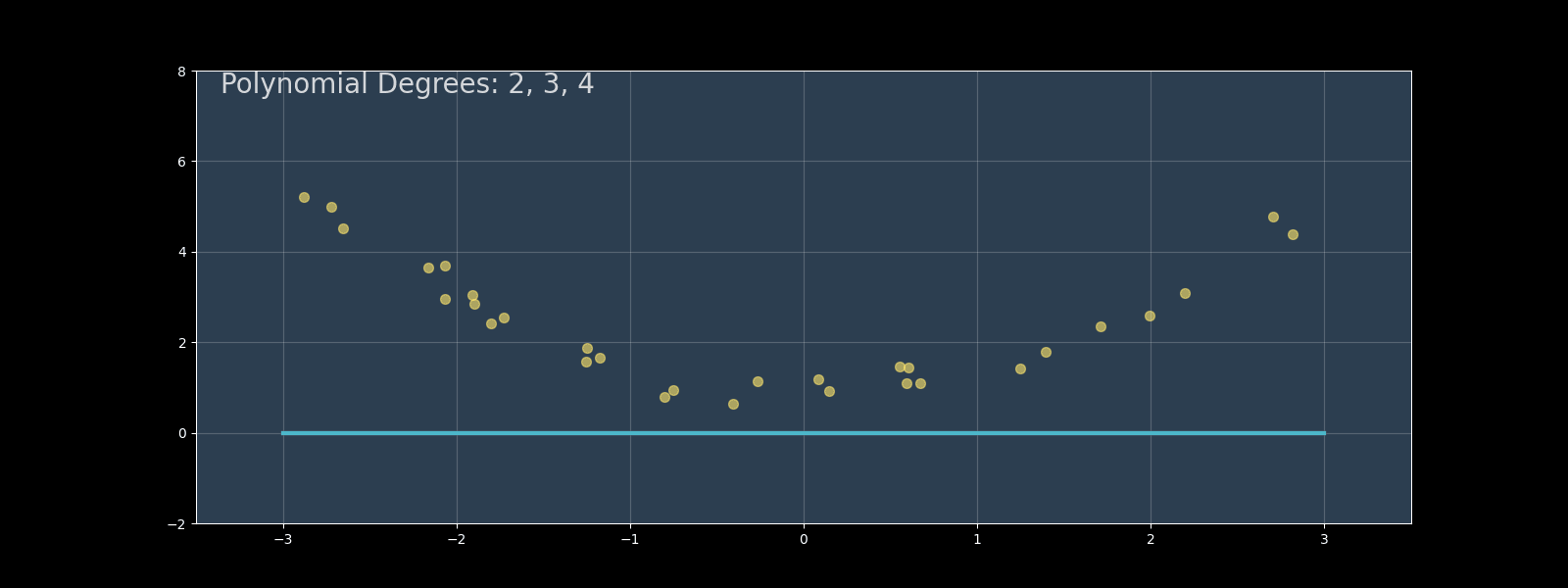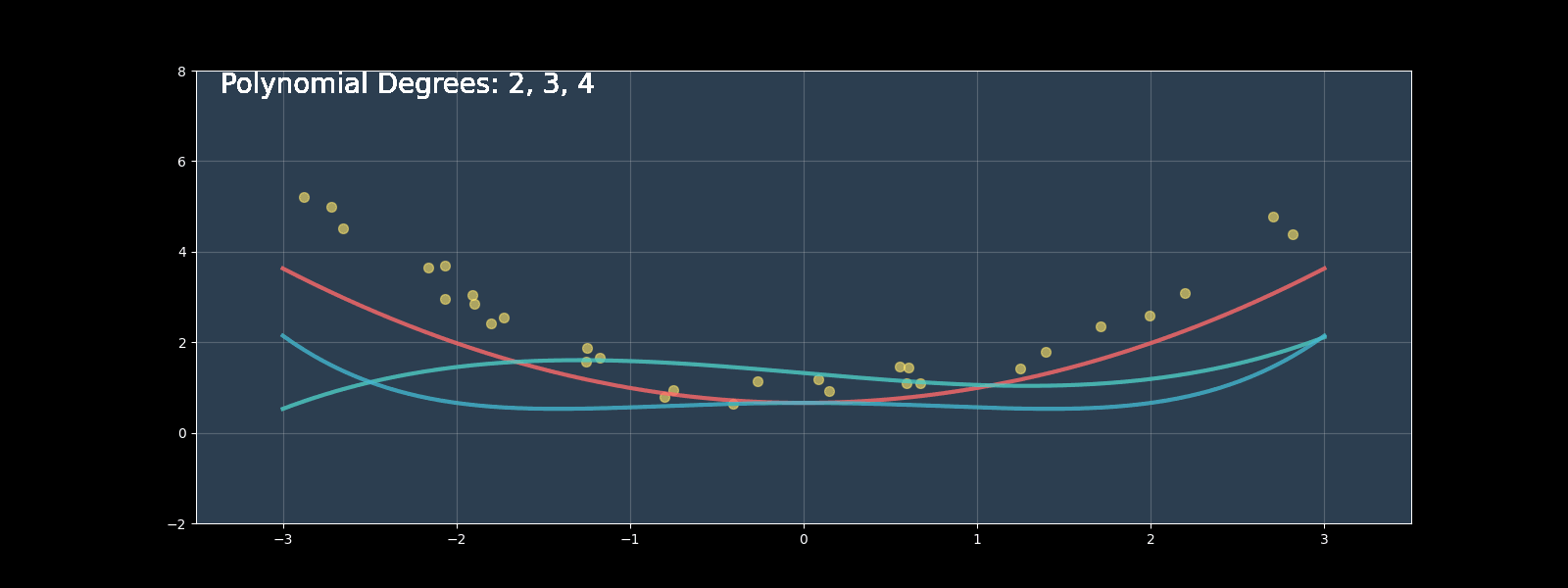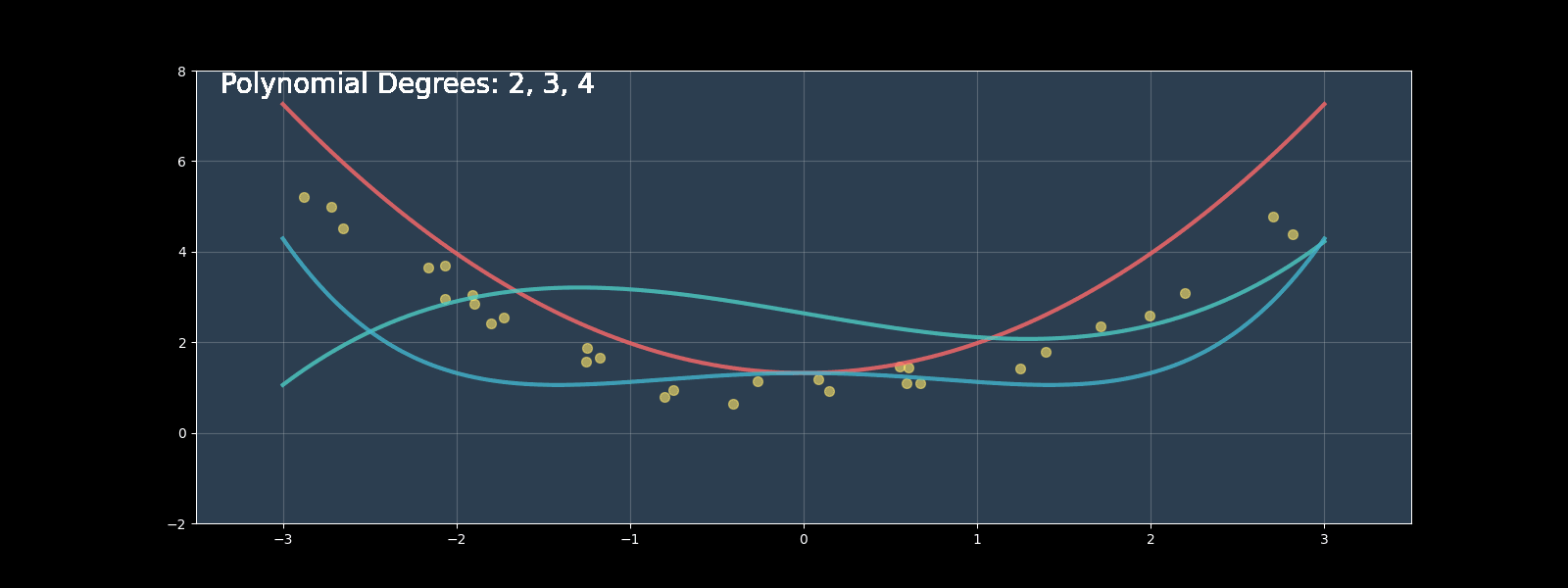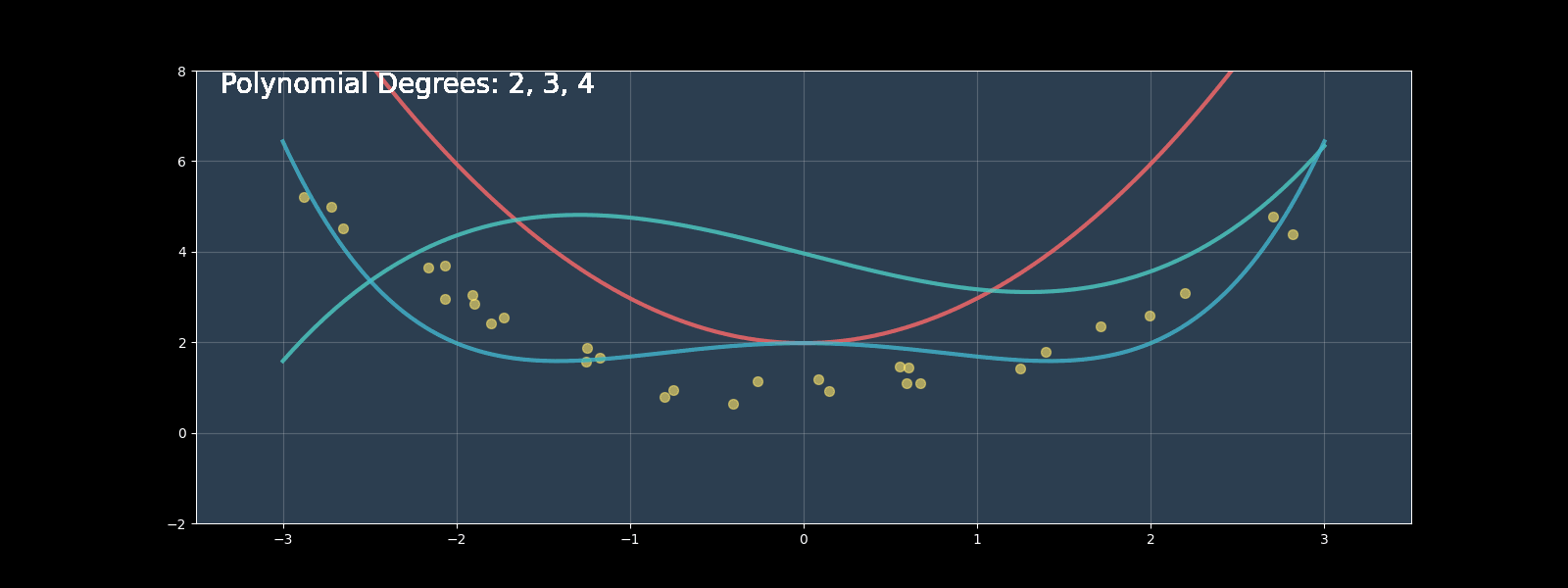
Polynomial regression extends linear regression by modeling nonlinear relationships using polynomial terms. In this comprehensive guide, we'll implement polynomial regression from scratch, compare it with scikit-learn's implementation, and explore optimization techniques.
