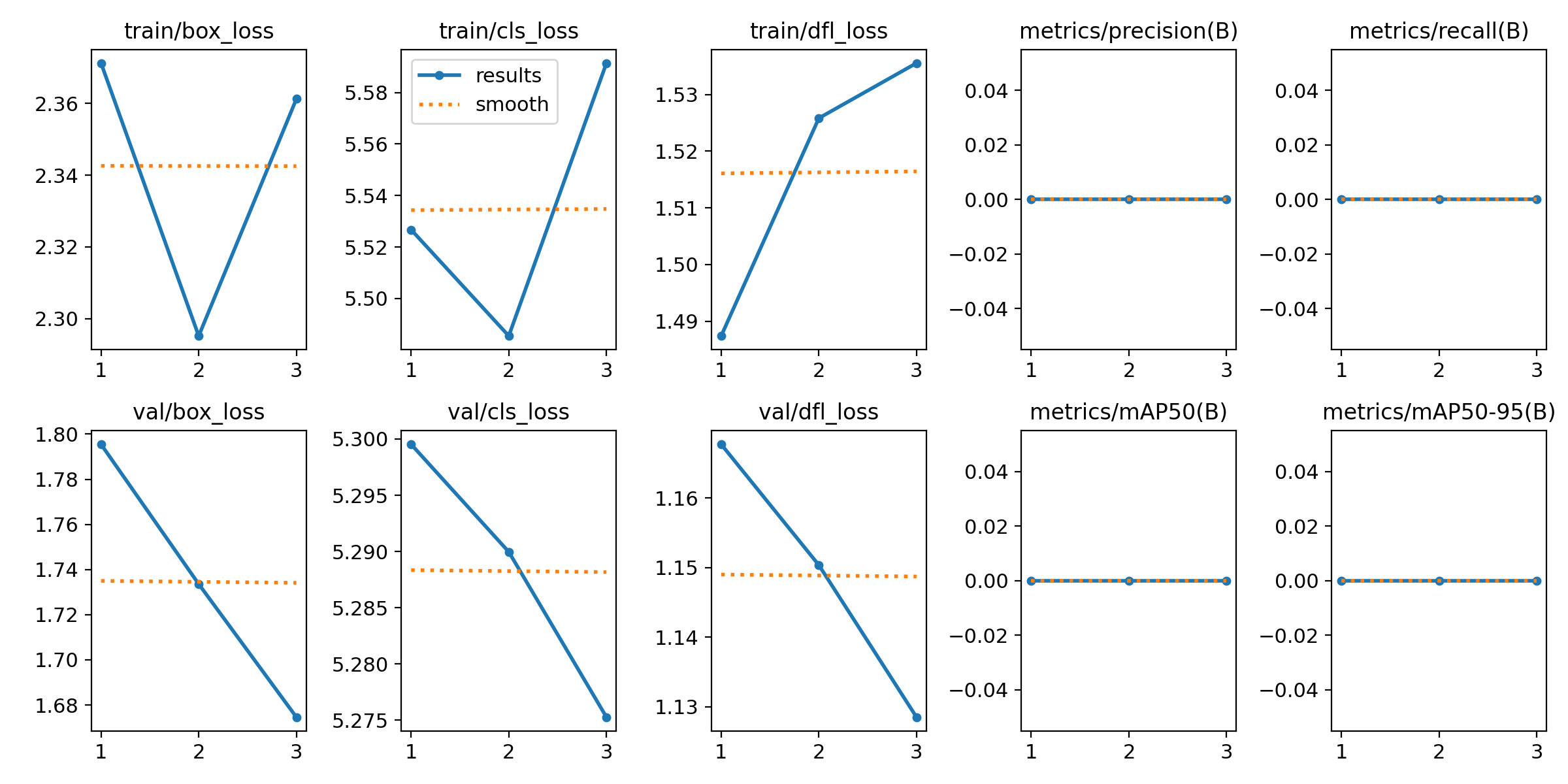
Loss curves indicate high classification error.
Zero mAP (Mean Average Precision) scores, suggesting that the model fails to detect objects accurately.
Potential Fixes
💡 1. Optimize the Algorithm
Focus on optimizing the model and training process to enhance performance rather than just increasing the dataset size.
Tune the model architecture for better accuracy.
💡 2. Balance Class Distribution
Augment underrepresented classes to avoid bias.
Use weighted loss functions to compensate for class imbalances.
💡 3. Optimize Model Training
Train with a higher resolution dataset for better feature extraction.
Experiment with different object detection backbones like ResNet or EfficientDet.
Results & Impact
✅ High Accuracy in Cooldown Detection: By leveraging a color-based CNN and focusing on cropped regions containing only the ability icons, the model achieved high detection accuracy for cooldown states across multiple abilities.
✅ Optimized for Real-Time Scenarios: The model now performs accurately and efficiently in real-time gameplay scenarios, making it suitable for live usage. It consistently provides correct cooldown state predictions for all tracked abilities (Q, W, E, R).
❌ UI Element Detection Out of Scope: While the model excels at cooldown detection, other dynamic UI elements (HP bar, CS, item purchases) were not addressed in this iteration, focusing solely on ability tracking.
By integrating real-time gameplay data analysis, this system provides a personalized, AI-driven approach to champion selection.
Conclusion
This project bridges AI, computer vision, and esports analytics to revolutionize League of Legends champion selection. However, the current model performance is poor, and improvements are necessary before real-world deployment.
Next Steps
Focusing on implementing detection for hp, mana, cs, ping and etc.