
In this article, we explore Parameter-Efficient Fine-Tuning (PEFT) methods, including Full Fine-Tuning, LoRA (Low-Rank Adaptation), DoRA (Weight-Decomposed Low-Rank Adaptation), and QLoRA (Quantized LoRA). By training and testing models on the SST-2 (Stanford Sentiment Treebank) dataset, we compare these approaches in terms of accuracy, loss, memory savings, and computational efficiency. The results demonstrate how PEFT methods can significantly reduce the computational burden and memory requirements without compromising performance, making them ideal for large-scale language models.
As large language models continue to grow in size and complexity, the demand for efficient fine-tuning methods has increased dramatically. Traditional full fine-tuning approaches, which involve updating all model parameters, are resource-intensive and often impractical for large models due to memory and computational constraints. This challenge has led to the development of Parameter-Efficient Fine-Tuning (PEFT) methods, which allow for effective adaptation of pre-trained models while updating only a small fraction of the parameters.
In this article, we dive into four popular fine-tuning approaches:
Full Fine-Tuning: The baseline approach where all model parameters are updated.
LoRA (Low-Rank Adaptation): A method that introduces trainable low-rank matrices to the model's weight matrices, reducing the number of updated parameters.
DoRA (Weight-Decomposed Low-Rank Adaptation): A further optimized variant of LoRA that decomposes model weights for enhanced efficiency.
QLoRA (Quantized Low-Rank Adaptation): A quantized version of LoRA that leverages 4-bit quantization to further reduce memory usage while maintaining performance.
We evaluate these techniques using the SST-2 (Stanford Sentiment Treebank) dataset, comparing their performance in terms of accuracy, loss, and memory efficiency. By the end of this article, readers will understand how PEFT methods can significantly reduce training costs while preserving or even improving model performance, making them an essential tool in the world of large-scale language models.
Full Fine-Tuning is the traditional approach to adapting a pre-trained model to a specific task. In this method, all of the model's parameters are updated during the fine-tuning process. This means that the pre-trained weights are not frozen; instead, they are adjusted to minimize the loss on the new dataset.
Since the model's entire parameter set is modified, full fine-tuning can lead to optimal performance for the target task, as the model has the flexibility to fully adapt to the new data.
High flexibility : The model can learn highly specific patterns for the new task, potentially leading to the best performance, especially when the task differs significantly from the pre-training objective.
State-of-the-art results: Full fine-tuning has been used in numerous applications to achieve leading results across a variety of NLP benchmarks.
Memory and computational cost: Fine-tuning all the parameters of a large model (e.g., models with billions of parameters) requires a significant amount of GPU memory and computational power, making it impractical for many users without access to specialized hardware.
Overfitting risk: If the new dataset is small or very specific, full fine-tuning can lead to overfitting, as the model may overly adjust to the fine-tuning dataset, losing some of the benefits from pre-training.
While full fine-tuning remains the baseline approach, it often becomes impractical as model sizes increase. This has motivated the development of parameter-efficient fine-tuning (PEFT) methods, which aim to reduce the number of parameters updated during fine-tuning, lowering computational requirements while still achieving high performance.
Parameter-Efficient Fine-Tuning (PEFT) methods offer a practical solution to the high computational and memory demands of full fine-tuning by updating only a fraction of the model’s parameters. These methods are particularly useful for fine-tuning large pre-trained models with limited hardware resources. In this section, we briefly introduce three key PEFT approaches: LoRA, DoRA, and QLoRA.
LoRA introduces trainable, low-rank matrices to the model’s weight matrices while freezing the core parameters. By only training the smaller, low-rank matrices, LoRA reduces the number of trainable parameters, making it highly efficient for large models. This technique has gained popularity for its ability to fine-tune models with significantly lower memory and computational requirements compared to full fine-tuning.
DoRA builds on the principles of LoRA but takes parameter efficiency further by decomposing weight matrices into low-rank components. This decomposition allows for even fewer trainable parameters while maintaining model performance. DoRA is designed for scenarios where memory efficiency is paramount, and fine-tuning needs to be performed with even less overhead.
QLoRA is a highly efficient fine-tuning method that combines the low-rank adaptation of LoRA with quantization, reducing the precision of the frozen weights (e.g., from 32-bit to 4-bit). This results in a dramatic reduction in memory usage while maintaining performance. QLoRA is particularly effective for fine-tuning large models on smaller hardware, making it one of the most memory-efficient methods available today.
