The rapid development of artificial intelligence in image processing has opened new avenues for automation and efficiency in content generation. This project implements a web-based application that utilizes the BLIP (Bootstrapping Language-Image Pre-training) model for automatic image captioning. Leveraging the Salesforce pre-trained BLIP model and its accompanying processor, the application converts images uploaded by users into descriptive text captions. The interface, built using Gradio, facilitates an interactive experience where users can input images and receive instant captions. The results demonstrate the effectiveness and accuracy of BLIP in generating meaningful descriptions while emphasizing its applicability in various fields such as accessibility, content creation, and database management.
Environment Setup: The application is developed using Python and includes libraries such as Gradio for the user interface, NumPy for image manipulation, and the Transformers library for model processing.
import gradio as gr import numpy as np from PIL import Image from transformers import AutoProcessor, BlipForConditionalGeneration
Model Selection: The BLIP model, specifically "Salesforce/blip-image-captioning-base," was selected for this project due to its advanced capabilities in image caption generation. The model's architecture incorporates both visual and textual inputs to produce coherent captions.
# Load the pretrained processor and model processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-base") model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
Image Processing: Users upload images in various formats through the Gradio interface. The input is converted into a NumPy array before being transformed into a PIL (Python Imaging Library) image. This step ensures compatibility with the processing requirements of the BLIP model.
Caption Generation: The processed image is passed to the model's pipeline, which tokenizes the input and generates a sequence of text tokens that describe the image. The maximum length of the generated caption is set to 50 tokens. The output tokens are then decoded into human-readable text.
def caption_image(input_image: np.ndarray): # Convert numpy array to PIL Image and convert to RGB raw_image = Image.fromarray(input_image).convert('RGB') # Process the image inputs = processor(raw_image, return_tensors="pt") # Generate a caption for the image out = model.generate(**inputs,max_length=50) # Decode the generated tokens to text caption = processor.decode(out[0], skip_special_tokens=True) return caption
User Interface: The Gradio interface is configured to accept image uploads and display the generated captions in real-time. The interface includes a title and a short description to guide users.
iface = gr.Interface( fn=caption_image, inputs=gr.Image(), outputs="text", title="Image Captioning", description="This is a simple web app for generating captions for images using a trained model." ) iface.launch()
The application was tested with various images to assess the model's performance in terms of accuracy and coherence of the generated captions. The following points summarize the results:
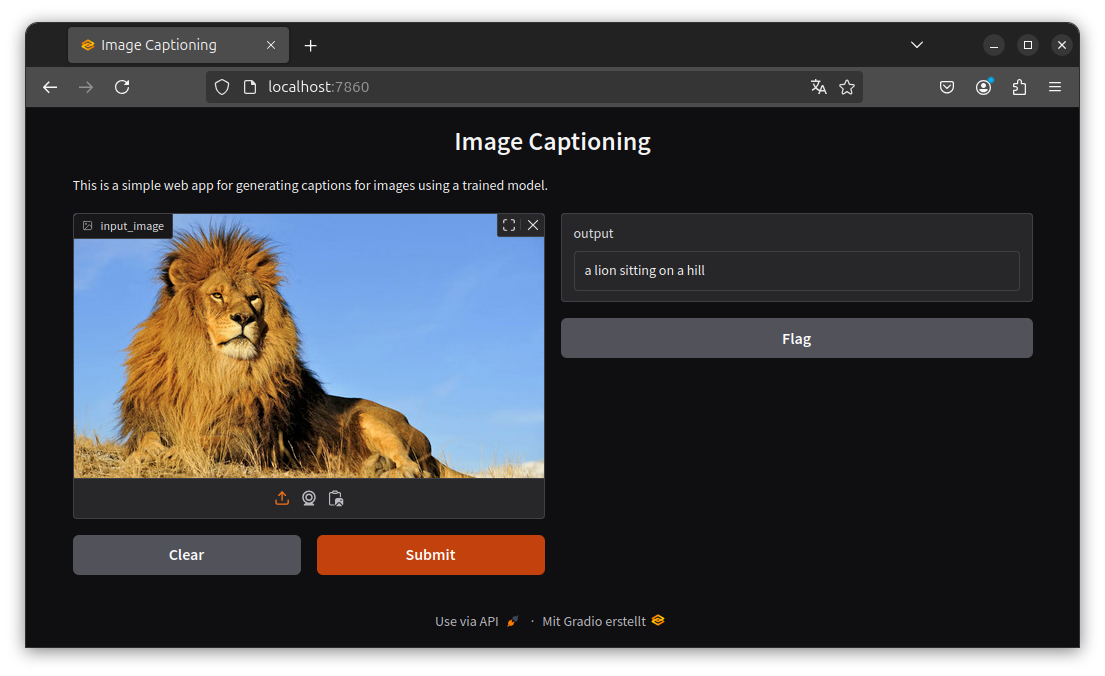
Performance: The BLIP model consistently provided accurate captions that closely reflected the content of the input images. The quality of captions varied slightly depending on the complexity of the image but remained contextually relevant.
User Interaction: The Gradio interface proved to be user-friendly, allowing users to seamlessly upload images and receive captions with minimal delay. Feedback from initial users highlighted the intuitive design and effectiveness of the model in generating relevant captions.
Applications: Successful demonstrations of the app suggest potential implementations in accessibility features (e.g., assisting visually impaired users) and content creation (e.g., auto-generating descriptions for social media posts or databases).
In conclusion, the integration of AI-generated image captions through the BLIP model in a web application represents a significant advancement in image processing technology, with potential implications across a range of industries. Further optimizations could enhance model responsiveness and expand its capability to handle complex scenes or abstract concepts.
