
Overview
KHOJ is an GenAI enabled RAG search engine which answers queries of employees across all customer facing units providing complete & up-to-date information regarding the bank’s Products, Policies, Processes & People (4Ps) at the click of a button. On searching for any information, the engine provides correct contextual replies along with all relevant documents, ppts, quiz, images etc which can be downloaded, shared or printed thus providing an end-to-end resolution to the respective query.
Problem Statement:
The bank offers a wide range of products & services (300+) that are governed by complex regulatory processes which are subject to regular changes as mandated by RBI. The frontline staff need to have all the information w.r.t. 4 Ps - Products, Policies, Processes & People (managing the products/processes) at their fingertips which is currently not available. Employees have to rely on numerous disparate sources (mails, presentations, portals created by different teams, etc.) to get the required information which may or may not be up-to-date. This leads to a lot of to & fro before any customer request/query is addressed correctly resulting in a delay in fulfilling customer requests and thereby increase in complaints.
To overcome this problem, we created an internal AI based search engine, KHOJ that answers all queries & provides the most relevant information w.r.t. the 4 Ps. KHOJ is our own internal Bank wide AI based unified search engine for all Bank employees. It's based on GenAI, therefore one can seamlessly search for information using conversational style communication as well.
Key Components:
In a Basic RAG (Retrieval-Augmented Generation) pipeline, the system uses a combination of search and generation to create accurate responses based on real data. Here’s a straightforward breakdown of how it works, with a few technical terms explained along the way:
1.User Query: The process starts when a user asks a question, such as "What are the benefits of a savings account?"
2.Retriever: This component, essentially a smart search engine, looks through a database of documents (like text chunks or articles) to find the most relevant information related to the query. It can use algorithms like BM25 (a common method for matching text) or embeddings-based search (where it matches the meaning rather than exact words).
3.Document Database: All the documents are stored in a special database, often a vector database (e.g., ChromaDB or Milvus). This type of database allows quick retrieval based on vector similarity, which is ideal for storing and searching large amounts of text in a format the retriever can efficiently work with.
4.Embedder: Before searching, both the user query and the documents are turned into embeddings—vector representations that capture the meaning of the text. The embedder is often a model like Sentence Transformers or similar tools that help convert text into a numeric format for quick similarity matching.
5.Relevant Document Retrieval: The retriever then uses the embeddings to find the best-matching documents or text chunks based on their similarity to the user query.
6.Generator (LLM): Once the relevant documents are found, they’re fed into a large language model (LLM) like GPT or Llama, which reads the documents and crafts a response that pulls in the specific information needed to answer the user’s question.
7.Final Response: The language model then produces a response based on the documents it reviewed, and this answer is sent back to the user.
Retrieving passages or documents within a RAG pipeline without further validation and self-reflection can result in unhelpful responses and factual inaccuracies. Since the models aren’t explicitly trained to follow facts from passages post-generation verification is necessary.
To make a Baisc RAG chatbot to a Enterprise Level Chat following key Components were used:
1.SELF-RAG
Self RAG (Self-Reflective Retrieval-Augmented Generation) is an advanced form of Retrieval-Augmented Generation where the model continuously evaluates and refines its answers based on the relevance of retrieved documents. It combines the typical RAG process with self-assessment, enabling it to iterate on responses and improve accuracy. Here’s how it works:
1.Question Analysis: The model first analyses the user query to understand what information is needed.
2.Retriever Loop: Instead of retrieving documents only once, Self RAG allows the model to revisit and adjust the retrieval process if the initial results aren’t sufficient, pulling in more relevant context iteratively.
3.Self-Reflection: After generating a response, the model assesses whether the answer is accurate and complete, based on the information retrieved. If not, it can refine the retrieval or adjust its answer for improved quality.
4.Feedback Integration: The model may also use past interactions or user feedback to improve future responses, learning over time what types of documents are most helpful for similar questions.
Self RAG is especially effective for complex queries, as it can iterate and improve answers, producing more relevant and contextually accurate responses by evaluating its own output.
