Abstract
This research focused on the efficient collection of experimental Metal-Organic Framework (MOF) data from scientific literature to address the challenges of accessing hard-to-find data and improving the quality of information available for machine learning studies in materials science. Utilizing a chain of advanced Large Language Models (LLMs), we developed a systematic approach to extract and organize MOF data into a structured format. Our methodology successfully compiled information from more than 40,000 research articles, creating a comprehensive and ready-to-use dataset. Specifically, data regarding MOF synthesis conditions and properties were extracted from both tables and text and then analyzed. Subsequently, we utilized the curated database to analyze the relationships between synthesis conditions, properties, and structure. Through machine learning, we identified the existence of a gap between simulation data and experimental data, and further analysis revealed the factors contributing to this discrepancy. Additionally, we leveraged the extracted synthesis condition data to develop a synthesis condition recommender system. This system suggests optimal synthesis conditions based on the provided precursors, offering a practical tool to refine synthesis strategies. This underscores the importance of experimental datasets in advancing MOF research.
Introduction
In the past decade, there has been an increasing number of datasets available in materials science obtained from computational simulations and experimental studies.[1-6] This abundance of data is crucial for the advancement of machine learning in the field, as it underpins the development of models that can accurately predict material properties and lead to the discovery of new materials. The significance of extracting and collecting this data cannot be overstated, as it improves the accuracy of predictive models[7, 8] and addresses the challenges associated with relying solely on computational simulations, which may not always reflect experimental results. This approach underscores the need to extract empirical data from the vast textual corpus of scientific literature. By mining large amounts of experimental data from already published papers, the data acquisition hurdle becomes lowered and one can enrich the connection between theoretical predictions and experimental validations in materials science.
Metal-Organic Frameworks (MOFs) are porous materials composed of metal ions or clusters coordinated with organic ligands, forming extensive networks with vast surface areas. Their significance is highlighted by a wide range of applications, from gas storage[9-13] and separation[14-17] to catalysis[17, 18] and drug delivery[19, 20], thanks to their customizable porosity and functionality. The sheer variety of MOFs, arising from the numerous potential metal-ligand combinations, emphasizes the critical need for comprehensive MOF data mining. This process is vital for systematically cataloging the properties and functionalities of MOFs, thus facilitating the precise design and utilization of these versatile materials across various sectors. Given the extensive potential and variability of MOFs, it is unsurprising that a substantial body of research is devoted to mining MOF data.
Previously, Park et al.[21] extracted specific data, such as surface area and pore volumes, from scientific texts using rule-based techniques, shedding light on the structural-property relationships in MOFs. Projects such as 'DigiMOF'[22] have demonstrated the effectiveness of rule-based coding in extracting synthetic information of MOFs using Natural Language Processing (NLP). The landscape has transformed with the incorporation of machine learning, as seen in the works of Nandy et al.[23, 24] They leveraged predictive models to assess the stability of MOFs, marking a leap in the accuracy, and sophistication of data mining efforts. Park et al.[25] highlighted further advancements by employing Positive and Unlabeled (PU) learning to predict MOF synthesizability, showcasing the nuanced capabilities of machine learning in addressing complex challenges in MOF synthesis. Manning et al.[26] conducted a thorough analysis of synthesis protocols, focusing on ZIF-8. They identified prevailing trends and optimized methodologies, demonstrating the importance of data mining in refining synthesis processes and deepening the understanding of MOF characteristics, underscoring the significant and evolving impact of data mining techniques in the field.
Recently, the emergence of large language models (LLMs), such as ChatGPT, has revolutionized data mining, particularly in extracting nuanced information from textual sources. These models excel at understanding textual context, enabling them to perform complex data mining tasks with high efficiency. LLMs have demonstrated remarkable capability in few-shot learning, achieving accurate results with minimal examples. This reduces the threshold for adopting advanced data mining techniques across various research fields. Furthermore, prompt engineering has become crucial in optimizing LLMs for specific challenges. Yaghi's group applied LLMs to extract metal-organic framework (MOF) synthesis parameters from scientific literature with exceptional precision.[27] LLMs have a wide range of applications, including predicting crystallization outcomes and facilitating interactive platforms such as MOF chatbots, significantly enriching the paradigms of data-driven research.
Building on the pioneering work of Yaghi's group in using large language models (LLMs) for data mining, we present 'L2M3' (Large Language Model MOF Miner), an innovative data mining system that fully automates the extraction process through a sophisticated array of LLMs. Our system has rigorously analyzed over 40,000 MOF papers, extracting 32 well-defined properties in a specific format, alongside a broader collection of properties in a more general form. We have further classified the MOF synthesis process into 21 distinct categories, each with its unique data format, thereby enhancing the granularity of our dataset. Leveraging this comprehensive dataset, we analyzed the structure-synthesis-property relationships of MOFs. First, we conducted a machine learning study to predict the properties of MOFs. This revealed discrepancies between experimental results and theoretical predictions, prompting further analysis to uncover the underlying reasons behind these discrepancies. Additionally, we leveraged the extracted synthesis condition data to develop a synthesis condition recommender system. This system suggests optimal synthesis conditions based on the provided precursors, offering a practical tool to refine synthesis strategies. These advancements highlight the transformative potential of systematic data collection and machine learning in advancing MOF research.
