1. Abstract
Document parsing is a critical task for automating workflows across various industries, traditionally reliant on optical character recognition (OCR) methods that are often computationally expensive and limited in flexibility. In this work, we leverage Google’s Paligemma, a state-of-the-art vision-language model, to fine-tune its capabilities for structured document parsing. By training Paligemma on a custom receipts dataset, we enable it to output structured JSON files. This approach reduces manual data entry efforts and demonstrates practical feasibility, operating efficiently on a single T4 GPU. Our results highlight the transformative potential of vision-language models in real-world document understanding tasks.
2. Introduction
Document parsing plays a pivotal role in automating data extraction processes, especially in industries such as finance, retail, and logistics. Documents like receipts and invoices are typically unstructured, making manual data entry both time-consuming and prone to errors. Traditional OCR techniques, though widely used, struggle with noisy data, diverse layouts, and high computational demands, particularly when scaled to real-world applications.
To address these challenges, we employ Google’s Paligemma model, a cutting-edge vision-language architecture designed for multimodal tasks. Paligemma integrates the SigLIP image encoder and Gemma text decoder through a linear adapter, combining visual comprehension with linguistic capabilities. The SigLIP encoder uses pairwise Sigmoid loss for efficient training and improved generalization, while the Gemma decoder generates structured textual outputs from tokenized inputs.
This project fine-tunes Paligemma for parsing receipt images into structured JSON files, facilitating seamless integration into database tools for automated workflows such as expense management and inventory tracking. The model demonstrates robust performance on a single T4 GPU, making it both cost-effective and practical for business applications. By leveraging advanced vision-language models over traditional OCR systems, our approach emphasizes computational efficiency, adaptability, and accuracy in document parsing tasks.
3. Literature Review
The motivation for this project stemmed from the limitations of traditional OCR-based document parsing methods, which often faltered when dealing with complex layouts, non-standard fonts, or low-resolution images. To overcome these challenges, we explored OCR-free approaches, such as the DONUT transformer, which presented a promising framework for document parsing. However, DONUT lacked the robustness required to handle diverse document formats comprehensively.
The release of Google’s Paligemma in July 2024 introduced a significant advancement in vision-language models. With 3 billion parameters and pretraining on multimodal datasets, Paligemma demonstrated exceptional capabilities for tasks requiring an intricate understanding of visual and textual information. Its modular architecture, documented extensively on platforms like Hugging Face, provided a flexible and powerful foundation for transfer learning in complex downstream tasks.
Recognizing Paligemma’s potential, we integrated it into our workflow to address the challenges of receipt parsing. The extensive documentation and resources on Hugging Face enabled efficient fine-tuning of the model for extracting key-value pairs from receipt images into structured JSON formats. This project represents the confluence of our need for an improved document parsing approach and the opportunity to leverage state-of-the-art vision-language technology.
4. Methodology
In this study, we fine-tuned Google’s Paligemma-3B-224 model using the PyTorch Lightning module for structured document parsing. The methodology involved several critical steps, starting with dataset preparation, where we employed a custom receipts dataset comprising images, unique IDs, parsed data, and raw data. This dataset was specifically selected to encapsulate diverse layouts and noisy characteristics commonly encountered in receipt parsing tasks.
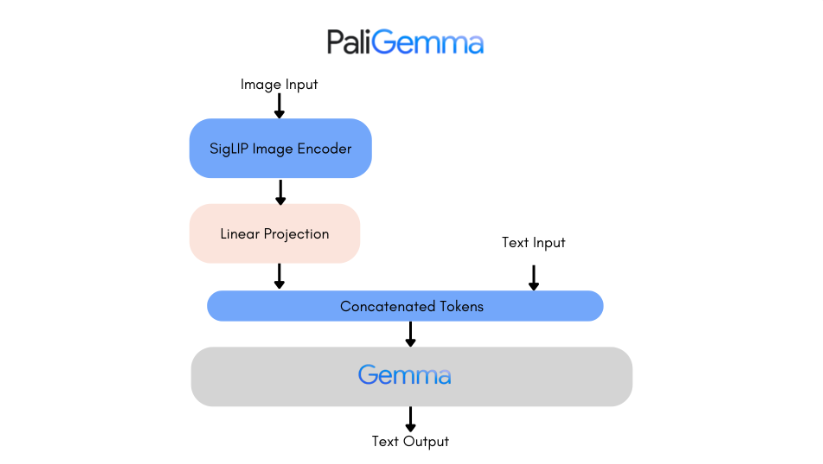
The Paligemma-3B-224 model was configured to balance efficiency and performance. It integrates the SigLIP image encoder and the Gemma text decoder, which facilitate multimodal input processing. Given the limited computational resources of a T4 GPU, we updated the weights in the model’s attention layers (approximately 170 million parameters) and opted for the Stochastic Gradient Descent (SGD) optimizer instead of the more resource-intensive Adam optimizer to enhance computational efficiency.
