This study presents the development of a Convolutional Neural Network (CNN) for the classification of casting defects in manufacturing processes. The model was trained on a dataset of 7,348 grayscale images sourced from Kaggle, representing various casting defects. The dataset underwent preprocessing, including rescaling, augmentation, and resizing to 64x64 pixels, and was partitioned into training, validation, and test sets. The CNN architecture consists of three convolutional layers followed by max pooling layers for dimensionality reduction, a dense layer and ReLU activation, and a dropout layer to mitigate overfitting. Implemented using TensorFlow, Keras, and scikit-learn, the model achieved an accuracy of 92%, demonstrating its potential for reliable defect detection in casting.This approach offers a promising solution for automating defect detection in manufacturing, improving quality control, and enhancing production efficiency.
Casting is a manufacturing technique in which a liquid material is typically poured into a mold with a hollow cavity shaped to the desired form and allowed to solidify. A casting defect refers to an unwanted irregularity that occurs during the metal casting process.
The methodology for the casting defect classification model follows a structured approach, encompassing dataset preparation, data preprocessing, model architecture design, and training. Below is a detailed description of the process:
Dataset Structure:
The dataset consists of 7,348 grayscale images, each of size 300x300 pixels, categorized into two classes: def_front and ok_front. The images were sourced from Kaggle and are organized as follows:
Training Set:
def_front: 3,758 images of defective castings.
ok_front: 2,875 images of non-defective castings.
Test Set:
def_front: 453 images of defective castings.
ok_front: 262 images of non-defective castings.
Libraries Used:
The model was built using several Python libraries essential for image processing, model development, and evaluation; TensorFlow and Keras for model construction and training, matplotlib for data visualization, and scikit-learn for evaluation metrics and model assessment.
Data Loading:
The paths to the training and test image directories were defined to load the images into the model. The training images were split into training and validation sets with an 80
Data Preprocessing:
Data preprocessing was performed using the ImageDataGenerator class. The training set underwent rescaling and augmentation, which included horizontal and vertical shifts, zooming, and validation splitting, to improve model robustness. The test set was normalized without any augmentation. All images were resized to 64x64 pixels with a batch size of 32 to optimize computational efficiency.
CNN Architecture:
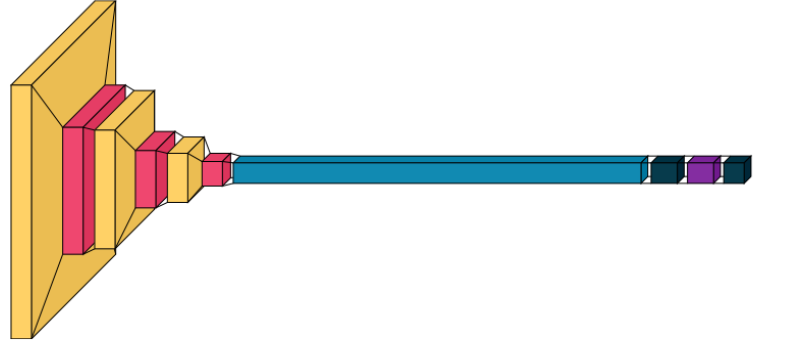
A Convolutional Neural Network (CNN) was designed for feature extraction and classification. The architecture consists of the following layers:
Convolutional Layers: Three convolutional layers with 32, 64, and 128 filters were used to extract features from the images.
MaxPooling Layers: MaxPooling layers were applied after each convolutional layer to reduce spatial dimensions and enhance computational efficiency.
Flattening Layer: The output of the convolutional layers was flattened to prepare the data for the fully connected layers.
Dense Layer: A fully connected dense layer with 256 neurons and ReLU activation was added for feature learning.
Dropout Layer: A dropout layer with a 33% rate was included to prevent overfitting during training.
Output Layer: A sigmoid activation function was used in the output layer to perform binary classification (def_front or ok_front).
This architecture was designed to balance feature extraction, model complexity, and regularization to optimize performance for casting defect detection.
The model was compiled using the Adam optimizer with a learning rate of 0.001, and binary cross-entropy was chosen as the loss function. The training was performed with early stopping, monitoring the validation loss, and restoring the best weights after three epochs of no improvement.
The model was trained for 30 epochs with the following parameters:
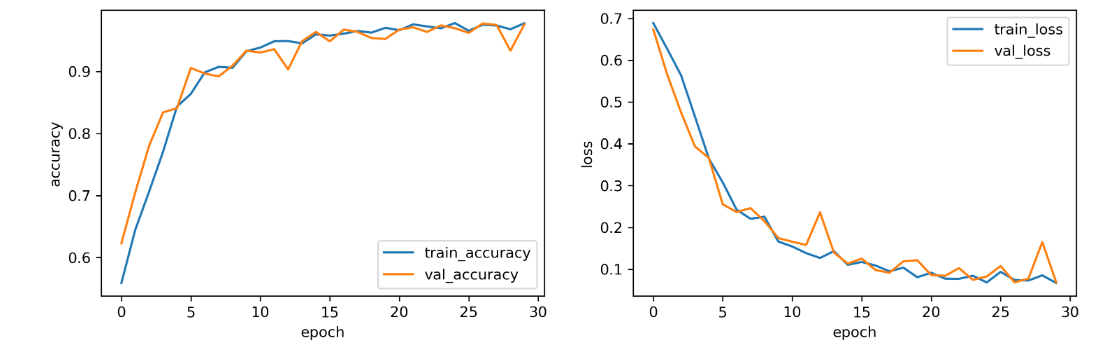
Training Accuracy: The model's accuracy on the training set improved from 54.63% in the first epoch to 97.57% by the final epoch.
Validation Accuracy: The model's validation accuracy achieved a peak of 97.59% in the final epoch.
Early Stopping: The early stopping callback ensured that the model was not overfitted, with the best model being restored at the point of highest validation accuracy.
Analysis:
The model's performance on the test set was evaluated after training, yielding the following results:
Test Loss: 0.2588
Test Accuracy: 91.89%
Training Accuracy: The training accuracy steadily increased, reaching 97.57% by the final epoch.
Validation Accuracy: The validation accuracy also showed a steady increase, peaking at 97.59%.
The model achieved 92% accuracy, correctly classifying most instances.
def_front:
Precision: 1.00, Recall: 0.87, F1: 0.93
The model perfectly identified def_front but missed some instances.
ok_front:
Precision: 0.82, Recall: 1.00, F1: 0.90
Perfect recall for ok_front, with some false positives.
Confusion Matrix:
Correctly classified 395 def_front and 262 ok_front instances.
58 false positives for def_front.
Overall, the model performed well, with minor misclassifications.
The study demonstrated the effectiveness of the model in classifying the two categories, with room for improvement in balancing precision and recall. Future work may involve further model optimization, exploring alternative algorithms, and addressing the current challenges to enhance performance and applicability. Additionally, the model was integrated into a Streamlit application, providing an interactive interface for real-time predictions and analysis.
Link