Result & Discussion
Overall workflow
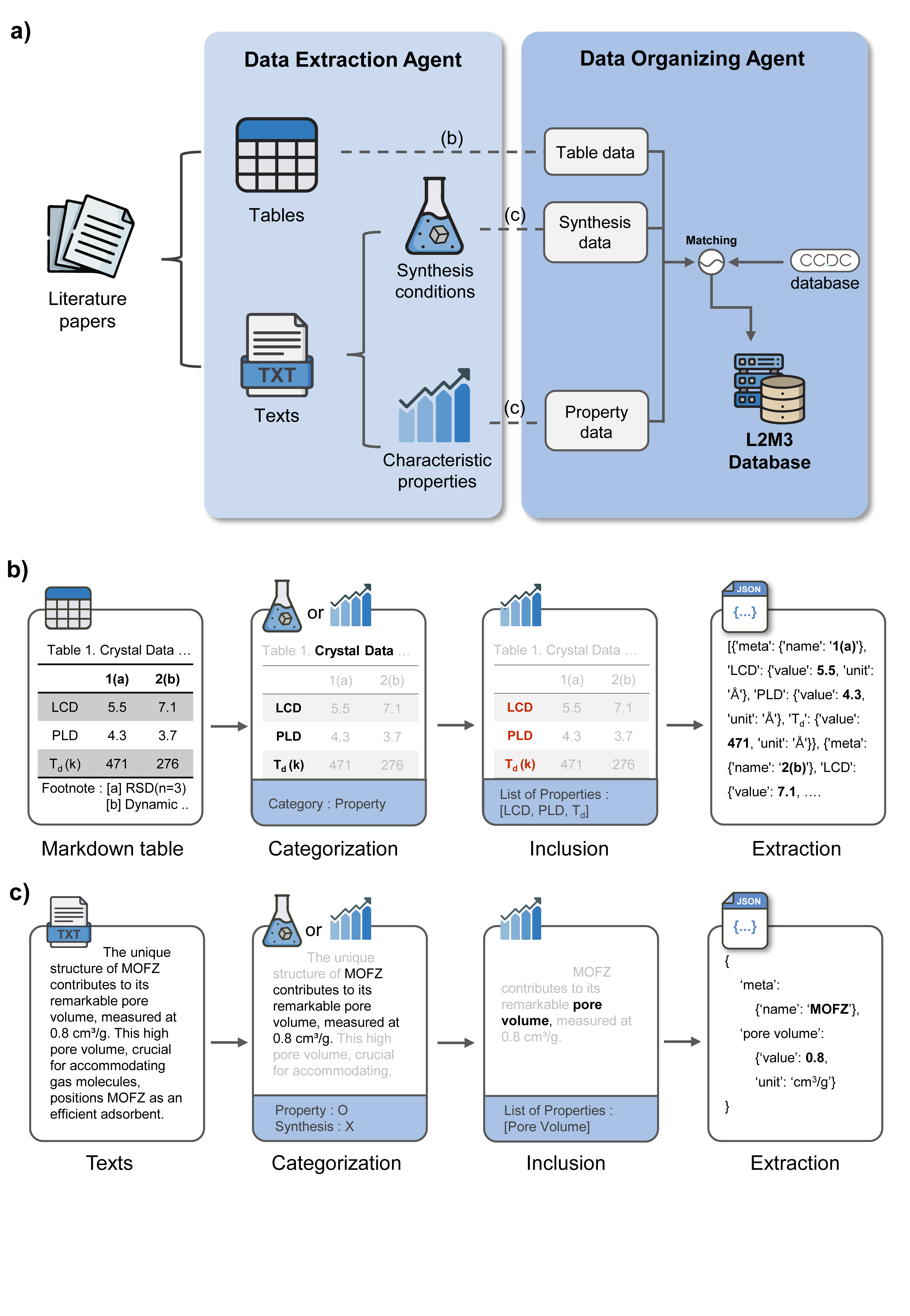
Figure 1. (a) Overall schematic of the L2M3 model (b) Overall process of table mining (c) Overall process of text mining
Figure 1(a) shows the overall framework of the L2M3 model, which extracts information from both text and tables in scientific papers. The model employs three specialized agents: the table agent, the synthesis condition agent and the property agent, all of which are used in the mining process. These three agents are used to extract information from papers about the properties and synthesis conditions of MOFs. After extraction, a matching agent standardizes material names and symbols to consolidate the extracted data into a unified metadata set. Finally, the consolidated dataset is matched against crystal data in the CCDC database[28] for structural matching. The process is designed for efficient input and output handling through a single code execution.
Figure 1(b) explains how the table agent processes the table data. Achieving accurate extraction from complex tables using rule-based coding techniques is challenging. To address this, a table agent based on LLM has been developed to increase the reliability of information extraction from tables. This agent works in three stages: categorization, inclusion and extraction. First, a categorization agent sorts tables into three categories: property table, crystal information table, and others. Examples of each table type can be found in Supplementary Table S1-S3. Next, inclusion is performed on the property table and the crystal information table, determining what information is contained in these tables. Finally, the extraction agent retrieves relevant information from both the Property and Crystal Info tables.
Figure 1(c) shows the process used by the synthesis condition agent and the property agent to extract information from text. In categorization step, the agent classifies the texts based on whether they describe a property, a synthesis condition, or contain no relevant information. If a paragraph describes a synthesis condition, the synthesis condition agent is used; if it refers to a property, the property agent is used. Each agent then performs inclusion steps to determine the specific information present. The properties and synthesis methods that can be extracted are listed in Supplementary Table S4 and S5. Following the inclusion steps, the extraction steps are performed to extract the information. The extraction prompt is tailored to the synthesis condition or property type identified, increasing accuracy and correctly formatting the data. In both processes, prompt engineering, model selection, temperature control, and validation process were employed to minimize hallucination and enhance consistency. (See Supplementary Note S1)
The individual steps in the data extraction phase are not independent. To extract a large number of properties and operations into the desired format, the length of the prompt increases significantly. This can lead to reduced accuracy, increased costs and cause significant user inconvenience. To address this issue, an adaptable LLM prompt has been designed within the extraction agent, allowing modifications based on the properties extracted during the inclusion stage. Figure 2(a) shows a schematic of the prompt generation process within the extraction agent. The system prompt for the extraction agent adapts to the results of the categorization process, taking into account the roles of synthesis text, property text, property table and crystal table. Properties or synthesis operations extracted during the inclusion step are transformed into corresponding information, JSON format and examples. These components are then combined to create the final extraction agent. This approach reduces the length of the prompt while ensuring that each property and synthesis operation is accurately maintained in JSON format.

Figure 2. (a) Example of an adaptable LLM prompt used in the Extraction Agent. Each component of the extraction prompt is constructed based on information obtained from the categorization and inclusion phases. (b) Schematic representation of the Data Organizing Agent. Data extracted by the Data Extracting Agent are tagged with metadata, which are compared to group data belonging to the same material into a unified dataset.