Data preprocessing was conducted using the Paligemma AutoProcessor, which performs image processing and tokenization. The parsed data was transformed into tokens suitable for training, followed by collation to prepare the data for model input. The training pipeline required inputs such as prompts, processed images, and text tokens, while evaluation tasks utilized prompts and processed images. Data loaders ensured that the processed inputs included input IDs, token type IDs, attention masks, pixel values, and labels for training and evaluation purposes.
The training pipeline utilized the SigLIP encoder for visual processing of images with pairwise Sigmoid loss and the Gemma decoder for generating structured textual outputs from tokenized sequences. The PyTorch Lightning module streamlined the process, enabling efficient training and validation. Training and validation steps were implemented to optimize performance, where the SGD optimizer facilitated faster convergence, although it sacrificed some of the precision provided by AdamW.
4.1 Loss Function
To optimize our fine-tuned Paligemma model for structured document parsing, we employed the pairwise sigmoid loss function. This choice was driven by its ability to align multimodal representations, particularly the image embeddings from the SigLIP encoder with the token embeddings from the Gemma decoder. By focusing on pairwise relationships, the loss ensures that relevant visual features correspond to accurate textual tokens, a crucial requirement for generating structured outputs like JSON.
During fine-tuning, the loss function evaluated the similarity between image features and text token embeddings for each pair of input data. Positive pairs—such as specific receipt image regions and their corresponding JSON keys—were encouraged to have higher similarity scores. Conversely, unrelated pairs were penalized to minimize their similarity, ensuring precise alignment between visual and textual modalities.
The loss function also proved computationally efficient compared to traditional contrastive losses, making it particularly suitable for resource-constrained setups like our T4 GPU environment. By optimizing the model using pairwise sigmoid loss, we achieved a significant improvement in the accuracy of key-value pair extraction while maintaining efficient training dynamics. This tailored optimization approach reinforced the model’s capacity to generalize across diverse receipt layouts and noisy document formats, contributing to its robustness and scalability in real-world applications
Formula
The edit distance (d(i, j)) between two strings (A) and (B) of lengths (m) and (n) is calculated using the following recursive relation:
where:
is the label indicating whether a pair is a positive match (1) or a negative match (0). is the similarity score between the embeddings of input and (e.g. cosine similarity). represents the indicator function 1 for a positive pair and 0 otherwise. is the total number of pairs.
4.2 Edit Distance
Edit distance was employed as a key evaluation metric to quantify the performance of the fine-tuned Paligemma model. Specifically, edit distance measures the minimum numerical of operations - such as insertions, deletions or subscriptions required to transform the predicted text into the ground truth text. By leveraging this metric, we were able to assess the accuracy of our model in recognizing and reconstructing text from input data.
During fine-tuning, edit distance provided a granular understanding of the model's performance across varying levels complexity. For example, a lower edit distance indicated that the model was accurately predicting text with minimal errors, while an increase in the metric reflected challenges posed by more complex inputs. This allowed us to identify patterns in errors and optimize the model further. Additionally, edit distance was instrumental in validating the generalizability of the model, as it helped benchmark performance against traditional OCR systems.
4.3 LORA
To make the model memory efficient, quantization to 8-bit precision was implemented, reducing the weights from Float32 to 8-bit without significantly compromising accuracy. The project also introduced Low-Rank Adaptation (LoRA), which applies targeted updates to specific layers of the model. These layers included the query, key, value, and output projections, as well as gate, up, and down projections. This approach maintained high computational efficiency while enhancing the adaptability of the fine-tuned model for the document parsing task.