Basic linear regression is expressed as:
where:
Polynomial regression extends this to:
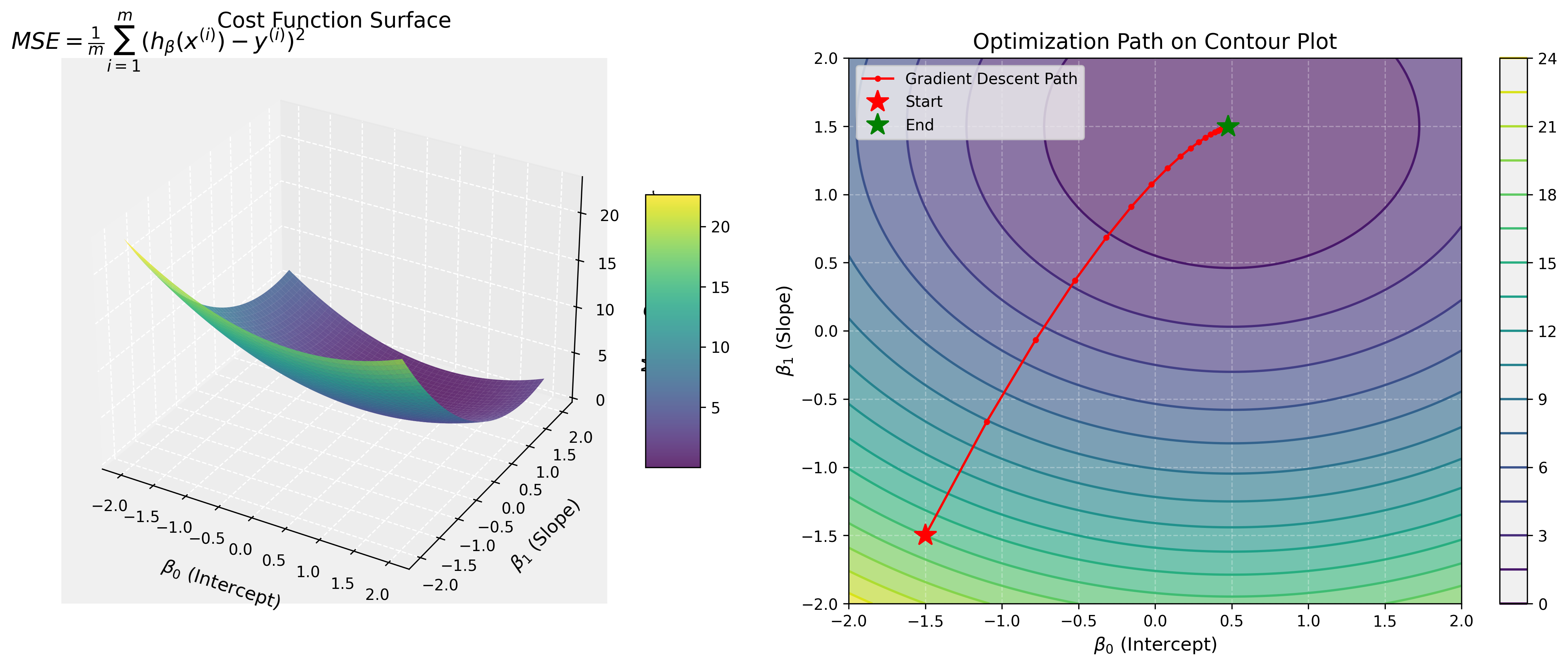
The Mean Squared Error (MSE) cost function:
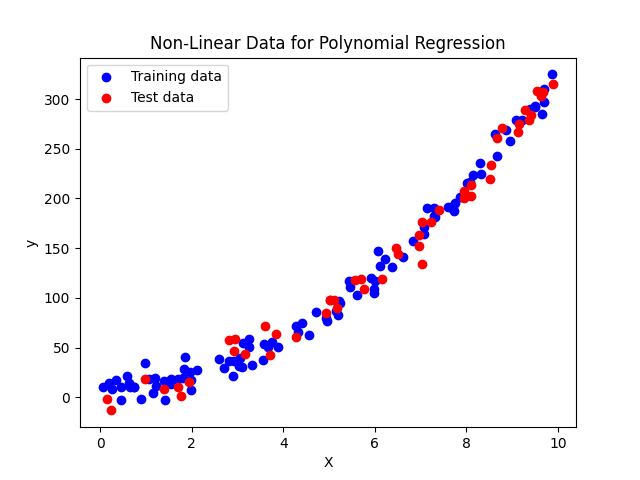
First, let's create synthetic nonlinear data:
import numpy as np import matplotlib.pyplot as plt # Create non-linear data (quadratic) np.random.seed(42) X_train = np.random.rand(100, 1) * 10 y_train = 3 * X_train**2 + 2 * X_train + 5 + np.random.randn(100, 1) * 10 X_test = np.random.rand(50, 1) * 10 y_test = 3 * X_test**2 + 2 * X_test + 5 + np.random.randn(50, 1) * 10
Our enhanced CustomPolynomialEstimator class:
class CustomPolynomialEstimator: def __init__(self, degree=2, include_bias=True, include_interactions=True, feature_selection_threshold=0.01, use_scaling=True): self.degree = degree self.include_bias = include_bias self.include_interactions = include_interactions self.feature_selection_threshold = feature_selection_threshold self.use_scaling = use_scaling self.scaler = StandardScaler() if use_scaling else None
Key Features:
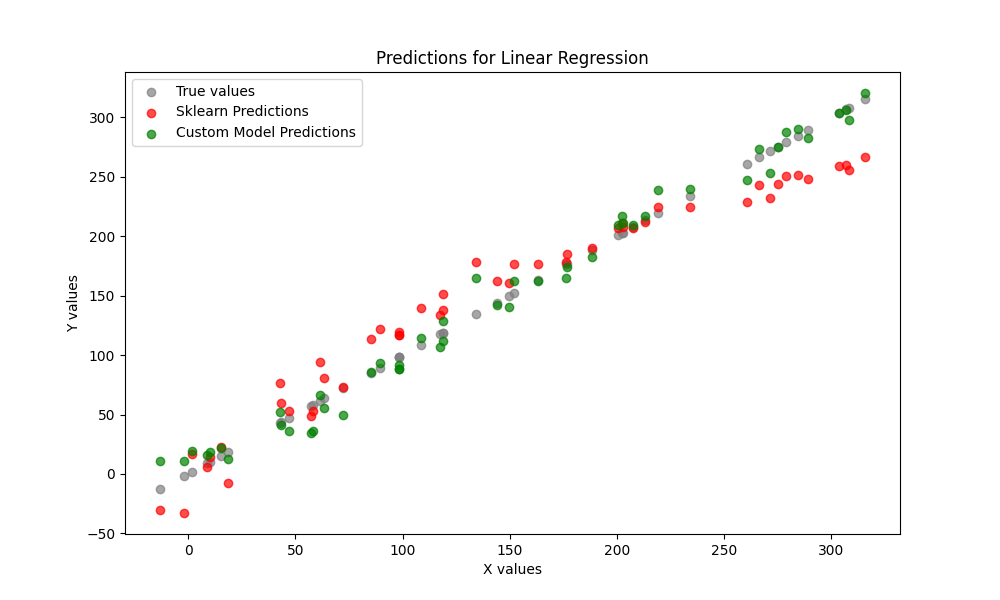
from sklearn.pipeline import make_pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression model_sklearn = make_pipeline( PolynomialFeatures(degree=2), LinearRegression() )
import numpy as np from itertools import combinations, combinations_with_replacement from sklearn.preprocessing import StandardScaler from sklearn.base import BaseEstimator, RegressorMixin class CustomPolynomialEstimator: def __init__(self, degree=2, include_bias=True, include_interactions=True, feature_selection_threshold=0.01, use_scaling=True): self.degree = degree self.include_bias = include_bias self.include_interactions = include_interactions self.feature_selection_threshold = feature_selection_threshold self.use_scaling = use_scaling self.scaler = StandardScaler() if use_scaling else None self.feature_importances_ = None model_custom = make_pipeline(CustomPolynomialEstimator(degree=2, include_interactions=True), LinearRegression()) model_custom.fit(X_train, y_train) pred_custom = model_custom.predict(X_test)

The gradient descent update rule:
where α is the learning rate.