To ensure that the extracted information has meaningful value, it is essential to link data extracted from different sources (e.g. text, tables and the CSD database) and data with different attributes (e.g. synthesis conditions and properties) for each MOF. Figure 2(b) provides an overview of how the data organizing agent merges information for the same material. Each data point is tagged with metadata, which includes attributes such as name, symbol, chemical formula, synonyms, refcode and lattice. During the data organization phase, the system checks whether data points have identical metadata attributes and links them to form a unified dataset for the same material. Subsequently, the chemical formula and lattice are compared with the CCDC database to establish links between the extracted data and the corresponding CCDC refcodes (see Methods section). This methodology establishes links between structure, synthesis and properties, aiding subsequent analyses and facilitating deeper insight into these relationships.
Finally, a refinement process was implemented using an LLM agent designed to verify whether the extracted information pertained specifically to MOFs. This step was necessary to filter out non-target materials, such as linkers or MOF composites that might have been inadvertently included during data extraction. Through this process, only the information relevant to the target material, MOFs, was retained. The detailed methodology for this verification process is provided in Supplementary Note S2.
Data mining result
MOF papers were collected based on the MOF subset criteria of the Cambridge Structural Database (CSD)[28] and through a search of MOF-related keywords in the Scopus database.[29] After analyzing over 40,000 academic papers and excluding those with errors, a dataset comprising 39,476 papers on synthesis conditions and material properties was successfully compiled. To assess the accuracy of the data analysis conducted using LLMs, a random sample of 150 papers was selected, taking into account the diversity of publishers. The evaluation was conducted separately based on three paragraph types: synthesis, property, and table. Each type was subjected to specific evaluation criteria across three tasks: categorization, inclusion, and extraction. For the categorization task, the focus was on verifying the correct identification of relevant information. The inclusion task ensured that the properties or synthesis method mentioned in the paragraphs were accurately captured, with any irrelevant details excluded. In the extraction task, attention was given to whether the correct values were presented in the specified JSON format. Further details on the evaluation process are available in Supplementary Note S3.
| Data Type | Categorization | Inclusion | Extraction | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| Synthesis | 1.00 | 0.98 | 0.99 | 0.96 | 0.91 | 0.94 | 0.96 | 0.90 | 0.93 |
| Property | 0.98 | 0.94 | 0.96 | 0.98 | 0.98 | 0.98 | 0.97 | 0.90 | 0.93 |
| Table | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
Table 1. Precision, recall, and F1 score of each step.
The accuracy evaluation results for the text mining process are summarized in Table 1. In the categorization task, our work achieved F1 scores higher than 0.96 across all three categories. This high performance can be attributed to the relatively straightforward structure of the classification task, with fewer classes to distinguish, making it easier than other tasks. Similarly, the inclusion task achieved a remarkable F1 score of over 0.94, reflecting high accuracy. The synthesis information extraction showed slightly lower accuracy due to the similarity between synthesis methods, such as solvothermal synthesis and chemical synthesis, making class differentiation more challenging. For the extraction task, an impressive accuracy of 0.93 was maintained despite its complexity. Notably, tasks involving tables demonstrated an exceptional accuracy of 0.99, likely due to the more intuitive structure of tables compared to text. However, in some cases where footnotes or captions were included, leveraging large language models (LLMs) proved more efficient than traditional rule-based methods.
These results demonstrate notable improvements compared to previous studies. Supplementary Note S4 and Table S6-9 provide a detailed comparison between our work and previous research. Previous studies on text mining for extracting properties MOFs have typically focused on just one or two specific properties.[21, 23, 30] In contrast, our research is able to extract a wide range of properties, encompassing over 20 different properties, showcasing its broader scope. Despite handling a larger set of properties and processing data from a relatively high volume of papers, our research surpasses the accuracy levels reported in previous works. Additionally, our data mining tool demonstrates high accuracy in identifying synthesis conditions compared to previous works.[22, 25, 27, 31] In particular, unlike previous work that focused solely on extracting synthetic conditions, our approach is significant in that it connects these conditions to characteristic properties.
The improvement in accuracy is largely due to the integration and chaining of LLMs. LLMs are well-suited to handle the unstructured nature of natural language, enabling them to process varied formats across different papers. For instance, as shown in Supplementary Figure S1 and S2, LLMs effectively extract information that are difficult to address with traditional rule-based methods. This adaptability significantly contributed to the enhanced accuracy of the mining process. Furthermore, linking three LLM agents in a sequential chain boosted performance even further. Breaking the problem into smaller, manageable tasks and processing them in sequence enhanced the performance of the LLMs.[32-34] This approach also helped minimize token limits and avoided issues that arise when prompts become too lengthy. In our study, the text-mining workflow was divided into three distinct steps, with each step handled by a specialized LLM agent. This task-specific focus enabled each agent to work more efficiently, resulting in higher overall accuracy.
A direct comparison between single LLM and multi-LLM agent frameworks highlights the advantages of the multi-LLM approach. As shown in Supplementary Note S5, the performance of the multi-LLM agents significantly surpasses that of a single LLM agent in terms of both accuracy and cost. By employing task-specific LLM agents for categorization, inclusion, and extraction, the multi-LLM approach achieves higher accuracy while substantially reducing expenses. This clearly demonstrates the efficiency of the multi-LLM agent.
The use of chain LLM-based agents presents a significant advantage, as it not only maintains high accuracy but also allows for easy expansion to new targets and materials. Traditional rule-based methods require considerable time and effort to create new rules whenever a new target is introduced or a different material is analyzed. Similarly, in machine learning models based on sequence learning, substantial resources must be invested to construct datasets for training.[25, 35] In contrast, LLM-based approaches leverage inherent linguistic properties, enabling seamless application with minimal effort. By simply adjusting the prompt while maintaining the existing baseline code, targets and materials can be switched effortlessly. This reduces the entry barrier for data mining applications considerably. A practical example of applying this to other fields is presented in Supplementary Note S6.
