Abstract
Biometry is the science of collecting and analyzing biologic or health data using statistical methods. Due to biologic data being very individual, it can be used in security purposes, for authentication, authorization and such. As technology advances, there are multiple ways of deciding whether some biologic data comes from the same person or not. One of these ways is using a neural network, or AI in general. The main point of this work was to implement a neural network which can take 2 images of a fingerprint, and decide whether it is the same finger or not.
Methodology
Picking a database
There are multiple databases which are publicly available and can be used for this purpose. Some of them have 1 print per finger, some of them have 2 prints per finger, and many have multiple prints per finger. My dataset is one of the latter. The advantage of this dataset is that I can make many pairs of the same finger, which is a must for the training of the neural network.
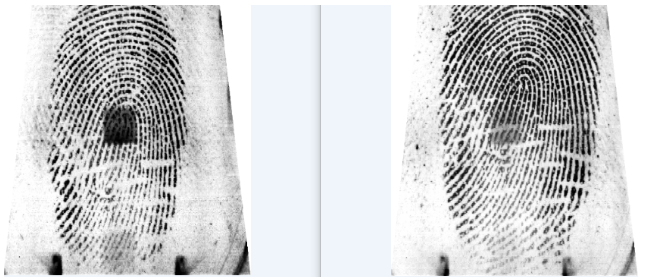
This is an example of a pair of prints from the same finger. The images look dissimilar because of multiple variables. Some of them are the cleanliness and damage of the finger when taking a print, the temperature of the person whose print is being taken, the pressure the person places on the fingerprint scanner and so on. The main point of the neural network is to take these variables into account when making a decision.
Preprocessing
Even though neural networks can work on raw images, the results are better if we can "help" it by doing some image preprocessing.
The first step is putting all the images into grayscale. Even though the pictures are already black and white, the files themselves were in color, which would hinder further processing. Because of this, the results are identical
On the following Github repository there are generic algorithms which were used for further preprocessing and feature extraction.
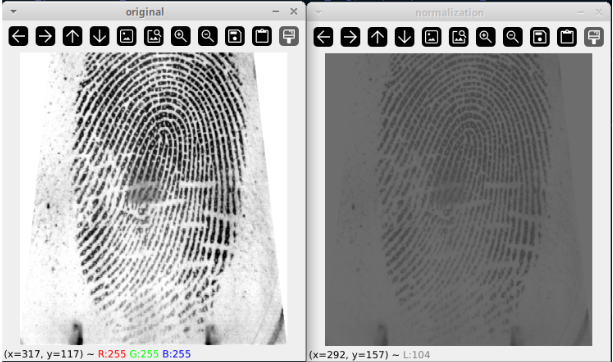
Normalization
The next step was normalizing the images. Because there can be differences in scanners used, the pressure amount and inequality in the finger placement, we need to normalize the images. The results of normalization looks like the following:
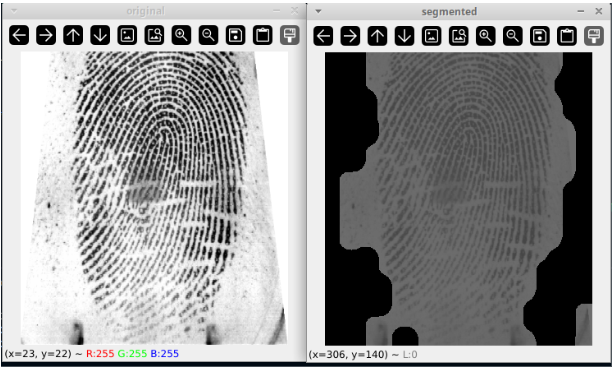
Segmentation
After normalizing the images, we need to try and remove the background as much as possible, while keeping the fingerprint. This works by calculating the variance of the gray level in the image. Of course, I am aware that the results can be even better in this step:
Ridge evaluation
To make the network's life easier, we can extract some features in the image. In this case, the main feature being analyzed is the finger ridge, which is unique per finger for every person. I took and used an algorithm which can evaluate the frequency and direction of the ridges. The results look like the following:
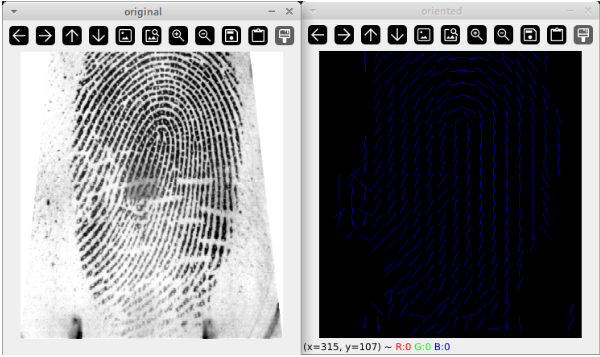
Enchancing the image
The last part of image preprocessing is enhancing it as much as possible. For this I used a gabor filter which boosts the contract between the ridges. Also, to make the ridges more uniform, each ridge is now 1 pixel wide.