Following is the base SELF RAG architecture implemented using Langgraph of Langchain:
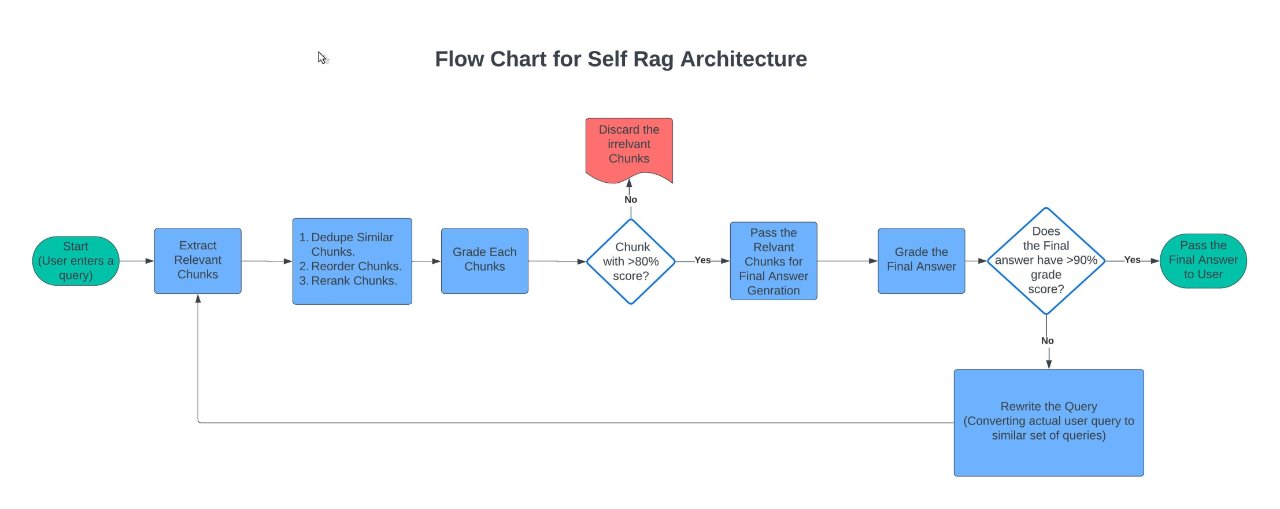
Langraph SelfRag Workflow Definition:
### Workflow Definition ### from langgraph.graph import END, StateGraph workflow = StateGraph(GraphState) # Define the nodes workflow.add_node("follow_up_detector", follow_up_detector) workflow.add_node("transform_followupquery", transform_followupquery) #workflow.add_node("decide_on_followup", decide_on_followup) workflow.add_node("retrieve", retrieve) workflow.add_node("grade_documents", grade_documents) workflow.add_node("generate", generate) workflow.add_node("transform_query", transform_query) workflow.add_node("prepare_for_final_grade", prepare_for_final_grade) # Build graph workflow.set_entry_point("follow_up_detector") workflow.add_conditional_edges( "follow_up_detector", decide_on_followup, { "transform_followupquery": "transform_followupquery", "retrieve": "retrieve", }, ) #workflow.set_entry_point("retrieve") workflow.add_edge("transform_followupquery", "retrieve") workflow.add_edge("retrieve", "grade_documents") workflow.add_conditional_edges( "grade_documents", decide_to_generate, { "transform_query": "transform_query", "generate": "generate", }, ) workflow.add_edge("transform_query", "retrieve") workflow.add_conditional_edges( "generate", grade_generation_v_documents, { "supported": "prepare_for_final_grade", "not supported": "generate", }, ) workflow.add_conditional_edges( "prepare_for_final_grade", grade_generation_v_question, { "useful": END, "not useful": "transform_query", }, )
2. Fine Tuning Embedding Model:
Embedding models play a crucial role in successful RAG applications, yet they are often trained on general knowledge, which limits their effectiveness for company- or domain-specific use. Customizing embeddings to your specific domain data can significantly enhance the retrieval performance of a RAG application.
For example, Bank possesses a vast knowledge repository covering information on products, policies, processes, and people, containing a variety of Indian jargon and financial terminology that standard embedding models struggle to process accurately. This can lead to misunderstandings of queries or extraction of irrelevant document chunks. Fine-tuning the embedding model on this specialized data is essential for improved accuracy and relevance.