Statistics

Figure 3. Distribution of mined properties of Metal-organic framework
Through the L2M3 system, we have collected information on synthesis conditions and various physical and chemical properties of the MOF material group. Figures 3 and 4 depict the distribution of these properties in graphical form, and statistics related to synthesis conditions can also be found in Supplementary Figure S3 and S4. Figure 3 shows the distribution of properties which we have clearly defined formats in JSON, revealing that information on chemical formula, lattice parameters, and density, which are necessary to estimate in the synthesis of MOF materials, are most frequently reported. We have also gathered a substantial amount of data on properties that are difficult or impossible to obtain through simulation, such as crystal size, decomposition temperature, and yield.

Figure 4. (a) Distribution of surface type (b) Distribution of mined pore volume probe (c) Scatter plot comparing mined surface area with calculated surface area. SA stands for surface area. Darker colors indicate higher point density. (d) Scatter plot comparing mined pore volume and calculated pore volume. PV stands for pore volume. (e) Box plot of mined surface area for 9 common MOFs. The yellow line represents the median and the red dots indicate the calculated surface area. (f) Box plot for the mined pore volume of 9 common MOFs.
Figure 4 provides a more detailed distribution of properties such as pore volume and surface area among various properties. More detailed distributions of other properties can be found in Supplementary Figure S5. As seen in Figure 4(a), the most widely used methodology for measuring the surface area of MOF materials is the BET method, and a comparison between the mined BET surface values and the calculated BET surface area values based on structure can be found in Figure 4(c). Similarly, as shown in Figure 4(b), N2 is most commonly used as a probe for measuring the pore volume of MOFs, and a comparison between the extracted values from documents using N2 as a probe and simulation calculated values can be found in Figure 4(d).
Examining Figures 4(c) and 4(d), it is clear that there is a discrepancy between the simulation and the experimental data. Simulations assume ideal conditions, whereas experiments are influenced by environmental factors such as temperature, pressure, and humidity, which are not fully considered in simulations. Furthermore, simulations often assume a perfectly ordered and defect-free structure, whereas real MOFs may exhibit surface roughness, defects, and irregularities. In addition, simulations often overlook the contribution of guest molecules. In addition to these factors, differences can arise from methodological differences in measurements and failure to account for intermolecular interactions in calculations.
These discrepancies are also highlighted in Figures 4(e) and 4(f), which show a significant variation between the mined pore volume and surface area of nine commonly synthesized MOFs and their corresponding computational simulation values. The figures compare simulated values, which provide a single, consistent measurement for each MOF structure, while the mined experimental values display a large range of measurements for each MOF. The simulation values tend to align with the median of the experimental values, suggesting a general consistency. However, the mined values exhibit considerable variance, reflecting the influence of different synthesis conditions and measurement environments. This variance underscores the complexity of reproducing identical properties in MOFs, even when the structures are theoretically the same.
This significant variation suggests the presence of outliers, which can be further analyzed for additional insights. Generally, surface area and pore volume are highly correlated in both mined and calculated data (Figure 5(a) and Figure 5(b)). However, some of the mined data significantly deviate from this correlation. Figure 5(b) presents a scatter plot of mined-data surface area and pore volume, categorizing the outlier data into six distinct types. The first type is MOF anomalies, which include MOFs that have different values from the known values for well-known MOFs or substances intended to form composites with MOFs rather than the MOFs themselves. The second type consists of MOFs or MOF composites that have undergone post-processing, most of which are located in the upper left of the graph. Third type includes cases where uncommon linkers or new synthesis methods yield performances that deviate from the usual trends. Fourth type involves MOFs obtained with measurements other than the total pore volume, such as micropore volume, other criteria, or values calculated through simulations. In fifth type, all the values come from the same MOF, which has exceptional pore volume and surface area. Last type represents errors in the mining process, such as incorrect pore diameter values or values extracted from descriptions of general MOFs rather than specific MOFs. Classifying these outliers helps us understand the reasons for discrepancies and guides future research. By identifying and categorizing these outliers, researchers can improve simulation accuracy and better predict the properties of newly synthesized MOFs.

Figure 5. (a) Scatter plot comparing simulated surface area and pore volume. (b) Analysis of MOFs deviating from established trends. All points represent text-mined surface area and pore volume. Outliers were categorized into six types and represented by circular dots.
Synthesis condition recommender
Understanding synthesis conditions is crucial to the development of new MOFs. Experimental scientists often rely on extensive trial and error to identify optimal synthesis conditions, which often serves as a bottleneck in the development of novel materials. Numerous studies have aimed to predict the feasibility of synthesis conditions to overcome this challenge.[25, 31] However, these approaches are often constrained by the limited availability of synthesis condition data and rely on predictive models with small datasets. Predictive models have inherent limitations in predicting synthesis conditions because these conditions are not defined by a single, precise value. Instead of determining an exact synthesis condition, recommending conditions with a high probability of success is a more practical solution. As a generative model, LLMs excel not in predicting exact values, but in generating novel data. This makes them particularly suitable for recommending synthesis conditions based on existing data sets. Efforts to use LLMs for this purpose are emerging in various fields, including inorganic and organic synthesis.[36-40]
Figure 6(a) illustrates the concept of a synthesis condition recommender. Users input the precursors involved in MOF synthesis and request recommended synthesis conditions, which the system generates accordingly. The implementation of this recommender is shown schematically in Figure 6(b). A dataset was constructed by pairing system prompts describing the role of the LLM with precursor lists as inputs and text-mined synthesis conditions as outputs. This dataset was used to fine-tune LLMs such as GPT-4o and GPT-3.5-turbo. Examples of text-mined synthesis conditions are shown in Supplementary Table S13. From a total of 60,735 extracted synthesis conditions, 9,044 were matched against the Cambridge Structural Database (CSD)[28] and included precursors that were used at least five times. These clean-up synthesis conditions were divided into training and test sets in a 3
Figure 6(c) compares the performance of the synthesis condition recommender across different LLMs and training methods. Recommendation scores, which measure the similarity between published synthesis conditions and predicted conditions, were used to evaluate performance. A score close to 1 indicates a high probability of synthesis success, while a score close to 0 indicates uncertainty. The detailed methodology for obtaining the recommendation score is described in Supplementary Note S9. Both fine-tuned models, GPT-4o and GPT-3.5-turbo, achieved high median recommendation scores of 0.83 and 0.83, respectively. Interestingly, the performance remained consistent across models, highlighting the greater influence of data quantity over model type. This suggests that as more synthesis condition data becomes available, model performance will further improve.
