One Story at a Time - Getting Info about your favourite novel characters just got easier!

Have you ever found yourself immersed in a novel, only to realize you've forgotten the role or relationships of certain characters? Or perhaps you've been curious about how a side character connects to the protagonist but couldn't recall the details. Such challenges are common, especially when navigating intricate narratives with extensive casts. To address this, I have developed a Python-based Command Line Interface (CLI) tool designed to automatically extract and organize detailed information about characters from unstructured text. Leveraging advanced Natural Language Processing (NLP) techniques, including Retrieval-Augmented Generation (RAG) and the LangChain framework, this tool transforms narrative text into structured data, offering readers clear insights into character roles, relationships, and traits. Additionally, when provided with multiple stories, the tool can identify which narrative a particular character belongs to, enriching the reading experience and aiding literary analysis.
Characters are the heart of any narrative, driving the plot and engaging readers through their journeys. However, as stories grow in complexity, so does the task of tracking character roles, relationships, and developments. My project introduces a tool that automates the extraction of structured character information, providing users with
Role Identification: Determining whether a character is a protagonist, antagonist, or side character.
Relationship Mapping: Elucidating connections between characters, such as familial ties, friendships, or rivalries.
Trait Description: Offering brief overviews of characters' attributes and personalities.
Story Association: Identifying the specific story or stories a character appears in when analyzing multiple narratives.
By converting unstructured narrative text into structured data, this tool facilitates deeper literary analysis, supports academic research, and enhances reader engagement.
This project originated from an interview challenge for a tech company that required me to demonstrate my experience with Retrieval-Augmented Generation (RAG) and Python. This challenge inspired me to address a common issue faced by readers: the difficulty of keeping track of complex character webs in literature. Reflecting on my own struggles to remember each character's significance and their connections often hindered my full engagement with the story. I realized that this is a shared dilemma among many readers. With that in mind, I set out to create a solution that not only helps ease these challenges but also enhances the overall comprehension and appreciation of literary works.
Additionally, this project aims to transform random stories into structured data. By analyzing narrative elements like character relationships, plot points, and themes, the tool can present these components in an organized manner. This structured data not only simplifies the understanding of the storyline but also allows readers to easily reference character backstories, motivations, and their interactions. Overall, this approach fosters a deeper engagement with the text and helps readers navigate complex narratives with greater ease.

The development of this project involves several key components:
The tool processes narrative texts stored in the stories directory. These texts serve as the input from which character information is extracted.
To manage large texts effectively, I utilized the LangChain framework to split the narratives into manageable chunks. Each chunk is then converted into embeddings—numerical representations of text—using Google's Gemini Pro model for text generation. These embeddings facilitate efficient retrieval of relevant text segments during the extraction process.
The generated embeddings are stored in ChromaDB, an open-source vector database optimized for AI applications. This setup enables quick and accurate retrieval of text chunks relevant to specific queries, which is crucial for the Retrieval-Augmented Generation (RAG) process.
CHROMA
RAG combines retrieval-based and generation-based models. In this project, when a query about a character is posed, the system retrieves relevant text chunks from ChromaDB and uses them to generate structured information about the character. This approach ensures that the generated information is both contextually relevant and accurate.
The extracted character information is structured into a JSON format, providing a clear and organized representation of attributes such as name, role, relationships, and traits. This structured data can be easily analyzed, visualized, or integrated into other applications.
I developed a user-friendly CLI to interact with the tool. Users can input commands to process specific stories and extract character information, making the tool accessible to individuals with varying levels of technical expertise.
To enhance robustness, the tool implements comprehensive error-handling mechanisms to address edge cases, such as missing data or ambiguous character references, ensuring reliable performance across diverse narratives.
By integrating these components, the tool effectively transforms unstructured narrative text into structured character information, enhancing readers' engagement and understanding of complex literary works.
Place your story files in the stories directory. Each file should:
Process all stories and generate embeddings:
python cli.py compute-embeddings stories/
Get information about a specific character:
python cli.py get-character-info "Character Name"
When extracting information about a character, you'll get a JSON response like this:
The output includes:
{ "name": "Jon Snow", "storyTitle": "Game of Thrones", "summary": "Jon Snow is a brave and honorable leader who serves as the Lord Commander of the Night's Watch and later unites the Free Folk and Westeros against the threat of the White Walkers.", "relations": [ {"name": "Arya Stark", "relation": "Sister"}, {"name": "Eddard Stark", "relation": "Father"} ], "characterType": "Protagonist" }
Your story files should contain narrative text that includes character interactions and descriptions.
Example dataset.