Thus, to overcome this drawback of Embedding Models we FineTuned OpenSource Nomic Embedding Model on bank's Financial Data using Matryoshka Representation Learning (MRL) technique.
Matryoshka Representation Learning (MRL) is a technique designed to create embeddings that can be truncated to various dimensions without significant loss of performance. This approach frontloads important information into earlier dimensions of the embedding, allowing for efficient storage and processing while maintaining high accuracy in downstream tasks such as retrieval, classification, and clustering.
For example, a Matryoshka model can preserve ~99.9% of its performance while needing 3x less storage. This is particularly useful for applications where storage and processing resources are limited, such as on-device applications or large-scale retrieval systems.
-Prepare embedding dataset for Finetuning.
To begin with we took open source Financial Finetuning data set from the HuggingFace.
https://huggingface.co/datasets/philschmid/finanical-rag-embedding-dataset
This Dataset is a Table with two Columns
- Question : A question Related to Finance Topic
- Context : Appropriate Answer to the given Question of the same row.
In addition to using this open-source finance dataset, we appended similar-format data containing questions and context specific to our bank which had samples of typical Indian Finance Jargons and terminology.
Comparing Pre and Post FineTuning performance of Open Source Nomic Embedding Model:
Matryoshka_dimensions for the base open Source Model:
| Dimension | Cosine NDCG@10 |
|---|---|
| dim_768 | 0.76690993364858 |
| dim_512 | 0.7650737231702913 |
| dim_256 | 0.7591935027788405 |
| dim_128 | 0.7524680821978482 |
| dim_64 | 0.7202764279713355 |
Matryoshka_dimensions for the FineTuned open Source Model:
| Dimension | Cosine NDCG@10 |
|---|---|
| dim_768 | 0.8223087410019563 |
| dim_512 | 0.8231699420389409 |
| dim_256 | 0.819548158104009 |
| dim_128 | 0.8008942502035629 |
| dim_64 | 0.7799518195532503 |
This shows an 8-10% improvement in the performance of the OpenSource Model on the Finance RAG application after FineTuning using Matryoshka Representation Learning (MRL).
3. Contextual Chunking:
Contextual Chunking is the process of breaking down long documents into smaller, meaningful sections or "chunks" that capture coherent pieces of information. This is especially important in applications like Retrieval-Augmented Generation (RAG), where large language models (LLMs) have limitations on the amount of text they can process at once (often measured in tokens).
Here’s why contextual chunking is essential for handling long documents:
1.Token Limit Constraints: Most LLMs have a maximum token limit per input, so directly inputting a lengthy document may not be feasible. Chunking helps to fit sections within this limit, making each part accessible to the model.
2.Maintaining Context: Simple splitting by word count or character limit often breaks sentences or paragraphs, leading to fragmented or incomplete ideas. Contextual chunking keeps related information together, preserving the meaning and coherence of each section.
3.Improved Retrieval Relevance: In RAG systems, a retriever pulls only the most relevant chunks to answer a query. Contextual chunking allows the retriever to select focused, relevant sections, enhancing the accuracy of information passed to the model.
4.Enhanced Generation Quality: When the generator receives well-organized, contextually relevant chunks, it can produce more accurate and context-aware responses. This reduces the risk of misinterpretation or missing critical information.
In summary, contextual chunking is vital for making long documents manageable, preserving meaning, and ensuring models can work effectively within token limits while still generating accurate, coherent responses.