To benchmark the fine-tuned models, additional approaches using prompt engineering and rule-based methods were implemented for comparison. Prompt engineering was categorized into zero-shot (n=0) and few-shot (n=10 and 100) settings based on the amount of data provided in the prompts. The rule-based method involved generating conditions either randomly or based on statistical distributions. Both methods yielded lower recommendation scores than fine-tuning. The performance of prompt engineering, unlike fine-tuning, was more sensitive to the capabilities of the LLM, highlighting the importance of model quality when data is scarce. The recommendation score improved as the number of data points increased, with zero-shot results resembling random generation. However, at n=100, the recommendation score exceeded that of the statistical method. Considering that experimental scientists often rely on frequently used synthesis conditions, the LLM-based approach shows a significant advantage in generating efficient synthesis conditions.
Figure 6(d) presents the changes in recommendation performance based on the timeline of the training dataset. The x-axis represents the maximum year included in the training dataset, while recommendation scores were measured using test sets from two time periods: five years after the training dataset (red) and 2017-2022 (blue). The recommender effectively predicted synthesis conditions for the following five years with consistently high accuracy, demonstrating its ability to generalize beyond the training period. Interestingly, while the model's performance for the subsequent five years remained stable regardless of the timeline, its accuracy for recent data declined as the timeline of the training data moved further back in time. This decrease is attributed to the increasing diversity of precursors and the strong influence of previous years on new synthesis conditions. As a result, recent data have a higher similarity to current conditions, leading to improved accuracy. These results suggest that the recommendation system will significantly aid future predictions of MOF synthesis conditions, with performance expected to improve as more synthesis data become available.

Figure 6. (a) An example of the synthesis condition recommender. (b) Schematic overview of the synthesis condition recommender system. (c) Changes in recommendation scores based on the type of LLM and training methods used. The recommendation score represents the similarity to published synthesis conditions. The box plot shows the median and interquartile range. n refers to the amount of data used for fine-tuning and prompt engineering. (d) Variation of recommendation scores based on the maximum year of the dataset used for training. Tested on fine-tuned GPT-4o model. The red bars represent scores tested on data from the following five years, while the blue bars represent scores tested on data from 2017-2022.
ChatMOF integration
With the development of LLMs, there has been a significant increase in interest in their accuracy and applicability in various fields[41-49], including materials science. Researchers in this field are particularly interested in using chatbots to obtain accurate synthetic information and to answer unstructured questions. Yaghi et al.[27] proposed an innovative approach to addressing these challenges by introducing a chatbot designed to navigate and interpret synthetic datasets. Through their work, they envisioned transforming complex datasets into a dynamic, interactive dialogue system, making the data more accessible and understandable to users. This initiative led to the creation of the ChatGPT Chemistry Assistant, designed as a reliable and knowledgeable companion for exploring chemical reactions, with a particular focus on MOF synthesis.
Recent research has focused on extending the capabilities of LLMs by integrating them with a variety of tools[49, 50]. Innovations such as babyAGI64 and AutoGPT65 are at the forefront of these efforts, demonstrating the potential of LLMs when combined with external tools to perform tasks that were previously beyond their scope. A recent development in this area is ChatMOF[53], a chatbot tailored for the prediction of properties and inverse design of MOFs. ChatMOF offers a variety of services related to MOFs, such as database searching, property prediction using MOFTransformer[40, 54] with universal transfer learning, and the generation of materials with user-desired properties using genetic algorithms.
Figure 7 and Supplementary Figure S10 demonstrate the functionality of this chatbot by linking ChatMOF with an L2M3 database. Supplementary Figure S10 introduces two new tools: the Search Synthesis Condition tool, which finds synthesis details and related articles using user questions, and the Material Finder, which translates common MOF names (such as IRMOF-1 and MIL-102) to their CCDC database REFCODEs. Figure 7 explains how ChatMOF finds the synthesis details of MIL-120. It uses Material Finder to match MIL-120 to its REFCODE and then employs the Synthesis Condition tool to retrieve the synthesis information. This enables ChatMOF to provide the requested synthesis details. Additionally, Supplementary Figure S11 demonstrates how ChatMOF obtains the metadata for the MOF-649 synthesis article, indicating its compatibility with the L2M3 database.
The integration of ChatMOF into an autonomous artificial intelligence system represents a significant leap into the future of materials science research. While traditional LLMs have been limited to processing text-based data, the envisioned future expands their capabilities to provide accurate and quality-assured information in the field of materials science using a variety of specialized tools. This evolution marks a significant advance in the utility and applicability of LLMs in scientific research, particularly in the field of materials science.

Figure 7. ChatMOF combined with L2M3 database. Casestudy of MIL-120
Methods
Journal paper retrieval & crawling
Our research employed a comprehensive data mining approach to collect a significant corpus of journal papers relevant to Metal-Organic Frameworks (MOFs). We targeted publications from four major scientific publishers: the American Chemical Society (ACS), Elsevier, the Royal Society of Chemistry (RSC), and Springer. We amassed a total of 41,681 unique papers, contributing to a rich dataset for our analysis. The papers were distributed among the publishers as follows: ACS contributed 16,481 papers, Elsevier 18,778, RSC 4,775, and Springer 1,647. Additional statistics on journal crawling can be found in the Supplementary Figure S12.
To maintain the integrity of our research process and respect copyright laws, we downloaded the journal papers in XML or HTML formats, adhering to ethical guidelines and obtaining explicit approval from each publisher to ensure compliance with their data usage policies.