LoRA is a popular Parameter-Efficient Fine-Tuning (PEFT) method designed to reduce the computational and memory overhead associated with fine-tuning large pre-trained models. Instead of updating the entire set of model parameters, LoRA introduces small, trainable low-rank matrices to specific weight matrices, while freezing the original model weights. This allows for efficient fine-tuning without sacrificing much performance.
The main idea behind LoRA is that instead of fine-tuning all parameters, we assume that the weight updates during fine-tuning can be expressed as a low-rank matrix. This significantly reduces the number of parameters to train, leading to memory and time savings. LoRA is especially effective in large models where the number of parameters is massive, making traditional fine-tuning impractical.
LoRA has been widely adopted for tasks that require fine-tuning massive models, particularly in natural language processing (NLP) applications. It has been proven to retain a high level of performance, even when only a small fraction of the parameters are updated.
LoRA is a powerful tool in the fine-tuning toolbox, and it serves as the foundation for more advanced PEFT methods such as DoRA and QLoRA.
In this section, we will walk through the technical implementation of the LoRA method applied to GPT-2 Large, specifically targeting the attention layers. The following implementation freezes the majority of the model’s parameters and applies low-rank adaptation matrices to the attention layers, which are of type Conv1D in GPT-2.
We start by defining the LoRA layer and then recursively applying it to the relevant parts of the model.
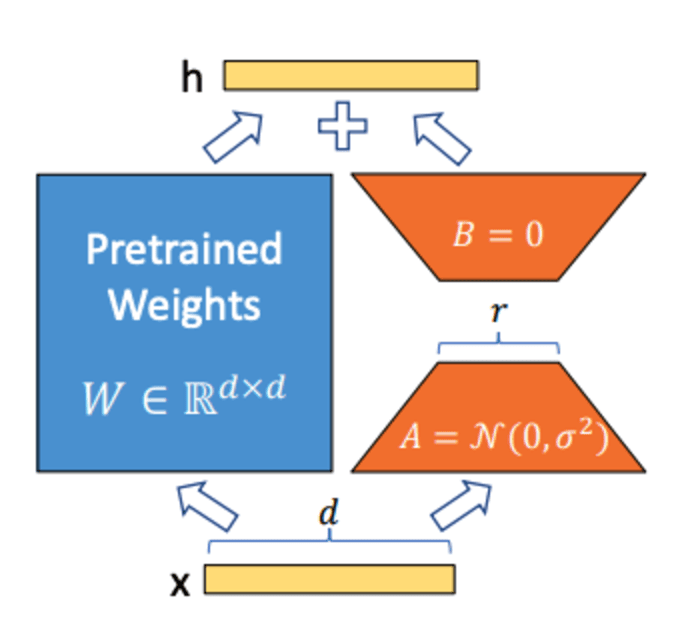
The first step is to create a custom LoRA class that decomposes the weight matrices into two smaller matrices A and B. The key is to modify the model by inserting these small, trainable matrices, which are later used during the fine-tuning process.
class LoRA(nn.Module): def __init__(self, original_layer, alpha, rank=8): super(LoRA, self).__init__() # Store the original layer's weight self.original_weight = original_layer.weight self.alpha = alpha self.rank = rank in_features = original_layer.weight.shape[0] out_features = original_layer.weight.shape[1] # Standard deviation for initialization std_dev = 1 / torch.sqrt(torch.tensor(rank).float()) # Perform weight decomposition into two low-rank matrices A and B # We initialize A and B with random values self.A = nn.Parameter(torch.randn(in_features, rank) * std_dev) self.B = nn.Parameter(torch.zeros(rank, out_features)) # Freeze the original weight (it won't be updated) self.original_weight.requires_grad = False def forward(self, x): # Approximate the original weight as the product of A and B low_rank_weight = self.alpha * torch.matmul(self.A, self.B) adapted_weight = self.original_weight + low_rank_weight # Apply the adapted weight to the input return torch.matmul(x, adapted_weight)
Instead of training the full weight matrix, we introduce two smaller matrices, A and B, to approximate the weight updates in a low-rank form. The rank of these matrices controls their dimensions:
A has dimensions
B has dimensions
where
Multiplying A and B gives a matrix with the same shape as the original weight matrix
Suppose you have the original weight matrix of size (1000x1000). This means that you have a million parameters in the original layer. If we approximate the matrix by decomposing it into two matrices of shape (1000, 8) and (8, 1000), you would only have 16000 trainable parameters. If you then multiply the two matrices, you get the original dimensions back. This way we approximated a million parameters using only 16000 parameters. In this case the rank is 8.
