Abstract
This research proposal outlines the development of GenAI-Chat, a Retrieval-Augmented Generation (RAG) based chatbot designed to enhance user interactions by integrating retrieval mechanisms with generative AI models. The system aims to provide accurate, contextually relevant, and up-to-date responses by leveraging external knowledge sources during the response generation process. The proposed study will focus on the design and implementation of GenAI-Chat, emphasizing its potential applications in various domains.
Introduction
The advent of Large Language Models (LLMs) has significantly advanced the capabilities of conversational AI systems. However, these models often face challenges such as hallucinations and the inability to access real-time information, limiting their effectiveness in dynamic environments. Retrieval-Augmented Generation (RAG) addresses these limitations by combining the strengths of information retrieval systems with generative models, enabling chatbots to produce more accurate and contextually appropriate responses. This integration is particularly beneficial in domains where up-to-date and precise information is crucial, such as customer support, education, and healthcare.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is an AI technique that enhances the capabilities of large language models by augmenting them with external knowledge. Instead of relying solely on the pre-trained knowledge of an LLM, RAG retrieves relevant information from a database or knowledge store to provide contextually accurate responses. This approach helps:
- Handle domain-specific queries.
- Improve accuracy by grounding responses in factual data.
- Reduce hallucination.
Architecture
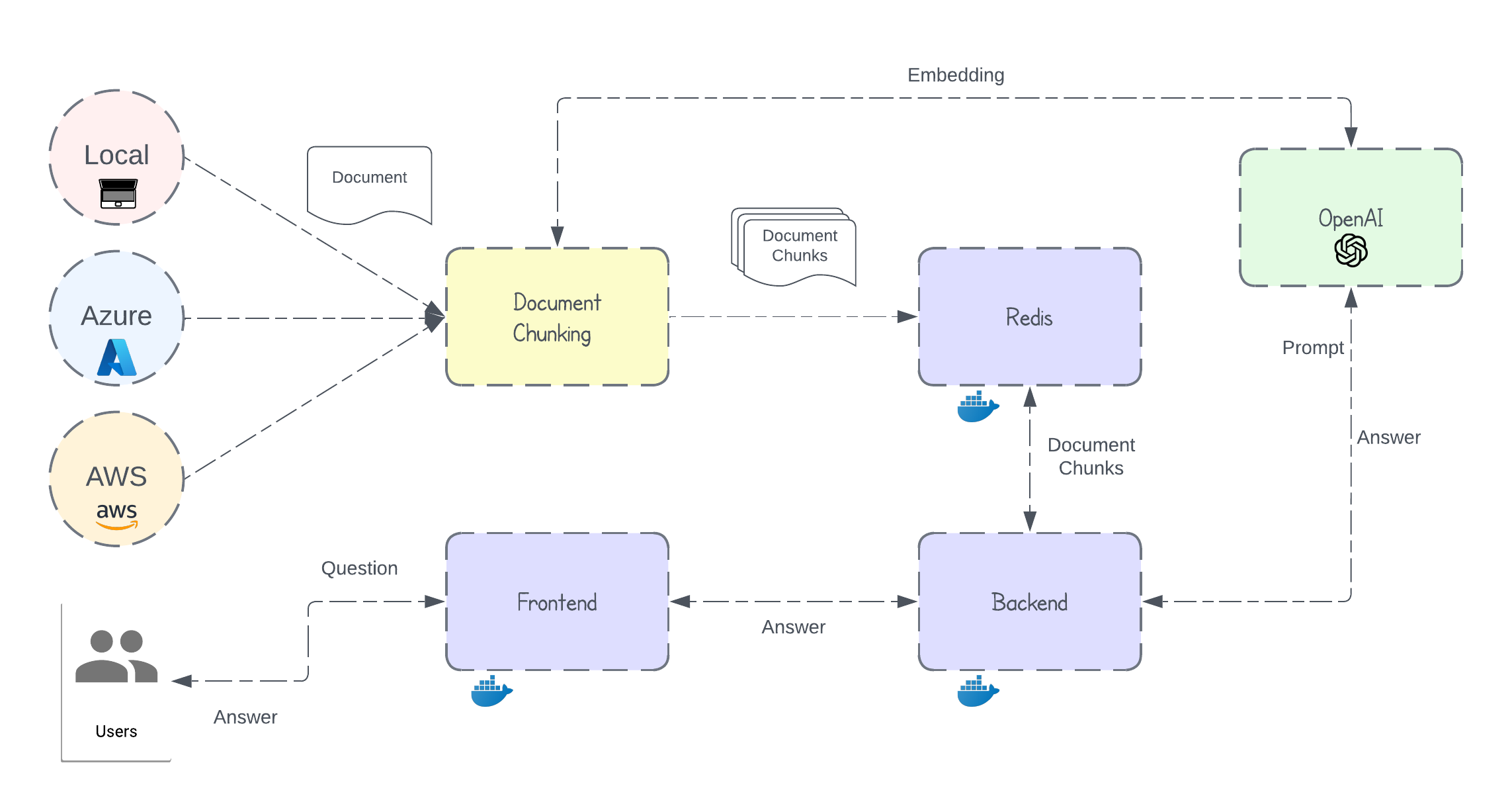
GenAI Chat is an intelligent question-answering chatbot designed to help users interact with their data. Built on the Retrieval Augmented Generation (RAG) technique, it leverages the power of OpenAI’s large language models (LLMs) and Redis vector databases to provide accurate and context-aware answers to complex user queries.