A substantial portion of our dataset, which includes 23,091 papers, is directly linked to structures identified as part of the MOF substance family within the Cambridge Structural Database (CSD)[28], providing a robust foundation for our research. Additionally, we utilized specialized crawling code to automatically identify and retrieve 18,590 articles from Elsevier's Scopus database, leveraging the Elsevier Scopus API for efficient filtering. This process targeted articles based on their relevance to MOF substances, discerned through related terms in their titles, abstracts, and keywords, thereby ensuring a comprehensive and relevant collection of studies for our MOF research dataset.
Integration with the CSD database
To improve the depth and usefulness of our dataset, we integrated our collection of journal papers with the Cambridge Structural Database (CSD)[28], a well-known repository for crystallographic data. This integration was made possible by using Digital Object Identifiers (DOIs) associated with our crawled papers. By querying the CSD database with these DOIs, we determined the presence and relevance of each paper within the CSD. This ensures a seamless linkage between our dataset and the valuable crystallographic information housed in the CSD.
The CSD database contains detailed crystallography data, providing access to structure files (e.g., CIF files), refcodes, lattice information, and more. These elements are essential for our research as they provide insights into the molecular and crystalline structures of MOF substances and serve as valuable metadata for our dataset. The integration process utilized the csd-python-api version 3.0.1468, which is compatible with the 2022 version of the CSD software. This API facilitated automated queries and retrievals from the CSD, streamlining the process of enriching our dataset with high-quality, relevant crystallographic data.
##Structure refinement and Zeo++ calculation
To prepare the structures sourced from the CSD database for analysis, we standardized their representation by adopting P1 symmetry for all structures to ensure consistency across the dataset. We removed floating solvents from the structures during the refinement process to eliminate potential interference. However, we retained binding ligands that are crucial for the structural and functional integrity of the Metal-Organic Frameworks (MOFs).
In addition, structures obtained from the CSD database may present challenges such as disorders or atom duplications, which can complicate analysis. To ensure the quality of our dataset, we excluded structures with atoms located too closely together, specifically those with interatomic distances less than 1 Angstrom. This selection criterion helps to avoid inaccuracies in the dataset due to overlapping or unrealistic atomic arrangements. After the refinement stage, properties such as the density, pore volume and surface area of the structures were calculated using zeo++ software69 with 1.82 probe radius. This tool is widely recognized for its capability in analyzing the geometric properties of nano-porous materials.
##Prompt engineering and fine-tuning
The data extraction process began by analyzing individual paragraphs within each journal paper. To prepare the text for processing, we utilized the Python libraries beautifulsoup4[57] and chemdataextractor[58]. These tools were effective in separating the papers into distinct paragraphs and eliminating any unnecessary HTML and XML formatting, resulting in a clean dataset for further analysis.
To orchestrate interactions between different LLMs, we used the Langchain Python library[59], specifically version 0.0.268. This setup allowed for a fully automated data extraction workflow, which was divided into three critical stages: categorization, property inclusion, and extraction. The Langchain library was instrumental in chaining these LLMs and automating the entire process. The automation was further streamlined by additional refinements, such as monitoring token length with the tiktoken Python library[60] and ensuring output consistency in TypeScript format.
For the categorization and property inclusion stages, we employed LLMs fine-tuned on OpenAI's GPT-3.5-turbo model, tailored with 723 and 681 example sets, respectively. This fine-tuning was crucial for achieving high accuracy in classifying and identifying relevant data, with examples developed through GPT-474 prompt engineering and refined with human review. When comparing the performance of GPT models with open-source alternatives like Llama, the latter exhibited lower accuracy, as detailed in Supplementary Note S10. Consequently, GPT was chosen for its superior performance to handle the complexity of our data mining tasks. As shown in Supplementary Note S11, the F1 score of data mining increases as the number of fine-tune datasets increases. Based on this observation, the size of the fine-tuning dataset was selected to balance performance and efficiency, ensuring optimal accuracy without unnecessary computational overhead. Supplementary Table S14 presents the accuracy achieved for categorization and inclusion tasks when using prompt engineering. Fine-tuning consistently outperformed prompt engineering in both tasks. As illustrated in Supplementary Figure S13, fine-tuning also reduced computational costs by approximately 95%. These findings highlight the efficiency of fine-tuning in terms of both performance and cost-effectiveness. Figure 8(a) illustrates the categorization process, employing finely tuned, concise prompts and examples for precise text category identification. Figure 8(b) depicts the inclusion step by the synthesis agent, adopting a similar approach to categorization but with explicit rules and human-provided examples to assure task accuracy, especially in distinguishing various synthesis conditions.
The final extraction step shifted to prompt engineering with GPT-4, chosen for its adaptability in processing novel information, with occasional support from GPT-3.5-turbo-0125 for tasks exceeding GPT-4's 8000-token limit. The introduction of the GPT-4-32K API was not incorporated due to the project's advanced stage and budget considerations. Figure 8(c) explores the extraction methodology for the synthesis condition agent, employing a detailed prompt strategy that includes a comprehensive rule set and specifies the data format, notably using JSON for consistency.
In Supplementary Figure S14, the estimated cost for data-mining around 40,000 papers is presented. The most significant expense is associated with the text categorization phase, primarily due to the large volume of paragraphs processed. Additionally, the extraction process employs a non-fine-tuned version of GPT-4, and include long prompts with a few example using JSON format, leading to high estimated costs for both aspects.

Figure 8. (a) An example prompt for categorization task (b) An example prompt for inclusion task (c) An example prompt for extraction prompt
Conclusion
In this study, we demonstrated a comprehensive data mining approach to extract valuable information on MOFs from a substantial dataset of approximately 40,000 scientific papers using LLM. This methodology allowed for the efficient extraction of key properties and synthesis conditions of MOFs, which are crucial for further research and development in this field.
Our evaluation of the accuracy of the data mining process revealed a high degree of reliability, affirming the potential of LLMs as powerful tools in the extraction of scientific data from vast corpora. Notably, in the categorization task, our research achieved F1 scores higher than 0.95 across all three categories, outperforming previous studies in terms of accuracy. Similarly, the inclusion task consistently achieved F1 scores of 0.95 or higher in every instance, with the extraction task maintaining an F1 score of 0.93 or higher. These results underscore the precision and robustness of our methodology.