The original model’s weight parameters are frozen (requires_grad = False), meaning they are not updated during fine-tuning. This significantly reduces memory usage and computational complexity because the majority of the model’s parameters remain untouched during the fine-tuning process.
During the forward pass, the effective weight is computed as a combination of the frozen original weight matrix and the scaled product of the two low-rank matrices, A and B, where the alpha parameter controls the magnitude of this adaptation. This scaling helps balance the contribution of the low-rank update to the overall weight matrix. The adapted weight matrix is then applied to the input, allowing the model to leverage the learned low-rank adaptation for fine-tuning, while still retaining the pre-trained knowledge encoded in the frozen weights.
Now that we have the LoRA class, we need to recursively apply it to the attention layers of the model, which are implemented as Conv1D layers in GPT-2.
from transformers.pytorch_utils import Conv1D def apply_peft_to_layer(module, alpha=4, rank=8, type='lora'): """ Recursively applies LoRA/DoRA to the appropriate layers in the model. Args: module: The current module to examine and possibly replace. alpha: Scaling factor for LoRA. rank: The rank of the low-rank adaptation. type: The type of PEFT to apply ('lora' or 'dora'). Returns: None (modifies the module in place). """ peft_module = LoRA if type == 'lora' else DoRA for name, child_module in module.named_children(): # We target the attention layers of GPT-2, which are Conv1D layers if isinstance(child_module, Conv1D) and 'c_attn' in name: # Replace the original attention layer with the LoRA-adapted layer setattr(module, name, peft_module(child_module, alpha=alpha, rank=rank)) # If the module has children, apply the function recursively if len(list(child_module.children())) > 0: apply_peft_to_layer(child_module, alpha, rank, type)
Recursive Application: This function navigates through the model's architecture, searching for attention layers (e.g., c_attn) that are implemented as Conv1D layers.
Conditional Replacement: Once an attention layer is found, we replace it with the LoRA-adapted layer using the setattr() function. The LoRA layer only affects the specific parts of the model where it is applied, leaving the rest of the model unchanged.
Recursive Search: The function checks for child layers and applies LoRA to any matching layers it finds recursively, ensuring that all attention layers in the model are adapted.
Finally, we define a function to load a pre-trained GPT-2 model and apply LoRA to its attention layers.
def get_custom_peft_model(alpha=4, rank=8, type='lora'): """ Load the model and apply LoRA/DoRA recursively to all applicable layers. Args: model_name: The name of the model to load. alpha: Scaling factor for LoRA. rank: Rank for low-rank adaptation in LoRA. Returns: The model with LoRA applied. """ # Load the GPT-2 model and set the pad token ID model = AutoModelForSequenceClassification.from_pretrained(model_name, ignore_mismatched_sizes=True).to(device) model.config.pad_token_id = tokenizer.pad_token_id # Freeze all model parameters except those in the LoRA layers for param in model.parameters(): param.requires_grad = False # Apply LoRA recursively to all relevant layers apply_peft_to_layer(model, alpha=alpha, rank=rank, type=type) return model
Loading the Model: The AutoModelForSequenceClassification function loads a pre-trained GPT-2 Large model.
Freezing the Model: Before applying LoRA, we freeze all of the model’s parameters to ensure that only the LoRA layers will be updated during fine-tuning.
Recursive LoRA Application: We apply the apply_peft_to_layer() function to recursively insert LoRA into the attention layers.
In GPT-2, the attention mechanism is implemented using Conv1D layers in the transformer blocks. This code specifically targets the attention layers (c_attn) of GPT-2 Large, replacing them with LoRA-modified versions. This allows us to achieve fine-tuning by modifying only a fraction of the model's parameters while leveraging the pre-trained knowledge of the frozen layers.