Each image in the dataset was processed in this way.
Picking a neural network
After processing all the images, I deliberated on which neural network to use. In the end I stumbled upon Siamese neural networks, which can take 2 inputs, which was perfect in this case due to me needing to take 2 images. Another good side of siamese neural networks is that they don't care about classification, but only deciding if 2 images are the same or not. Of course, for implementing the network I used Python and Keras.
For creating the pairs of inputs I had to create an algorithm which would pair the images from the dataset. The first step was creating a dictionary where the key was a particular finger, so in the end we have a dictionary of 65 keys. Each finger has 8 prints, which would mean we can make 64 pairs of the same finger per finger. When we take the 64 pairs of 65 fingers, we have a total of 4160 pairs of the same finger. After this I created the same amount of pairs of different fingers. For creating both I used the Cartesian product. For the same finger, we have a cartesian product in the same key of the dictionary, while for the different fingers we take random 2 groups.
For the neural network itself we have a contrastive loss function, because it needs 2 pairs of inputs, which was done in the last step. We also use a Euclidean distance to calculate the difference between the images.
After testing, the best results were with this particular neural network structure:
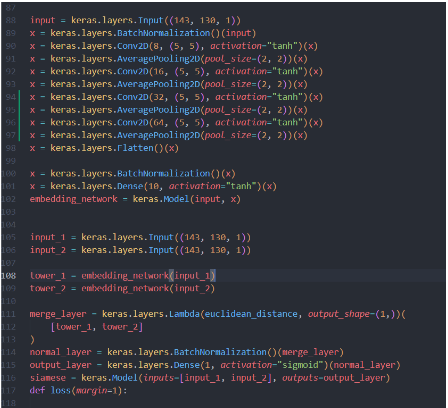
To properly train the network, each pair of fingers got a label, 1.0 for different fingers and 0.0 for the same fingers. After this we shuffled all the pairs so that the neural network wasn't trained on let's say all different pairs.
Results
This is the results of our training:
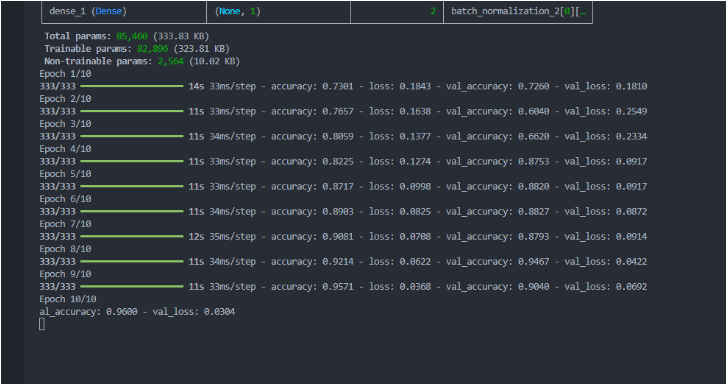
Given the epoch results, we conclude that the final accuracy of the model is 96%, which is a lot. When having a smaller amount of layers, the results were a lot worse, or around 76%