The chatbot consists of these core components:
- Frontend: Takes user queries and sends them to the backend. It's built with HTML + JavaScript and is running in a Docker container with Nginx.
- Backend: Takes user queries, fetches relevant documents from Redis Vector DB, builds prompts, and sends them to the LLM for generating response. Its built with Flask and is running in a Docker container.
- Redis Vector Database: Stores the document text, embedding vectors and session data. It’s also running in a Docker container.
- OpenAI LLM: Takes prompt and generates response. Chatbot utilizes
gpt-4omodel for generating response andtext-embedding-3-largemodel for generating embedding vectors.
Methodology
Key Features
- Dynamic Knowledge Retrieval: It retrieve relevant documents from Redis Vector databases in real time, allowing them to respond with up-to-date and contextually accurate information.
- Natural language understanding: It utilizes Large language models (LLMs). LLMs can analyze complex patterns in language and can accurately interpret subtle meanings, respond appropriately to diverse queries, and adapt to various conversational styles, significantly enhancing the quality of human-computer communication.
- Multiple File Support: Project currently supports
.txt,.pdf,.docx,.json,.csvand.xlsxfiles. - Multiple Data Source Support: Project supports 3 different sources for document indexing i.e.
Local,AzureandAWS.
Data indexing
Users can index documents into the Redis Vector Database from the below 3 sources:
- Local Files
- Azure Blob Storage
- AWS S3 Buckets
Once documents are uploaded, they go through a chunking process that breaks large documents into multiple smaller documents (chunks). Then embedding vector for each chunk is generated using OpenAI’s text embedding model. Finally, each chunk’s text and its embedding vector are stored in the Redis Vector Database.
Classifying LLM Responses for Source Exclusion
In certain types of LLM responses, such as greeting messages and thank you messages, it is unnecessary to display source information in the final output. To address this, we use the DistilBERT model to classify LLM responses into 3 specific categories: Greeting messages, Thank You messages, and Bad messages. Below are examples of each category:
- Greeting message example: Hi, how can I assist you today?
- Thank you message example: I’m glad that was helpful! Let me know if there’s anything else I can assist you with.
- Bad message example: I’m sorry, but I need more clarity on your question. Can you provide more details?
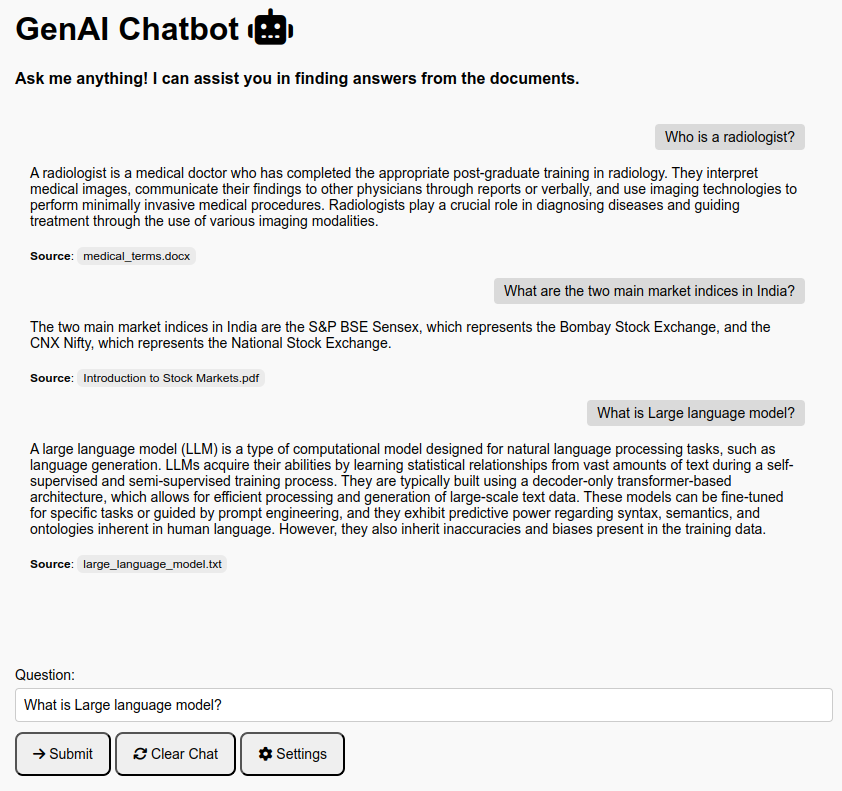
If an LLM response is classified into any of these categories, the source information will be omitted from the final output.