DoRA is an extension of the LoRA method, offering even greater efficiency by applying a weight decomposition technique. Similar to LoRA, DoRA freezes the majority of the model's parameters and focuses on updating only small, trainable matrices. However, DoRA goes one step further by decomposing the weight matrices into two parts before applying low-rank adaptation, allowing for more granular control over the updates.
• In LoRA, the entire weight update is approximated by the product of two low-rank matrices. In DoRA, the original weight matrix is first decomposed into two components: magnitude and direction. This decomposition separates the scaling factor (magnitude) from the orientation (direction) of the weight update, providing more control over the fine-tuning process and improving efficiency.
• The decomposition into magnitude and direction allows for better adaptability in certain tasks, where a more detailed breakdown of the model’s weights can lead to higher performance with fewer trainable parameters. Specifically, DoRA computes unit vectors to represent the direction of weight updates, while applying scaling through a magnitude factor.
The unit vector, which represents the direction, is computed by normalizing the low-rank matrix product. You can obtain the unit vector by diving the vector by its norm.
where
The norm of a vector
The technical implementation of DoRA builds upon the LoRA framework, but adds an additional decomposition step to the weight matrices.
class DoRA(nn.Module): def __init__(self, original_layer, alpha, rank=8): super(DoRA, self).__init__() self.original_weight = original_layer.weight self.alpha = alpha self.rank = rank in_features = original_layer.weight.shape[0] out_features = original_layer.weight.shape[1] # Perform weight decomposition into two low-rank matrices A and B # We initialize A and B with random values std_dev = 1 / torch.sqrt(torch.tensor(rank).float()) self.A = nn.Parameter(torch.randn(in_features, rank) * std_dev) self.B = nn.Parameter(torch.zeros(rank, out_features)) self.m = nn.Parameter(torch.ones(1, out_features)) self.original_weight.requires_grad = False def forward(self, x): # Approximate the original weight as the product of A and B low_rank_weight = self.alpha * torch.matmul(self.A, self.B) low_rank_weight_norm = low_rank_weight / (low_rank_weight.norm(p=2, dim=1, keepdim=True) + 1e-9) # Add the original (frozen) weight back to the low-rank adaptation low_rank_weight = self.m * low_rank_weight_norm adapted_weight = self.original_weight + low_rank_weight # Apply the adapted weight to the input return torch.matmul(x, adapted_weight)
Decomposition Step: An extra decomposition step is introduced with the self.m parameter, allowing the model to learn different magnitudes for the normalized weight updates. This provides more flexibility by decoupling the direction of the weight updates (captured by the low-rank matrices) from their magnitude, enabling finer control over the adaptation process.
Forward Pass: The adapted weight is still a combination of the frozen weight and the low-rank matrices, but with an additional scaling layer that offers more flexibility in weight updates.
To summarize, the key distinction between LoRA and DoRA lies in DoRA's decoupling of the magnitude and direction of the weight updates. This is achieved through the normalization of the low-rank matrices:
low_rank_weight_norm = low_rank_weight / (low_rank_weight.norm(p=2, dim=1, keepdim=True) + 1e-9) low_rank_weight = self.m * low_rank_weight_norm
By normalizing the weight updates and then scaling them with a learnable magnitude parameter (self.m), DoRA allows for more refined control over both the direction and magnitude of the weight updates, enhancing the model’s ability to adapt to specific tasks.
QLoRA builds on the foundation laid by LoRA and further improves efficiency by incorporating quantization techniques. By reducing the precision of the model’s frozen parameters through quantization while keeping the low-rank adaptation matrices in higher precision, QLoRA dramatically reduces the memory and computational requirements without significantly affecting model performance.
The key idea behind QLoRA is to combine the low-rank adaptation from LoRA with 4-bit quantization for the frozen parameters. This approach allows fine-tuning on large models even on hardware with limited memory resources, such as GPUs with smaller VRAM, by maintaining the core functionality of the model with fewer bits while still updating essential components with high precision.
By quantizing the non-trainable parts of the model and focusing on higher precision for the small trainable matrices, QLoRA achieves extreme memory efficiency. This makes it possible to fine-tune extremely large models using commodity hardware, allowing for wider accessibility without compromising performance.
In this section, we’ll walk through the technical implementation of QLoRA, which combines 4-bit quantization with Low-Rank Adaptation (LoRA) to achieve memory-efficient fine-tuning on large models. The goal is to quantize the frozen parameters of the model using 4-bit precision while applying LoRA to specific layers, allowing the fine-tuning process to focus on a small set of trainable parameters.