5. Results
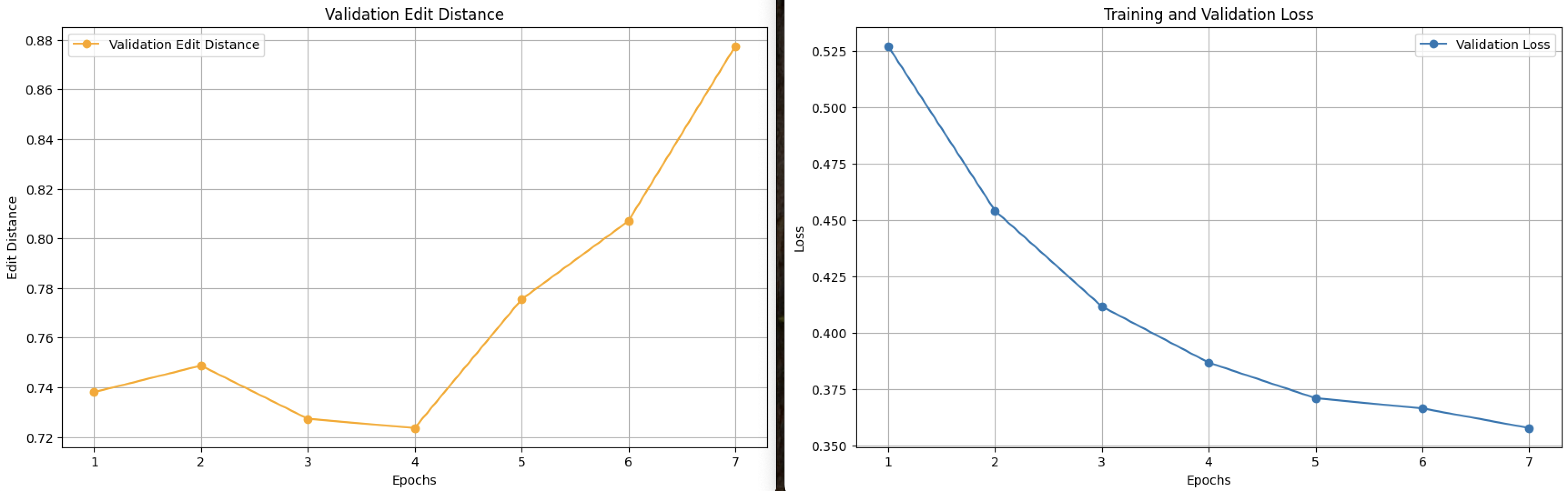
The two graphs collectively provide insights into the performance and efficiency of our fine-tuned Paligemma model. The first graph illustrates the validation edit distance over seven epochs, showing an initial stable trend followed by a gradual increase in later epochs. This rise in edit distance is attributed to the growing complexity of inputs encountered during validation, which challenges the model's ability to maintain low errors. Despite this, the second graph, depicting validation loss, shows a steady decline from approximately 0.525 in epoch 1 to around 0.35 in epoch 7. This consistent reduction in loss indicates the model's ability to optimize and generalize well across increasingly diverse and complex datasets.
Our approach demonstrates a significant advantage in terms of computational efficiency compared to traditional OCR methods. While traditional OCR systems can achieve higher precision in certain cases, they often require extensive computational resources and fine-tuning time. In contrast, our fine-tuned Paligemma model achieves comparable results with minimal computation overhead, requiring only a T4 GPU for training and deployment. This makes it particularly suitable for production environments where resource constraints are critical. The close alignment of our model's precision to that of traditional methods, combined with its efficiency, underscores its potential as a potential and scalable solution for real world OCR tasks.