Stories
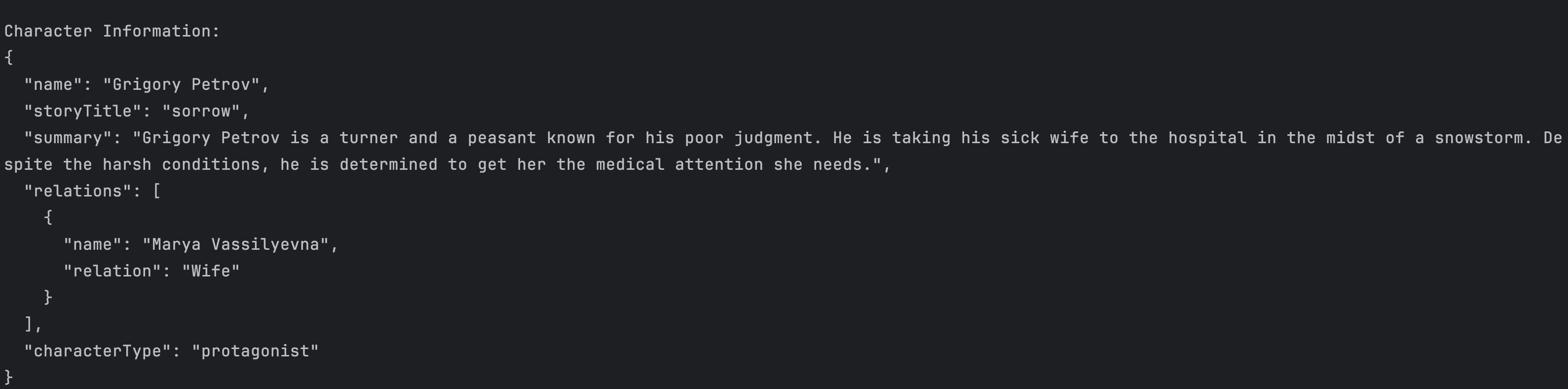
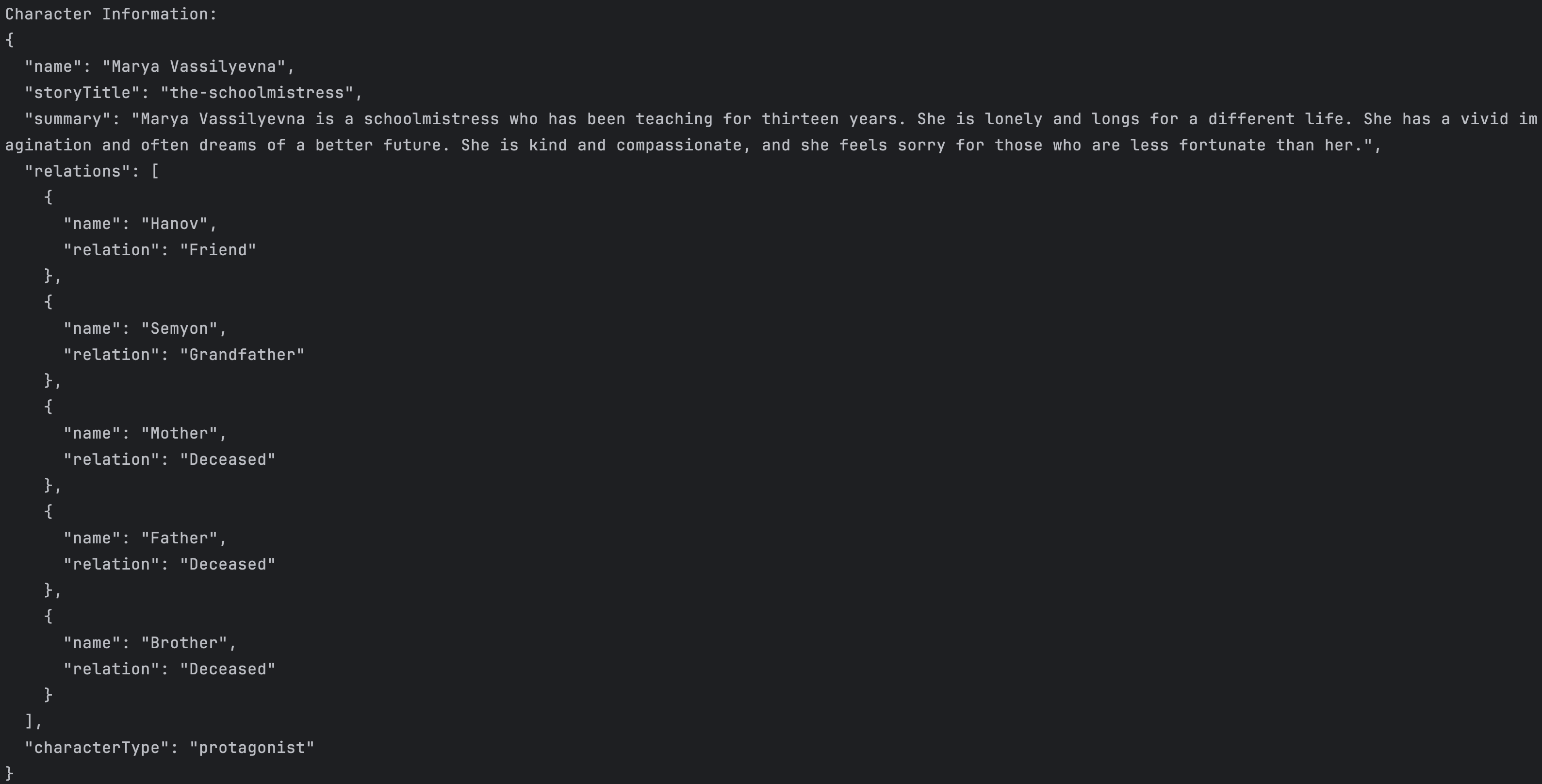

The tool handles various edge cases:
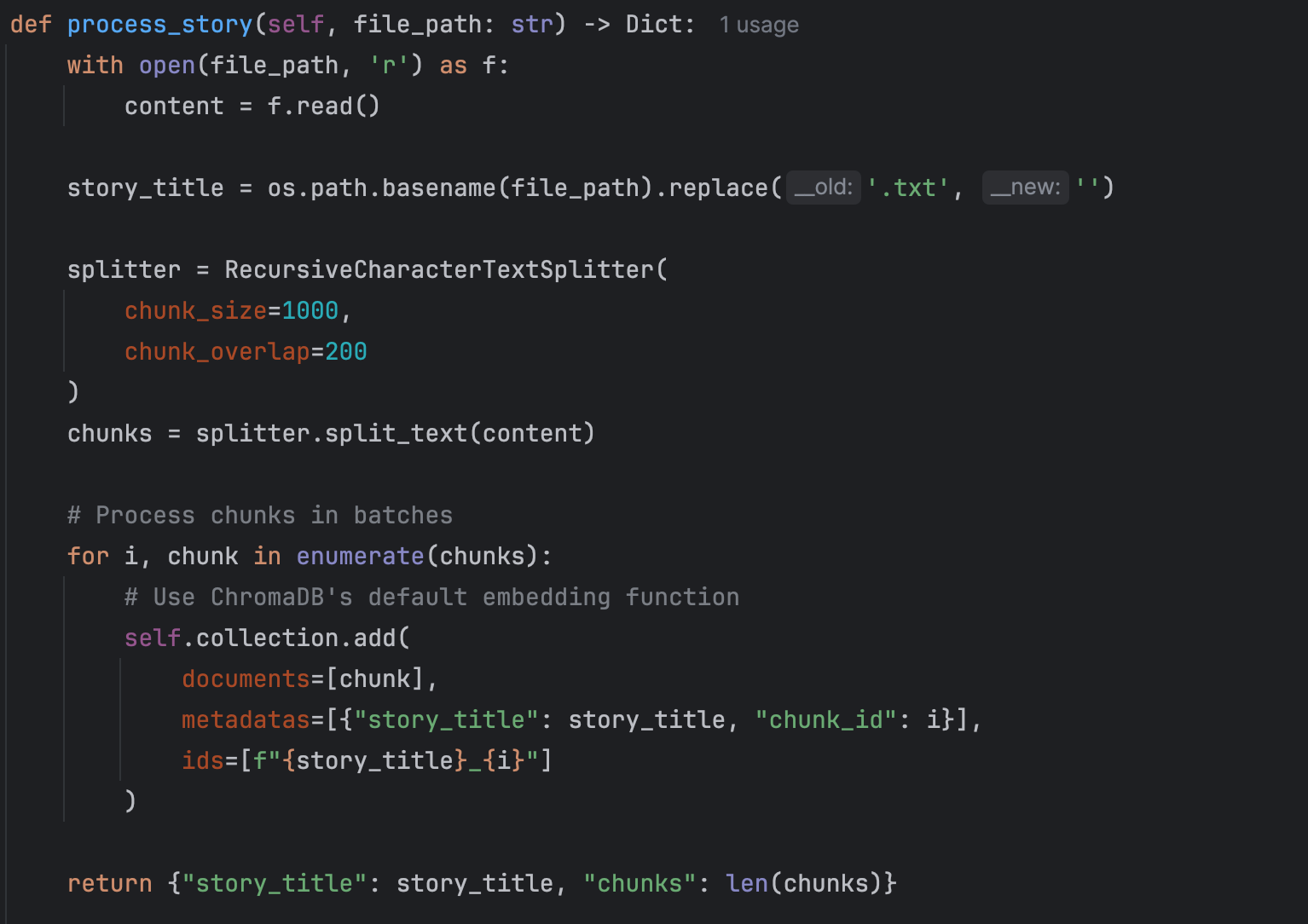
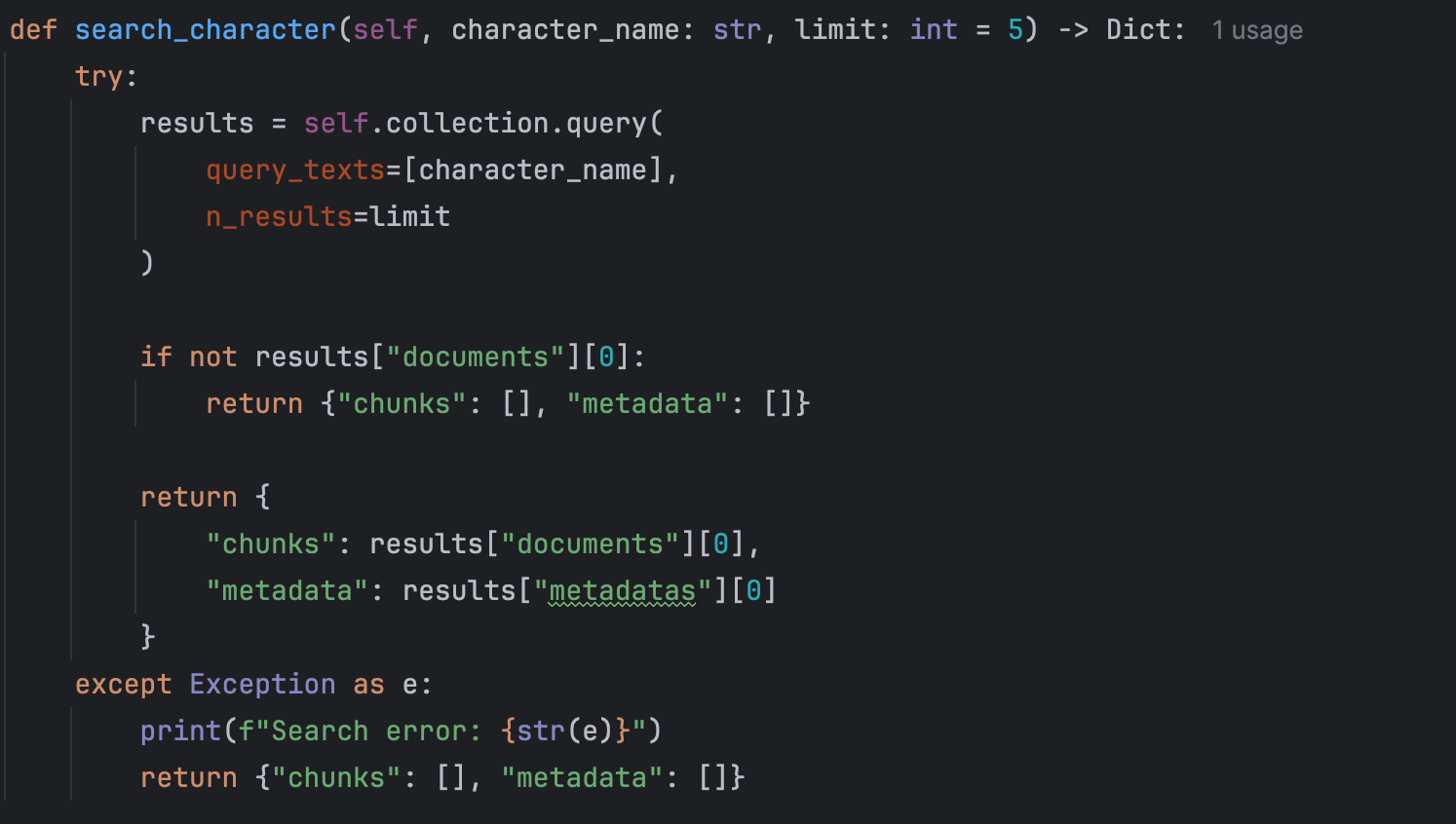

This project demonstrates the potential of integrating advanced NLP techniques, such as RAG and LangChain, to bridge the gap between unstructured literary narratives and structured data analysis. By automating the extraction of character information, the tool offers a valuable resource for readers, educators, and researchers, fostering a deeper understanding and appreciation of literature.
For more details and access to the code plus more such projects please visit my GitHub repositories:
Feel free to follow for more such works
https://github.com/Ayu5-h/Structured-Information-Extraction---Character-Info
https://js.langchain.com/docs/introduction/?utm_source=chatgpt.com
https://docs.trychroma.com/docs/overview/introduction
https://python.langchain.com/docs/concepts/rag/
https://cookbook.chromadb.dev/embeddings/bring-your-own-embeddings/