You can install it using :
pip install -U bitsandbytes
The following code demonstrates how we load a pre-trained model, apply 4-bit quantization, and then incorporate LoRA to fine-tune the model.
from transformers import AutoModelForSequenceClassification, AutoTokenizer, BitsAndBytesConfig model_name = "openai-community/gpt2-large" tokenizer = AutoTokenizer.from_pretrained(model_name) if tokenizer.pad_token is None: tokenizer.pad_token = tokenizer.eos_token # Using eos_token as the pad_token if it's not defined # Step 1: Load the model using 4-bit quantization quantization_config = BitsAndBytesConfig( load_in_4bit=True, # Enable 4-bit quantization bnb_4bit_use_double_quant=True, # Use double quantization for accuracy bnb_4bit_compute_dtype=torch.float16, # Use FP16 for computation during training/inference bnb_4bit_quant_type="nf4", # Normal float 4-bit quantization ) # Step 2: Load the pre-trained model with the quantization configuration model = AutoModelForSequenceClassification.from_pretrained( model_name, quantization_config=quantization_config, # Pass the quantization config device_map="auto", # Automatically map model to available devices (e.g., GPU) ) # Set the padding token ID model.config.pad_token_id = tokenizer.pad_token_id # Step 3: Apply LoRA to the quantized model model = get_peft_model(model, lora_config)
4-bit Quantization Configuration:
BitsAndBytesConfig to enable 4-bit quantization by setting load_in_4bit=True. This ensures that the frozen model parameters are stored in a highly compressed form, using only 4 bits per parameter.bnb_4bit_use_double_quant=True enables double quantization for better accuracy, and bnb_4bit_compute_dtype=torch.float16 ensures that the computations during training and inference are done in 16-bit floating-point precision (FP16).bnb_4bit_quant_type="nf4" specifies the quantization type as normal float 4-bit (NF4), which is known to provide better precision compared to standard 4-bit quantization methods.Loading the Pre-trained Model:
AutoModelForSequenceClassification.from_pretrained and mapped to the appropriate device (GPU or CPU) using device_map="auto".Applying LoRA:
get_peft_model function. This ensures that only a small set of trainable low-rank matrices is updated during fine-tuning, while the frozen, quantized weights remain untouched.By combining 4-bit quantization with LoRA, QLoRA dramatically reduces the memory footprint required to fine-tune large models. The quantization of frozen weights ensures that memory usage is minimized, while LoRA allows fine-tuning to occur on a small set of trainable parameters, preserving performance while making fine-tuning feasible on hardware with limited resources.
In this section, we demonstrate Parameter-Efficient Fine-Tuning (PEFT) in action by comparing the performance and efficiency of the different approaches: Full Fine-Tuning, LoRA, DoRA, and QLoRA. We trained each of these methods on the SST-2 dataset and captured both the model performance (e.g., accuracy) and running time to highlight the trade-offs between each approach.
The SST-2 (Stanford Sentiment Treebank) dataset is a popular benchmark for sentiment classification. It consists of movie reviews, where each review is labeled as either positive or negative. The task involves classifying the sentiment of each review based on the text, making it a suitable dataset for evaluating the performance of natural language models.
SST-2 is widely used for fine-tuning pre-trained models in NLP because of its simplicity and binary classification nature, providing a good baseline for comparing different model architectures and fine-tuning approaches.
We provide a notebook showcasing the full training pipeline, including:
By comparing the results from these different approaches, we can demonstrate the efficiency and scalability benefits of PEFT methods, particularly for large models where full fine-tuning becomes impractical.
We compare the execution times of different fine-tuning approaches: Full Fine-Tuning, LoRA, DoRA, and QLoRA. To make the comparison easier to interpret, we've normalized the execution times, with Full Fine-Tuning set to 100%.
The bar chart below illustrates the relative execution times for each approach. As expected, Full Fine-Tuning takes the longest time, since it updates all model parameters. In contrast, LoRA, DoRA, and QLoRA dramatically reduce execution times by focusing on a smaller set of parameters and applying techniques such as low-rank adaptation and quantization.