Technology Used
Python, Flask, Docker, Nginx, Redis, Pytorch, HTML, AWS, Azure
Implementation
Message history
Large Language Models (LLMs) are inherently stateless, meaning they do not retain the memory of previous interactions. To enable a chatbot with multi-turn conversational capabilities, it is crucial to provide the LLM with past conversations.
Below is the structure of message object which is sent to OpenAI to generate final response, it is stored in Redis with a unique session ID:
messages = [ {"role": "system", "content": objective}, {"role": "system", "content": document_context}, {"role": "user", "content": question}, {"role": "assistant", "content": response}, {"role": "user", "content": question}, {"role": "assistant", "content": response}, {"role": "user", "content": question} ... ]
Note:
- Past conversations will be removed from the message object based on the token limit. This is necessary to maintain the message object within a defined size and to ensure that the LLM focuses more on recent conversations.
- The
document_contextis removed from the message object before saving it in Redis. It is dynamically updated for each new question to ensure the latest context is provided to the LLM.
Index Schema
Below is the index schema for index in Redis Vector Database which stores several pieces of information for each document chunk, including the index name, filename, chunk id, text content, source details, tags, and embedding vector.
def create_index(index_name): try: # check to see if index exists redis_client.ft(index_name).info() print("Index already exists!") except: # schema schema = ( TextField("index_name"), # Text Field TextField("file_name"), # Text Field TextField("chunk"), # Text Field TextField("content"), # Text Field TextField("source"), # Text Field TagField("tag"), # Tag Field Name VectorField("vector", # Vector Field Name "FLAT", { # Vector Index Type: FLAT or HNSW "TYPE": "FLOAT32", # FLOAT32 or FLOAT64 "DIM": EMBEDDING_DIMENSIONS, # Number of Vector Dimensions "DISTANCE_METRIC": "COSINE", # Vector Search Distance Metric } ), ) # index Definition definition = IndexDefinition(prefix=[DOC_PREFIX], index_type=IndexType.HASH) # create Index redis_client.ft(index_name).create_index(fields=schema, definition=definition) print(f"Index {index_name} created!")
Parameters
Here are some of the configured parameters:
SESSION_EXPIRATION: Chat history will be removed from Redis after 900 seconds (15 minutes).TOKEN_LIMIT: The maximum token limit for LLM response generation is set to 5000.TOP_K: The top 2 most relevant documents based on the user’s query will be retrieved from Redis.CHUNK_SIZE: Each chunk can contain a maximum of 5000 characters (~1000 tokens).CHUNK_OVERLAP: There will be a 200 character overlap between chunks.
The complete code is available in this GitHub repository.
Conclusion
We discussed how to design and build a Retrieval Augmented Generation (RAG) based chatbot that combines a large language model with a vector database to provide accurate, context-aware responses to user queries.
We explored the process of indexing data from multiple sources such as local files, Azure Blob Storage, and AWS S3, as well as the chunking and embedding steps that ensure the data is efficiently stored and accessed. This approach not only improves accuracy but also reduces the risk of hallucinations, making the chatbot a reliable tool for handling domain-specific queries.
Next Step
Possible enhancements for chatbot:
- Hybrid Search: Combining Vector Search (dense retrieval) with BM25 (sparse retrieval).
- Support for audio, images, etc.
- Support for multiple LLMs ex.
Anthropic Claude 3 Sonnet,DeepSeek R1,Meta Llama 3.3, etc.