from sklearn.linear_model import SGDRegressor sgd_model = make_pipeline( PolynomialFeatures(degree=2), SGDRegressor(max_iter=1000, tol=1e-3) )
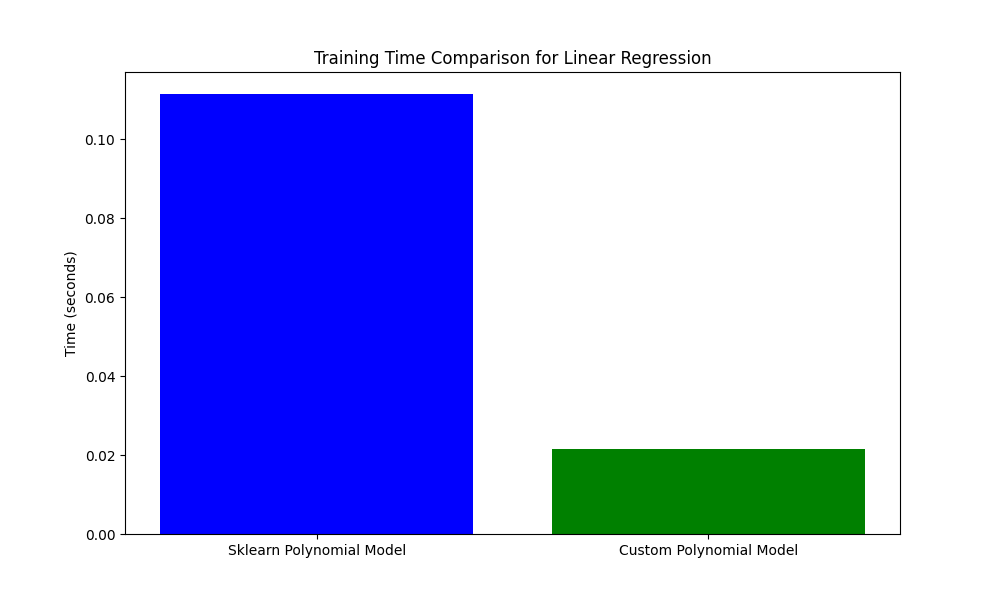
custom_sgd = make_pipeline(CustomPolynomialEstimator(degree=2, include_interactions=True), SGDRegressor()) # Measure training time start_time = time.time() custom_sgd.fit(X_train, y_train) pred_custom_sgd = custom_sgd.predict(X_test) # Calculate R^2 score score_custom_sgd_train = custom_sgd.score(X_test, y_test) print(f"Custom SGD Model Training R^2 Score: {score_custom_sgd_train:.4f}") end_time = time.time() time_custom_sgd = end_time - start_time print(f"Time taken for training and prediction: {time_custom_sgd:.4f} seconds")



| Model | R² Score | Training Time (s) |
|---|---|---|
| LR - Build-In VS Build-In | 0.9298 | 0.010 |
| LR - Build-In VS Custom | 0.9922 | 0.012 |
| SGD - Build-In VS Build-In | 0.9214 | 0.010 |
| SGD - Build-In VS Custom | 0.9864 | 0.011 |
Complete implementation: GitHub Repository Link