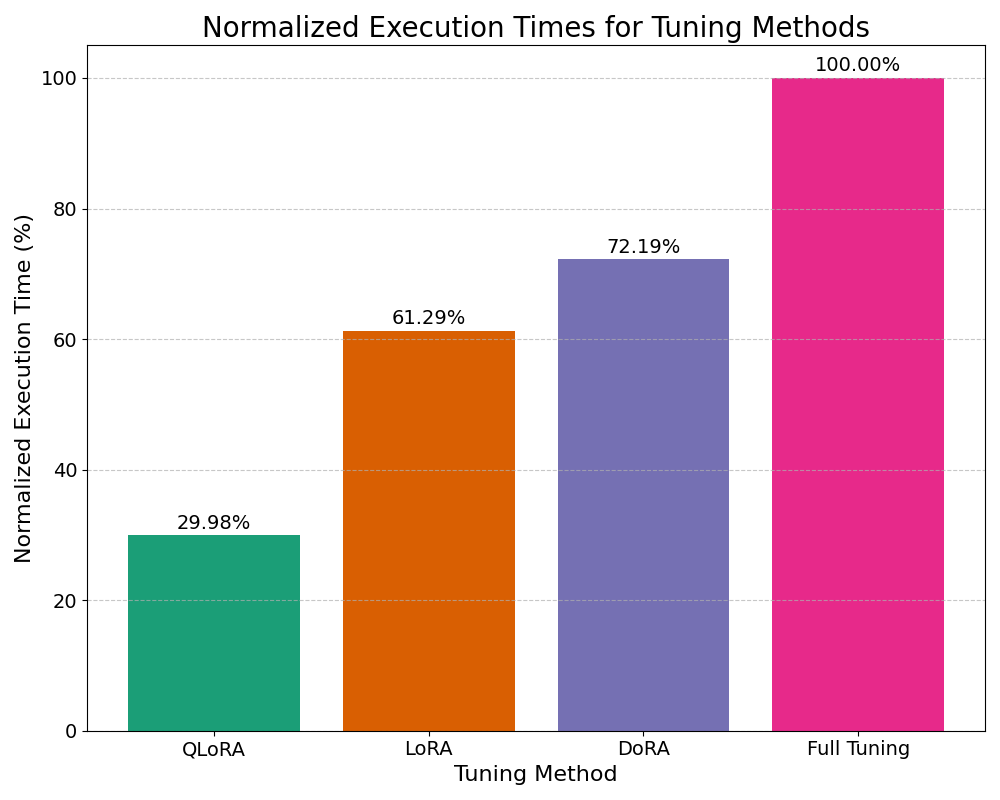
This comparison highlights how parameter-efficient methods like LoRA, DoRA, and QLoRA enable fast fine-tuning of large models, making them suitable for hardware with limited resources while maintaining competitive performance.
We compare the model size of the Original Model with the size after applying QLoRA. To visualize this, we’ve created a diagram showing two circles representing the relative sizes of the models. The original model was 2.88GB, and after applying QLoRA, the model size was reduced to just 0.46GB—which is only 16% of the original size, thanks to quantization and low-rank adaptation.
This significant reduction in size comes with only a 4% drop in validation accuracy. The validation accuracy of full fine-tuning was 90%, while QLoRA achieved a comparable 86%, making this a highly efficient trade-off between model size and performance.