5.1 Inference
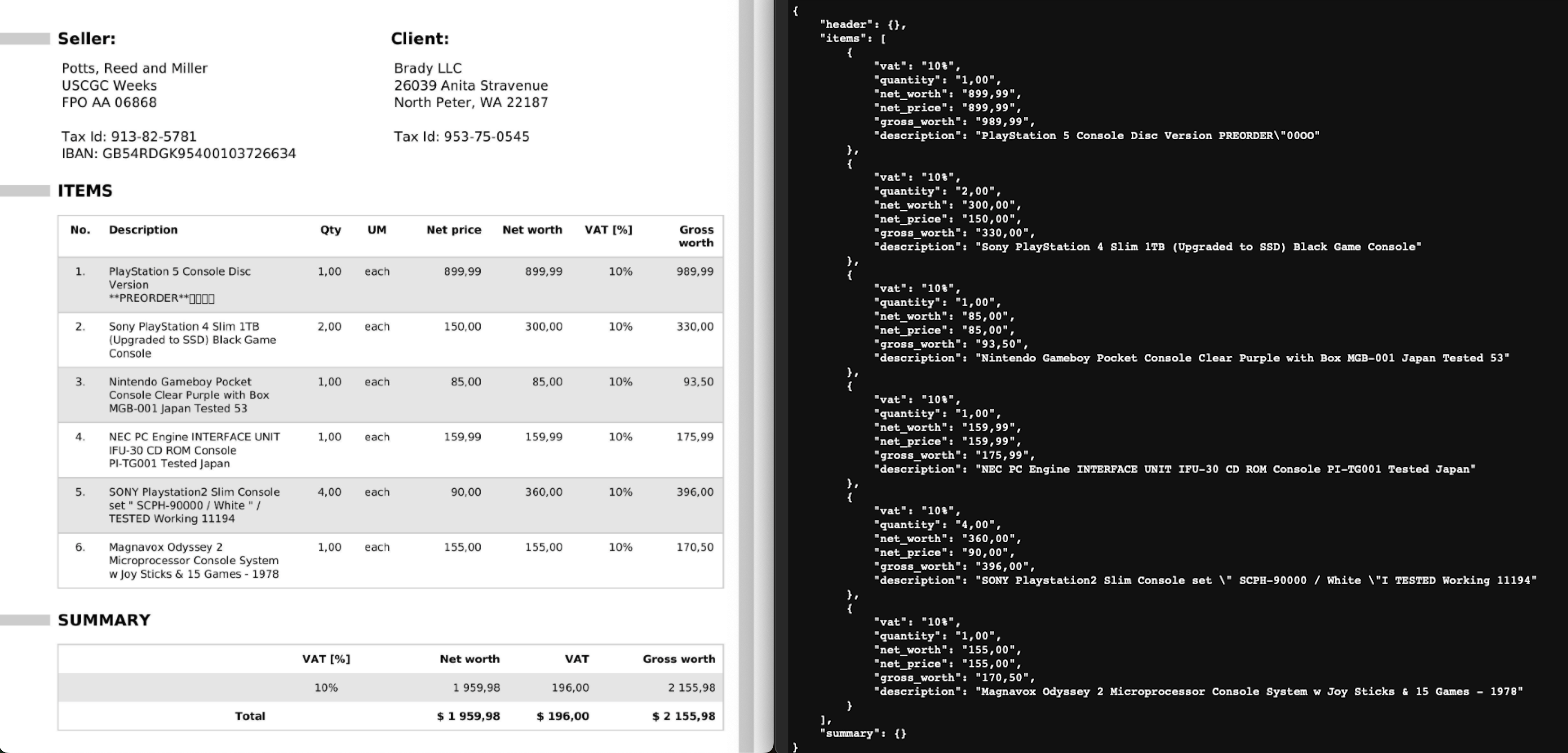
We have added an example of a receipt image to demonstrate the model's performance. This example showcases how effectively the fine-tuned Paligemma model extracts and structures data, highlighting its accuracy and ability to parse complex receipt layouts.
6. Conclusion
In conclusion, this project demonstrates the efficacy of leveraging advanced Vision-Language Models, specifically Paligemma, for document understanding and key-value extraction from complex receipt images. By addressing the limitations of traditional OCR-based techniques, we successfully implemented an OCR-free pipeline capable of parsing and structuring information with high accuracy. Through fine-tuning and systematic evaluation, the model showcased its robustness and versatility, paving the way for scalable solutions in real-world applications.
The integration of Paligemma into our workflow highlights the transformative potential of cutting-edge AI technologies in handling diverse and intricate document layouts. This project not only contributes to advancements in document understanding but also underscores the importance of transfer learning and domain-specific adaptations in maximizing the utility of large-scale pre-trained models. Future work could explore further optimization of the model, including enhancements for multilingual support and expanding its applicability to other types of documents.
Ultimately, this project represents a significant step forward in the automation and efficiency of data extraction and processing, setting a solid foundation for future innovations in this domain.
7. Citations:
PaliGemma: A versatile 3B VLM for transfer [https://doi.org/10.48550/arXiv.2407.07726]