The subsequent statistical analysis provided insights into the distribution of various properties and synthesis conditions, while also identifying and addressing discrepancies between the experimental data and simulation data. By identifying these discrepancies, a more nuanced analysis was possible, highlighting the importance of accurate experimental data in predictive modeling. Furthermore, when both experimental and simulation data were incorporated into machine learning models, it was observed that these discrepancies significantly impacted the machine learning outcomes. Specifically, predictions of experimental data were far more precise when the models were trained using actual experimental data rather than relying solely on simulation data. This finding underscores the critical role that high-quality experimental data plays in improving the accuracy of predictive models in material science.
In addition, we conducted a detailed machine learning study to predict density values. The models trained with experimental data achieved an average R² value of 0.84, whereas the models trained with simulation data yielded an average R² value of 0.43. This highlighted the discrepancies between experimental and simulation data, and we analyzed the causes behind these differences. Through SHAP analysis, synthesis condition evaluation, and structure analysis, we identified residual species as the cause of these density value discrepancies. This analysis revealed the underlying structural and compositional factors influencing MOF density.
In addition to this, we also leveraged the extracted synthesis condition data to develop a synthesis condition recommender system. This system utilizes precursor information to suggest optimal synthesis conditions. The fine-tuned models using GPT-4 and GPT-3.5 each achieved a high recommendation score of 0.83, offering a practical and automated tool for researchers to refine synthesis strategies and enhance experimental reproducibility.
Our approach not only highlights the effectiveness of data mining with LLMs in the field of MOFs but also demonstrates the value of integrating statistical and predictive modeling techniques. This work sets the stage for more extensive and refined studies in material science, particularly in the efficient exploration and utilization of large-scale scientific datasets, while paving the way for practical applications in predictive modeling and synthesis optimization.
Reference
1 Chung, Y. G., et al. Computation-ready, experimental metal–organic frameworks: A tool to enable high-throughput screening of nanoporous crystals. Chemistry of Materials 2014, 26 (21), 6185-6192
2 Chung, Y. G., et al. Advances, updates, and analytics for the computation-ready, experimental metal–organic framework database: CoRE MOF 2019. Journal of Chemical & Engineering Data 2019, 64 (12), 5985-5998
3 Rosen, A. S., et al. Machine learning the quantum-chemical properties of metal–organic frameworks for accelerated materials discovery. Matter 2021, 4 (5), 1578-1597
4 Online Materials Information Resource - MatWeb, https://www.matweb.com/ (accessed October 28, 2024).
5 Jain, A., et al. Commentary: The Materials Project: A materials genome approach to accelerating materials innovation. APL materials 2013, 1 (1), 011002
6 Otsuka, S.; Kuwajima, I.; Hosoya, J.; Xu, Y.; Yamazaki, M. PoLyInfo: Polymer database for polymeric materials design. in 2011 International Conference on Emerging Intelligent Data and Web Technologies. (2011)
7 Lim, Y.; Kim, J. Application of transfer learning to predict diffusion properties in metal–organic frameworks. Molecular Systems Design & Engineering 2022, 7 (9), 1056-1064
8 Torrey, L.; Shavlik, J. in Handbook of research on machine learning applications and trends: algorithms, methods, and techniques 242-264 (IGI global, 2010).
9 Felix Sahayaraj, A., et al. Metal–organic frameworks (MOFs): the next generation of materials for catalysis, gas storage, and separation. Journal of Inorganic and Organometallic Polymers and Materials 2023, 33 (7), 1757-1781
10 Li, Y.; Wang, Y.; Fan, W.; Sun, D. Flexible metal–organic frameworks for gas storage and separation. Dalton Transactions 2022, 51 (12), 4608-4618
11 Mason, J. A.; Veenstra, M.; Long, J. R. Evaluating metal–organic frameworks for natural gas storage. Chemical Science 2014, 5 (1), 32-51
12 Ma, S.; Zhou, H.-C. Gas storage in porous metal–organic frameworks for clean energy applications. Chem Commun 2010, 46 (1), 44-53
13 Park, J.; Lim, Y.; Lee, S.; Kim, J. Computational design of metal–organic frameworks with unprecedented high hydrogen working capacity and high synthesizability. Chemistry of Materials 2022, 35 (1), 9-16
14 Lim, Y.; Park, J.; Lee, S.; Kim, J. Finely tuned inverse design of metal–organic frameworks with user-desired Xe/Kr selectivity. Journal of Materials Chemistry A 2021, 9 (37), 21175-21183
15 Li, J.-R.; Kuppler, R. J.; Zhou, H.-C. Selective gas adsorption and separation in metal–organic frameworks. Chemical Society Reviews 2009, 38 (5), 1477-1504
16 Li, J.-R.; Sculley, J.; Zhou, H.-C. Metal–organic frameworks for separations. Chemical reviews 2012, 112 (2), 869-932
17 Lee, J., et al. Metal–organic framework materials as catalysts. Chemical Society Reviews 2009, 38 (5), 1450-1459
18 Cho, S., et al. Interface-sensitized chemiresistor: Integrated conductive and porous metal-organic frameworks. Chemical Engineering Journal 2022, 449, 137780
19 Della Rocca, J.; Liu, D.; Lin, W. Nanoscale metal–organic frameworks for biomedical imaging and drug delivery. Accounts of chemical research 2011, 44 (10), 957-968
20 Horcajada, P., et al. Porous metal–organic-framework nanoscale carriers as a potential platform for drug delivery and imaging. Nature materials 2010, 9 (2), 172-178
21 Park, S., et al. Text mining metal–organic framework papers. Journal of chemical information and modeling 2018, 58 (2), 244-251