The plot below illustrates the significant reduction in model size achieved through QLoRA:
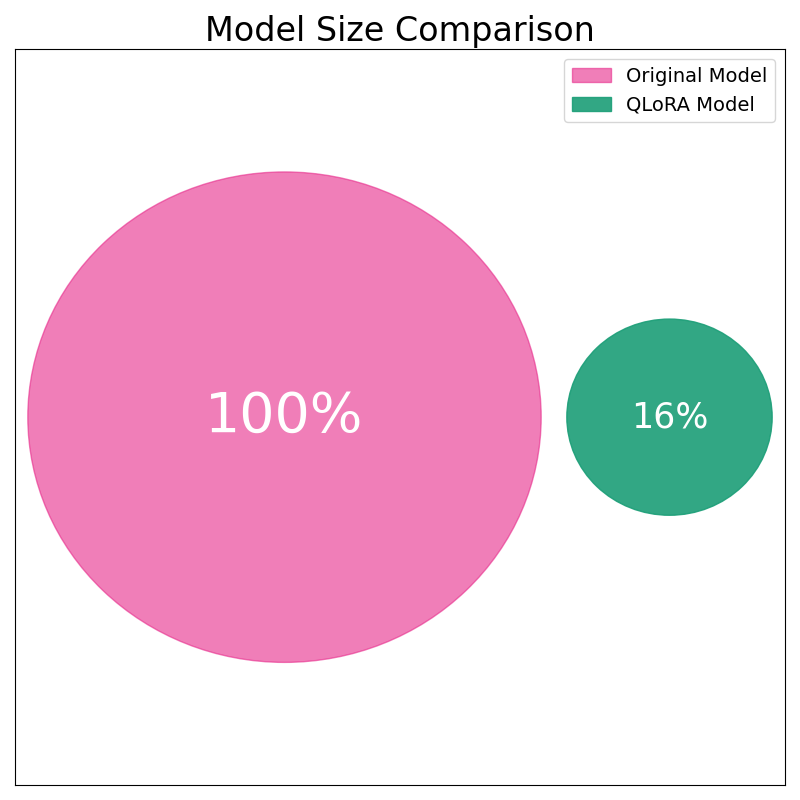
It’s important to note that methods like LoRA and DoRA do not directly affect the overall model size, as they primarily modify how the model is fine-tuned by freezing most of the parameters and introducing trainable low-rank matrices. However, QLoRA achieves a significant size reduction by quantizing the frozen weights, making it much more memory-efficient.
Now let's compare the training loss and validation accuracy of different fine-tuning approaches, including Full Fine-Tuning, LoRA, DoRA, and QLoRA.
The plot below shows the training loss for each approach across multiple epochs. While Full Fine-Tuning achieves the lowest training loss, it doesn’t necessarily result in the best validation accuracy. In fact, LoRA demonstrates better validation accuracy, even though its training loss is slightly higher.
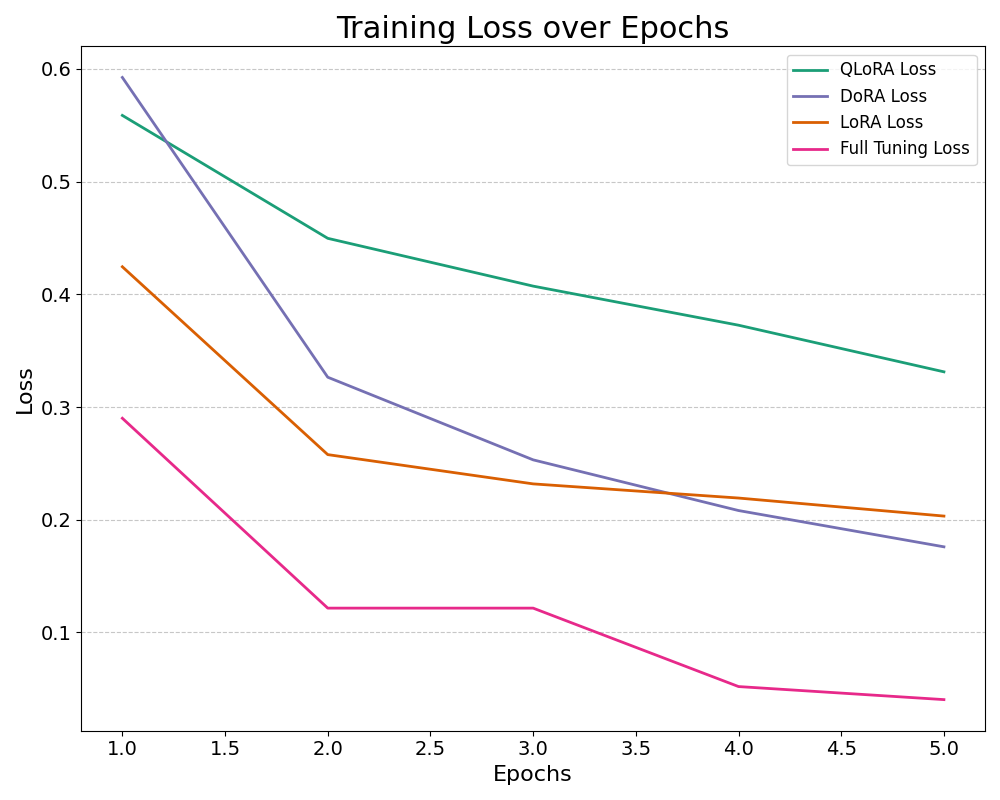
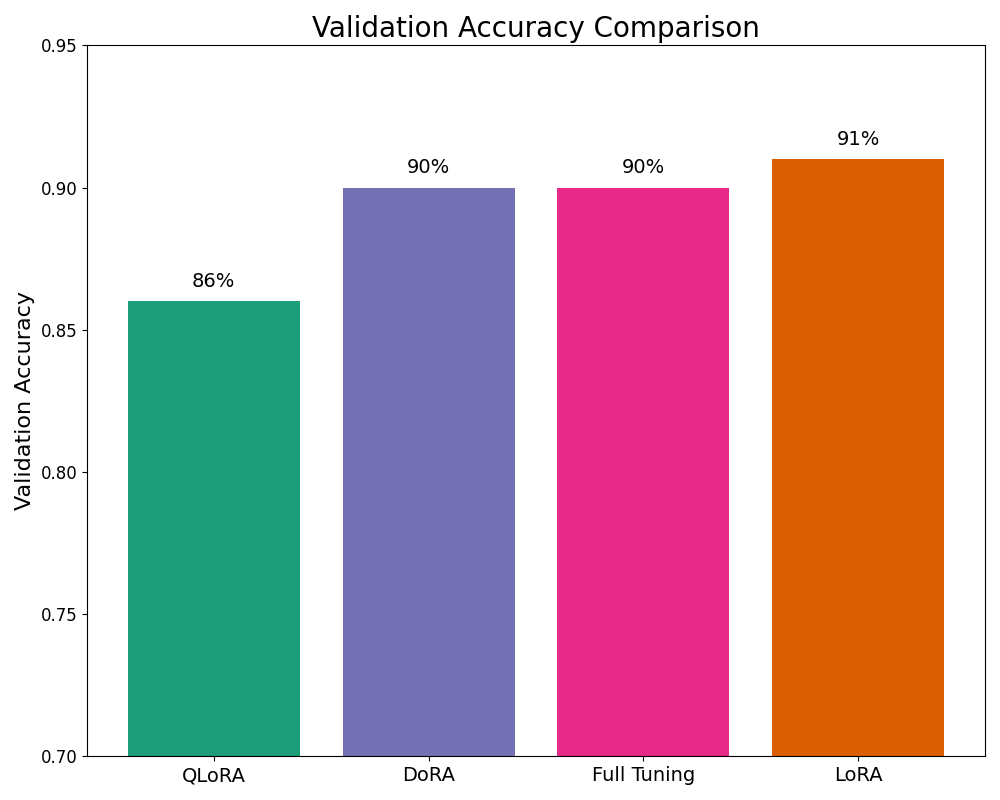
This highlights a critical observation when working with smaller datasets: Full Fine-Tuning can lead to overfitting. It optimizes well on the training data (leading to lower training loss), but this can come at the cost of generalization to unseen validation data. On the other hand, methods like LoRA and QLoRA, which focus on updating fewer parameters, tend to generalize better, striking a balance between training performance and validation accuracy.
By using parameter-efficient methods such as LoRA, we can avoid overfitting and achieve stronger validation performance, making these approaches particularly effective for fine-tuning on small datasets.
In this article, we've explored several Parameter-Efficient Fine-Tuning (PEFT) approaches, including LoRA, DoRA, and QLoRA, and compared them to Full Fine-Tuning. Through our experiments, we observed key trade-offs in terms of model size, execution time, training loss, and validation accuracy.
Overall, PEFT methods like LoRA and QLoRA offer a promising solution for fine-tuning large models on small datasets or limited hardware. They strike a balance between efficiency and performance, making them an attractive option for modern machine learning tasks.
These findings demonstrate the value of adopting parameter-efficient methods, especially when dealing with limited resources, without sacrificing model performance.
Hu, Edward J., et al. LoRA: Low-Rank Adaptation of Large Language Models
Shih-Yang Liu, et al. DoRA: Weight-Decomposed Low-Rank Adaptation
Tim Dettmers, et al. QLoRA: Efficient Finetuning of Quantized LLMs
BitsAndBytes: Optimizing Memory for Large Language Models