To implement contextual chunking effectively, we needed an LLM with a large context window. We chose Llama 3.2 3B, an efficient open-source model that supports a 128K token context window, making it ideal for handling long documents. Below is a code snippet demonstrating our implementation:
# Setup for Hugging Face Llama 3.2 model (loaded locally) model_path = "Path/model/llama3.2" tokenizer = AutoTokenizer.from_pretrained(model_path) model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16) # Initialize the text generation pipeline pipe = pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, device=0 if torch.cuda.is_available() else -1, # Use GPU if available max_length=128000 # Context window set to 128k tokens ) class ContextualRetrieval: """ A class that implements the Contextual Retrieval system using Llama 3.2. """ def __init__(self): """ Initialize the ContextualRetrieval system. """ self.text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, ) self.embeddings = embeddingz # Assuming 'embeddingz' is defined elsewhere in your code self.llm = pipe # Use Hugging Face pipeline here def process_document(self, documents: List[Document]) -> Tuple[List[Document], List[Document]]: """ Process a list of Document objects by splitting them into chunks and generating context for each chunk. """ chunks = [] for doc in documents: # Split the document into chunks doc_chunks = self.text_splitter.create_documents([doc.page_content]) # Add metadata to each chunk for chunk in doc_chunks: chunk.metadata = doc.metadata # Retain original metadata chunks.extend(doc_chunks) # Generate contextualized chunks contextualized_chunks = self._generate_contextualized_chunks(chunks) return chunks, contextualized_chunks def _generate_contextualized_chunks(self, chunks: List[Document]) -> List[Document]: """ Generate contextualized versions of the given document chunks. """ contextualized_chunks = [] for chunk in chunks: # Generate context based on each chunk's page content context = self._generate_context(chunk.page_content) # Use chunk only contextualized_content = f"{context}\n\n{chunk.page_content}" # Retain metadata while creating the contextualized chunk contextualized_chunks.append(Document(page_content=contextualized_content, metadata=chunk.metadata)) return contextualized_chunks def _generate_context(self, chunk: str) -> str: """ Generate context for a specific chunk using the language model. """ # Prepare the message for the language model messages = [ {"role": "system", "content": "You are an AI assistant that provides succinct context to help improve search retrieval of document chunks."}, {"role": "user", "content": f"<document>\n{document}\n</document>\n\nHere is the chunk we want to situate within the whole document:\n<chunk>\n{chunk}\n</chunk>\nPlease give a detailed succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the detailed succinct context and nothing else."} ] # Generate the response from the language model response = self.llm(messages) final_response=response[0]["generated_text"][-1]['content'] # Ensure it's properly formatted return final_response
4. Advance Retriever pipeline of RAG:
In Retrieval-Augmented Generation (RAG), advanced retrievers play a crucial role in enhancing the quality of retrieved information, especially when dealing with complex queries or large document sets. Here’s why advanced retrievers like LangChain’s Multi-Query Retriever and an Ensemble Retriever (combining BM25 with VectorDB) are valuable, along with the benefits of a compression and re-ranking pipeline:
1.Handling Complex Queries with Multi-Query Retriever:
Traditional retrievers may struggle with complex or nuanced queries because they retrieve based on a single interpretation.
LangChain’s Multi-Query Retriever creates multiple reformulations of the original query to capture different possible meanings or nuances. This approach broadens the retrieval scope, ensuring that the most relevant information—regardless of phrasing—is included.
2.Increased Relevance with Ensemble Retriever (BM25 + VectorDB):
Combining BM25 (a text-based retriever that excels at keyword matching) with a VectorDB retriever (which retrieves semantically similar information based on embeddings) allows for a more balanced retrieval.
BM25 captures literal matches in the text, while VectorDB captures contextual meaning, creating a more comprehensive set of results that balances precision and recall.
3.Context Compression Pipeline:
Once relevant documents are retrieved, they’re often too lengthy or verbose for the model’s context window. A context compression step trims down the content by summarizing or extracting key points without losing critical information.
This step ensures that only the most relevant parts of the document are passed to the generator, making it more efficient for the model to process within its context limits.
4.Re-Ranking for Optimal Relevance:
The final step involves re-ranking the compressed chunks, ordering them by relevance to the query. This ensures the generator receives the most relevant chunks first, increasing the likelihood of an accurate response.
In summary, advanced retrieval pipelines with multi-query retrievers, ensemble techniques, and context compression and re-ranking help capture complex queries, ensure diverse yet relevant results, and streamline the model’s input, ultimately enhancing RAG performance.
Conclusion
In conclusion, the implementation of an agentic Self RAG architecture, combined with fine-tuning of the embedding model and advanced chunking and retrieval pipelines, has led to the development of an enterprise-level RAG system. This system is currently in use at the bank, delivering accurate responses to user queries and empowering front-line employees to better serve the bank’s customers.