22 Glasby, L. T., et al. DigiMOF: a database of metal–organic framework synthesis information generated via text mining. Chemistry of Materials 2023, 35 (11), 4510-4524
23 Nandy, A.; Duan, C.; Kulik, H. J. Using machine learning and data mining to leverage community knowledge for the engineering of stable metal–organic frameworks. Journal of the American Chemical Society 2021, 143 (42), 17535-17547
24 Nandy, A., et al. MOFSimplify, machine learning models with extracted stability data of three thousand metal–organic frameworks. Scientific Data 2022, 9 (1), 74
25 Park, H.; Kang, Y.; Choe, W.; Kim, J. Mining insights on metal–organic framework synthesis from scientific literature texts. Journal of Chemical Information and Modeling 2022, 62 (5), 1190-1198
26 Manning, J. R.; Sarkisov, L. Unveiling the synthesis patterns of nanomaterials: a text mining and meta-analysis approach with ZIF-8 as a case study. Digital Discovery 2023, 2 (6), 1783-1796
27 Zheng, Z.; Zhang, O.; Borgs, C.; Chayes, J. T.; Yaghi, O. M. ChatGPT chemistry assistant for text mining and the prediction of MOF synthesis. Journal of the American Chemical Society 2023, 145 (32), 18048-18062
28 Moghadam, P. Z., et al. Development of a Cambridge Structural Database subset: a collection of metal–organic frameworks for past, present, and future. Chemistry of Materials 2017, 29 (7), 2618-2625
29 Burnham, J. F. Scopus database: a review. Biomedical digital libraries 2006, 3, 1-8
30 Tayfuroglu, O.; Kocak, A.; Zorlu, Y. In silico investigation into h2 uptake in mofs: combined text/data mining and structural calculations. Langmuir 2019, 36 (1), 119-129
31 Luo, Y., et al. MOF synthesis prediction enabled by automatic data mining and machine learning. Angewandte Chemie International Edition 2022, 61 (19), e202200242
32 Wei, J., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 2022, 35, 24824-24837
33 Yao, S., et al. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv
34 Sun, S.; Liu, Y.; Wang, S.; Zhu, C.; Iyyer, M. Pearl: Prompting large language models to plan and execute actions over long documents. arXiv preprint arXiv.14564 2023
35 Kononova, O., et al. (2019).
36 Song, Z.; Lu, S.; Ju, M.; Zhou, Q.; Wang, J. Is Large Language Model All You Need to Predict the Synthesizability and Precursors of Crystal Structures? arXiv preprint arXiv.07016 2024
37 Kim, S.; Schrier, J.; Jung, Y. Explainable Synthesizability Prediction of Inorganic Crystal Structures using Large Language Models. 2024
38 Kim, S.; Jung, Y.; Schrier, J. Large language models for inorganic synthesis predictions. Journal of the American Chemical Society 2024, 146 (29), 19654-19659
39 M. Bran, A., et al. Augmenting large language models with chemistry tools. Nature Machine Intelligence 2024, 1-11
40 Ruan, Y., et al. An automatic end-to-end chemical synthesis development platform powered by large language models. Nature communications 2024, 15 (1), 10160
41 Dunn, A., et al. Structured information extraction from complex scientific text with fine-tuned large language models. arXiv preprint arXiv.05238 2022
42 Jablonka, K. M., et al. 14 examples of how LLMs can transform materials science and chemistry: a reflection on a large language model hackathon. Digital Discovery 2023, 2 (5), 1233-1250
43 Guo, T., et al. What can large language models do in chemistry? a comprehensive benchmark on eight tasks. Advances in Neural Information Processing Systems 2023, 36, 59662-59688
44 White, A. D., et al. Assessment of chemistry knowledge in large language models that generate code. Digital Discovery 2023, 2 (2), 368-376
45 Lee, P.; Bubeck, S.; Petro, J. Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine. New England Journal of Medicine 2023, 388 (13), 1233-1239
46 Waisberg, E., et al. GPT-4: a new era of artificial intelligence in medicine. Irish Journal of Medical Science (1971-) 2023, 192 (6), 3197-3200
47 Nori, H.; King, N.; McKinney, S. M.; Carignan, D.; Horvitz, E. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv.13375 2023
48 Wang, Y.; Zhao, Y.; Petzold, L. Are large language models ready for healthcare? a comparative study on clinical language understanding. in Machine Learning for Healthcare Conference. (2023)
49 Bran, A. M.; Cox, S.; White, A. D.; Schwaller, P. Chemcrow: Augmenting large-language models with chemistry tools. arXiv preprint arXiv.05376 2023
50 Shen, Y., et al. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems 2024, 36
51 yoheinakajima. babyagi, https://github.com/yoheinakajima/babyagi (accessed October 28, 2024).
52 Significant-Gravitas. AutoGPT, https://github.com/Significant-Gravitas/AutoGPT (accessed October 28, 2024).
53 Kang, Y.; Kim, J. Chatmof: An autonomous ai system for predicting and generating metal-organic frameworks. arXiv preprint arXiv.01423 2023
54 Park, H.; Kang, Y.; Kim, J. Enhancing Structure–Property Relationships in Porous Materials through Transfer Learning and Cross-Material Few-Shot Learning. ACS Applied Materials & Interfaces 2023, 15 (48), 56375-56385
55 ccdc-opensource. csd-python-api-scripts, https://github.com/ccdc-opensource/csd-python-api-scripts (accessed October 28, 2024).
56 Willems, T. F.; Rycroft, C. H.; Kazi, M.; Meza, J. C.; Haranczyk, M. Algorithms and tools for high-throughput geometry-based analysis of crystalline porous materials. Microporous and Mesoporous Materials 2012, 149 (1), 134-141
57 wention. BeautifulSoup4, https://github.com/wention/BeautifulSoup4 (accessed October 28, 2024).
58 Swain, M. C.; Cole, J. M. ChemDataExtractor: a toolkit for automated extraction of chemical information from the scientific literature. Journal of chemical information and modeling 2016, 56 (10), 1894-1904
59 langchain-ai. langchain, https://github.com/langchain-ai/langchain (accessed October 28, 2024).
60 openai. tiktoken, https://github.com/openai/tiktoken (accessed October 28, 2024).
61 Achiam, J., et al. Gpt-4 technical report. arXiv preprint arXiv.08774 2023